java并发编程实践学习(11)性能和可伸缩性
很多改进性能的技术同样增加了复杂度,因此增加了安全和活跃度失败的可能性。
11.1性能的思考
无论是CPU周期、内存、网络带宽、I/O带宽、数据库请求、磁盘空间、以及其他一些资源。当活动因某个特定资源受阻时,我们称之为受限于该性能资源:受限于CPU,受限于数据库。
但是与单线程方法相比,使用多线程总会引入一些性能的开销:包括与协调相关的开销(加锁,信号,内存同步),增加上下文切换,线程的创建和消亡,以及调度的开销。当线程被过度使用后,这些开销会超过提高后的吞吐量响应性和计算能力带来的补偿,从另一个方面,一个没能经过良好并发设计的应用程序,甚至比相同功能顺序的程序性能更差。
1. 性能“遭遇”可伸缩性
可伸缩性指的是:当增加计算资源的时候(比如增加额外CPU数量,内存,存储器,I/O带宽),吞吐量和生产量能够相应的得以改进。
为并发而进行的调试,通常目的是用最小的代价完成相同的工作,比如通过缓存来重用以前的计算结果,或者使用时间复杂度小的算法。
二.Amdahl定律
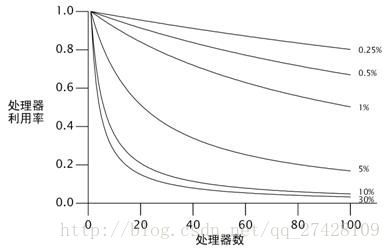
Amdahl定律描述了在一个系统中,基于可并行化和串行化的组件各自 所占的比重,程序通过获得额外的计算资源,理论上能够加速多少。如果F 是必须串行化执行的比重,那么Amdahl定律告诉我们,在一个N 处理器的机器中,我们最多可以加速:![]()
当N 无限增大趋近无穷时,speedup 的最大值无限趋近1/F ,这意味着一个程序中如果50%的处理都需要串行进行的话,speedup 只能提升2倍(不考虑事实上有多少线程可用);如果程序的10%需要串行进行,speedup 最多能够提高近10倍。Amdahl定律同样量化了串行化的效率开销。在拥有10个处理器的系统中,程序如果有10%是串行化的,那么最多可以加速5.3 倍(53%的使用率),在拥有100个处理器的系统中,这个数字可以达到9.2(9%的使用率)。这使得无效的CPU利用永远不可能到达10倍。
图11.1展示了随着串行执行和处理器数量变化,处理器最大限度的利用率的曲线。随着处理器数量的增加,我们很明显地看到,即使串行化执行的程度发 生细微的百分比变化,都会大大限制吞吐量随计算资源增加。
但是为了在多处理器系统中预知你的程序是否存在加速的可能性,你同样需要识别你的任务中串行的部分。
假设应用程序中N 个线程正在执行doWork,从一个共享的工作队列中取出任务,并处理;假设这里的任务并不依赖其他任务的结果或边界效应。忽略任务进行队列操作的时间, 如果我们增加处理器,应用程序会随之发生什么样的改进呢?乍看这个程序可能完全由并行任务组成,并不会相互等待,那么处理器越多,更多的任务就越可能并发 处理。然而,其中也包含串行组件——从队列中获取任务。所有工作者线程都共享工作队列,因此它会需要一些同步机制,从而在并发访问中保持完整性。如果通过 加锁来守卫队列状态,那么当一个线程从队列中取出任务的时候,其他线程想要取得下一个任务就必须等待——这便是任务处理中串行的部分。
单个任务的处理时间不仅包括执行任务Runnable的时间,也包括从共享队列中取出任务的时间。如果工作队列是 LinkedBlockingQueue类型的,这个取出的操作被阻塞的可能性小于使用同步的LinkedList的阻塞可能,这是因为 LinkedBlockingQueue使用了更具伸缩性的算法,但是访问所有共享的数据结构,本质上都会向程序引入一个串行的元素。
这个例子同样忽略了另一个的相同的串行源(source of serialization):结果处理。所有有用的计算都产生一些结果集或者边界效应——如果不是,它们可以当作死代码(dead code)被遗弃掉。因为Runnable没有提供明确的结果处理,这些任务必须具有一些边界效应,设定把它们的结果写入日志还是存入一个数据结构。日志文件和结果容器通常由多个工作者线程共享,并且因此成为了同源的串行部分。如果不是每个线程各自维护自己的结果的数据结构,而是在所有任务都执行完后合并所有的结果,这最终就合并成为了一个串行源。
串行访问任务队列
public class WorkerThread extends Thread {
private final BlockingQueue queue;
public WorkerThread(BlockingQueue queue) {
this.queue = queue;
}
public void run() {
