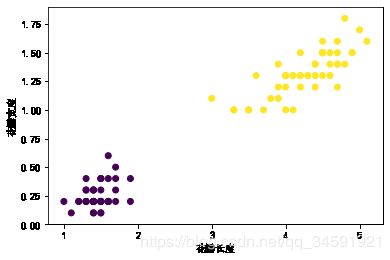
1.LDA+鸢尾花
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
def LDA(X, y):
X1 = np.array([X[i] for i in range(len(X)) if y[i] == 0])
X2 = np.array([X[i] for i in range(len(X)) if y[i] == 1])
len1 = len(X1)
len2 = len(X2)
mju1 = np.mean(X1, axis=0)
mju2 = np.mean(X2, axis=0)
cov1 = np.dot((X1 - mju1).T, (X1 - mju1))
cov2=np.dot((X2 - mju2).T, (X2 - mju2))
Sw = cov1 + cov2
a=mju1-mju2
a=(np.array([a])).T
w=(np.dot(np.linalg.inv(Sw),a))
X1_new =func(X1, w)
X2_new = func(X2, w)
y1_new = [1 for i in range(len1)]
y2_new = [2 for i in range(len2)]
return X1_new,X2_new,y1_new,y2_new
def func(x, w):
return np.dot((x), w)
iris = datasets.load_iris()
X = iris["data"][:, (2, 3)]
y = iris["target"]
setosa_or_versicolor = (y == 0) | (y == 1)
X = X[setosa_or_versicolor]
y = y[setosa_or_versicolor]
x1_new, X2_new, y1_new, y2_new = LDA(X, y)
plt.xlabel('花瓣长度')
plt.ylabel('花瓣宽度')
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
plt.scatter(X[:, 0], X[:, 1], marker='o', c=y)
plt.show()
2.LDA+月亮
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
def LDA(X, y):
X1 = np.array([X[i] for i in range(len(X)) if y[i] == 0])
X2 = np.array([X[i] for i in range(len(X)) if y[i] == 1])
len1 = len(X1)
len2 = len(X2)
mju1 = np.mean(X1, axis=0)
mju2 = np.mean(X2, axis=0)
cov1 = np.dot((X1 - mju1).T, (X1 - mju1))
cov2=np.dot((X2 - mju2).T, (X2 - mju2))
Sw = cov1 + cov2
a=mju1-mju2
a=(np.array([a])).T
w=(np.dot(np.linalg.inv(Sw),a))
X1_new =func(X1, w)
X2_new = func(X2, w)
y1_new = [1 for i in range(len1)]
y2_new = [2 for i in range(len2)]
def func(x, w):
return np.dot((x), w)
X, y = datasets.make_moons(n_samples=100, noise=0.15, random_state=42)
plt.scatter(X[:, 0], X[:, 1], marker='o', c=y)
plt.show()
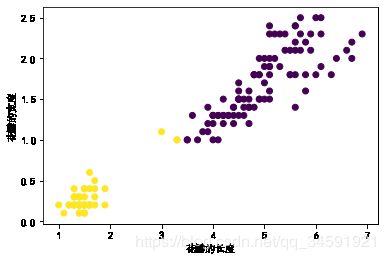
3.K-means+鸢尾花
from sklearn import datasets
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
lris_df = datasets.load_iris()
x_axis = lris_df.data[:,2]
y_axis = lris_df.data[:,3]
model = KMeans(n_clusters=2)
model.fit(lris_df.data)
prddicted_label= model.predict([[6.3, 3.3, 6, 2.5]])
all_predictions = model.predict(lris_df.data)
plt.xlabel('花瓣的长度')
plt.ylabel('花瓣的宽度')
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
plt.scatter(x_axis, y_axis, c=all_predictions)
plt.show()
4.K-means+月亮
from sklearn.datasets import make_moons
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
import numpy as np
X, y = make_moons(n_samples=100, noise=0.15, random_state=42)
