编译原理FIRST集和FOLLOW集的求法以及构建LL(1)分析表
文章目录
- FIRST集的求法
- FOLLOW集的计算
- 生成预期分析表算法
- 例题
- 分析句子
FIRST集的求法
FIRST集是一个文法符号串所可能推导出的符号串的第一个终结符的集合
对于文法G的任一符号串 α \alpha α = x 1 x 2 … x n x_{1}x_{2} \ldots x_{n} x1x2…xn
- 置 FIRST( α \alpha α) = ϕ \phi ϕ
- 将 FIRST( x 1 x_{1} x1) 中一切非 ϵ \epsilon ϵ 符号加进 FIRST( α \alpha α)
- 若 ϵ ∈ \epsilon\in ϵ∈ FIRST( x 1 x_{1} x1), 将 FIRST( x 2 x_{2} x2) 中一切非 ϵ \epsilon ϵ 符号加进FIRST( α \alpha α); 若 ϵ ∈ \epsilon \in ϵ∈ FIRST( x 1 x_{1} x1) 和 FIRST( x 2 x_{2} x2), 将 FIRST( x 3 x_{3} x3) 中一切非 ϵ \epsilon ϵ 符号加进 FIRST( α \alpha α) 中, 依此类推.
- 对于一切 1 ⩽ \leqslant ⩽ i ⩽ \leqslant ⩽ n, ϵ ∈ \epsilon \in ϵ∈ FIRST( x i x_{i} xi), 则将 ϵ \epsilon ϵ 符号加入 FIRST( α \alpha α).
note:
FIRST集从产生式左侧推导,例如求A的FIRST集,要先从产生式左侧找到A,然后根据产生式右侧的信息求出A的FIRST集
例如:
S → \rightarrow → BS ‘ ^` ‘
S ‘ → ^` \rightarrow ‘→ aB | ϵ \epsilon ϵ
B → \rightarrow → DB ‘ ^` ‘
B ‘ → ^` \rightarrow ‘→ b | ϵ \epsilon ϵ
D → \rightarrow → d | ϵ \epsilon ϵ
FIRST(S) = {d, b, a, ϵ \epsilon ϵ}
FIRST(S ‘ ^` ‘) = {a, ϵ \epsilon ϵ}
FIRST(B) = {d, b, ϵ \epsilon ϵ}
FIRST(B ‘ ^` ‘) = {b, ϵ \epsilon ϵ}
FIRST(D) = {d, ϵ \epsilon ϵ}
解释:
第一个求S的FIRST集,先从产生式的左侧找到S, (S → \rightarrow → BS ‘ ^` ‘), 然后根据该产生式右侧的信息(BS ‘ ^` ‘) 和求FIRST集的第二条规则求FIRST(B), 从产生式的左侧找到B, (B → \rightarrow → DB ‘ ^` ‘), 然后根据该产生式右侧的信息(DB ‘ ^` ‘) 和求FIRST集的第二条规则求FIRST(D), 从产生式的左侧找到D, (D → \rightarrow → d | ϵ \epsilon ϵ), 然后根据该产生式右侧的信息(d | ϵ \epsilon ϵ) 和求FIRST集的第二条规则, 将终结符d加入FIRST(S).
F I R S T ( S ) = { d } \color{red} { FIRST(S) = \{d\} } FIRST(S)={d}
又根据第三条规则,因为D → ϵ \rightarrow \epsilon →ϵ, 所以将FIRST(B ‘ ^` ‘) 加入到FIRST(S)中,从产生式的左侧找到B ‘ ^` ‘, (B ‘ → ^` \rightarrow ‘→ b | ϵ \epsilon ϵ), 然后根据该产生式右侧的信息(b | ϵ \epsilon ϵ) 和求FIRST集的第二条规则, 将终结符b加入FIRST(S).
F I R S T ( S ) = { d , b } \color{red} { FIRST(S) = \{d, b\} } FIRST(S)={d,b}
又根据第三条规则,因为B ‘ → ϵ ^` \rightarrow \epsilon ‘→ϵ, 所以将FIRST(S ‘ ^` ‘) 加入到FIRST(S)中,从产生式的左侧找到S ‘ ^` ‘, (S ‘ → ^` \rightarrow ‘→ aB | ϵ \epsilon ϵ), 然后根据该产生式右侧的信息(aB | ϵ \epsilon ϵ) 和求FIRST集的第二条规则, 将终结符a加入FIRST(S).
