HashMap实现原理
面试必考HashMap底层原理详解之手写实现自己的HashMap
redis 哈希一致性
还有很多数据结构都会有哈希算法
面试 提高逼格
还是自己去看一些框架底层 都可以看懂源码意思
举一个例子:
map.put(key value)
key多种混合类型 或者是对象
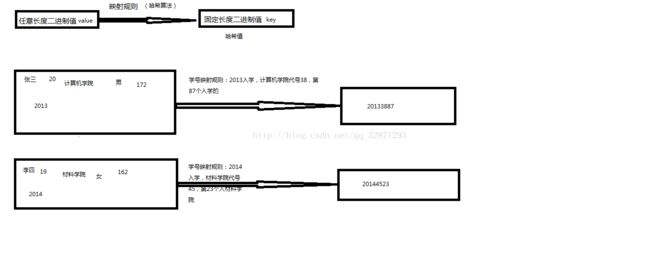
key 哈希算法(散列)到 Map底层去存储?
效果:(快存 快取 加快 效率)不像以前我们去存 要遍历 然后位置为空我们就存进去
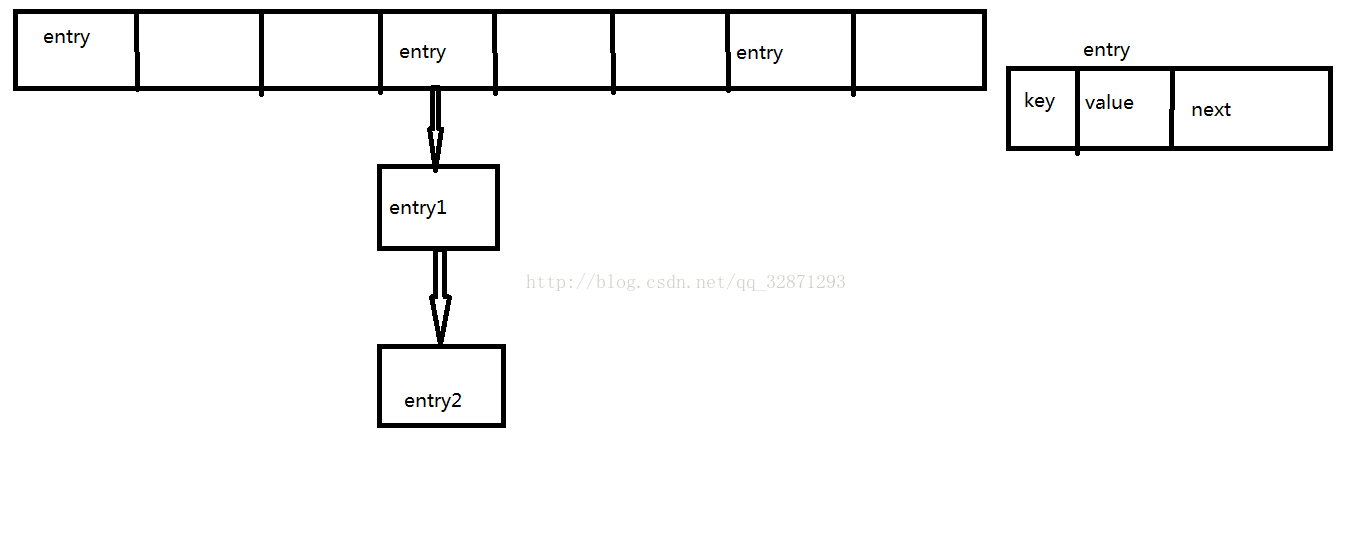
Map底层 实际上是 数组+链表形式
key 223 454 6676 4545
操作:(哈希算法)-->散列 ----把这些KEY 通过某些算法 将这些key 像天女散花 一样存在数组的各处
数组 位置 4 8 67 678 分散在数组各个位置
散列:就是来一个key 我就随便存一个数组上的位置 不是连续 非常散开
hash算法介绍:
1、hashcode取模法
key.hashcode() % table.length-1
2、平方取中法
哈希表处理冲突:
1、线形探测法 线性探测步长 2
2、链表形式解决冲突(因为不同的key 所存储的数组位置可能一样但是 这个位置下面挂的链表位置绝对不一样)
扩容:如果存个数大于 数组长度*负载因子
负载因子:负载的标准 0.75 我们就需要扩容
数组长度 * 3
我们需要再次散列 到新组数上面存储
自定义实现自己DNHasnMap
5 & 15 = 5 = index;
redis 哈希一致性
还有很多数据结构都会有哈希算法
面试 提高逼格
还是自己去看一些框架底层 都可以看懂源码意思
举一个例子:
map.put(key value)
key多种混合类型 或者是对象
key 哈希算法(散列)到 Map底层去存储?
