《我的PaddlePaddle学习之路》笔记七——车牌端到端的识别
原文博客:Doi技术团队
链接地址:https://blog.doiduoyi.com/authors/1584446358138
初心:记录优秀的Doi技术团队学习经历
*本篇文章基于 PaddlePaddle 0.10.0、Python 2.7
前言
车牌识别的应用场景有很多,比如在停车场。通过车牌识别登记入库和出库的车辆的情况,并计算该车停留时间,然后折算费用。还可以在公路上识别来往的车辆,方便交警的检查等等。接下来我们就是使用PaddlePaddle来做一个车牌识别,我们直接通过段端到端识别,不用分割即可完成识别。在阅读这篇文章时,你应该先阅读上一篇验证码端到端的识别,在上一篇的很多细节,在本篇中不会很说得很细。
车牌的采集
车牌的下载
在做车牌识别之前,我们要先数据。这些车牌数据我打算从百度图片中获取,所以我先编写一个程序来帮我们下载车牌图像。
# -*- coding:utf-8 -*-
import re
import uuid
import requests
import os
class DownloadImages:
def __init__(self, download_max, key_word):
self.download_sum = 0
self.download_max = download_max
self.key_word = key_word
self.save_path = '../images/download/'
def start_download(self):
self.download_sum = 0
gsm = 80
str_gsm = str(gsm)
pn = 0
if not os.path.exists(self.save_path):
os.makedirs(self.save_path)
while self.download_sum < self.download_max:
str_pn = str(self.download_sum)
url = 'http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&' \
'word=' + self.key_word + '&pn=' + str_pn + '&gsm=' + str_gsm + '&ct=&ic=0&lm=-1&width=0&height=0'
print url
result = requests.get(url)
self.downloadImages(result.text)
print '下载完成'
def downloadImages(self, html):
img_urls = re.findall('"objURL":"(.*?)",', html, re.S)
print '找到关键词:' + self.key_word + '的图片,现在开始下载图片...'
for img_url in img_urls:
print '正在下载第' + str(self.download_sum + 1) + '张图片,图片地址:' + str(img_url)
try:
pic = requests.get(img_url, timeout=50)
pic_name = self.save_path + '/' + str(uuid.uuid1()) + '.jpg'
with open(pic_name, 'wb') as f:
f.write(pic.content)
self.download_sum += 1
if self.download_sum >= self.download_max:
break
except Exception, e:
print '【错误】当前图片无法下载,%s' % e
continue
if __name__ == '__main__':
downloadImages = DownloadImages(100, '车牌')
downloadImages.start_download()
通过上面这个程序,只要给定义下载的数据和“车牌“这个关键字,就可以开始下载车牌了,下载好的车牌会放在images/download/这个路径下。
命名车牌照片
我们下载好的图像还不能直接使用,还有经过几步的处理。下载好的车牌图像不是每张都有车牌的,还有很多无效的图像,我们还有删除这些照片。
剩下的图像我们要把它命名为车牌对应的内容,比如下面的图像命名为辽B2723L,并存放在images/src_temp/下

车牌定位
原始的图像包括很多其他的噪声,会影响到训练的效果,加上我们的数据集非常小,所以我们要裁剪多余的地方,才会使得我们的模型尽可能收敛得更小。
当然这么费劲的工作不能全部由我们手工去裁剪,我们要编写一个程序,让它来帮我们裁剪图像。
对车牌的裁剪比较复杂,我们把它分成4个部分来做:
1. 首先将彩色的车牌图像转换成灰度图
2. 灰度化的图像利用高斯平滑处理后,再对其进行中直滤波
3. 使用Sobel算子对图像进行边缘检测
4. 对二值化的图像进行腐蚀,膨胀,开运算,闭运算的形态学组合变换
5. 对形态学变换后的图像进行轮廓查找,根据车牌的长宽比提取车牌
一、灰度化
# 转化成灰度图
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)

二、高斯平滑和中值滤波
# 高斯平滑
gaussian = cv2.GaussianBlur(gray, (3, 3), 0, 0, cv2.BORDER_DEFAULT)

# 中值滤波
median = cv2.medianBlur(gaussian, 5)

三、Sobel算子对图像进行边缘检测
# Sobel算子,X方向求梯度
sobel = cv2.Sobel(median, cv2.CV_8U, 1, 0, ksize=3)
四、二值化
# 二值化
ret, binary = cv2.threshold(sobel, 170, 255, cv2.THRESH_BINARY)
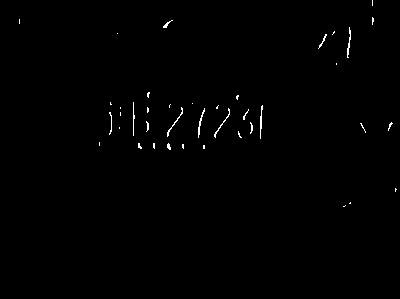