while (true) {
try {
Runnable task = queue.take();
task.run();
} catch (InterruptedException e) {
break; /* 允许线程退出 */
}
}
}
} 1.框架中隐藏的串行化
为了观察并行化如何被隐藏在应用程序的构架中,我们可以比较加入线程时的吞吐量,基于观察到的可伸缩性变化来推断串行源。
下图的曲线比较了俩个均为线程安全的Queue实现:synchronizedList包装了LinkedList,另一个是ConcurrentLinkedQueue。尽管每一次运行代表相同数量的工作,我们能够看到,只有改变队列的实现才能明显的影响可伸缩性。

ConcurrentLinkedQueue的吞吐量持续改进,直到它到达了处理器数量,之后会保持不变。另一个方面同步LinkedList的吞吐量在3个线程时表现了其带来的改进,但是之后会下跌,因为同步的开销增加了。图中当线程数为4或5时,竞争是非常激烈的,以至于每次访问队列都要竞争锁,并且吞吐量受控于上下文切换的次数
吞吐量的不同源自于俩个队列实现的串行化不同。同步的LinkedList用一个锁守护着整个队列,在offer和remove调用时都要获取这个锁;concurrentLinkedQueue使用了精妙的非阻塞队列算法,它使用了原子引用来更新各个链接指针。这俩者,其中一个是把整个的插入和删除都实现为串行化的,另一个则是把每个指针的更新变成串行化的。
三.线程引入的开销
单线程程序既不存在调度问题,也不存在同步的开销,不许需要用锁来保证数据结构的一致性。调度和线程内部的协调需要付出性能的开销;对于性能改进的线程来说,并行带来的性能优势必须超过并发所引入的开销。
1.切换上下文
如果主线程是唯一可调度的线程,它不会被排除在调度之外。如果可运行的线程数大于CPU的数量,那么OS会最终强制换出正在执行的线程,从而使其他线程能够使用CPU。切换上下文是需要代价的;线程的调度需要操控和jvm中共享的数据结构。
当线程因为竞争一个锁而阻塞时,JVM通常会将这个线程挂起,运行他被换成。如果线程频繁发生阻塞,那么线程就不能完整的使用它调度的限额了。一个程序发生越多的阻塞(阻塞I/O、等待竞争锁、或者等待条件变量),与受限于CPU的程序相比,就会造成越多的上下文切换,这增加了调度的开销并且减少了吞吐量。
2.内存同步
性能开销的几个来源。synchronized和volatile提供的可见性保证要求使用一个特殊的、名为存储关卡的指令来刷新缓存,使缓存无效,刷新硬件的写缓存,并延迟执行的传递。存储关卡同样会对性能产生影响,因为他们抑制了编译器的优化;在存储关卡中,大多数操作是不能被重新排序。
现代JVM能够通过优化,解除经确证不存在竞争的锁,从而减少额外的同步。更加成熟的JVM可以使用逸出分析来识别本地对象的引用并没有在堆中被暴露,并且因此成为本地线程。编译器同样可以进行锁的粗化,把临近的synchronized块用相同的锁合并起来,并对toString使用单独的锁请求和释放。
一个线程中的同步也可能影响到其他的线程的性能。同步造成了共享内存总线上的通信量。这个总线的带宽是有限的,所有进程都共享这条总线。如果线程必须竞争同步带宽,所有用到同步的县城都会受阻。
3.阻塞
非竞争的同步可以由JVM完全掌控;而竞争的同步肯呢更需要OS的活动,这会增大开销。当锁为竞争的时候,失败的线程必然发生阻塞。JVM既能自旋等待(不断尝试获取锁,直到成功),或者在操作系统中挂起这个被阻塞的线程。哪一个效率高要取决于上下文切换的开销,以及成功的获取所需要等待的时间这两者之间的关系。自旋等待更适合短期的等待,而挂起适合长时间的等待。有一些JVM基于过去等待的时间的数据剖析在这两者之间进行选择,但是大多数等待锁的线程都是被挂起的。
需要挂起线程可能因为线程无法得到锁,或者因为他们在等待某个条件,抑或被I/O操作阻塞。
四.减少锁的竞争
访问独占锁守护的资源是穿行的,一次只有一个线程能访问它。
有两个原因影响着锁的竞争性:锁被请求的频率,以及持有该锁的时间。如果这两者的乘积足够小,那么大多数请求锁的尝试都是非竞争的,但是请求很大的话,线程将会阻塞以等待锁;
有三种方式来减少锁的竞争:
- 减少锁的持有时间
- 减少请求锁的频率
- 用协调机制取代独占锁,从而允许更强的并发性
1.缩小锁范围(”快进快出”)