效果:(快存 快取 加快 效率)不像以前我们去存 要遍历 然后位置为空我们就存进去
Map底层 实际上是 数组+链表形式
key 223 454 6676 4545
操作:(哈希算法)-->散列 ----把这些KEY 通过某些算法 将这些key 像天女散花 一样存在数组的各处
数组 位置 4 8 67 678 分散在数组各个位置
散列:就是来一个key 我就随便存一个数组上的位置 不是连续 非常散开
hash算法介绍:
1、hashcode取模法
key.hashcode() % table.length-1
2、平方取中法
哈希表处理冲突:
1、线形探测法 线性探测步长 2
2、链表形式解决冲突(因为不同的key 所存储的数组位置可能一样但是 这个位置下面挂的链表位置绝对不一样)
扩容:如果存个数大于 数组长度*负载因子
负载因子:负载的标准 0.75 我们就需要扩容
数组长度 * 3
我们需要再次散列 到新组数上面存储
自定义实现自己DNHasnMap
5 & 15 = 5 = index;
package DnHashMap;
public interface DNMap{
//快存 快取
public V put(K k,V v);
public V get(K k);
public int size();
//内部接口 定义数组里面存对象类型
public interface Entry{
public K getKey();
public V getValue();
}
}
public interface DNMap
//快存 快取
public V put(K k,V v);
public V get(K k);
public int size();
//内部接口 定义数组里面存对象类型
public interface Entry
public K getKey();
public V getValue();
}
}
package DnHashMap;
import java.util.ArrayList;
import java.util.List;
public class DNHashMap implements DNMap {
// 默认的数组大小
private static int defaulLength = 16;
// 扩容标准
private static double defaultAddSizeFactor = 0.75;
// 使用数组位置总数
private int size;
// 这个定义一个Entry类型的数组 int []
private Entry[] table = null;
// 构造方法
public DNHashMap() {
this(defaulLength, defaultAddSizeFactor);
}
public DNHashMap(int length, double defaultAddSizeFactor) {
if (length < 0) {
throw new IllegalArgumentException("参数不能为负数:" + length);
}
if (defaultAddSizeFactor <= 0 || Double.isNaN(defaultAddSizeFactor)) {
throw new IllegalArgumentException("扩容标准必须是大于0的数字:" + length);
}
this.defaulLength = length;
this.defaultAddSizeFactor = defaultAddSizeFactor;
table = new Entry[defaulLength];
}
// 快存 里面用到hash散列 不需要去遍历 直接找到位置存
public V put(K k, V v) {
if (size >= defaulLength * defaultAddSizeFactor) {
// 我么就需要扩容 扩容2倍
up2Size();
}
// 通过key 来确定存储到我们底层数组的位置
int index = getIndex(k, table.length);
Entry entry = table[index];
if (entry == null) {
table[index] = newEntry(k, v, null);
size++;
} else {
// 位置不为空 链表形式解决冲突
table[index] = newEntry(k, v, entry);
}
return table[index].getValue();
}
// 获取实例的方法
private DNHashMap.Entry newEntry(K k, V v, Entry next) {
// TODO Auto-generated method stub
return new Entry(k, v, next);
}
// 通过key 来确定存储到我们底层数组的位置
private int getIndex(K k, int length) {
// hashcode取模法
int m = length - 1;
// 5 & 15 = 5 = index;
int index = hash(k.hashCode()) & m;
// 还不放心
return index >= 0 ? index : -index;
}
// 这个就是我们现在最精髓的方法 index 位置保证放在我们的数组范围内
private int hash(int hashCode) {
hashCode = hashCode ^ ((hashCode >>> 20) ^ (hashCode >>> 12));
return hashCode ^ (hashCode >>> 7) ^ (hashCode >>> 4);
}
// 扩容2倍的方法
private void up2Size() {
Entry[] newTable = new Entry[2 * defaulLength];
// 我们需要把老数组table的存的Entry再重新散列到我们newTable
againHash(newTable);
