Why Does Unsupervised Pre-training Help Deep Learning 论文翻译
为什么无监督预训练有助于深度学习?
本文基本是机器翻译,并参考了娄英欣的翻译:
https://blog.csdn.net/qq_37655759/article/details/57445246
原论文:《Why Does Unsupervised Pre-training Help Deep Learning》
原论文中有不少脚注,这里不再列出,有兴趣可以查看原论文。
摘要:
最近的研究致力于深度架构的学习算法,例如Deep Belief Networks和自动编码器变体堆栈(stacks of auto-encoder variants),在几个领域获得了令人印象深刻的结果,例如视觉和语言数据集。在监督学习任务中获得的最佳结果涉及无监督学习组件,通常在无监督的训练前阶段。尽管这些新算法已经使训练深度模型成为可能,但是对于这个困难的学习问题的性质仍然存在许多疑问。这里调查的主要问题如下:无监督的预训练如何运作?如果要进一步改进深层架构的学习,回答这个问题很重要。我们提出了几个解释性假设,并通过大量模拟进行测试。我们根据经验展示了预训练对深度、模型能力和训练样例数量的影响。实验证实并阐明了无监督预训练的优势。结果表明,无监督的预训练指导学习最小化吸引(attraction)的盆地(basins),支持从训练数据集中更好地推广;从这些结果引申出来的论据支持对预训练效果的正则化解释。
关键词:
深层结构,无监督预训练,深度置信网络,堆叠降噪自动编码器,非凸最优化
- 前言
深度学习思想旨在采用由低层特征组成的高层特征来学习特征层次结构。包括的学习思想有:深层结构的广义数组(Bengio, 2009),多隐层的神经网络(Bengio, 2007)和多层隐藏变量的图解模型(Hinton, 2006)。对于理论成果(Yao, 1985),Bengio和LeCun在2007年进行了回顾和讨论,建议为了学习能表达高层抽象的复杂函数,需要深层结构。最近该领域的学习浪潮似乎支持这个观点,尤其是与人工智能相关的课题,例如计算机视觉(Bengio, 2007),自然语言处理(Collobert and Weston,2008)和信息检索(Salakhutdinov and Hinton, 2007)。深度学习思想明显优于同类竞争者,经常打败其他最先进的技术。
尽管存在具有多层自适应参数的训练模型的严峻挑战,但最近对深度学习算法的潜力进行了演示。在几乎所有深度学习的实例中,目标函数是参数的高度非凸函数,在模型参数空间中可能存在许多不同的局部最小值。主要困难在于并非所有这些最小值都提供等效的泛化误差,并且我们建议,对于深层体系结构,标准训练方案(基于随机初始化)倾向于将参数放置在参数空间的区域中,这些区域泛化性差 - 如经常基于经验地去观察,但很少报道(Bengio和LeCun,2007)。
深层结构有效训练策略的突破是在2006年,出现了2种训练算法:深度置信网络(deep belief networks)(Hinton, 2006)和堆叠自动编码器(stacked auto-encoders)(Bengio, 2007),二者均基于相似的方法:先进行逐层贪婪无监督预训练,然后进行监督微调。每层均采用无监督学习算法进行预训练,学习输入(前一层的输出)的非线性变换,捕获输入的主要变化。无监督预训练有益于最终的训练阶段,最终深层结构通过基于梯度优化的监督训练准则进行微调。虽然对于深度模型预训练的性能很好,但是很少有人知道成功背后隐藏的机制。
本文通过大量的实验来探索无监督预训练如何使得深层结构更有效和为什么它比传统神经网络训练方法更好。本文提出了几个合理的预训练作用的假设。第一个假设,无监督预训练作为一种网络的预处理器,为了将来的监督训练将参数值放在适当的范围。第二个假设,无监督预训练 初始化模型到参数空间的一个点,致使优化过程更有效,从某种意义上说实现了最低的经验代价函数( the empirical cost function)(Bengio, 2007)。
在这里,我们认为我们的实验支持将无监督预训练作为一种不寻常的正则化形式的观点:最小化方差并对参数空间的配置引入偏差,这对于无监督学习是有用的。这种观点将无监督的预训练放在最近开发的半监督方法的族中。然而,无监督预训练方法在半监督训练策略中是独特的,因为它通过定义标准监督训练的特定初始化点而不是修改监督目标函数(Barron,1991)或在整个训练中明确地对参数施加约束(Lasserre et al,2006)来起作用。这种初始化为正则化策略在神经网络文献中具有优先权,在早期停止思想(Sjöberg和Ljung, 1995; Amari等,1997)的形式中,并且在隐马尔可夫模型(HMM)社区(Bahl et al,1986; Povey and Woodland,2002)中,发现首先将HMM训练为一般的模型是必不可少的(作为初始化步骤),然后才能有条理地进行微调。我们建议,在训练深度结构的高度非凸性情况下,定义特定的初始化点隐含地对参数施加约束,因为它指定了cost function中的哪个最小值(在非常大量的可能最小值中)是允许的。通过这种方式,可以将无监督的预训练视为与Lasserre等人(2006年)的方法相关。
另一个重要的、明显的无监督预训练的特征是,在标准的训练中使用随机梯度下降法,且即使样本数量大量增长,预训练产生的有益的泛化效果也不会减少。我们认为这是由于非凸目标函数的组合和随机梯度下降法对样本顺序的依赖性。我们发现参数的早期变化对最终学习结束的区域(下降过程中的basin of attraction)有很大的影响。特别地就泛化而言,无监督预训练设置参数在能达到更好的吸引盆(basin of attraction)的区域。因此,尽管无监督预训练作为正则器,但是当训练数据很大的时候,它对训练目标有积极的影响。
正如上文所言,本文通过大量的实验来评估无监督预训练有助于深度学习的多种假设。为此,我们设计了一系列实验来排除一些假设,试图验证无监督预训练的神秘效果。
在第一组实验中(第6部分),我们验证无监督预训练对提高训练好的深层结构的泛化误差的影响。在这部分我们也会利用降维技术来说明无监督预训练是怎样影响参数空间的局部最小。
在第二组实验中(第7部分),我们直接将两种备选假设(预训练作为预处理器;预训练作为优化方案)与无监督预训练是正则化策略的假设进行比较。在最后一组实验中(第8部分),我们探讨了无监督预训练于在线学习环境中的作用,其中可用训练样本的数量变得非常大。在这些实验中,我们测试了与成本函数拓扑相关的假设的关键方面,以及未经监督的预训练在操纵监督训练的参数空间区域中的作用。
在深入研究实验之前,我们首先深入回顾深层架构培训面临的挑战,以及我们如何相信无监督的预培训能够克服这些挑战。
- 深度学习的挑战
在本节中,我们提出了为什么通过梯度反向传播对深度模型进行标准训练似乎如此困难的疑问。首先,重要的是要确定我们的意思,即说明训练是困难的。
我们认为,培训深层体系结构的主要挑战是处理跨层参数之间训练期间存在的强依赖性。设想问题困难(conceive the difficulty of the problem)的一种方法是我们必须同时:
- 适应底层以提供足够的输入给最后(训练结束)上层的设置
- 适应上层以充分利用最后(结束训练)底层的设置
第二个问题本身很容易(当已知其他层的最终设置时)。目前尚不清楚第一个是多么困难,我们猜想当必须联合学习两组层时会出现特殊的困难,因为目标函数的梯度限于给定其他参数的当前设置的局部测量。此外,因为具有足够的容量,顶部两层可以容易地在训练集上过拟合,训练误差不一定揭示优化较低层的难度。如我们在这里的实验所示,标准训练方案倾向于将参数放置在参数空间的区域中,这些区域概括性差。
如果我们重点关注基于随机梯度下降的传统训练思想,那么就会产生一个独立却相关的问题。在线梯度下降过程中的样本定义了参数空间的轨迹,在某种意义上会收敛(误差不再提高,可能因为接近局部最小值)。有一假设,轨迹中小的扰动(初始化或变化)对早期影响很大。在接下来的早期随机梯度下降过程中,权重的变化会增加数量级,因此非线性网络的数量增加。当出现上述情况,由训练样本分布随机梯度下降可达到的区域的集合会变得更小。早期训练的小扰动使得模型参数从一个盆转换到附近的一个,然而后来(通常用于较大的参数值)似乎很难逃脱这样的一个吸引盆。因此早期的样本有更大的影响,而且在实践中,在对于训练样本特定和任意排序的特定参数空间区域诱捕模型参数。这个现象的一个重要结论是即使面对大量的监督数据,在早期的训练过程中,随机梯度下降法受到一定程度的过拟合训练数据的影响。在这层意义上,无监督预训练与优化过程相互作用密切,而且当训练样本的数量非常大的时候,无监督预训练的积极影响不仅体现在泛化误差,还体现在泛化误差上。
- 无监督预训练的正则化作用
正如前言所述,通过在监督微调训练过程前引入逐层贪婪预训练可以克服深度学习的挑战。正则化效果是预训练过程的结果,建立在参数空间内部区域微调过程的初始化点,在参数空间中参数从此受限。参数被限制到相对小体积的参数空间中,这个空间描述为监督微调代价函数局部吸引盆的边界。
预训练过程增加了权重的大小,且在标准的深层模型中采用S非线性和更多的拓扑特征如峰、谷和平稳,可以使得函数更非线性和本地代价函数更复杂。这些拓扑特性的存在使得本地参数空间通过梯度下降过程更难达到有效的距离。这是预训练过程所施加的限制属性的核心,是正则化特性的基础。
但是无监督预训练限制参数到特定区域:捕获输入分布结构P(X)。预训练作为正则化,在一定程度上削弱了其有效性。并不是所有的正则化矩阵都是平等的,相比于标准的正则化如L1和L2参数惩罚项,无监督预训练有意想不到的效果。我们认为它的成功归功于无监督预训练过程中无监督训练标准的优化。
在贪婪无监督训练的每个阶段,每层被训练来表示数据变化现存的主导因素。在每层,根据X的统计可靠特征来预测输出Y。这个观点使得非监督预训练与半监督的学习策略方法一致。正如最近其他的研究成果一样,我们在正则化模型参数中来证明半监督思想的有效性,无监督预训练的限制范围为学习P(X)有助于学习P(Y|X)。我们发现X的变形-学习的特征-是P(X)中预测的变化的主要因素,当预训练有效,这些X学习到的特征也可以预测Y。在深度学习的背景下,贪婪无监督策略可能也有特殊函数。在一定程度上,通过引入一个代理标准解决了不同层同时学习参数(在第2部分提到过)的问题。这个代理标准鼓励输入数据变化的显著因素,以便于在中间层显示。
为了说明这段推理,我们引入了参数的先验分布来使无监督预训练的效果形式化。我们假设参数选定在有界区域 S ⊂ R d S\subset \mathbb R^{d} S⊂Rd。让S 在区域 { R k } \{R_{k}\} {Rk}中分割,该区域是在训练误差中下降过程的吸引盆(basins)(注意 { R k } \{R_{k}\} {Rk}依赖于训练集,随着实例的增加依赖性降低)。对于i,j不相等,我们有 ∪ k R k = S \cup_{k}R_{k}=S ∪kRk=S以及 R i ∩ R j = 0 R_{i}\cap R_{j}=0 Ri∩Rj=0。 v k = ∫ 1 θ ∈ R k d θ v_{k}=\int1_{\theta\in R_{k}}d\theta vk=∫1θ∈Rkdθ表示区域 R k R_{k} Rk的体积(θ是模型参数)。 r k r_{k} rk是 R k R_{k} Rk中纯随机初始化的概率, π k \pi_{k} πk是 R k R_{k} Rk中预训练的概率,即 ∑ k r k = ∑ k π k = 1 \sum_{k}r_{k}=\sum_{k}\pi_{k}=1 ∑krk=∑kπk=1。我们考虑初始化过程为正则化项:
r e g u l a r i z e r = − l o g P ( θ ) . regularizer = − log P(θ). regularizer=−logP(θ).
