我的爬虫入门作(一)
目录
- 1. 工具
- 2. 正文
- 2.1 URL
- 2.2 思路
- 2.3 实现
- 2.3.1 获取各个章节URL
- 2.3.2 获取一章内容
- 2.3.3 写入内容
- 2.3.4 完整代码
- 3. 小结
- 3.1 html基础知识
- 3.2 Requests库方法
- 3.3 BeauifulSoup库
- 3.4 文件写入
- 3.5 各个章节URL
- 4. 参考
1. 工具
- 开发环境:Python3.7 + Visual Studio Code
- 浏览器:谷歌浏览器
- 安装Python库:requests——用来获取HTML、BeautifulSoup——用来解析HTML文档
2. 正文
2.1 URL
目标:在新笔趣阁网站上爬取烽火戏诸侯的《雪中悍刀行》(此处安利一波,烽火大大的文笔很好,天不生我李淳罡。。。。。跑偏了)。
目录页地址:http://www.xbiquge.la/0/745/
2.2 思路
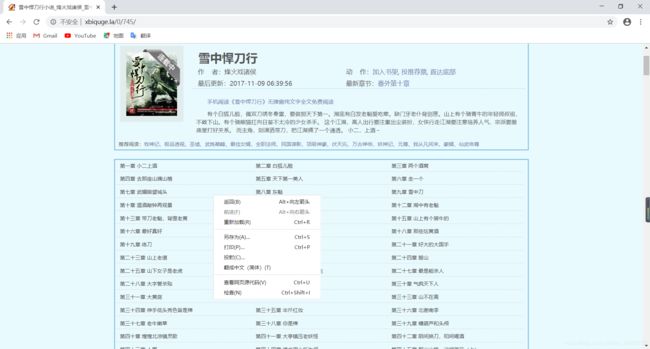
- 分析目录页源码,找到保存各个章节URL的标签:右击鼠标—>选择检查(N)或者按F12,网页的源码就出来了。 要找到目录的URL,将鼠标放在其中一章目录上右击鼠标,源码就会跳到对应的内容那里。可见各章节的URL存放在属性id=’'list"的div标签内,只需找到对应属性的div,再将其内包含的所有a标签找出,就是找齐所有章节的URL了。
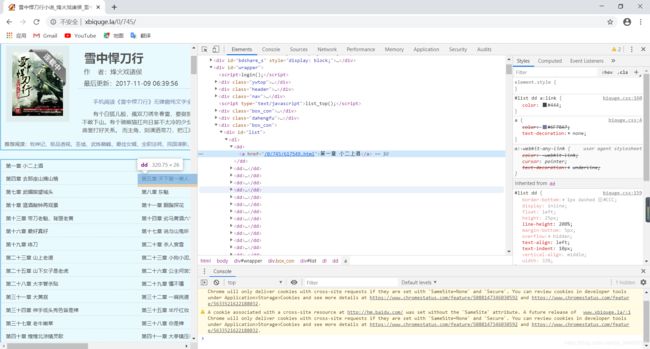

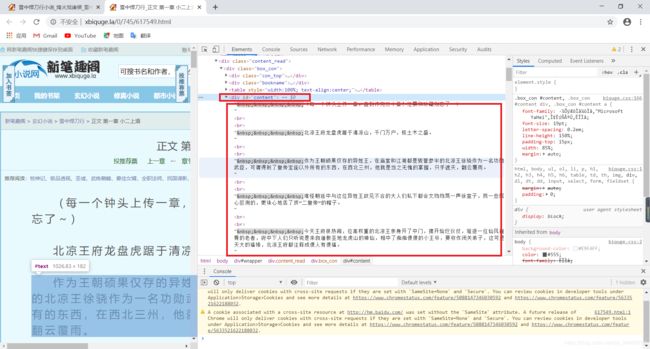
- 分析章节页内容:在内容(正文)上右击鼠标—>检查,跳到源码对应的内容。发现内容被存放在属性id="content"的div标签上,所以需要找到相应的div标签,再输出内容。
- 总体思路:在目录页获取各个章节的URL—>通过各个章节的URL遍历各个章节的内容—>写入文本文件(txt)里面
2.3 实现
2.3.1 获取各个章节URL
def __get_Link_chapter(self):
'''在目录页获得各个章节的url.