五、形态变换
# 膨胀和腐蚀操作的核函数
element1 = cv2.getStructuringElement(cv2.MORPH_RECT, (9, 1))
element2 = cv2.getStructuringElement(cv2.MORPH_RECT, (9, 7))
# 膨胀一次,让轮廓突出
dilation = cv2.dilate(binary, element2, iterations=1)
# 腐蚀一次,去掉细节
erosion = cv2.erode(dilation, element1, iterations=1)
# 再次膨胀,让轮廓明显一些
dilation2 = cv2.dilate(erosion, element2, iterations=iterations)

最后裁剪
box = region[0]
ys = [box[0, 1], box[1, 1], box[2, 1], box[3, 1]]
xs = [box[0, 0], box[1, 0], box[2, 0], box[3, 0]]
ys_sorted_index = np.argsort(ys)
xs_sorted_index = np.argsort(xs)
x1 = box[xs_sorted_index[0], 0]
x2 = box[xs_sorted_index[3], 0]
y1 = box[ys_sorted_index[0], 1]
y2 = box[ys_sorted_index[3], 1]
img_plate = img[y1:y2, x1:x2]
cv2.imwrite('../data/data_temp/%s.jpg' % self.img_name, img_plate)

在形态变换中,我先是使用了6次迭代膨胀,如果6次迭代膨胀没能裁剪到图像,就使用3次迭代膨胀的方式去变换。如果还不能就真的没有办法了,只能使用手工裁剪了。还有不得不说的是这个程序虽然优化了很多,但是裁剪的效果还是不太好,剩下没有成功裁剪的还是要手动裁剪,使用Windows 10 的自带图像查看器可以很方便裁剪。在第11章的自定义图像数据集实现目标检测中就介绍使用神经网络定位车牌,可以使用神经网络预测的结果定位车牌,识别率会高很多。
裁剪后的图像存放在data/data_temp/,等待分配给训练和测试的数据集。
灰度化和分配数据集
我们裁剪后的图像还是彩色的,并存放在data/data_temp/,我们现在要把他们灰度化和分配给训练的data/train_data和测试的data/test_data,所以要编写一个程序批量处理他们。
# coding=utf-8
import os
from PIL import Image
def Image2GRAY(path):
# 获取临时文件夹中的所有图像路径
imgs = os.listdir(path)
i = 0
for img in imgs:
# 每10个数据取一个作为测试数据,剩下的作为训练数据
if i % 10 == 0:
# 使图像灰度化并保存
im = Image.open(path + '/' + img).convert('L')
im = im.resize((180, 80), Image.ANTIALIAS)
im.save('../data/test_data/' + img)
else:
# 使图像灰度化并保存
im = Image.open(path + '/' + img).convert('L')
im = im.resize((180, 80), Image.ANTIALIAS)
im.save('../data/train_data/' + img)
i = i + 1
if __name__ == '__main__':
# 临时数据存放路径
path = '../data/data_temp'
Image2GRAY(path)
现在训练数据和测试数据都有了,可以开始读取数据了
数据的读取
生成list文件
跟上一篇文章中说的一样,这次我们还是使用Tab键分开图像路径和和对应的label,所以我们的程序跟之前一样
# coding=utf-8
import os
class CreateDataList:
def __init__(self):
pass
def createDataList(self, data_path, isTrain):
# 判断生成的列表是训练图像列表还是测试图像列表
if isTrain:
list_name = 'trainer.list'
else:
list_name = 'test.list'
list_path = os.path.join(data_path, list_name)
# 判断该列表是否存在,如果存在就删除,避免在生成图像列表时把该路径也写进去了
if os.path.exists(list_path):
os.remove(list_path)
# 读取所有的图像路径,此时图像列表不存在,就不用担心写入非图像文件路径了
imgs = os.listdir(data_path)
for img in imgs:
name = img.split('.')[0]
with open(list_path, 'a') as f:
# 写入图像路径和label,用Tab隔开
f.write(img + '\t' + name + '\n')
if __name__ == '__main__':
createDataList = CreateDataList()
# 生成训练图像列表
createDataList.createDataList('../data/train_data/', True)
# 生成测试图像列表
createDataList.createDataList('../data/test_data/', False)
同样会在data/train_data生成图像列表trainer.list,会在data/test_data生成图像列表test.list。
读取数据成list
然后通过以下的程序生成对应的list