对于预训练模型,先验概率为:
P p r e − t r a i n i n g ( θ ) = ∑ k 1 θ ∈ R k π k / v k . P_{pre−training}(\theta)=\sum_{k}1_{\theta\in R_{k}}\pi_{k}/v_{k}. Ppre−training(θ)=k∑1θ∈Rkπk/vk.
对于没有预训练的模型,先验概率为:
P n o − p r e − t r a i n i n g ( θ ) = ∑ k 1 θ ∈ R k r k / v k . P_{no-pre−training}(\theta)=\sum_{k}1_{\theta\in R_{k}}r_{k}/v_{k}. Pno−pre−training(θ)=k∑1θ∈Rkrk/vk.
我们可以证明 P p r e − t r a i n i n g ( θ ∈ R k ) = π k P_{pre−training}(\theta\in R_{k})=\pi_{k} Ppre−training(θ∈Rk)=πk, P n o − p r e − t r a i n i n g ( θ ∈ R k ) = r k P_{no-pre−training}(\theta\in R_{k})=r_{k} Pno−pre−training(θ∈Rk)=rk。当 π k \pi_{k} πk非常小,无监督预训练中惩罚项很高。正则化的导数几乎处处为0,因为我们在区域中选择了统一的先验概率。因此考虑正则化和生成模型 P p r e − t r a i n i n g ( θ ) P_{pre−training}(\theta) Ppre−training(θ),需要选择一个合理的初始化点 θ \theta θ(从这个点开始,在训练标准的迭代最小化中,惩罚项不会增加),这就是我们实验中预训练模型是怎样构建的。
注意形式化只是一个说明:我们只是简单展示一下如何概念性的考虑初始化点的正则化作用,而不能认为是正则化实现的文字解释,因为我们没有计算 π k \pi_{k} πk的解析式。相反,这些是无监督预训练过程的隐函数。
- 之前相关的工作
我们先回顾一下文献中的半监督学习(SSL),因为SSL框架也是我们所研究的。
4.1 相关半监督方法
人们认为生成模型比判别模型更不容易过拟合(Ng, 2002)。考虑输入变量X和目标变量Y,判别模型关注P(Y|X),生成模型关注P(X, Y)(经常参数化为P(X|Y) P(Y)),也就是说它也关注P(X)的正确性,因为当最终目标只是给定X 预测Y,P(X)可以减少拟合数据的自由度。
探索P(X)的信息可以提高分类的泛化,已经成为半监督学习之后的另一类思想(Chapelle, 2006)。例如,我们可以采用无监督学习将X映射为一个表示法(也叫嵌入),例如两个实例X1和X2属于相同的群集,那么它们最终会有相近的嵌入。然后在那个新的空间使用监督学习(例如线性分类器),并在很多情况下获得更好的泛化性能(Belkin, 2002)。这种方法采用主成分分析作为分类器前的一个预处理步骤。在这些模型中,首先采用无监督学习将数据转换为新的表示,然后采用监督学习分类器,学习将数据的新表示形式映射到类预测。
可以考虑 P ( X ) P(X) P(X)(或 P ( X , Y ) P(X,Y) P(X,Y))和 P ( Y ∣ X ) P(Y|X) P(Y∣X)共享参数(或其参数以某种方式连接)的模型,而不是在模型中使用单独的无监督和监督组件,并且可以将监督标准 − l o g P ( Y ∣ X ) -logP(Y|X) −logP(Y∣X)与无监督或生成的标准( − l o g P ( X ) −logP(X) −logP(X) or − l o g P ( X , Y ) −logP(X,Y) −logP(X,Y))进行权衡。然后可以看出,生成标准对应于先验的特定形式(Lasserre et al., 2006),即 P ( X ) P(X) P(X)的结构以共享参数化捕获的方式连接到 P ( Y ∣ X ) P(Y|X) P(Y∣X)的结构。通过控制总标准中包含多少生成标准,可以找到比纯粹生成性或纯粹歧视性训练标准更好的权衡(Lasserre et al., 2006; Larochelle and Bengio, 2008)。
在深层结构中,一个非常有趣的应用是将每层无监督嵌入准则加到传统的监督训练(Weston, 2008)。这就是一个强大的半监督策略,也是本文中描述和评估的一种替代算法,组合了无监督学习和监督学习。
在缺乏标签数据(充足的无标签数据)的情况下,深层结构表现突出。Salakhutdinov and Hinton (2008)提出了学习高斯过程协方差矩阵的思想,使用无标签数据模型化 P ( X ) P(X) P(X)对提高 P ( Y ∣ X ) P(Y|X) P(Y∣X)的效果非常明显。注意结果是预料的:用少量的标签样本建模 P ( X ) P(X) P(X)很有帮助。我们的结果显示即使有丰富的标签数据,无监督预训练仍对泛化有明显的积极影响:一个有点令人吃惊的结论。
4.2 过早停止(Early Stopping)是正则化的一种形式
我们认为预训练作为初始化可以看作将优化过程限制在一个相对小体积的参数空间中,相当于监督代价函数的局部吸引盆(basin of attraction)。限制初始化过程到参数空间中靠近初始配置的区域,过早停止和其有相似的影响。 τ \tau τ表示迭代的次数, η \eta η表示更新过程中的学习率, τ η \tau\eta τη可被视为正则化参数的倒数。事实上,限制了参数空间中从起始点可达区域的数量。至于使用二次误差函数和简单梯度下降的简单线性模型(初始化在原点)的优化,过早停止与传统的正则化有相同的作用。
因此,在预训练和过早停止中,监督代价函数参数限制接近它们的初始值。更正式的正则化过早停止处理由Sjöberg and Ljung (1995)提出。与预训练处理不相同,本文阐明了深层结构中初始化的效果。
- 实验装置和方法论
在这部分,我们会描述用来测量第3部分和之前提出的假设的实验装置。这部分描述了使用的深层结构、数据集和重现我们结果的必要细节。
5.1 模型
所有文献中训练深层结构的方法都有一些共同点:他们依赖无监督学习算法在每层提供一个训练信号。主要工作分为两个阶段。第一阶段,无监督预训练,所有层均采用逐层无监督学习信号来初始化。第二阶段,微调,全局训练标准(criterion)(预测误差,在监督任务下使用标签)最小化。在最初提出的算法中(Hinton, 2006; Bengio, 2007; Ranzato, 2007),无监督预训练采用逐层贪婪:在第k阶段,第k层训练采用前一层的输出作为输入,且前一层保持固定。
我们将考虑深度学习文献中两个具有代表性的深层结构。
5.1.1 深度置信网络(DBN)
第一个模型是Hinton等人的Deep Belief Net(DBN)(2006年),它通过贪婪的方式训练并堆叠几层受限玻尔兹曼机(RBM)获得。一旦训练了这个RBM堆栈,它就可以用于初始化多层神经网络以进行分类。
具有n个隐藏单元的RBM是用于隐藏变量 h i h_{i} hi和观测变量 x j x_{j} xj之间的联合分布的马尔可夫随机场(MRF),使得 P ( h ∣ x ) P(h|x) P(h∣x)和 P ( x ∣ h ) P(x|h) P(x∣h)得以分解,即 P ( h ∣ x ) = ∏ i P ( h i ∣ x ) P(h|x)=\prod_{i}P(h_{i}|x) P(h∣x)=∏iP(hi∣x)和 P ( x ∣ h ) = ∏ j P ( x j ∣ h ) P(x|h)=\prod_{j}P(x_{j}|h) P(x∣h)=∏jP(xj∣h)。 MRF的充分统计通常是 h i h_{i} hi, x j x_{j} xj和 h i x j h_{i}x_{j} hixj,其构成以下联合分布:
P ( x , h ) ∝ e h ′ W x + b ′ x + c ′ h P(x,h)\varpropto e^{h'Wx+b'x+c'h} P(x,h)∝eh′Wx+b′x+c′h
