RPnet车牌检测原理以及代码实现
1.
论文地址:论文地址
代码地址:https://github.com/detectRecog/CCPD.git
2.网络结构
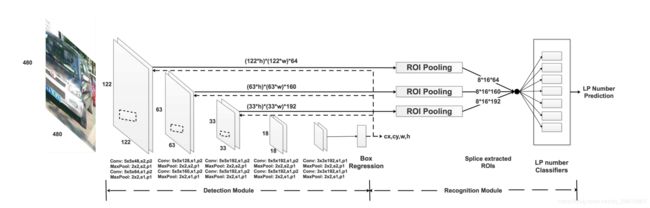 简单的来说,网络分为两个部分,检测模块以及识别模块。
简单的来说,网络分为两个部分,检测模块以及识别模块。
-
检测模块
RPnet通过检测模块中的所有卷积层从输入图像中提取特征。随着卷积层数量的增加,通道数量增加,特征图逐渐减小。最后得出的特征图具有更高层次的特征提取,有利于识别车牌以及车牌的边框。这里假设:边框中心坐标 x , y x,y x,y以及宽度和高度为 b x , b y , b w , b h {b_x},{b_y},{b_w},{b_h} bx,by,bw,bh,那么对于输入为 W , H W,H W,H的图像来说,边框的位置可以表示为: c x , c y , w , h cx,cy,w,h cx,cy,w,h:
c x = b x W , c y = b y H , w = b w W , h = b h H , 0 < c x , c y , w , h < 1 cx = {{bx} \over W},cy = {{by} \over H},w = {{bw} \over W},h = {{bh} \over H},0 < cx,cy,w,h < 1 cx=Wbx,cy=Hby,w=Wbw,h=Hbh,0<cx,cy,w,h<1
注意:这里没怎么看懂,为什么是这样。
最后一个卷积层后面接3个全连接层,称为“边框预测器”。检测模块充当网络的的“注意力层”。它告诉识别模块在哪里去识别。 -
识别模块
网络中不同层的特征图具有不同的感受野大小。此外,根据以前的工作已经表明,使用来自较低层的特征图可以提高语义分割质量,因为较低层能够捕获输入对象的更精细的细节。类似地,来自相对较低层的特征图对于识别车牌字符也很重要,就像语义分割中的对象边界一样,车牌的区域相对于整个图像是非常小的。经过检测模块的所有卷积层之后(最终的结果,而不是每层的结果)会预测出边框的位置: ( c x , c y , w , h ) (cx,cy,w,h) (cx,cy,w,h)。对于 m × n m\times n m×n p通道的图来说,识别模块提取的特征面积为 ( m × h ) × ( n × w ) (m\times h)\times (n\times w) (m×h)×(n×w) p通道。RPnet在(第二层、第四层、第六层)的末端提取feature map。提取的特征图的尺寸为:
( 122 ∗ h ) ∗ ( 122 ∗ w ) ∗ 64 , ( 63 ∗ h ) ∗ ( 63 ∗ w ) ∗ 160 , ( 33 ∗ h ) ∗ ( 33 ∗ w ) ∗ 192 (122 ∗ h) ∗ (122 ∗ w) ∗ 64, (63 ∗ h) ∗ (63 ∗ w) ∗ 160, (33 ∗ h) ∗ (33 ∗ w) ∗ 192 (122∗h)∗(122∗w)∗64,(63∗h)∗(63∗w)∗160,(33∗h)∗(33∗w)∗192。再实际中发现从高卷积层中提取特征映射会使识别速度变慢,对提高识别精度的帮助不大。在提取这些特征映射之后,RPnet利用roi pooling将提取的每个特征转换为具有固定空间范围 P H × P W P_H\times P_W PH×PW(如本文中的8*16)的特征映射。这三张特征图被调整为调整大小 8 ∗ 16 ∗ 64 8*16*64 8∗16∗64、 8 ∗ 16 ∗ 160 8*16*160 8∗16∗160和 8 ∗ 16 ∗ 192 8*16*192 8∗16∗192被连接到一张 8 ∗ 16 ∗ 416 8*16*416 8∗16∗416大小的功能图,用于车牌的分类。
3.训练
- 损失函数
损失函数分为:localization loss (loc) and the classification loss (cls)
 分类损失为交叉熵损失函数
分类损失为交叉熵损失函数
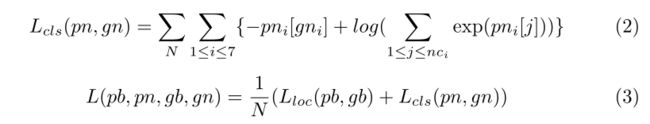
在最终训练PRnet之前,首先要训练PRnet的检测模块,使他能够检测出车牌的区域: ( c x , c y , w , h ) (cx,cy,w,h) (cx,cy,w,h)
并且要求: 0 < c x , c y , w , h < 1 0 < cx, cy, w, h < 1 0<cx,cy,w,h<1 ,并且最后能够 w 2 ≤ c x ≤ 1 − w 2 , h 2 ≤ c y ≤ 1 − h 2 {w \over 2} \le cx \le 1 - {w \over 2},{h \over 2} \le cy \le 1 - {h \over 2} 2w≤cx≤1−2w,2h≤cy≤1−2h。从而可以表示有效的ROI,指导识别模块提取特征图。与大多数物体检测相关的论文[29,31]在ImageNet [44]上预先训练它们的卷积层以使这些层更具代表性,我们在CCPD上从头开始训练检测模块,因为CCPD的数据量足够大并且,为了定位诸如牌照的单个物体,在ImageNet上预训练的参数不一定比从头开始训练更好。在实践中,检测模块在训练集上训练300个时期后总是给出合理的边界框预测。
4.初看论文时的一些问题
1.检测出的是车牌的框,那么分类网络进行识别的时候,就能够做每个字符的分类么?