X1=X[:,0]
X2=X[:,1]
model = KMeans(n_clusters=2)
model.fit(X)
prddicted_label= model.predict([[-0.22452786,1.01733299]])
all_predictions = model.predict(X)
plt.scatter(X1, X2, c=all_predictions)
plt.show()
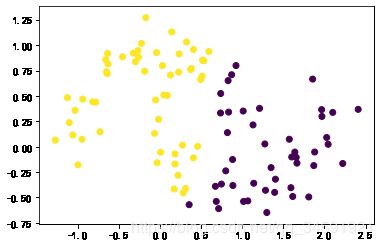
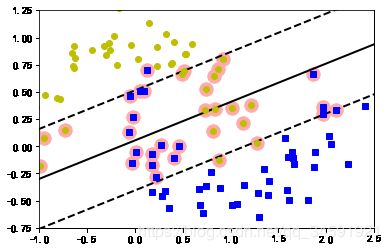
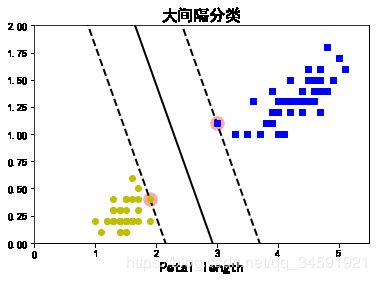
5.SVM+鸢尾花
from sklearn.svm import SVC
from sklearn import datasets
import matplotlib.pyplot as plt
import numpy as np
iris = datasets.load_iris()
X = iris["data"][:, (2, 3)]
y = iris["target"]
setosa_or_versicolor = (y == 0) | (y == 1)
X = X[setosa_or_versicolor]
y = y[setosa_or_versicolor]
svm_clf = SVC(kernel="linear", C=float("inf"))
svm_clf.fit(X, y)
def plot_svc_decision_boundary(svm_clf, xmin, xmax):
w = svm_clf.coef_[0]
b = svm_clf.intercept_[0]
x0 = np.linspace(xmin, xmax, 200)
decision_boundary = -w[0]/w[1] * x0 - b/w[1]
margin = 1/w[1]
gutter_up = decision_boundary + margin
gutter_down = decision_boundary - margin
svs = svm_clf.support_vectors_
plt.scatter(svs[:, 0], svs[:, 1], s=180, facecolors='#FFAAAA')
plt.plot(x0, decision_boundary, "k-", linewidth=2)
plt.plot(x0, gutter_up, "k--", linewidth=2)
plt.plot(x0, gutter_down, "k--", linewidth=2)
plt.title("大间隔分类", fontsize=16)
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
plot_svc_decision_boundary(svm_clf, 0, 5.5)
plt.plot(X[:, 0][y==1], X[:, 1][y==1], "bs")
plt.plot(X[:, 0][y==0], X[:, 1][y==0], "yo")
plt.xlabel("Petal length", fontsize=14)
plt.axis([0, 5.5, 0, 2])
plt.show()
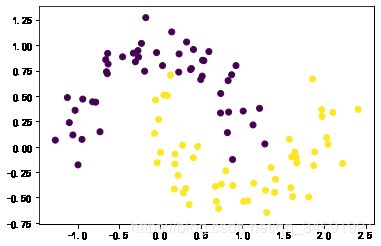
6.SVM+月亮
from sklearn.svm import SVC
from sklearn import datasets
import matplotlib.pyplot as plt
import numpy as np
X, y = datasets.make_moons(n_samples=100, noise=0.15, random_state=42)
svm_clf = SVC(kernel="linear")
svm_clf.fit(X, y)
def plot_svc_decision_boundary(svm_clf, xmin, xmax):
w = svm_clf.coef_[0]
b = svm_clf.intercept_[0]
x0 = np.linspace(xmin, xmax, 200)
decision_boundary = -w[0]/w[1] * x0 - b/w[1]
margin = 1/w[1]
gutter_up = decision_boundary + margin
gutter_down = decision_boundary - margin
svs = svm_clf.support_vectors_
plt.scatter(svs[:, 0], svs[:, 1], s=180, facecolors='#FFAAAA')
plt.plot(x0, decision_boundary, "k-", linewidth=2)
plt.plot(x0, gutter_up, "k--", linewidth=2)
plt.plot(x0, gutter_down, "k--", linewidth=2)
plot_svc_decision_boundary(svm_clf, -2, 3)
plt.plot(X[:, 0][y==1], X[:, 1][y==1], "bs")
plt.plot(X[:, 0][y==0], X[:, 1][y==0], "yo")
plt.axis([-1, 2.5, -0.75, 1.25])
plt.show()