def get_file_list(image_file_list):
'''
生成用于训练和测试数据的文件列表。
:param image_file_list: 图像文件和列表文件的路径
:type image_file_list: str
'''
dirname = os.path.dirname(image_file_list)
path_list = []
with open(image_file_list) as f:
for line in f:
# 使用Tab键分离路径和label
line_split = line.strip().split('\t')
filename = line_split[0].strip()
path = os.path.join(dirname, filename)
label = line_split[1].strip()
if label:
path_list.append((path, label))
return path_list
通过上一步生成的list文件,再调用这个程序就可以生成图像路径和标签的list了
# 获取训练列表
train_file_list = get_file_list(train_file_list_path)
# 获取测试列表
test_file_list = get_file_list(test_file_list_path)
生成和读取标签字典
有了list还不行,还要有一个标签字典,这个标签字典包括训练label的所有字符,这个标签字典是之后训练和预测都要使用的。我们要生成一个标签字典格式是:
字符 出现次数
字符 出现次数
字符 出现次数
字符 出现次数
要注意的是,更上次不一样,这次的label有中文,所以在保存字典的时候要注意中文编码的问题。
def build_label_dict(file_list, save_path):
"""
从训练数据建立标签字典
:param file_list: 包含标签的训练数据列表
:type file_list: list
:params save_path: 保存标签字典的路径
:type save_path: str
"""
values = defaultdict(int)
for path, label in file_list:
# 加上unicode(label, "utf-8")解决中文编码问题
for c in unicode(label, "utf-8"):
if c:
values[c] += 1
values['' ] = 0
# 解决写入文本文件的中文编码问题
f = codecs.open(save_path,'w','utf-8')
for v, count in sorted(values.iteritems(), key=lambda x: x[1], reverse=True):
content = "%s\t%d\n" % (v, count)
# print content
f.write(content)
然后把训练数据传给这个函数就可以生成字典了
build_label_dict(train_file_list, label_dict_path)
然后是读取字典
def load_dict(dict_path):
"""
从字典路径加载标签字典
:param dict_path: 标签字典的路径
:type dict_path: str
"""
return dict((line.strip().split("\t")[0], idx)
for idx, line in enumerate(open(dict_path, "r").readlines()))
训练和测试数据的读取
处理好标签字典之后,现在就要处理训练数据和测试数据的读取问题了,在上几步我么拿到了train_file_list,只有这个list是不能直接用了给PaddlePaddle读取训练的,我们还有处理一下。
# coding=utf-8
import cv2
import paddle.v2 as paddle
class Reader(object):
def __init__(self, char_dict, image_shape):
'''
:param char_dict: 标签的字典类
:type char_dict: class
:param image_shape: 图像的固定形状
:type image_shape: tuple
'''
self.image_shape = image_shape
self.char_dict = char_dict
def train_reader(self, file_list):
'''
训练读取数据
:param file_list: 用预训练的图像列表,包含标签和图像路径
:type file_list: list
'''
def reader():
UNK_ID = self.char_dict['' ]
for image_path, label in file_list:
# 解决key为中文问题
label2 = []
for c in unicode(label, "utf-8"):
for dict1 in self.char_dict:
if c == dict1.decode('utf-8'):
label2.append(self.char_dict[dict1])
yield self.load_image(image_path), label2
return reader
def load_image(self, path):
'''
加载图像并将其转换为一维向量
:param path: 图像数据的路径
:type path: str
'''
image = paddle.image.load_image(path,is_color=False)
# 将所有图像调整为固定形状
if self.image_shape:
image = cv2.resize(
image, self.image_shape, interpolation=cv2.INTER_CUBIC)
image = image.flatten() / 255.