其中相应的参数 θ = ( W , b , c ) θ=(W,b,c) θ=(W,b,c)(其中 ′ ' ′ 表示转置, c i c_{i} ci与 h i h_{i} hi相关联, b j b_{j} bj与 x j x_{j} xj相关,而 W i j W_{ij} Wij与 h i x j h_{i}x_{j} hixj相关)。如果我们将 h i h_{i} hi和 x j x_{j} xj限制为二元单元(binary units),则可以得到:
P ( x ∣ h ) = ∏ j P ( x j ∣ h ) w i t h P(x|h)=\prod_{j}P(x_{j}|h)\ \ \ \ with P(x∣h)=j∏P(xj∣h) with
P ( x j = 1 ∣ h ) = s i g m o i d ( b j + ∑ i W i j h i ) P(x_{j}=1|h)=sigmoid(b_{j}+\sum_{i}W_{ij}h_{i}) P(xj=1∣h)=sigmoid(bj+i∑Wijhi)
其中, s i g m o i d ( a ) = 1 / ( 1 + e x p ( − a ) ) sigmoid(a)=1/(1+exp(-a)) sigmoid(a)=1/(1+exp(−a))(applied element-wise on a vector a),并且P(h|x)还有一个相似形式:
P ( h ∣ x ) = ∏ i P ( h i ∣ x ) w i t h P(h|x)=\prod_{i}P(h_{i}|x)\ \ \ \ with P(h∣x)=i∏P(hi∣x) with
P ( h i = 1 ∣ x ) = s i g m o i d ( c i + ∑ j W i j x j ) P(h_{i}=1|x)=sigmoid(c_{i}+\sum_{j}W_{ij}x_{j}) P(hi=1∣x)=sigmoid(ci+j∑Wijxj)
除了二项式之外,RBM形式可以推广到其他条件分布,包括连续变量。 Welling等人(2005)描述了RBM模型对指数族条件分布的推广。
可以通过近似随机梯度下降(Approximate Stochastic Gradient Descent)来训练RBM模型。虽然P(x)在RBM中不易被处理,但对比差异估计(Contrastive Divergence estimator)(Hinton,2002)是 ∂ l o g P ( x ) ∂ θ \frac{\partial logP(x)}{\partial \theta} ∂θ∂logP(x)的一个很好的随机近似,因为它经常具有相同的符号(Bengio和Delalleau,2009)。
DBN是一个多层生成模型,层变量为 h 0 h_{0} h0(输入或可见层), h 1 h_{1} h1, h 2 h_{2} h2等。前两层的联合分布为RBM, P ( h k ∣ h k + 1 ) P(h_{k} | h_{k+1}) P(hk∣hk+1)以与RBM相同的方式进行参数化。因此,2层DBN是RBM,并且RBM的堆栈与相应的DBN共享参数化。对比分歧(The Contrastive Divergence)更新方向可用于将DBN的每个层初始化为RBM,如下所述。考虑训练为具有隐藏层 h 1 h_{1} h1和可见层 v 1 v_{1} v1的RBM P 1 P_{1} P1的DBN的第一层。我们可以训练第二个RBM P 2 P_{2} P2,当从训练数据集中采样 v 1 v_{1} v1时,该第二个RBM P 2 P_{2} P2模拟(在其可见层中)来自 P 1 ( h 1 ∣ v 1 ) P_{1}(h_{1} | v_{1}) P1(h1∣v1)的样本 h 1 h_{1} h1。可以证明,这最大化了DBN的对数似然的下限。可以贪婪地增加层数,将新添加的顶层训练为RBM,以通过连接较低层的后验 P ( h k ∣ h k − 1 ) P(h_{k} | h_{k-1}) P(hk∣hk−1)产生的样本来进行建模(从训练数据集中的 h 0 h_{0} h0开始) 。
DBN或RBM堆栈的参数也对应于确定的前馈多层神经网络的参数。神经网络的第k层的第i个单元使用DBN的第k层的参数 c k c_{k} ck和 W k W_{k} Wk输出 h ^ k i = s i g m o i d ( c k i + ∑ j W k i j h ^ k − 1 , j ) \hat{h}_{ki}=sigmoid(c_{ki}+\sum_{j}W_{kij}\hat{h}_{k-1,j}) h^ki=sigmoid(cki+∑jWkijh^k−1,j)。因此,一旦训练了RBM堆栈或DBN,就可以使用这些参数来初始化相应的多层神经网络的第一层。可以添加一个或多个附加层以将顶层特征 h k h_{k} hk映射到与目标变量相关联的预测上(这里是与分类任务中的每个类相关联的概率)。 Bengio(2009)提供了有关RBM和DBN的更多细节,以及相关模型和深层架构的调查。
5.1.2 堆叠降噪自动编码器(Stacked Denoising Auto-Encoders, SDAE)
第二个模型是Vincent(2008)提出的堆叠降噪自动编码器,采用了DBN的贪婪原则,但是使用降噪自动编码器作为无监督模型的框架。自动编码器的编码器 h ( ⋅ ) h(\cdot) h(⋅)和解码器 g ( ⋅ ) g(\cdot) g(⋅)的结合可以确定训练集中的样本,即满足 g ( h ( x ) ) ≈ x g(h(x))\approx x g(h(x))≈x,其中,x是训练数据。
假设有一些限制条件阻止 g ( h ( ⋅ ) ) g(h(\cdot)) g(h(⋅))确定任意参数,自动编码器需要捕获训练集中的统计结构来最小化重建误差。然而,对于高容量的代码(h(x)维数多),自动编码器可以学习到一个简单的编码。注意到,最小化自动编码器的重建误差和RBM训练的对比分歧有一个亲密的关联:二者均可以近似对数似然梯度(Bengio, 2009)。
降噪自动编码器(Vincent, 2008)是普通自动编码器的随机变量,即使在高容量模型中,它也不能学习恒等映射。降噪自动编码器可以对输入的破损数据进行降噪,训练标准可以认为是特定生成模型的似然函数的变分下界。它已经被证明性能明显比普通自动编码器好,在深层监督结构中与RBM性能相似或者更好(Vincent, 2008)。另一种方法限制自动编码器的编码单元比输入的方式:通过编码稀疏来限制容量(Ranzato, 2008)。
我们现在总结堆叠去噪自动编码器的训练算法。 Vincent等人(2008)给出了更多详细信息。每个去噪自动编码器都在其输入x上运行,可以是原始输入,也可以是前一层的输出。去噪自动编码器经过训练,以便从随机破坏(嘈杂)的变换中重建x。每个去噪自动编码器的输出是“代码矢量” h ( x ) h(x) h(x),不要与通过将解码器应用于该代码矢量而获得的重建混淆。在我们的实验中, h ( x ) = s i g m o i d ( b + W x ) h(x)=sigmoid(b+Wx) h(x)=sigmoid(b+Wx)是普通的神经网络层,具有隐藏的单位偏差b和权重矩阵W。设 C ( x ) C(x) C(x)代表x的随机破坏(corruption)。正如Vincent等人(2008)所做的那样,我们设置 C i ( x ) = x i C_{i}(x) = x_{i} Ci(x)=xi或0,选择用于归零的随机子集(固定大小)。我们还考虑了盐和胡椒噪声(salt and pepper noise),我们选择固定大小的随机子集并设置 C i ( x ) = B e r n o u l l i ( 0.5 ) C_{i}(x) = Bernoulli(0.5) Ci(x)=Bernoulli(0.5)。去噪的“重建”是从 x ^ = s i g m o i d ( c + W T h ( C ( x ) ) ) \hat{x}=sigmoid(c+W^{T}h(C(x))) x^=sigmoid(c+WTh(C(x)))的噪声输入获得的,使用偏差c和馈送的转置 - 前进重量(feedforward weights)W.在对图像的实验中,对于特定像素i的原始输入 x i x_{i} xi和其重建 x ^ i \hat{x}_{i} x^i都可以被解释为该像素的伯努利概率:在该位置将像素绘制为黑色的概率。我们用 C E ( x ∣ ∣ x ^ ) = ∑ i C E ( x i ∣ ∣ x ^ i ) CE(x||\hat{x}) = ∑_{i}CE(x_{i}||\hat{x}_{i}) CE(x∣∣x^)=∑iCE(xi∣∣x^i)表示与x的每个元素相关的伯努利概率分布与其重建概率 x ^ : C E ( x ∣ ∣ x ^ ) = − ∑ i ( x i l o g x ^ i + ( 1 − x i ) l o g ( 1 − x ^ i ) ) \hat{x}:CE(x||\hat{x}) = − ∑_{i}(x_{i} log \hat{x}_{i} + (1 − x_{i} ) log (1 − \hat{x}_{i})) x^:CE(x∣∣x^)=−∑i(xilogx^i+(1−xi)log(1−x^i))之间的分量交叉熵的总和。当输入分量及其重构在[0,1]时,伯努利模型才有意义;另一种选择是使用高斯模型,其对应于均方误差(MSE)标准。