减小竞争发生可能性的有效方式是尽可能缩短把持锁的时间。这可以通过把与锁无关的代码移出synchronized块来实现。我们可以使用代理线程安全的技术。省去显示的同步,也能减小忘记加相应的锁而造成风险。
尽管缩小synchronized块能提高可伸缩性。但是同步的开销非零。把一个synchronized块拆分成多个块在某些时刻会产生反作用。
2.减小锁的粒度
减小持有锁的时间比例的另一种方式是让线程减少调用它的频率,这可以通过分拆锁和分离锁实现。采用互相独立的锁,守卫多个状态变量。
如果一个锁守卫数量大于一,且相互独立的状态变量,你可以通过分拆锁,使每一个锁守护不同的状态变量。
3.分离锁
分拆锁有时候可以被扩展,分成可大可小的锁块集合,并且他们归属于相互独立的对象,这样的情况就是分离锁。
分离锁的负面作用是:对容器加锁进行独占访问更加困难,并且更加昂贵。
4.避免热点域
当每一个操作都请求变量的时候,锁的粒度很难被降低。这是性能和可伸缩性相互牵制的另一个方面;通常使用的优化方法,比如缓存常用的计算结果,会引入“热点域(hot fields)”,从而限制可伸缩性。
如果由你来实现HashMap,你会遇到一个选择:size方法如何计算Map条目的大小?最简单的方法是每次调用的时候数一遍。通常使用的优化方法是在插入和移除的时候更新一个单独的计数器;这会给put和remove方法造成很小的开销,以保证计数器的更新,但是,这会减少size方法的开销,从O(n)减至O(1)。
在单线程或完全同步的实现中,保存一个独立的计数能够很好地提高类似size和isEmpty这样的方法的速度,但是却使改进可伸缩性变得更难了,因为每一个修改map的操作都要更新这个共享的计数器。即使你对每一个哈希链(hash chain)都使用了锁的分离,对计数器独占锁的同步访问还是重新引入了可伸缩性问题。这看起来像是一个性能的优化——缓存size操作的结果——却已经转化为一个可伸缩性问题。这种情况下,计数器被称为热点域(hot field),因为每个变化操作都要访问它。
为避免这个问题,ConcurrentHashMap通过枚举每个条目获得size,并把这个值加入到每个条目,而不是维护一个全局计数。为了避免列举所有元素,ConcurrentHashMap为每一个条目维护一个独立的计数域。同样由分离的锁守护。
5.独占锁的替代方法
用于减轻竞争锁带来的影响的第三种技术是提前使用独占锁,这有助于使用更友好的并发方式进行共享状态的管理。这包括使用并发容器、读-写锁、不可变对象,以及原子变量。
原子变量提供了能够减少更新“热点域”的方式,如果你的类只有少量热点域,并且该类不参与其他变量的不变约束,那么使用原子变量替代它可能会提高可伸缩性。(改变你的代码,减少它的热点域,这样会提高可伸缩性,甚至——原子变量减少更新热点域的开销,但是它们完全消除这种开销。)
6.监测CPU利用率
当我们测试可伸缩性的时候,我们的目标通常是保持处理器的充分利用。Unix系统的vmstat和mpstat,或者Windows系统的perfmon都能够告诉你处理器有多“忙碌”。
如果所有的CPU都没有被均匀地利用(有时CPU很忙碌地运行,有时候很“清闲”),那么你的首要目标应该是增强你程序的并行性。不均匀的利用率表明,大多数计算都由很小的线程集完成,你的应用程序将不能够利用额外的处理器资源。
如果你的CPU没有完全利用,你需要找出原因。有下面几种原因:
- 不充足的负载。可能被测试的程序还没有被加入足够多的负载。你可以增加负载,并检查利用率、响应时间和服务运行时间的变化。产生足够多的负载,使应用程序饱和需要计算机强大的能力;问题可能在于客户端系统是否具有足够的能力,而不是被测试系统。
- I/O限制。你可以通过iostat或者perfmon判定一个应用程序是否是受限于磁盘的,或者通过监测它的网络通信量级判断它是否有带宽限制。
- 外部限制。如果你的应用程序取决于外部服务,比如数据库,或者Web Service,那么瓶颈可能不在于你自己的代码。你可以通过使用Profiler工具,或者数据库管理工具来判断等待外部服务结果的用时。
- 锁竞争。使用Profiling工具能够告诉你,程序中存在多少个锁的竞争,哪些锁很“抢手”。 如果不使用剖析器(profiler),你也可以通过随机取样来获得相同的信息,触发一些线程转储,并寻找其中线程竞争锁的信息。 如果线程因等待锁被阻塞,与线程转储相应的栈框架会声明“waiting to lock monitor …”。非竞争的锁几乎不会出现在线程转储中;竞争激烈的锁几乎总会至少有一个线程在等待获得它,所以会频繁出现在线程转储中。