return image
值得留意的是train_reader(self, file_list)这函数,因为标签字典中有中文,所以字典中有的key是中文的,所以要做一些编码的处理。
然后通过下面的代码就可以拿到reader了
# 获取测试数据的reader
test_reader = paddle.batch(
my_reader.train_reader(test_file_list),
batch_size=BATCH_SIZE)
# 获取训练数据的reader
train_reader = paddle.batch(
paddle.reader.shuffle(
my_reader.train_reader(train_file_list),
buf_size=1000),
batch_size=BATCH_SIZE)
定义神经网络
有了训练数据之后,我们就要定义神经网络了。
下面是数据大小和label的定义
# 获取字典大小
dict_size = len(char_dict)
以下就是类初始化的数据和定义数据和label的操作:
class Model(object):
def __init__(self, num_classes, shape, is_infer=False):
'''
:param num_classes: 字符字典的大小
:type num_classes: int
:param shape: 输入图像的大小
:type shape: tuple of 2 int
:param is_infer: 是否用于预测
:type shape: bool
'''
self.num_classes = num_classes
self.shape = shape
self.is_infer = is_infer
self.image_vector_size = shape[0] * shape[1]
self.__declare_input_layers__()
self.__build_nn__()
def __declare_input_layers__(self):
'''
定义输入层
'''
# 图像输入为一个浮动向量
self.image = paddle.layer.data(
name='image',
type=paddle.data_type.dense_vector(self.image_vector_size),
# shape是(宽度,高度)
height=self.shape[1],
width=self.shape[0])
# 将标签输入为ID列表
if not self.is_infer:
self.label = paddle.layer.data(
name='label',
type=paddle.data_type.integer_value_sequence(self.num_classes))
定义网络模型,该网络模型
首先是通过CNN获取图像的特征,
然后使用这些特征来输出展开成一系列特征向量,
然后使用RNN向前和向后捕获序列信息,
然后将RNN的输出映射到字符分布,
最后使用扭曲CTC来计算CTC任务的成本,获得了cost和额外层。
def __build_nn__(self):
'''
建立网络拓扑
'''
# 通过CNN获取图像特征
def conv_block(ipt, num_filter, groups, num_channels=None):
return paddle.networks.img_conv_group(
input=ipt,
num_channels=num_channels,
conv_padding=1,
conv_num_filter=[num_filter] * groups,
conv_filter_size=3,
conv_act=paddle.activation.Relu(),
conv_with_batchnorm=True,
pool_size=2,
pool_stride=2, )
# 因为是灰度图所以最后一个参数是1
conv1 = conv_block(self.image, 16, 2, 1)
conv2 = conv_block(conv1, 32, 2)
conv3 = conv_block(conv2, 64, 2)
conv_features = conv_block(conv3, 128, 2)
# 将CNN的输出展开成一系列特征向量。
sliced_feature = paddle.layer.block_expand(
input=conv_features,
num_channels=128,
stride_x=1,
stride_y=1,
block_x=1,
block_y=11)
# 使用RNN向前和向后捕获序列信息。
gru_forward = paddle.networks.simple_gru(
input=sliced_feature, size=128, act=paddle.activation.Relu())
gru_backward = paddle.networks.simple_gru(
input=sliced_feature,
size=128,
act=paddle.activation.Relu(),
reverse=True)
# 将RNN的输出映射到字符分布。
self.output = paddle.layer.fc(input=[gru_forward, gru_backward],
size=self.num_classes + 1,
act=paddle.activation.Linear())
self.log_probs = paddle.layer.mixed(
input=paddle.layer.identity_projection(input=self.output),
act=paddle.activation.Softmax())
# 使用扭曲CTC来计算CTC任务的成本。
if not self.is_infer:
# 定义cost
self.cost = paddle.layer.warp_ctc(
input=self.output,
label=self.label,
size=self.num_classes + 1,