解析目录页,通过属性找到存放各个章节url的div标签,
获取各个章节的url并且返回
'''
# 当请求发生异常:连接或者超时错误,等待1S再尝试
for try_counter in range(10):
try:
req_lp = requests.get(self.__url_lp, timeout=10)
break
except ConnectionError:
print('尝试获取目录页ConnectionError:%d' % (try_counter+1))
except TimeoutError:
print('尝试获取目录页TimeoutError:%d' % (try_counter+1))
except:
print('尝试获取目录页OtherError:%d' % (try_counter+1))
time.sleep(1)
if try_counter >= 9:
print('获取目录页失败')
return
else:
try:
req_lp.encoding = req_lp.apparent_encoding
# 建立BeautifulSoup对象,指定解析器lxml
bs_lp = BeautifulSoup(req_lp.text, 'lxml')
# 找到所有对应属性的div标签
div_list = bs_lp.find_all('div', attrs=self.__attrs_div_lp)
# 找到所有的a标签
link_chapter = []
for div in div_list:
link_chapter += div.find_all('a')
return link_chapter
except TypeError:
print('目录页解析异常:TypeError')
return
except:
print('目录页解析异常:OtherError')
return
2.3.2 获取一章内容
def __get_content_chapter(self, link):
'''获取章节内容.
:param link:在目录页解析后得到的a标签
内含章节名和url
'''
name_chapter = link.string
url_chapter = self.__url_ws + link['href'] # 拼接得到章节页url
# 在链接和读取过程中,出现异常的处理方式
# 这里出现异常的话循环10次,等待1S重新读取
for try_counter in range(10):
try:
# 超时设置为10S
req_ct = requests.get(url_chapter, timeout=10)
break
except ConnectionError:
print('尝试获取章节链接:ConnectionError%d' % (try_counter+1))
except TimeoutError:
print('尝试获取章节链接:TimeoutError%d' % (try_counter+1))
except:
print('尝试获取章节链接:OtherError%d' % (try_counter+1))
time.sleep(1)
if try_counter >= 9:
print('获取链接失败:'+name_chapter)
return name_chapter+'\n\n'
else:
try:
req_ct.encoding = self.__encode
# 建立BeautifulSoup对象
bs_ct = BeautifulSoup(
req_ct.text, 'lxml')
# 将找到的div内容转换成文本格式,
# 并且将里面的 (不间断空格)替换成空格
# 将br标签替换成换行符
content = bs_ct.find(
'div', attrs=self.__attrs_div_ct)
content = str(content).replace('
','\n').replace('\xa0',' ')
content = BeautifulSoup(content,'lxml').get_text()
return name_chapter + '\n\n' + content + '\n\n'
except TypeError:
print('章节页解析异常:TypeError '+name_chapter)
return name_chapter+'\n\n'
except:
print('章节页解析异常:OtherError '+name_chapter)
return name_chapter+'\n\n'
2.3.3 写入内容
def write(self, path_save):
'''写下载的文件到指定路径.