F I R S T ( S ) = { d , b , a } \color{red} { FIRST(S) = \{d, b, a\} } FIRST(S)={d,b,a}
又根据第四条规则,因为 ϵ ∈ \epsilon \in ϵ∈ FIRST(D) , ϵ ∈ \epsilon \in ϵ∈ FIRST(B ‘ ^` ‘), 所以 ϵ ∈ \epsilon \in ϵ∈ FIRST(B), 又因为 ϵ ∈ \epsilon \in ϵ∈ FIRST(S ‘ ^` ‘), 所以 ϵ ∈ \epsilon \in ϵ∈ FIRST(S). 最终结果如下:
F I R S T ( S ) = { d , b , a , ϵ } \color{red} { FIRST(S) = \{d, b, a, \epsilon\} } FIRST(S)={d,b,a,ϵ}
第二个求S ‘ ^` ‘的FIRST集, 先从产生式左侧找到S ‘ ^` ‘, (S ‘ → ^` \rightarrow ‘→ aB | ϵ \epsilon ϵ), 然后根据产生式右侧的信息(aB | ϵ \epsilon ϵ), S既能推导出aB又能推导出 ϵ \epsilon ϵ, 所以根据规则二和规则四得出:
F I R S T ( S ‘ ) = { a , ϵ } \color{red}{ FIRST(S^`) = \{a, \epsilon\} } FIRST(S‘)={a,ϵ}
第三个求B的FIRST集, 产生式的左侧找到B, (B → \rightarrow → DB ‘ ^` ‘), 然后根据该产生式右侧的信息(DB ‘ ^` ‘) 和求FIRST集的第二条规则求FIRST(D), 从产生式的左侧找到D, (D → \rightarrow → d | ϵ \epsilon ϵ), 然后根据该产生式右侧的信息(d | ϵ \epsilon ϵ) 和求FIRST集的第二条规则, 将终结符d加入FIRST(B).
F I R S T ( B ) = { d } \color{red} { FIRST(B) = \{d\} } FIRST(B)={d}
又根据第三条规则,因为D → ϵ \rightarrow \epsilon →ϵ, 所以将FIRST(B ‘ ^` ‘) 加入到FIRST(B)中,从产生式的左侧找到B ‘ ^` ‘, (B ‘ → ^` \rightarrow ‘→ b | ϵ \epsilon ϵ), 然后根据该产生式右侧的信息(b | ϵ \epsilon ϵ) 和求FIRST集的第二条规则, 将终结符b加入FIRST(B).
F I R S T ( B ) = { d , b } \color{red} { FIRST(B) = \{d, b\} } FIRST(B)={d,b}
又根据第四条规则,因为 ϵ ∈ \epsilon \in ϵ∈ FIRST(D) , ϵ ∈ \epsilon \in ϵ∈ FIRST(B ‘ ^` ‘), 所以 ϵ ∈ \epsilon \in ϵ∈ FIRST(B), 最终结果如下:
F I R S T ( B ) = { d , b , ϵ } \color{red} { FIRST(B) = \{d, b, \epsilon\} } FIRST(B)={d,b,ϵ}
求第四个B ‘ ^` ‘的FIRST集和第五个求D的FIRST集同求第二个求S ‘ ^` ‘的FIRST集,结果为:
F I R S T ( B ‘ ) = { b , ϵ } F I R S T ( D ) = { d , ϵ } \color{red} { FIRST(B^`) = \{b, \epsilon\} }\\ { FIRST(D) = \{d, \epsilon\} } FIRST(B‘)={b,ϵ}FIRST(D)={d,ϵ}
FOLLOW集的计算
FOLLOW集是文法符号后面可能跟随的终结符的集合(不包括空串)
- 对于文法的开始符号S,置 # 于 FOLLOW(S)中.
- 若 A → \rightarrow → aB β \beta β 是一个产生式, 则把 FIRST( β \beta β) \ | ϵ \epsilon ϵ| 加至 FOLLOW(B) 中.
- 若 A → \rightarrow → aB 是一个产生式,或 A → \rightarrow → aB β \beta β 是一个产生式而 β ⇒ ϵ \beta \Rightarrow \epsilon β⇒ϵ (即 ϵ ∈ \epsilon \in ϵ∈) FIRST(B), 则把 FOLLOW(A) 加至 FOLLOW(B) 中.