norm_by_times=True,
blank=self.num_classes)
# 定义额外层
self.eval = paddle.evaluator.ctc_error(input=self.output, label=self.label)
最后通过调用该类就可以获取到模型了,传入的参数是
dict_size是标签字典的大小,在上面有介绍是用来生成label的
IMAGE_SHAPE这个是图像的宽度和高度,格式是:(宽度,高度)
model = Model(dict_size, IMAGE_SHAPE, is_infer=False)
开始训练
定义训练器
有了数据和神经网络,我们就可以开始训练,在训练之前,我们先要有一个训练器,接下来我们要定义一个训练器
# 初始化PaddlePaddle
paddle.init(use_gpu=True, trainer_count=1)
# 定义网络拓扑
model = Model(dict_size, IMAGE_SHAPE, is_infer=False)
# 创建优化方法
optimizer = paddle.optimizer.Momentum(momentum=0)
# 创建训练参数
params = paddle.parameters.create(model.cost)
# 定义训练器
trainer = paddle.trainer.SGD(cost=model.cost,
parameters=params,
update_equation=optimizer,
extra_layers=model.eval)
启动训练
有了数据和神经网络模型,也有了训练器,现在就可以开始训练了
# 开始训练
trainer.train(reader=train_reader,
feeding=feeding,
event_handler=event_handler,
num_passes=5000)
训练的时候我们要有一个训练事件来把我们保存训练好的参数
# 训练事件
def event_handler(event):
if isinstance(event, paddle.event.EndIteration):
if event.batch_id % 100 == 0:
print("Pass %d, batch %d, Samples %d, Cost %f, Eval %s" %
(event.pass_id, event.batch_id, event.batch_id *
BATCH_SIZE, event.cost, event.metrics))
if isinstance(event, paddle.event.EndPass):
result = trainer.test(reader=test_reader, feeding=feeding)
print("Test %d, Cost %f, Eval %s" % (event.pass_id, result.cost, result.metrics))
# 检查保存model的路径是否存在,如果不存在就创建
if not os.path.exists(model_save_dir):
os.mkdir(model_save_dir)
with gzip.open(
os.path.join(model_save_dir, "params_pass.tar.gz"), "w") as f:
trainer.save_parameter_to_tar(f)
这个项目依赖的 warp CTC 只有CUDA的实现,所以只支持 GPU 运行,要运行该项目就要搭建PaddlePaddle的GPU版本。如果你使用百度深度学习的GPU集群,要看看上一篇安装libwarpctc.so库部分。
在训练时会输出这样类似的日志:
Pass 0, batch 0, Samples 0, Cost 45.893759, Eval {}
Test 0, Cost 27.545489, Eval {}
Pass 1, batch 0, Samples 0, Cost 28.823596, Eval {}
Test 1, Cost 25.830573, Eval {}
Pass 2, batch 0, Samples 0, Cost 26.331317, Eval {}
Test 2, Cost 25.292363, Eval {}
Pass 3, batch 0, Samples 0, Cost 23.742380, Eval {}
Test 3, Cost 24.762170, Eval {}
开始预测
经过差不多1000pass之后,我们可以使用保存好的参数来做预测了
def infer(img_path, model_path, image_shape, label_dict_path):
# 获取标签字典
char_dict = load_dict(label_dict_path)
# 获取反转的标签字典
reversed_char_dict = load_reverse_dict(label_dict_path)
# 获取字典大小
dict_size = len(char_dict)
# 获取reader
my_reader = Reader(char_dict=char_dict, image_shape=image_shape)
# 初始化PaddlePaddle
paddle.init(use_gpu=True, trainer_count=1)
# 获取网络模型
model = Model(dict_size, image_shape, is_infer=True)
# 加载训练好的参数
parameters = paddle.parameters.Parameters.from_tar(gzip.open(model_path))
# 获取预测器
inferer = paddle.inference.Inference(output_layer=model.log_probs, parameters=parameters)
# 裁剪车牌
cutPlateNumber = CutPlateNumber()
cutPlateNumber.strat_crop(img_path, True)