}
private void againHash(Entry[] newTable) {
// 装Entry对象
List> entryList = new ArrayList>();
for (int i = 0; i < table.length; i++) {
if (table[i] == null) {
continue;
}
foundEntryByNext(table[i], entryList);
}
if (entryList.size() > 0) {
size = 0;
defaulLength = 2 * defaulLength;
table = newTable;
for (Entry entry : entryList) {
if (entry.next != null) {
// 从新散列之前将所有链表清空
entry.next = null;
}
put(entry.getKey(), entry.getValue());
}
}
}
// 寻找Entry 对象且 包括每个数组位置处链表的所有Entry 对象
private void foundEntryByNext(Entry entry, List.Entry> entryList) {
if (entry != null && entry.next != null) {
entryList.add(entry);
// 递归
foundEntryByNext(entry.next, entryList);
} else {
entryList.add(entry);
}
}
public V get(K k) {
// key 拿到数组下标位置的对象
int index = getIndex(k, table.length);
if (table[index] == null) {
return null;
}
return findVauleByEqualKey(k, table[index]);
}
private V findVauleByEqualKey(K k, DNHashMap.Entry entry) {
if (k == entry.getKey() || k.equals(entry.getKey())) {
return entry.getValue();
} else {
// 处理 不同的key 散列的位置是一样的 但是是通过链表分开
if (entry.next != null) {
return findVauleByEqualKey(k, entry.next);
}
}
return null;
}
public int size() {
// TODO Auto-generated method stub
return size;
}
class Entry implements DNMap.Entry {
K k;
V v;
// 这个就是存在next找到低下的Entry对象
Entry next;
public Entry(K k, V v, Entry next) {
this.k = k;
this.v = v;
this.next = next;
}
// 获取存到Entry对象里面的key value
public K getKey() {
// TODO Auto-generated method stub
return k;
}
public V getValue() {
// TODO Auto-generated method stub
return v;
}
}
}
import java.util.ArrayList;
import java.util.List;
public class DNHashMap
// 默认的数组大小
private static int defaulLength = 16;
// 扩容标准
private static double defaultAddSizeFactor = 0.75;
// 使用数组位置总数
private int size;
// 这个定义一个Entry类型的数组 int []
private Entry
// 构造方法
public DNHashMap() {
this(defaulLength, defaultAddSizeFactor);
}
public DNHashMap(int length, double defaultAddSizeFactor) {
if (length < 0) {
throw new IllegalArgumentException("参数不能为负数:" + length);
}
if (defaultAddSizeFactor <= 0 || Double.isNaN(defaultAddSizeFactor)) {
throw new IllegalArgumentException("扩容标准必须是大于0的数字:" + length);
}
this.defaulLength = length;
this.defaultAddSizeFactor = defaultAddSizeFactor;
table = new Entry[defaulLength];
}
// 快存 里面用到hash散列 不需要去遍历 直接找到位置存
public V put(K k, V v) {
if (size >= defaulLength * defaultAddSizeFactor) {
// 我么就需要扩容 扩容2倍
up2Size();
}
// 通过key 来确定存储到我们底层数组的位置
int index = getIndex(k, table.length);
Entry
if (entry == null) {
table[index] = newEntry(k, v, null);
size++;
} else {
// 位置不为空 链表形式解决冲突
table[index] = newEntry(k, v, entry);
}
return table[index].getValue();
}
// 获取实例的方法
private DNHashMap