对于DBN或SDAE,在无监督训练之后添加逻辑回归层作为输出。该层使用softmax(多项逻辑回归)单元来估计 P ( c l a s s ∣ x ) = s o f t m a x c l a s s ( a ) P(class|x)=softmax_{class}(a) P(class∣x)=softmaxclass(a),其中 a i a_{i} ai是来自顶部隐藏层的输出的线性组合。然后像往常一样训练整个网络用于多层感知器,以最小化输出(负对数似然)预测误差。
5.2 数据集
本文实验基于3个数据集,我们的实验结果将有助理解之前深层结构的结果,大部分基于MNIST数据集和其变形:
- MNIST
LeCun(1998)提出的数字分类数据,包含了60000个训练样本和10000个测试样本,均为28*28灰度手写数字 - InfiniteMNIST
Loosli (2007)提出的数据集,是MNIST的扩展,可以获得恰似无限的样本。样本的获得是通过对原始的MNIST数字进行随机的弹性变形。在这个数据集,只有一组实例,我们将会比较模型的在线性能 - Shapeset
一个具有几何不变性的综合数据集,对10*10的三角形和正方形图像进行二元分类。实例显示图像的形状有很多变化,例如大小、方向和灰度级。数据集由50000训练、10000验证和10000测试图像组成。
5.3 设置
使用的模型有:
- 包含伯努利RBM层的DBN
- 基于伯努利输入单元的堆叠降噪自动编码器(SDAE)
- 标准前馈多层神经网络
每个模型均包含1-5个隐藏层,每个隐藏层都包含相同的隐藏单元,是一个超参数。其他超参数为无监督和监督学习率、L2惩罚项/权重衰减和SDAE中随机破损输入的百分数。对于MNIST,每层监督和无监督通过的数据为50。对于InfiniteMNIST,有250万无监督更新,然后是750万监督更新。标准前馈多层神经网络采用100万监督更新进行训练。对于MNIST,模型选择是根据能优化验证集中监督错误的超参数。对于InfiniteMNIST,超参数的选择是根据最后一百万样本的平均在线误差。所有的情况下均采用了纯随机梯度更新。
实验涉及对具有可变数量的层的深层架构的训练,其具有和不具有无监督的预训练。对于给定层,使用来自均匀 [ − 1 / k , 1 / k ] [-1/\sqrt{k},1/\sqrt{k}] [−1/k,1/k]的随机样本初始化权重,其中k是某一个单元从前一层(the fan-in)接收的连接数。接下来是监督梯度下降或无监督预训练。
在大多数情况下(MNIST),我们首先做了一组实验,采用10个不同的随机初始化种子计算超参数值的向量积,然后根据有/无预训练模型、层数和训练标准数,选出验证误差最小的超参数。基于这些超参数,我们又采用额外的400个初始化种子做实验。对于InfiniteMNIST,只考虑一个随机选择的种子。
在接下来的讨论中我们会经常用到一个词:明显的局部最小值,意味着当通过随机梯度下降法再有明显的进步,训练结束后得到的解决方案。可能这不是真正的局部最小值(可能会有一个小小的峡谷朝着显着的改善,不能通过梯度下降进入),但是很明显这些终止点代表着梯度下降“卡/陷”在了某一区域。同时要注意,我们所说的层数是指网络中的隐藏层数。
- 无监督预训练的效果
我们首先会呈现大量的仿真实验,来证实之前所说的关于深层结构的结论。在分析实验结果的过程中,我们开始关联本文的假设,然后针对本文假设做实验。
6.1 更好的泛化
当我们选择每层的单元数、学习速率和训练迭代次数来优化验证集中分类误差,相比于没有预训练、相同深度或较浅深度的比MNIST小的不同视觉数据集,无监督预训练大幅度减小了测试分类误差。
上述工作建立在一个或少量不同随机初始化种子,因此本文研究的其中一个目标就是确定当初始化一般神经网络(深或浅)和预训练过程的时候,使用随机种子产生的影响。为此,在MNIST数据集选择了50-400个不同的种子来获得图像。
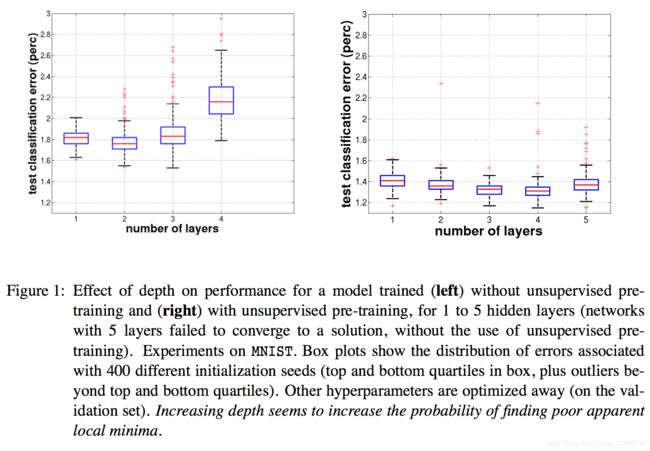
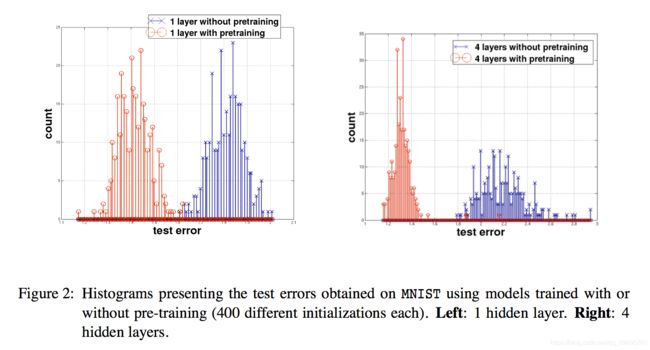
图1中显示了基于有/无预训练且增加网络的深度,测试分类误差的分布。图2中显示了1层和4层的分布直方图。在图1中,从1层到4层,无监督预训练使得分类误差稳步下降,然而没有预训练的误差在第2层后开始上升。我们应该注意到,如果不采用无监督预训练,无法有效训练第5层模型。无监督预训练的平均误差较低,且似乎对随机初始化有很强健壮性。无监督预训练在达到4隐层后方差仍保持相同水平,且离群的数量也增长缓慢。
形成鲜明对比的无预训练:当增加层数超过2后,方差和离群数量急剧增长。图2中显示,当我们增加层数,无监督预训练的效果更明显,随机初始化的健壮性也更好。无预训练更深层结构的误差方差和均值都增长,说明了当我们开始于随机初始化,增加深度意味着增加了找到差的明显局部最小值的可能性。还有一个很有趣的事,无监督预训练中采用400个种子得到低方差和小的传播误差:因此对于随机初始化种子,无监督预训练具有健壮性。
实验表明采用随机初始化种子,没有预训练最终的测试误差的方差较大,且对于更深结构效果会放大。我们同时也要注意到这项技术的成功有一个限制因素:在第5层性能下降。
6.2 特征可视化
图3显示了监督微调前/后DBN第一层的权重(滤波器)。为了可视化第2、3层单元的作用,我们使用了激活最大化技术(Erhan, 2009):为了可视化单元的最大响应,该思想通过寻找有界输入模式来最大化激活给定单元。这是一个优化问题,通过在输入空间中执行梯度上升算法来寻找激活函数的局部最大值。有趣的是,从大部分随机初始化的输入模式中可以获得几乎相同的最大激活函数输入模式。
作为比较,我们也做了无预训练网络1-3层滤波器可视化(图4)。第1层滤波器似乎与局部特征相关,2、3层则无法解释。定性地说,图3最下面一行的滤波器与图4有些相似,这是一个有趣的结论。此外,利用无监督预训练学习网络中的视觉特征似乎更有趣。
从图3中我们可以得到一些有趣的结论。首先,经过预训练的监督微调,即使有750万更新,也没有明显的改变权重(至少在视觉上):它们似乎“卡”在了一个特定的权重空间区域,监督微调后权重也没有明显改变(视觉上两行形式相同)。其次,不同层改变不同:第1层改变最少,监督训练对第3层影响更大。这些观察结果与我们的假设所做的预测一致:即随机梯度下降的早期dynamics,即无监督预训练引起的 dynamics,可以将训练锁定在参数空间的一个区域中,该区域对于以纯监督方式训练的模型来说基本上是不可接近的。
最后,增加更多层使得特征的复杂度增加。第1层权重编码基础检测器,第2层权重检测数字部分,第3层权重检测整个数字。当增加层数特征会更复杂,对于每个特征只用一幅图片来显示,这样不能处理好特征的非线性特性。例如,当特征高度活跃(或高度不活跃),它不能显示模式集。
图3、4显示了基于InfiniteMNIST的滤波器,与应用于MNIST的可视化类似。同样,SDAE获得的特征有类似定性的结论。

6.3 学习轨迹模型可视化
学习特征的可视化允许我们对深层结构的训练策略做定性的比较。然而我们无法调查这些策略是如何受随机初始化影响的,因为从多种初始化学习来的特征看起来都很相似。如果我们可以同时可视化多个模型,这样我们就可以探索我们的假设,且确认预训练模型和没有预训练的模型之间的区别。这两组模型在参数空间中覆盖的不同区域吗?参数轨迹会卡在很多明显不同的局部最小值吗?