note:
- FOLLOW集中没有 ϵ \epsilon ϵ
- FOLLOW集从产生式右侧推导,例如求A的FOLLOW集时,要从产生式右侧找到A,然后根据A右侧符号信息,求出A的FOLLOW集
例如:
S → \rightarrow → BS ‘ ^` ‘
S ‘ → ^` \rightarrow ‘→ aB | ϵ \epsilon ϵ
B → \rightarrow → DB ‘ ^` ‘
B ‘ → ^` \rightarrow ‘→ b | ϵ \epsilon ϵ
D → \rightarrow → d | ϵ \epsilon ϵ
FOLLOW(S) = {#}
FOLLOW(S ‘ ^` ‘) = {#}
FOLLOW(B) = FIRST(S ‘ ^` ‘) \ | ϵ \epsilon ϵ| ∪ \cup ∪ FOLLOW(S ‘ ^` ‘) ∪ \cup ∪ FOLLOW(S) = {a, #}
FOLLOW(B ‘ ^` ‘) = FOLLOW(B) = {a, #}
FOLLOW(D) = FIRST(B ‘ ^` ‘) \ | ϵ \epsilon ϵ| ∪ \cup ∪ FOLLOW(B) = {b, a, #}
解释:
第一个求S的FOLLOW集, 因为S是开始符号,所以将#加入到FOLLOW(S)中,从产生式右侧找S,没有找到,所以最终结果:
F O L L O W ( S ) = { # } \color{red} { FOLLOW(S) = \{ \# \} } FOLLOW(S)={#}
第二个求S ‘ ^` ‘的FOLLOW集, 从产生式右侧找S ‘ ^` ‘, (S → \rightarrow → BS ‘ ^` ‘), 根据右侧符号信息和求FOLLOW集的第三条规则,将 FOLLOW(S) 加入到 FOLLOW(S ‘ ^` ‘) 中,最终结果:
F O L L O W ( S ‘ ) = { # } \color{red} { FOLLOW(S^`) = \{ \# \} } FOLLOW(S‘)={#}
第三个求B的FOLLOW集,从产生式右侧找到B,(S → \rightarrow → BS ‘ ^` ‘ 、S ‘ → ^` \rightarrow ‘→ aB | ϵ \epsilon ϵ), 根据 S → \rightarrow → BS ‘ ^` ‘ 和第二条规则,得:
F O L L O W ( B ) = F I R S T ( S ‘ ) ∖ ∣ ϵ ∣ = { a } \color{red} { FOLLOW(B) = FIRST(S^`) \setminus |\epsilon| = \{a\} } FOLLOW(B)=FIRST(S‘)∖∣ϵ∣={a}
根据S ‘ → ^` \rightarrow ‘→ aB 和第三条规则,得:
F O L L O W ( B ) = F O L L O W ( S ‘ ) = { a , # } \color{red} { FOLLOW(B) = FOLLOW(S^`) = \{a, \# \} } FOLLOW(B)=FOLLOW(S‘)={a,#}
又因为S ‘ → ϵ ^` \rightarrow \epsilon ‘→ϵ, 根据S → \rightarrow → BS ‘ ^` ‘ 和第三条规则,得:
F O L L O W ( B ) = F O L L O W ( S ) = { a , # } \color{red} { FOLLOW(B) = FOLLOW(S) = \{a, \#\} } FOLLOW(B)=FOLLOW(S)={a,#}
第四个求B ‘ ^` ‘的FOLLOW集,从产生式的右侧找到B ‘ ^` ‘, (B → \rightarrow → DB ‘ ^` ‘), 根据第三条规则,得:
F O L L O W ( B ‘ ) = F O L L O W ( B ) = { a , # } \color{red} { FOLLOW(B^`) = FOLLOW(B) = \{a, \#\} } FOLLOW(B‘)=FOLLOW(B)={a,#}
第五个求D的FOLLOW集,从产生式的右侧找到D, (B → \rightarrow → DB ‘ ^` ‘), 根据第二条规则,得:
F O L L O W ( D ) = F I R S T ( B ‘ ) ∖ ∣ ϵ ∣ = { b } \color{red} { FOLLOW(D) = FIRST(B^`) \setminus |\epsilon| = \{b\} } FOLLOW(D)=FIRST(B‘)∖∣ϵ∣={b}
又因为B ‘ → ϵ ^` \rightarrow \epsilon ‘→ϵ, 根据 B → \rightarrow → DB ‘ ^` ‘ 和第三条规则,得:
F O L L O W ( D ) = F O L L O W ( B ) = { b , a , # } \color{red} { FOLLOW(D) = FOLLOW(B) = \{b, a, \#\} } FOLLOW(D)=FOLLOW(B)={b,a,#}
生成预期分析表算法
- 对于文法G的每个产生式 A → α \rightarrow \alpha →α, 执行第2步和第3步
- 对每个终结符a ∈ \in ∈ FIRST( α \alpha α), 把 A → α \rightarrow \alpha →α 加至 M[A, a]中
- 若 ϵ ∈ \epsilon \in ϵ∈ FIRST( α \alpha α), 则对任何b ∈ \in ∈ FOLLOW(A) 把 A → α \rightarrow \alpha →α 加至 M[A, b]中
note:
每个产生式的意思是将所有含“|”的产生式全部展开,然后看每个产生式的FIRST集,如果这个FIRST集中有“ ϵ \epsilon ϵ”, 那就要将这个产生式加入到 FOLLOW集中相应符号中
例题
已知文法G如下:
S → \rightarrow → AB
A → \rightarrow → Ba | ϵ \epsilon ϵ
B → \rightarrow → Db | D
D → \rightarrow → d | ϵ \epsilon ϵ
(1) 构建文法G的LL(1)分析表
(2) 判断句子adb是否为有效文法产生的语言,并给出分析过程
因为 S ⇒ \Rightarrow ⇒ A ⇒ \Rightarrow ⇒ B ⇒ \Rightarrow ⇒ D ⇒ ̸ \Rightarrow \not ⇏ S, 所以不存在左递归
因为将 A → \rightarrow → Ba | ϵ \epsilon ϵ 代入到 S → \rightarrow → AB 会含有回溯,B → \rightarrow → Db | D 这条产生式本身也含有回溯,所以要先消除回溯
消除左递归(本题不需要消除左递归):
P的产生式: P → \rightarrow → Pa 1 _1 1 | Pa 2 _2 2 | … | Pa m _m m | β 1 \beta_1 β1 | β 2 \beta_2 β2 | … | β n \beta_n βn
其中,每个a不等于 ϵ \epsilon ϵ, 每个 β \beta β不以P开头
P → β 1 P ‘ \rightarrow \beta_1 P^` →β1P‘ | β 2 P ‘ \beta_2 P^` β2P‘ | … | β n P ‘ \beta_n P^` βnP‘
P ‘ → a 1 P ‘ ^` \rightarrow a_1 P^` ‘→a1P‘ | a 2 P ‘ a_2 P^` a2P‘ | … | a m P ‘ a_m P^` amP‘
消除回溯(提左因子)
A的规则是: A → δ β 1 \rightarrow \delta \beta_1 →δβ1 | δ β 2 \delta \beta_2 δβ2 | … | δ β n \delta \beta_n δβn | γ 1 \gamma_1 γ1 | γ 2 \gamma_2 γ2 | … | γ m \gamma_m γm
其中,每个 γ \gamma γ不以 δ \delta δ开头
A → δ A ‘ \rightarrow \delta A^` →δA‘ | γ 1 \gamma_1 γ1 | γ 2 \gamma_2 γ2 | … | γ m \gamma_m γm
A ‘ → β 1 ^` \rightarrow \beta_1 ‘→β1 | β 2 \beta_2 β2 | … | β n \beta_n βn
通过消除回溯,将文法改写为:
S → \rightarrow → BS ‘ ^` ‘
S ‘ → ^` \rightarrow ‘→ aB | ϵ \epsilon ϵ
B → \rightarrow → DB ‘ ^` ‘
B ‘ → ^` \rightarrow ‘→ b | ϵ \epsilon ϵ
D → \rightarrow → d | ϵ \epsilon ϵ
通过拆分上边的产生式,得到:
- S → \rightarrow → BS ‘ ^` ‘
- S ‘ → ^` \rightarrow ‘→ aB
- S ‘ → ϵ ^` \rightarrow \epsilon ‘→ϵ
- B → \rightarrow → DB ‘ ^` ‘
- B ‘ → ^` \rightarrow ‘→ b
- B ‘ → ϵ ^` \rightarrow \epsilon ‘→ϵ
- D → \rightarrow → d