// TODO Auto-generated method stub
return new Entry(k, v, next);
}
// 通过key 来确定存储到我们底层数组的位置
private int getIndex(K k, int length) {
// hashcode取模法
int m = length - 1;
// 5 & 15 = 5 = index;
int index = hash(k.hashCode()) & m;
// 还不放心
return index >= 0 ? index : -index;
}
// 这个就是我们现在最精髓的方法 index 位置保证放在我们的数组范围内
private int hash(int hashCode) {
hashCode = hashCode ^ ((hashCode >>> 20) ^ (hashCode >>> 12));
return hashCode ^ (hashCode >>> 7) ^ (hashCode >>> 4);
}
// 扩容2倍的方法
private void up2Size() {
Entry
// 我们需要把老数组table的存的Entry再重新散列到我们newTable
againHash(newTable);
}
private void againHash(Entry
// 装Entry对象
List
for (int i = 0; i < table.length; i++) {
if (table[i] == null) {
continue;
}
foundEntryByNext(table[i], entryList);
}
if (entryList.size() > 0) {
size = 0;
defaulLength = 2 * defaulLength;
table = newTable;
for (Entry
if (entry.next != null) {
// 从新散列之前将所有链表清空
entry.next = null;
}
put(entry.getKey(), entry.getValue());
}
}
}
// 寻找Entry 对象且 包括每个数组位置处链表的所有Entry 对象
private void foundEntryByNext(Entry
if (entry != null && entry.next != null) {
entryList.add(entry);
// 递归
foundEntryByNext(entry.next, entryList);
} else {
entryList.add(entry);
}
}
public V get(K k) {
// key 拿到数组下标位置的对象
int index = getIndex(k, table.length);
if (table[index] == null) {
return null;
}
return findVauleByEqualKey(k, table[index]);
}
private V findVauleByEqualKey(K k, DNHashMap
if (k == entry.getKey() || k.equals(entry.getKey())) {
return entry.getValue();
} else {
// 处理 不同的key 散列的位置是一样的 但是是通过链表分开
if (entry.next != null) {
return findVauleByEqualKey(k, entry.next);
}
}
return null;
}
public int size() {
// TODO Auto-generated method stub
return size;
}
class Entry
K k;
V v;
// 这个就是存在next找到低下的Entry对象
Entry
public Entry(K k, V v, Entry
this.k = k;
this.v = v;
this.next = next;
}
// 获取存到Entry对象里面的key value
public K getKey() {
// TODO Auto-generated method stub
return k;
}
public V getValue() {
// TODO Auto-generated method stub
return v;
}
}
}
package DnHashMap;
public class Test {
public static void main(String[] args) {
DNMap dnmap = new DNHashMap();
for (int i = 0; i < 1000; i++) {
dnmap.put("key" + i, "value" + i);
}
System.out.println("----------------------以下是取值:观察键值对是否错乱---------------------");
for (int i = 0; i < 1000; i++) {
System.out.println("key: " + "key" + i + " value:"
+ dnmap.get("key" + i));
}
}
}
public class Test {
public static void main(String[] args) {
DNMap
for (int i = 0; i < 1000; i++) {
dnmap.put("key" + i, "value" + i);
}
System.out.println("----------------------以下是取值:观察键值对是否错乱---------------------");
for (int i = 0; i < 1000; i++) {
System.out.println("key: " + "key" + i + " value:"
+ dnmap.get("key" + i));
}
}
}
来源2017-3-10 动脑