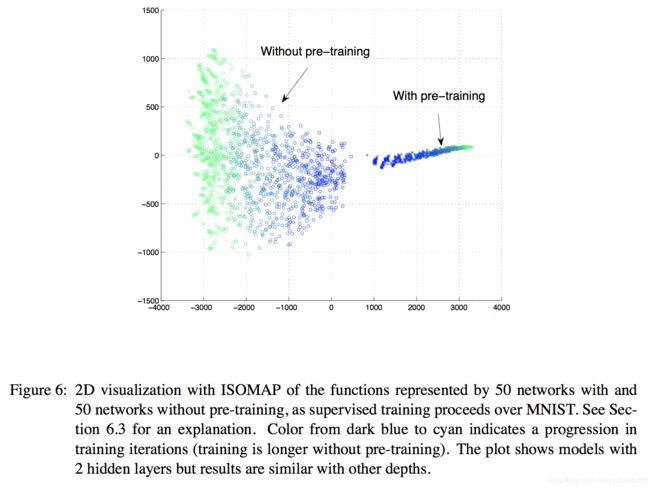
不幸的是,不可能直接比较两种结构的参数值,因为相同模型会采用很多相同参数的变换。然而,我们可以采用函数逼近方法来比较每个网络的函数(输入到输出),而不是比较参数。函数是对于所有的输入有无限有序输出值,可以用有限输入近似。为了可视化训练过程的轨迹,我们采用下面的步骤。对于一个给定的模型,我们计算和连接测试集的所有输出作为一个长向量,来总结它所在的“函数空间”。对于每个部分训练的模型都得到一个这样的向量。使用降维方法可以将这些向量映射到二维空间来实现可视化。图5和图6显示了使用降维技术得到的结果,分别得到局部和全局的结构。根据训练规则每个点均着色来帮助根据轨迹移动。
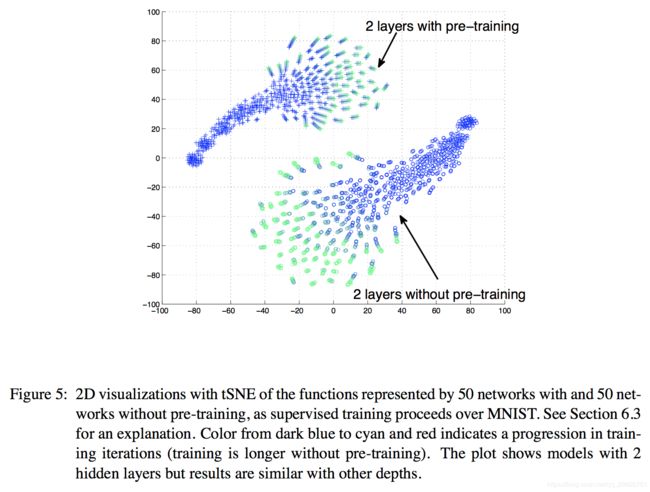
可视化得到的结论:
- 预训练和无预训练模型的开始和停滞(stay)在函数空间的不同区域;
- 局部结构的可视化(图5):给定模型(预训练和无预训练)的轨迹最初一起移动。然而在某一时刻(大约7之后),轨迹发散,且不会再互相靠近(无预训练模型更明显)。这表明每个轨迹都会移动到明显不同的局部最小值;
- 整体结构的可视化(图6):预训练模型与无预训练模型不相交,且区域小得多。事实上,从没有预训练的函数角度来看,预训练似乎一样,且训练期间他们的自相似性在增加(种子方差下降),这与第3部分预训练的形式一致,即我们描述了观测无监督预训练的正则化作用的理论依据,在这里,预训练参数落在吸引盆的概率很小。
训练轨迹的可视化似乎证实了我们的猜想。很难保证每条轨迹都在不同的局部最小值结束(对不同的参数和不同的函数)。
我们也分析了训练结束后的模型,可视化参数向量 附近的训练标准。通过随机采样方向v,画出 在v方向的训练标准,即 。其可视化如图7所示。误差无限近似二次函数,似乎在所有方向都有局部最小值,而不是鞍点或平原。通过计算黑塞矩阵,可以得到更明确的答案。图7显示了在无监督与训练下和更深层结构下,误差更小。

6.4 启示
到现在为止,一系列的结果与我们的假设相一致。预训练可以得到更好的泛化使得随机初始化具有鲁棒性,无监督学习P(X)有助于P(Y|X)的学习。我们所观测到的函数空间显示有很多明显的局部最小值。预训练模型似乎结束在这些误差空间的不同区域(参数空间的不同区域)。这个结果是从函数空间轨迹得到的,而且对于可视化学习特征,可以定性的观察到有/无预训练的模型有明显的不同。
- 无监督预训练的角色
目前本文可以证实,开始于预训练权重的监督优化比随机初始化权重能更好的进行分类。为了更好的理解这一优势从哪里来的,需要知道监督目标优化在两种情况下是一样的。基于梯度的优化过程也是一样的。唯一的不同点是参数空间中的起始点:随机选择还是经过无监督预训练后获得(也开始于随机初始化)。
深层结构建立于几层非线性组合,产生的误差面是非凸的,而且由于疑似存在很多局部最小值导致其很难优化。基于梯度的优化应该结束在明显的局部最小值(也可从上面的可视化得到),无论我们从吸引盆(basin of attraction)的哪里开始。从这个角度来讲,无监督预训练的优势为放置于吸引盆(basin of attraction)更深的参数空间区域,这比随机选择开始参数要好。这个优势可以实现更好的优化。
无监督预训练可能会将模型放置在训练误差并不比随机开始好(或更差)的参数空间区域,但是这也会得到更好的泛化(测试误差)。这个现象即为正则化的影响。注意这两种解释并不是相互排斥的。
最后,有一个很简单且很明显的解释:即监督训练开始时权重大小的不同(或者更通俗的说权重的边缘分布)。我们首先分析(排除)第一个假设。
7.1 实验1:无监督预训练对监督学习提供了一个更好的调整过程吗?
典型的深度模型梯度下降训练采用随机分配权重进行初始化,小到可以在参数空间的线性区域(对于大部分神经网络和DBN模型接近为0)。我们有理由质疑是否最初的无监督预训练阶段的优势只是由于权重更大,因此在某种意义上提供了优化过程更好的调整的初始值,我们想排除这个可能性。
通过调整,我们从初始的权重求得范围和边缘分布的平均值。换言之,如果我们仍采用独立的初始权重,但是使用一个更合适的分布而不是均匀分布 ,这样我们能得到与无监督预训练相同的优势吗?为了证明上述猜想,我们计算了无监督预训练中每层受训的权重和偏差的边缘直方图。根据这些直方图我们重新采样得到初始随机权重,并进行微调。结果显示参数与无监督预训练得到参数有相同的边缘统计特性,但是不一样的联合分布。
想象两个场景。第一个场景,边缘初始化比标准初始化(无预训练)有明显更好的性能。这就意味着无监督预训练可以提供更好的权重边缘条件。第二个场景,相比于无预训练,边缘使得性能更相近或更差。
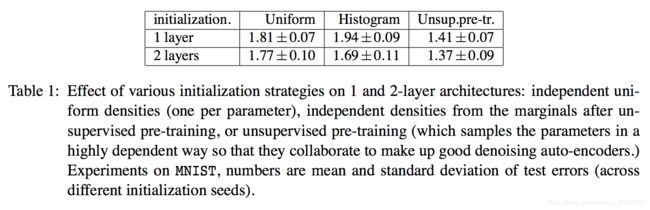
我们观察表1可以发现结论属于第一种场景。然而,对于基于MNIST的2个隐藏层,在预训练结束后初始化权重匹配的边缘分布似乎稍微提高了泛化误差,差别并不明显,对有/无预训练的结果影响不大。
实验结果推翻了预处理假设,但并不排除优化假设和正则化假设。
7.2 实验2:预训练对训练误差的影响
优化和正则化假设在预测无监督预训练如何影响训练误差方面是有分歧的:前者预测无监督预训练会导致较低的训练误差,然后后者的预测是相反的。为了验证这两种假设的影响,我们来看一下基于训练代价函数的测试代价(测试数据的福对数似然函数),即优化过程中参数空间的轨迹。图8显示了参数空间中开始于同一随机初始化点的400条曲线,即蓝色的无预训练,红色的有预训练。
实验基于网络的1/2/3隐藏层。正如图8所示,1个隐藏层时,无监督预训练有更小的训练代价,暗示着有更好的优化,对深层网络并不一定成立。可以观察到,相同的训练代价,预训练模型比随机初始化模型有更低的测试代价。因此,优势是一种更好的泛化而不是仅仅一个更好的优化过程。
因此得到如下结论:无监督预训练和正则化有相同的影响,或参数好的“prior”,即使在优化代价中没有明显的正则化术语。正如假设中所说,可以推断在无监督预训练标准(SDAE)中,限制参数空间中可能的起始点对限制最后的配置参数值有影响。像一般的正则化矩阵,无监督预训练因此被视为减少方差和引入偏差。与一般的正则化矩阵不同,无监督预训练有依赖数据行为。

7.3 实验3:层数的影响
正则化的另外一个本质特征是容量(例如隐藏单元数)增加,正则化效果增加,有效地将模型复杂度约束转换为另外一个。在这个实验中我们探索每层的单元数和无监督预训练效果之间的关系。无监督预训练正则化作用的假设使得当每层单元数增加的时候,我们会看到无监督预训练有效性有增加的趋势。
我们采用MNIST训练模型进行有/无预训练,过程增加层数量:每层25,50,100,200,400,800个单元,结果如图9所示。在SDAE中,我们期望降噪预训练过程何以帮助多层分类,因为降噪预训练在层比输入大的时候,允许在过完成的情况下学习有用的表达(Vincent, 2008)。我们观察到的是一个更系统的结果:无监督预训练对多层和更深层网络有帮助,但它似乎对太小的网络有伤害。
图9还显示DBN在性质上与SDAE一样,在某种意义上,具有较小层的无监督预训练架构会损害性能。 InfiniteMNIST上的实验揭示了定性相同的结果。这样的实验似乎指向了对正则化假设的重新验证。在这种情况下,无人监督的预训练似乎是DBN和SDAE模型的附加正则化器 - 除了隐藏层的小尺寸提供的正则化之外。随着模型大小从800个隐藏单元减少,泛化误差增加,并且随着无监督预训练而增加更多可能是因为额外的正则化效应:小网络已经具有有限的容量,因此进一步限制(或引入额外的偏见)它可能损害泛化。这样的结果似乎与纯粹的优化效果不相容。我们还获得了DBN和SDAE似乎与训练前策略具有定性相似效果的结果。

该影响可以解释为,无监督预训练作为提高输入变换的角色,可以有效捕获输入分布P(X)的主要变量。可能只有小部分变量与预测类标签Y有关。当隐藏层很小,通过无监督预训练学习不太可能得到预测Y的变换。
7.4 实验4:挑战优化假设
实验1 – 3的结果与正规化假设是一致的,实验2 – 3似乎直接支持正则化假说。
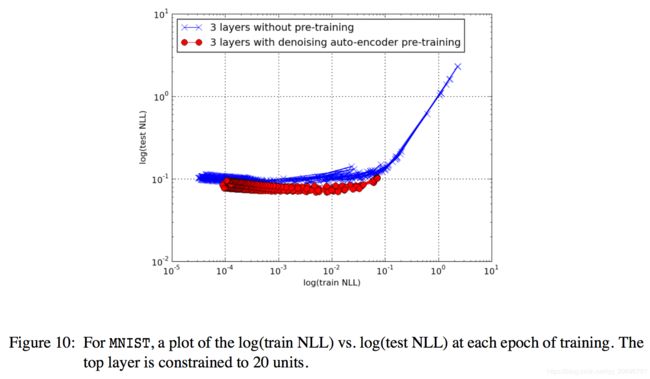
在文献中有一些支持优化的假设。Bengio(2007)限制深层网络的最顶层只有20个单元,然后测量了有/无预训练的训练误差。该思想是防止网络由于顶部隐藏层而过拟合训练误差,因此可以看出是否底层的优化影响是存在的。报告中训练和测试误差均比预训练网络低。存在一个问题就是他们使用了过早停止,这样是有问题的,因为正如之前所说,过早停止本身就是正则化,它可以影响训练误差。可以想象如果Bengio(2007)使得模型收敛,结果会不同。我们需要证明一下。
图10显示了没有过早停止产生的结果。尽管泛化误差较低,对于预训练网络训练误差仍旧较高。这个结果支持正则化假设,反对优化假设。可能发生的事:过早停止阻止了无预训练网络朝着明显的局部最小值移动太多。
7.5 实验5:对比预训练和L1/L2正则化
另外一种假设是经典的正则化可能和无监督预训练具有相同的影响。我们研究了没有预训练的网络采用L1/L2正则化的影响,发现基于MNIST的小惩罚起作用,但是增益远没有预训练大。对于InfiniteMNIST,L1/L2正则化的最佳值为0。
这不是一个完全令人惊讶的发现:并不是所有的正则化矩阵都是相等的,这与半监督训练的文献相一致,即无监督预训练可以被看作为正则化的一种特别有效的形式。
7.6 总结实验1-5
到目前为止,之前试验获得的结果对无监督预训练的影响有非常清晰的解释:正则化作用。我们可以看到采样使用相同的权重大小是不够的:无监督初始化是至关重要的。而且我们观察到,标准的L1/L2正则化达不到预训练的水平。