:param path_save:指定的保存路径
'''
# 在指定的文件夹路路径之下新建与书名同名的文本文件
path_save = path_save + '\\' + self.__name + '.txt'
# 获取各个章节的URL
link_chapter = self.__get_Link_chapter()
if link_chapter is None:
pass
else:
# 打开文件
with open(path_save, 'w+', encoding=self.__encode) as file:
for chapter, link in enumerate(link_chapter):
# 获取章节内容
content_chapter = self.__get_content_chapter(link)
file.write(content_chapter)
sys.stdout.write('下载进度:%.1f%%' % float(
chapter/len(link_chapter)*100)+'\r')
print('<<'+self.__name+'>>下载完成')
2.3.4 完整代码
from bs4 import BeautifulSoup
import requests
import time
import sys
class fiction():
def __init__(self, name, url_ws, url_lp, encode, attrs_div_lp={}, attrs_div_ct={}):
self.__name = name # 名字
self.__url_ws = url_ws # 网站url
self.__url_lp = url_lp # 链接(目录)页的url
self.__attrs_div_lp = attrs_div_lp # 链接(目录页)存放各个章节链接的div标签属性
self.__attrs_div_ct = attrs_div_ct # 章节页存放内容的div标签属性
self.__encode = encode # 指定编码格式
def Update(self, name, url_ws, url_lp, encode, attrs_div_lp={}, attrs_div_ct={}):
'''重置参数
必须同时重置所有参数,否则可能出现错误
'''
self.__name = name # 名字
self.__url_ws = url_ws # 网站url
self.__url_lp = url_lp # 链接(目录)页的url
self.__attrs_div_lp = attrs_div_lp # 链接(目录页)存放各个章节链接的div标签属性
self.__attrs_div_ct = attrs_div_ct # 章节页存放内容的div标签属性
self.__encode = encode
def __get_Link_chapter(self):
'''在目录页获得各个章节的url.
解析目录页,通过属性找到存放各个章节url的div标签,
获取各个章节的url并且返回
'''
# 当请求发生异常:连接或者超时错误,等待1S再尝试
for try_counter in range(10):
try:
req_lp = requests.get(self.__url_lp, timeout=10)
break
except ConnectionError:
print('尝试获取目录页ConnectionError:%d' % (try_counter+1))
except TimeoutError:
print('尝试获取目录页TimeoutError:%d' % (try_counter+1))
except:
print('尝试获取目录页OtherError:%d' % (try_counter+1))
time.sleep(1)
if try_counter >= 9:
print('获取目录页失败')
return
else:
try:
req_lp.encoding = req_lp.apparent_encoding
# 建立BeautifulSoup对象,指定解析器lxml
bs_lp = BeautifulSoup(req_lp.text, 'lxml')
# 找到所有对应属性的div标签
div_list = bs_lp.find_all('div', attrs=self.__attrs_div_lp)
# 找到所有的a标签
link_chapter = []
for div in div_list:
link_chapter += div.find_all('a')
return link_chapter
except TypeError:
print('目录页解析异常:TypeError')
return
except:
print('目录页解析异常:OtherError')
return
def __get_content_chapter(self, link):
'''获取章节内容.
:param link:在目录页解析后得到的a标签
内含章节名和url
'''
name_chapter = link.string
url_chapter = self.__url_ws + link['href'] # 拼接得到章节页url
# 在链接和读取过程中,出现异常的处理方式
# 这里出现异常的话循环10次,等待1S重新读取
for try_counter in range(10):
try:
# 超时设置为10S
req_ct = requests.get(url_chapter, timeout=10)
break
except ConnectionError:
print('尝试获取章节链接:ConnectionError%d' % (try_counter+1))
except TimeoutError:
print('尝试获取章节链接:TimeoutError%d' % (try_counter+1))
except:
print('尝试获取章节链接:OtherError%d' % (try_counter+1))
time.sleep(1)
if try_counter >= 9:
print('获取链接失败:'+name_chapter)
return name_chapter+'\n\n'
else:
try:
req_ct.encoding = self.__encode
# 建立BeautifulSoup对象
bs_ct = BeautifulSoup(
req_ct.text, 'lxml')
# 将找到的div内容转换成文本格式,
# 并且将里面的 (不间断空格)替换成空格
# 将br标签换成换行符
content = bs_ct.find(
'div', attrs=self.__attrs_div_ct)
content = str(content).replace('
','\n').replace('\xa0',' ')
content = BeautifulSoup(content,'lxml').get_text()
return name_chapter + '\n\n' + content + '\n\n'
except TypeError:
print('章节页解析异常:TypeError '+name_chapter)
return name_chapter+'\n\n'
except:
print('章节页解析异常:OtherError '+name_chapter)
return name_chapter+'\n\n'
def write(self, path_save):
'''写下载的文件到指定路径.