# 加载裁剪后的车牌
test_batch = [[my_reader.load_image('../images/infer.jpg')]]
# 开始预测
return start_infer(inferer, test_batch, reversed_char_dict)
跟之前的不一样的是,我们要预测的车牌也要经过裁剪才可以很好地预测
# 裁剪车牌
cutPlateNumber = CutPlateNumber()
cutPlateNumber.strat_crop(img_path, True)
# 加载裁剪后的车牌
test_batch = [[my_reader.load_image('../images/infer.jpg')]]
在裁剪的时候,我们把要预测的图像专门保存起来,等待预测的
if is_infer:
# 如果是用于预测的图像,就给定文件名
cv2.imwrite('../images/infer.jpg', img_plate)
获得PaddlePaddle的预测器和图像的一维向量之后,我们就可以开始预测了
def start_infer(inferer, test_batch, reversed_char_dict):
# 获取初步预测结果
infer_results = inferer.infer(input=test_batch)
num_steps = len(infer_results) // len(test_batch)
probs_split = [
infer_results[i * num_steps:(i + 1) * num_steps]
for i in range(0, len(test_batch))]
# 最佳路径解码
result = ''
for i, probs in enumerate(probs_split):
result = ctc_greedy_decoder(
probs_seq=probs, vocabulary=reversed_char_dict)
return result
预测出来的是字典编号,我们要通过这些编号反转的标签字典,获得对应的字符:
def load_reverse_dict(dict_path):
"""
从字典路径加载反转的标签字典
:param dict_path: 标签字典的路径
:type dict_path: str
"""
return dict((idx, line.strip().split("\t")[0])
for idx, line in enumerate(open(dict_path, "r").readlines()))
还有我们在预测是要获得最优的预测路径,通过下面的代码获取最优的解码
def ctc_greedy_decoder(probs_seq, vocabulary):
"""CTC贪婪(最佳路径)解码器。
由最可能的令牌组成的路径被进一步后处理
删除连续的重复和所有的空白。
:param probs_seq: 每个词汇表上概率的二维列表字符。
每个元素都是浮点概率列表为一个字符。
:type probs_seq: list
:param vocabulary: 词汇表
:type vocabulary: list
:return: 解码结果字符串
:rtype: baseline
"""
# 尺寸验证
for probs in probs_seq:
if not len(probs) == len(vocabulary) + 1:
raise ValueError("probs_seq dimension mismatchedd with vocabulary")
# argmax以获得每个时间步长的最佳指标
max_index_list = list(np.array(probs_seq).argmax(axis=1))
# 删除连续的重复索引
index_list = [index_group[0] for index_group in groupby(max_index_list)]
# 删除空白索引
blank_index = len(vocabulary)
index_list = [index for index in index_list if index != blank_index]
# 将索引列表转换为字符串
return ''.join([vocabulary[index] for index in index_list])
最后调用该预测函数就可以预测了
if __name__ == "__main__":
# 要预测的图像
img_path = '../data/test_data/京CX8888.jpg'
# 模型的路径
model_path = '../models/params_pass.tar.gz'
# 图像的大小
image_shape = (180, 80)
# 标签的路径
label_dict_path = '../data/label_dict.txt'
# 获取预测结果
result = infer(img_path, model_path, image_shape, label_dict_path)
print '预测结果:%s' % result
预测的结果输出的日志:
预测结果:京CX8888
训练数据太少了,训练出来的模型不是很好,存在过拟合现象。这种情况可以通过增加训练数据,可以避免过拟合。笔者做这些车牌已经很费劲了,虽然只要250多张,但是花了不少时间,如果读者想提高识别准确率,可以通过增加数据量来训练更好的模型。
上一章:《我的PaddlePaddle学习之路》笔记六——验证码端到端的识别
下一章:《我的PaddlePaddle学习之路》笔记八——场景文字识别
项目代码
GitHub地址:https://github.com/yeyupiaoling/LearnPaddle
参考资料
- http://paddlepaddle.org/
- https://www.jianshu.com/p/fcfbd3131b84
- http://blog.csdn.net/louzhengzhai/article/details/72802978
- http://blog.csdn.net/w1573007/article/details/77199733
PyTorch从入门到实战一次学会