最引人注目的正则化假设的证据是图8和9,优化假设Bengio(2007)不成立。
- 在线学习设置
我们的假设不仅包括统计/现象学的假设:无监督预训练起正则化作用,也包含了一种机制:这样的行为出现也作为一系列训练动态性—在训练阶段和非凸监督目标函数中使用随机梯度。
在我们的假设中,我们提出早期的样例会引发权重大小的改变,增加网络的非线性,相反会减少随机梯度下降过程可得到的区域。这就意味着早期的样例决定着剩余训练样例的吸引盆;同时意味着早期的样例对训练模型的配置参数有不成比例的影响。
一个假设是是我们将会预测采用无限的或者非常大的数据集在线设置,无监督预训练的行为与标准的L1/L2正则化产生分歧。这是因为当数据增加时,标准的L1/L2正则化影响减小;然而当数据增加时,无监督预训练的影响保持不变。
需要注意在线学习的随机梯度下降是泛化误差的随机梯度下降优化,所以在线错误比较好意味着对于泛化误差优化的好。
在本部分,我们经验性地挑战一下这方面的假设,显示出证据支持我们的假设,即正则化。
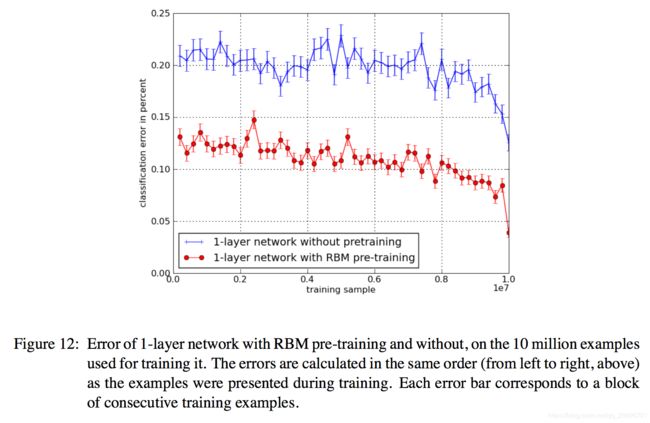
8.1 实验6:在大数据集下预训练的效果
本部分实验结果可能是这篇文章最惊人的发现。图11显示基于InifiteMNIST 6种结构的在线分类错误:1-3层DBN,1-3层SDAE,1-3层无预训练网络。
从这些实验中我们可以观察到以下几点。首先,无预训练的3层网络比无预训练的1层网络泛化误差较差。该现象证明了即使在线设置假设依旧成立,优化深层网络比浅层网络难。其次,3层SDAE模型比3层DBN模型泛化更好。最后且最重要,当训练样例数量增加,相反,预训练的优势不消失。
注意到每个模型的隐藏单元数都是一个超参数。所以理论结果显示,当容量和数据增加,1层无预训练网络原则上应该可以代表输入分布。相反,没有预训练,网络将不会利用额外的容量,这一现象再次指向了优化解释。然而很明显,非凸优化问题的起点很重要,即便对于那些看起来很容易优化的网络,这个现象支持我们的假设。

另外一个实验在图12中显示了大规模在线随机非凸优化的影响。基于InifiteMNIST,按照模型样例的顺序计算训练集的错误。我们观察到几个有趣的结论:首先,两种模型均更擅长分类更近可见的样例。这是拥有不变学习率的随机梯度下降的自然效应(指数的给最近的样例更大的权重)。同时,也要注意对于两种模型在训练开始的样例,就误差来说,本质上与测试样例类似。最后,我们观察到在训练集上,预训练模型整体表现更好。这与优化假设一致,即它表明无监督预训练有优化效果。
在线设置中,训练和泛化误差收敛,正如经验分布收敛于真是的数据分布。这些结果都表明随着数据集的增加,无监督预训练的影响不会消失。对于无监督预训练正则化作用,我们如果仅从表面理解,是预料不到这个结果的。然而它和我们对在线设置中无监督预训练基于非凸目标函数的随机梯度下降训练的解释相一致,阐明了我们的假设。
8.2 实验7:样例顺序的影响
本文假设的机制暗示着由于学习的动态性(权重大小的增加和训练过程的非线性),和依赖于吸引盆的早期数据(当基于随机梯度下降训练,早期样例敏感性增强)。基于InifiteMNIST我们操作于在线随机优化体制,在这我们试图找到一个高度非凸目标函数的局部最小值。然后,需要学习这种优化输出多大程度受训练过程中在不同点可见样例的影响,和是否早期样例有更大的影响。
为了量化训练过程中在不同点训练样例的输出方差,和比较有/无预训练模型的方差,我们进行了如下实验。给定100万样例的数据集,我们变化第100万个样例且保持其他不变。训练好10组模型后,测量出基于固定数据集网络的输出方差。接着同样改变下100万样例,观察哪组训练组对最终函数影响最大。
图13显示了实验结果,开始的样本比后面的样本更能影响网络的输出。然而,方差比预训练网络低。除此之外,我们应该注意到预训练网络的方差在0.25(开始预训练点)之后比监督网络在0.0的方差要小。这个结果意味着无监督预训练可以被视为一种方差减小技术,与正则化假设一致。最后,两个网络均受用于优化的最后一组样例的影响较大,这是由于在随机梯度中我们使用了固定学习率,最近期的样本梯度有更大的影响。
这些结果均与我们的假设一致:早期样本有更大的影响(方差更高),且预训练模型在我们的预期下可以减小方差。

8.3 实验8:预训练前k层
从图11我们可以看到对于3层网络无监督预训练的影响是不同的。在图14中,我们探索了深度和无监督预训练的关系,设置如下:基于MNIST和InifiteMNIST,我们只预训练底部k层,对顶部n-k层像平时一样随机初始化。在这个实验中,n=3且k从0(无预训练)变化到n(正常预训练)。
对于MNIST,我们画出了log(train NLL) vs. log(test NLL)的轨迹,每个点代表着一定数量epochs后的测量。轨迹大致从右到左、从上到下,对应着训练和测试误差的减少。我们也可以看到模型从某一点开始过拟合。

对于InifiteMNIST,优化低层/高层困难度的结果很模糊。我们预期最大增量增益来自于预训练的前1/2层,事实上对于前2层是成立的,对于1层是不成立的。但我们预训练更多层,模型的泛化更好。对于MNIST,预训练更多层,最终的训练误差变得更差。该现象同样支持正则化假设。
- 讨论和总结
我们已经证明无监督预训练可以增加深层网络的鲁棒性,结果同样显示增加无预训练结构的深度,会增加找到差的明显局部最小值的可能性。预训练网络可以始终有更好的泛化,预训练网络比没有预训练网络可以定性地学习到不同的特征。而且,拥有不同初始化种子的网络的轨迹似乎落入很多明显不同的局部最小值,结果再次不同,依赖于是否使用了预训练。
无监督预训练不单单只是一种能得到好的初始化边缘分布的方法,它还能捕获参数间复杂的依赖关系。我们发现有无监督预训练的深层网络似乎表现出一些正则化的特性:对于足够小的层数,预训练深层结构比随机初始化的深层结构更差。而且,当层数足够大,预训练模型的训练误差大,但是泛化性能好。此外,我们重做了一个实验,似乎可以得到无监督预训练的优化假设解释,但是相反我们观测到的是正则化影响。我们也展示了经典的正则化技术如L1/L2等达不到无监督预训练的效果,且随着数据的增加无监督预训练的效果不消失,所以如果无监督预训练是正则化器,那么它一定是截然不同的那种。
本文考虑了两种无监督预训练模型—降噪自动编码器和受限玻尔兹曼机,两种模型有相似的结果。我们很惊讶的观察到,即使在非常大的训练集中预训练的优势依旧存在,指出结论:非凸优化问题的开始点真的很重要,这个结论是通过观察不同层的可视化滤波器验证的。最后,无监督预训练作为方差减少技术,但是在大数据集中预训练网络有较低训练误差,这一结果支持优化解释。
我们如何理解所有这些结果?从表面上看,似乎正规化效应和看起来像优化效果之间的矛盾尚未得到解决。我们试图在第3节中描述一个假设,而不是坚持这些标签,这个假设在第3节中描述了使用两个阶段(无监督的预训练和监督微调)训练的体系结构中的学习动态,我们认为这是一致的具有以上所有结果。
这个假设表明,监督目标函数的非凸性存在consequences,我们在整个实验中以各种方式观察到了这一结果。其中一个后果是早期的例子对训练结果有很大的影响,这也是为什么在大规模设置中仍然存在无监督的预训练的效果的原因之一。在整篇文章中,我们深入研究了这样一种观点:从实际目的来看,早期例子(与无监督的预训练相结合)引起的吸引盆(basin of attraction)是一个监督训练无法逃脱的盆地(basin)。
从我们制作的各种可视化和性能评估中可以观察到这种效果。无监督的预训练作为仅影响监督训练起点的正则化因子,与经典正则指数相反,不会随着更多数据而消失(至少从我们的结果中可以看出)。基本上,无监督的预训练有利于隐藏单元,其计算输入X的特征,其对应于真实P(X)中的主要变化因子。假设这些中的一些近似特征可用于预测Y中的变化,则无监督预训练在低预测泛化误差的解附近建立参数。
我们的结果暗示的主要信息之一是,具有随机梯度下降的非凸目标函数的优化给分析带来了挑战,特别是在具有大量数据的区域中。到目前为止,我们的分析表明,在这种制度下接受过训练的网络可能会受到早期例子的影响。在我们希望我们的网络能够在后面的示例中捕获更多信息的情况下,即从非常大的数据集进行训练并尝试从中捕获大量信息时,这可能会带来问题。
一个有趣的实现是,通过一个小的训练集,我们通常不会非常重视最小化训练误差,因为过拟合是一个主要问题:训练误差不是区分两个模型的泛化性能的好方法。在该设置中,无监督的预训练有助于找到具有更好的泛化误差的明显的局部最小值。如图12所示,通过大型训练集,经验分布和真实分布收敛。在这种情况下,找到更好的明显局部最小值将是重要的,而更强(更好)的优化策略应该在训练集非常大时对泛化产生重大影响。另请注意,将我们的实验技术扩展到训练深度自动编码器(带瓶颈)的问题会很有意思,之前的结果(Hinton和Salakhutdinov,2006)表明,不仅测试误差而且训练误差大大降低通过无监督的预训练,这是优化效果的有力指标。我们假设瓶颈的存在是区分深度自动编码器和这里研究的深度分类器的关键因素。
尽管专门用于这里描述的实验的集群有几个月的CPU时间(比这个领域的大多数先前工作多了几个数量级),但是为了更好地理解这些影响,当然可以做更多的工作。我们最初的目标是通过良好控制的数据集进行良好控制的实验。它不是推进特定的算法,而是试图更好地理解其他地方已经充分记录的现象。尽管如此,我们的结果受到所使用数据集的限制,如果对其他数据进行相同的实验,则可以得出不同的结论。