:param path_save:指定的保存路径
'''
# 在指定的文件夹路路径之下新建与书名同名的文本文件
path_save = path_save + '\\' + self.__name + '.txt'
# 获取各个章节的URL
link_chapter = self.__get_Link_chapter()
if link_chapter is None:
pass
else:
# 打开文件
with open(path_save, 'w+', encoding=self.__encode) as file:
for chapter, link in enumerate(link_chapter):
# 获取章节内容
content_chapter = self.__get_content_chapter(link)
file.write(content_chapter)
sys.stdout.write('下载进度:%.1f%%' % float(
chapter/len(link_chapter)*100)+'\r')
print('<<'+self.__name+'>>下载完成')
if __name__ == '__main__':
start = time.time()
f = fiction(name='雪中悍刀行',
url_ws='http://www.xbiquge.la',
url_lp='http://www.xbiquge.la/0/745/',
attrs_div_lp={'id': 'list'},
attrs_div_ct={'id': 'content'},
encode='utf-8')
f.write(r'C:\Users\HP\Desktop\pytxt')
stop = time.time()
print('用时:%ds' % (stop-start))
3. 小结
3.1 html基础知识
html基础知识:菜鸟教程——HTML教程
3.2 Requests库方法
- get():获取服务器响应的内容。注意:最好设置超时时间,否者如果服务器无响应则一直会发送请求,程序就会一直卡在那个地方,而且不会报异常或者错误。

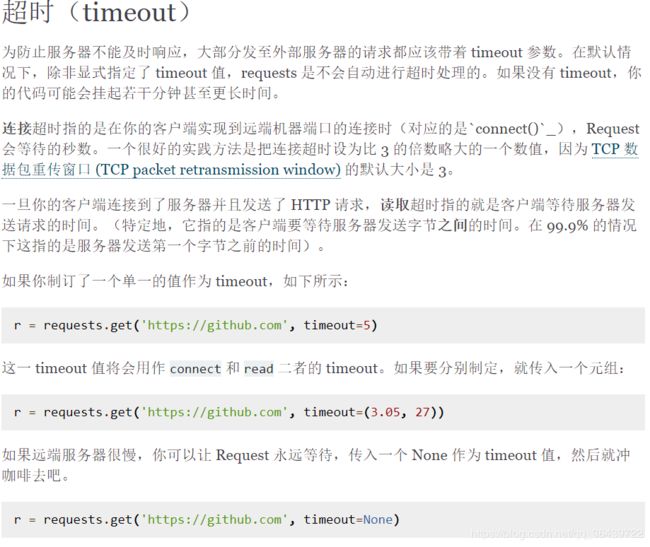
- 关于编码问题:最好是指定编码方式,根据Requests猜测的编码可能不准,后面写入文本的时候可能会发生异常。具体的分析可以参考知乎

html在源码head部分的charset就指定了编码,有时候说明的编码和实际使用的编码不一致,此时使用Response.apparent_encoding指定编码。
req_lp.encoding = req_lp.apparent_encoding
3. Requests库更多更详细可以参考官方文档:快速上手、高级用法、开发接口
3.3 BeauifulSoup库
- 建立BeauifulSoup对象:
bs_lp = BeautifulSoup(req_lp.text, 'lxml')
第一个参数时需要解析的HTML文档,第二个参数时指定的文档解析器


2. find_all()方法:寻找当前tag标签下符合过滤条件的所有标签,返回一个bs4.element.ResultSet类型,其实可以像列表形式使用。

3. 编码:使用BeautifulSoup之后,无论原来的HTML文档是gbk编码还是utf-8编码亦或是其他编码,全都会转成Unicode编码,可能是因为Unicode编码兼容所有的语言吧。
3.4 文件写入
Python文件操作:菜鸟教程——Python3 File(文件) 方法
3.5 各个章节URL
目录页的各个章节的URL是不完整的,需拼接上网站的URL才算是完整的URL。
url_chapter = self.__url_ws + link['href'] # 拼接得到章节页url
4. 参考
- Python3网络爬虫快速入门实战解析
- python3爬虫中文乱码问题求解?(beautifulsoup4)
第一次修改:将br标签换成换行符