5.代码实现
label的计算
new_labels = [(leftUp[0] + rightDown[0])/(2*ori_w), (leftUp[1] + rightDown[1])/(2*ori_h), (rightDown[0]-leftUp[0])/ori_w, (rightDown[1]-leftUp[1])/ori_h]
loss: 检测模块
loss += 0.8 * nn.L1Loss().cuda()(y_pred[:][:2], y[:][:2])
loss += 0.2 * nn.L1Loss().cuda()(y_pred[:][2:], y[:][2:])
识别模块
#跨越链接层
_x1 = self.wR2.module.features[1](x0)#特征图
_x3 = self.wR2.module.features[3](x2)
_x5 = self.wR2.module.features[5](x4)
boxLoc = self.wR2.module.classifier(x9) # 检测模块最终检测出的框的位置(相对于原始图像)
h1, w1 = _x1.data.size()[2], _x1.data.size()[3] #求出特征图尺寸
p1 = Variable(torch.FloatTensor([[w1,0,0,0],[0,h1,0,0],[0,0,w1,0],[0,0,0,h1]]).cuda(), requires_grad=False)
h2, w2 = _x3.data.size()[2], _x3.data.size()[3]
p2 = Variable(torch.FloatTensor([[w2,0,0,0],[0,h2,0,0],[0,0,w2,0],[0,0,0,h2]]).cuda(), requires_grad=False)
h3, w3 = _x5.data.size()[2], _x5.data.size()[3]
p3 = Variable(torch.FloatTensor([[w3,0,0,0],[0,h3,0,0],[0,0,w3,0],[0,0,0,h3]]).cuda(), requires_grad=False)
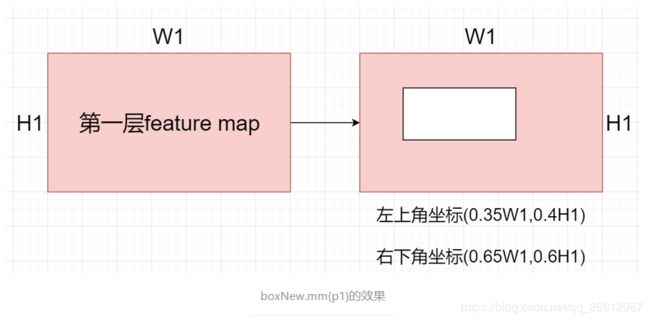
#论文的思想是根据检测模型预测出来框的位置,取出对应大小的特征图,之后roi polling 合并到一起,再去分类。所以就涉及到:怎么拿出对应的特征图
```python
#这里把(x,y,w,h)的形势转化为(x1,y1,x2,y2)的形势
postfix = Variable(torch.FloatTensor([[1,0,1,0],[0,1,0,1],[-0.5,0,0.5,0],[0,-0.5,0,0.5]]).cuda(), requires_grad=False)
boxNew = boxLoc.mm(postfix).clamp(min=0, max=1)
boxNew.mm(p1) #返回的就是检测网络检测出的框在这个特征图上的真实的坐标
# roi pooling
im = input.narrow(0, i, 1)[..., roi[1]:(roi[3] + 1), roi[0]:(roi[2] + 1)]#拿出特征图中对应的区域
# input.narrow 表示取变量input在第0维上,从索引i到i+1范围
output.append(F.adaptive_max_pool2d(im, size))