我们的结果表明,深度网络中的优化是一个复杂的问题,在很大程度上受到训练期间早期实例的影响。未来的工作应该澄清这一假设。如果它是真的并且我们希望我们的学习者从非常大的训练集中捕获非常复杂的分布,那么可能意味着我们应该考虑学习算法来减少早期示例的影响,允许参数从当前的吸引子中逃脱学习动力卡住了。
这里报告的观察结果提供了比已经讨论过的更详细的解释,可以在未来的工作中进行测试。我们假设当我们从输入层到特征层次的更高层次时,输入分布中存在的变化因子越来越多地被解开。这与观察到在图像训练的DBN中几何变换不变性的观察结果是一致的(Goodfellow等,2009),以及通过从模型中抽样产生的输入图像的变化可视化(Hinton,2007; Susskind等人,2008),或考虑与不同深度的不同单位相关的优选输入(Lee et al。,2009; Erhan et al。,2009)。因此,在学习的早期阶段,上层(通常快速学习的那些层)将能够访问更稳健的输入表示,并且不太可能受到输入中存在的因素变化的纠缠的阻碍。如果这个假设是正确的,那将有助于解释无监督的预训练如何解决第2节中解释的鸡与蛋的问题:监督的深层架构的较低层需要上层来定义它们应该提取什么,反之亦然。相反,较低层可以提取变异因子的鲁棒和解开的表示,并且上层选择和组合适当的因子(有时不是全部在顶部隐藏层)。请注意,随着变化因素被解开,也可能发生其中一些不向上传播(在微调之前),因为RBM不会尝试在其隐藏层中表示独立的输入位。
为了进一步解释为什么较小的隐藏层在预训练时比没有训练后产生更差的性能(图9),人们可以进一步假设,对于某些数据集,P(X)中存在的主要变异因素(可能是在与随机投影16相比,较小的一层对Y的预测性较低,正是由于假设的解缠结效应。有了足够的隐藏单元,无监督的预训练可以在较大的学习特征集中提取一些高度预测Y(比随机预测更多)。这个额外的假设可以通过测量每个隐藏单元和对象类别之间的互信息来测试(由Lee等人,2009年完成),因为隐藏单元的数量是变化的(如图9所示)。当隐藏单元的数量太小时,预期具有最多互信息的单元将通过预训练提供较少信息,并且当隐藏单元的数量足够大时,预训练提供更多信息。
根据我们在第3节中提出的假设,下面的结果是不明确的:在图8(a)中,当只有一个隐藏层时,训练误差低于预训练,但是更多层更差。这可以通过以下附加假设来解释。虽然每个图层在其某些特征中提取有关Y的信息,但无法保证在移动到更高层时保留所有这些信息。人们可能会特别怀疑RBM,它不会在其隐藏层中编码任何输入位,这些输入位将略微独立于其他输入位,因为这些位将通过可见偏差来解释:Y与其他因素的完美解耦X中的变化可能会产生关于Y的边缘独立位。尽管有监督的微调应该有助于将该信息向输出层冒泡,但对于更深层的网络来说可能更难以解释,这解释了图8的上述特征。相反,在单个隐藏层的情况下,关于Y的较少信息将被丢弃(如果有的话),使得监督输出层的工作更容易。这与之前的结果(Larochelle等,2009)一致,表明对于多个数据集,当输出层仅从顶部隐藏层获取输入时,监督微调显着改善了分类误差。这个假设也与这里的观察结果一致(图1),无监督的预训练实际上对太深的网络没有帮助(并且可能会受到伤害)。
除了探索上述假设之外,未来的工作还应包括调查本文提出的结果与Hinton和Salakhutdinov(2006)之间的联系,其中似乎很难通过深度自动获得良好的训练重建误差。编码器(在无监督的环境中),不进行预训练。未来工作的其他途径包括分析和理解深度半监督技术,其中人们不会在预训练阶段和监督阶段之间分离,例如Weston等人(2008年)和Larochelle和Bengio(2008年)的工作。 这种算法更直接地落入半监督方法的领域。我们认为与我们所进行的分析类似的分析可能会更难,但也许也会呈现出来。
许多悬而未决的问题仍然存在于理解和改进深层架构。我们的信念是,在深层架构中设计改进的学习策略需要更深刻地理解我们面临的困难。这项工作有助于通过广泛的模拟得出这样的理解,并提出一个假设,解释无监督预训练背后的机制,这得到了我们的结果的充分支持。
参考文献:
Shun-ichi Amari, Noboru Murata, Klaus-Robert Mu ̈ller, Michael Finke, and Howard Hua Yang. Asymptotic statistical theory of overtraining and cross-validation. IEEE Transactions on Neural Networks, 8(5):985–996, 1997.
Lalit Bahl, Peter Brown, Peter deSouza, and Robert Mercer. Maximum mutual information es- timation of hidden markov parameters for speech recognition. In International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 49–52, Tokyo, Japan, 1986.
Andrew E. Barron. Complexity regularization with application to artificial neural networks. In G. Roussas, editor, Nonparametric Functional Estimation and Related Topics, pages 561–576. Kluwer Academic Publishers, 1991.
Mikhail Belkin and Partha Niyogi. Laplacian eigenmaps and spectral techniques for embedding and clustering. In T.G. Dietterich, S. Becker, and Z. Ghahramani, editors, Advances in Neural Information Processing Systems 14 (NIPS’01), Cambridge, MA, 2002. MIT Press.
Yoshua Bengio. Learning deep architectures for AI. Foundations and Trends in Machine Learning, 2(1):1–127, 2009. Also published as a book. Now Publishers, 2009.
Yoshua Bengio and Olivier Delalleau. Justifying and generalizing contrastive divergence. Neural Computation, 21(6):1601–1621, June 2009.
Yoshua Bengio and Yann LeCun. Scaling learning algorithms towards AI. In L. Bottou, O. Chapelle, D. DeCoste, and J. Weston, editors, Large Scale Kernel Machines, pages 321–360. MIT Press, 2007.
Yoshua Bengio, Olivier Delalleau, and Nicolas Le Roux. The curse of highly variable functions for local kernel machines. In Y. Weiss, B. Scho ̈lkopf, and J. Platt, editors, Advances in Neu- ral Information Processing Systems 18 (NIPS’05), pages 107–114. MIT Press, Cambridge, MA, 2006.
Yoshua Bengio, Pascal Lamblin, Dan Popovici, and Hugo Larochelle. Greedy layer-wise training of deep networks. In Bernhard Scho ̈lkopf, John Platt, and Thomas Hoffman, editors, Advances in Neural Information Processing Systems 19 (NIPS’06), pages 153–160. MIT Press, 2007.
Marc H. Bornstein. Sensitive periods in development : interdisciplinary perspectives / edited by Marc H. Bornstein. Lawrence Erlbaum Associates, Hillsdale, N.J. :, 1987.
Olivier Chapelle, Jason Weston, and Bernhard Scho ̈ lkopf. Cluster kernels for semi-supervised learn- ing. In S. Becker, S. Thrun, and K. Obermayer, editors, Advances in Neural Information Process- ing Systems 15 (NIPS’02), pages 585–592, Cambridge, MA, 2003. MIT Press.