- D → ϵ \rightarrow \epsilon →ϵ
先看这八个产生式的FIRST集,如果FIRST集中有 ϵ \epsilon ϵ, 就要看相应产生式的FOLLOW集(例如产生式3、6、8)
终结符: {a, b, d, #}
非终结符: {S, S ‘ ^` ‘, B, B ‘ ^` ‘, D}
FIRST(S) = {a, b, d, ϵ \epsilon ϵ} FOLLOW(S) = {#}
FIRST(S ‘ ^` ‘) = {a, ϵ \epsilon ϵ} FOLLOW(S ‘ ^` ‘) = {#}
FIRST(B) = {d, b, ϵ \epsilon ϵ} FOLLOW(B) = {a, #}
FIRST(B ‘ ^` ‘) = {b, ϵ \epsilon ϵ} FOLLOW(B ‘ ^` ‘) = {a, #}
FIRST(D) = {d, ϵ \epsilon ϵ} FOLLOW(D) = {b, a, #}
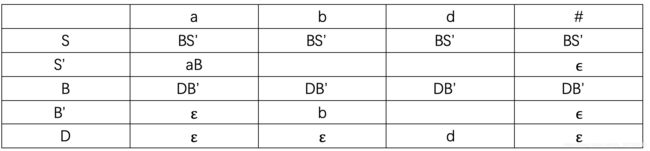
解释:
先看S这一行,因为第一条产生式 FIRST(BS ‘ ^` ‘) = {a, b, d, ϵ \epsilon ϵ},所以根据第二条规则,在a, b, d列填入BS ‘ ^` ‘,又因为 ϵ ∈ \epsilon \in ϵ∈ FIRST(BS ‘ ^` ‘), 所以还要看S的FOLLOW集,FOLLOW(S) = {#},所以在#这一列也填入BS ‘ ^` ‘
看S ‘ ^` ‘这一行,第二条产生式 FIRST(aB) = {a}, 根据第二条规则,在a这一列填入aB
又因为第三条产生式S ‘ → ϵ ^` \rightarrow \epsilon ‘→ϵ, ϵ ∈ \epsilon \in ϵ∈ FIRST(S ‘ ^` ‘), 所以看S ‘ ^` ‘的FOLLOW集,FOLLOW(S ‘ ^` ‘) = {#}, 所以在#这一列填入 ϵ \epsilon ϵ (这个 ϵ \epsilon ϵ 由S ‘ → ϵ ^` \rightarrow \epsilon ‘→ϵ这条产生式得出)
看B这一行,因为第四条产生式 FIRST(DB ‘ ^` ‘) = {d, b, ϵ \epsilon ϵ}, 根据第二条规则,在d, b列填入DB ‘ ^` ‘, 又因为 ϵ ∈ \epsilon \in ϵ∈ FIRST(DB ‘ ^` ‘), 所以看B的FOLLOW集,因为FOLLOW(B) = {a, #}, 所以在a, #列填入DB ‘ ^` ‘
看B ‘ ^` ‘这一行,因为第五条产生式 FIRST(b) = {b}, 所以在b列填入b
又因为第六条产生式B ‘ → ϵ ^` \rightarrow \epsilon ‘→ϵ, ϵ ∈ \epsilon \in ϵ∈ FIRST(B ‘ ^` ‘), 所以看B ‘ ^` ‘的FOLLOW集,FOLLOW(B ‘ ^` ‘) = {a, #}, 所以在a, #列填入 ϵ \epsilon ϵ
看D这一行,因为第七条产生式 FIRST(d) = {d}, 所以在d列填入d
又因为第八条产生式 D → ϵ \rightarrow \epsilon →ϵ, ϵ ∈ \epsilon \in ϵ∈ FIRST(D), 所以看D的FOLLOW集,FOLLOW(D) = {a, b, #}, 所以在a, b, #列填入 ϵ \epsilon ϵ
分析句子
栈STACK用于存放文法符号。分析开始时,栈底先放一个’#’, 然后,放进文法开始符号。同时,假定输入串之后也总有一个‘#’,标志输入串结束
对于任何(X, a), 总控程序每次都执行下述三种可能的动作之一
- 若 X = a = ‘#’, 则宣布分析成功,停止分析过程
- 若 X = a = ̸ \not ̸ ‘#’, 则把X从STACK栈顶逐出,让a指向下一个输入符号
- 若 X 是一个非终结符,则查看分析表M,若 M[A, a] 中存放着关于X的一个产生式,那么,首先把X逐出STACK栈顶,然后,把产生式的右部符号串按反序推进STACK栈(若右部符号为 ϵ \epsilon ϵ, 则意味不推什么东西进栈)

解释:
将开始符号S放入栈顶,要分析的句子放入输入,看分析表,当S遇到a时,根据第三条规则,执行 S → \rightarrow → BS ‘ ^` ‘ ,将S从栈顶逐出,将BS ‘ ^` ‘按反序推进栈,得到S ‘ ^` ‘B,看分析条,当B遇到a,根据第三条规则,执行 B → \rightarrow → DB ‘ ^` ‘, 将B从栈顶逐出,将DB ‘ ^` ‘按反序推进栈,得到B ‘ ^` ‘D, 看分析表 …(依此类推),当分析栈为终结符时,则根据第二条规则,分析栈栈顶和输入串第一个字符进行抵消,当分析栈栈顶为‘#’,且输入串为‘#’时,则宣布分析成功,停止分析过程