Olivier Chapelle, Bernhard Scho ̈lkopf, and Alexander Zien. Semi-Supervised Learning. MIT Press, 2006.
Ronan Collobert and Jason Weston. A unified architecture for natural language processing: Deep neural networks with multitask learning. In William W. Cohen, Andrew McCallum, and Sam T. Roweis, editors, Proceedings of the Twenty-fifth International Conference on Machine Learning (ICML’08), pages 160–167. ACM, 2008.
Dumitru Erhan, Yoshua Bengio, Aaron Courville, and Pascal Vincent. Visualizing higher-layer features of a deep network. Technical Report 1341, Universite ́ de Montre ́al, 2009.
Patrick Gallinari, Yann LeCun, Sylvie Thiria, and Francoise Fogelman-Soulie. Memoires associa- tives distribuees. In Proceedings of COGNITIVA 87, Paris, La Villette, 1987.
Ian Goodfellow, Quoc Le, Andrew Saxe, and Andrew Ng. Measuring invariances in deep networks. In Y. Bengio, D. Schuurmans, J. Lafferty, C. K. I. Williams, and A. Culotta, editors, Advances in Neural Information Processing Systems 22, pages 646–654. 2009.
Raia Hadsell, Ayse Erkan, Pierre Sermanet, Marco Scoffier, Urs Muller, and Yann LeCun. Deep belief net learning in a long-range vision system for autonomous off-road driving. In Proc. Intelligent Robots and Systems (IROS’08), pages 628–633, 2008.
Johan Ha ̊stad. Almost optimal lower bounds for small depth circuits. In Proceedings of the 18th annual ACM Symposium on Theory of Computing, pages 6–20, Berkeley, California, 1986. ACM Press.
Johan Ha ̊stad and Mikael Goldmann. On the power of small-depth threshold circuits. Computa- tional Complexity, 1:113–129, 1991.
Geoffrey E. Hinton. Training products of experts by minimizing contrastive divergence. Neural Computation, 14:1771–1800, 2002.
Geoffrey E. Hinton. To recognize shapes, first learn to generate images. In Paul Cisek, Trevor Drew, and John Kalaska, editors, Computational Neuroscience: Theoretical Insights into Brain Function. Elsevier, 2007.
Geoffrey E. Hinton and Ruslan Salakhutdinov. Reducing the dimensionality of data with neural networks. Science, 313(5786):504–507, July 2006.
Goeffrey E. Hinton, Simon Osindero, and Yee Whye Teh. A fast learning algorithm for deep belief nets. Neural Computation, 18:1527–1554, 2006.
Hugo Larochelle and Yoshua Bengio. Classification using discriminative restricted Boltzmann ma- chines. In William W. Cohen, Andrew McCallum, and Sam T. Roweis, editors, Proceedings of the Twenty-fifth International Conference on Machine Learning (ICML’08), pages 536–543. ACM, 2008.
Hugo Larochelle, Dumitru Erhan, Aaron Courville, James Bergstra, and Yoshua Bengio. An em- pirical evaluation of deep architectures on problems with many factors of variation. In Int. Conf. Mach. Learn., pages 473–480, 2007.
Hugo Larochelle, Yoshua Bengio, Jerome Louradour, and Pascal Lamblin. Exploring strategies for training deep neural networks. The Journal of Machine Learning Research, 10:1–40, January 2009.
Julia A. Lasserre, Christopher M. Bishop, and Thomas P. Minka. Principled hybrids of generative and discriminative models. In Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR’06), pages 87–94, Washington, DC, USA, 2006. IEEE Computer Society.
Yann LeCun. Mode`les connexionistes de l’apprentissage. PhD thesis, Universite ́ de Paris VI, 1987.
Yann LeCun, Le ́on Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, 1998.
Honglak Lee, Chaitanya Ekanadham, and Andrew Ng. Sparse deep belief net model for visual area V2. In J.C. Platt, D. Koller, Y. Singer, and S. Roweis, editors, Advances in Neural Information Processing Systems 20 (NIPS’07), pages 873–880. MIT Press, Cambridge, MA, 2008.
Honglak Lee, Roger Grosse, Rajesh Ranganath, and Andrew Y. Ng. Convolutional deep belief networks for scalable unsupervised learning of hierarchical representations. In Le ́on Bottou and Michael Littman, editors, Proceedings of the Twenty-sixth International Conference on Machine Learning (ICML’09). ACM, Montreal (Qc), Canada, 2009.
Gae ̈lle Loosli, Ste ́phane Canu, and Le ́on Bottou. Training invariant support vector machines us- ing selective sampling. In Le ́on Bottou, Olivier Chapelle, Dennis DeCoste, and Jason Weston, editors, Large Scale Kernel Machines, pages 301–320. MIT Press, Cambridge, MA., 2007.
Hossein Mobahi, Ronan Collobert, and Jason Weston. Deep learning from temporal coherence in video. In Le ́on Bottou and Michael Littman, editors, Proceedings of the 26th International Conference on Machine Learning, pages 737–744, Montreal, June 2009. Omnipress.
Andrew Y. Ng and Michael I. Jordan. On discriminative vs. generative classifiers: A comparison of logistic regression and naive bayes. In T.G. Dietterich, S. Becker, and Z. Ghahramani, editors, Advances in Neural Information Processing Systems 14 (NIPS’01), pages 841–848, 2002.
Simon Osindero and Geoffrey E. Hinton. Modeling image patches with a directed hierarchy of markov random field. In J.C. Platt, D. Koller, Y. Singer, and S. Roweis, editors, Advances in Neural Information Processing Systems 20 (NIPS’07), pages 1121–1128, Cambridge, MA, 2008. MIT Press.
Dan Povey and Philip C. Woodland. Minimum phone error and i-smoothing for improved discrim- inative training. In Acoustics, Speech, and Signal Processing, 2002. Proceedings. (ICASSP ’02). IEEE International Conference on, volume 1, pages I–105–I–108 vol.1, 2002.
Marc’Aurelio Ranzato, Christopher Poultney, Sumit Chopra, and Yann LeCun. Efficient learning of sparse representations with an energy-based model. In B. Scho ̈lkopf, J. Platt, and T. Hoffman, editors, Advances in Neural Information Processing Systems 19 (NIPS’06), pages 1137–1144. MIT Press, 2007.
Marc’Aurelio Ranzato, Y-Lan Boureau, and Yann LeCun. Sparse feature learning for deep belief networks. In J.C. Platt, D. Koller, Y. Singer, and S. Roweis, editors, Advances in Neural Infor- mation Processing Systems 20 (NIPS’07), pages 1185–1192, Cambridge, MA, 2008. MIT Press.
Ruslan Salakhutdinov and Geoffrey E. Hinton. Using deep belief nets to learn covariance kernels for Gaussian processes. In J.C. Platt, D. Koller, Y. Singer, and S. Roweis, editors, Advances in Neural Information Processing Systems 20 (NIPS’07), pages 1249–1256, Cambridge, MA, 2008. MIT Press.
Ruslan Salakhutdinov and Geoffrey E. Hinton. Semantic hashing. In Proceedings of the 2007 Work- shop on Information Retrieval and applications of Graphical Models (SIGIR 2007), Amsterdam, 2007. Elsevier.
Ruslan Salakhutdinov, Andriy Mnih, and Geoffrey E. Hinton. Restricted Boltzmann machines for collaborative filtering. In Zoubin Ghahramani, editor, Proceedings of the Twenty-fourth Interna- tional Conference on Machine Learning (ICML’07), pages 791–798, New York, NY, USA, 2007. ACM.
Sebastian H. Seung. Learning continuous attractors in recurrent networks. In M.I. Jordan, M.J. Kearns, and S.A. Solla, editors, Advances in Neural Information Processing Systems 10 (NIPS’97), pages 654–660. MIT Press, 1998.
Jonas Sjo ̈berg and Lennart Ljung. Overtraining, regularization and searching for a minimum, with application to neural networks. International Journal of Control, 62(6):1391–1407, 1995.
Joshua M. Susskind, Geoffrey E., Javier R. Movellan, and Adam K. Anderson. Generating facial expressions with deep belief nets. In V. Kordic, editor, Affective Computing, Emotion Modelling, Synthesis and Recognition, pages 421–440. ARS Publishers, 2008.
Joshua Tenenbaum, Vin de Silva, and John C. Langford. A global geometric framework for nonlin- ear dimensionality reduction. Science, 290(5500):2319–2323, December 2000.
Laurens van der Maaten and Geoffrey E. Hinton. Visualizing data using t-sne. Journal of Machine Learning Research, 9:2579–2605, November 2008.
Pascal Vincent, Hugo Larochelle, Yoshua Bengio, and Pierre-Antoine Manzagol. Extracting and composing robust features with denoising autoencoders. In Andrew McCallum and Sam Roweis, editors, Proceedings of the 25th Annual International Conference on Machine Learning (ICML 2008), pages 1096–1103. Omnipress, 2008.
Max Welling, Michal Rosen-Zvi, and Geoffrey E. Hinton. Exponential family harmoniums with an application to information retrieval. In L.K. Saul, Y. Weiss, and L. Bottou, editors, Advances in Neural Information Processing Systems 17 (NIPS’04), pages 1481–1488, Cambridge, MA, 2005. MIT Press.
Jason Weston, Fre ́de ́ric Ratle, and Ronan Collobert. Deep learning via semi-supervised embed- ding. In William W. Cohen, Andrew McCallum, and Sam T. Roweis, editors, Proceedings of the Twenty-fifth International Conference on Machine Learning (ICML’08), pages 1168–1175, New York, NY, USA, 2008. ACM.
Andrew Yao. Separating the polynomial-time hierarchy by oracles. In Proceedings of the 26th Annual IEEE Symposium on Foundations of Computer Science, pages 1–10, 1985.
Long Zhu, Yuanhao Chen, and Alan Yuille. Unsupervised learning of probabilistic grammar-markov models for object categories. IEEE Transactions on Pattern Analysis and Machine Intelligence, 31(1):114–128, 2009.