JUC并发编程学习(十四)-任务拆分ForkJoin详解
分而治之思想
在古代,皇帝要想办成一件事肯定不会自己亲自去动手,而是把任务细分发给下面的大臣,下面的大臣也懒呀,于是把任务继续分成几个部分,继续下发,于是到了最后最终负责的人就完成了一个小功能。上面的领导再把这些结果一层一层汇总,最终返回给皇帝。这就是分而治之的思想。
什么是ForkJoin
从JDK1.7开始,Java提供ForkJoin框架用于并行执行任务,它的思想就是将一个大任务分割成若干小任务,最终汇总每个小任务的结果得到这个大任务的结果。简单的理解,ForkJoin是一个可对任务进行拆分,分而治之的类。
ForkJoinPool
既然任务是被逐渐的细化的,那就需要把这些任务存在一个池子里面,这个池子就是ForkJoinPool,它与其它的ExecutorService区别主要在于它使用“工作窃取“,那什么是工作窃取呢?
一个大任务会被划分成无数个小任务,这些任务被分配到不同的队列,这些队列有些干活干的块,有些干得慢。于是干得快的,一看自己没任务需要执行了,就去隔壁的队列里面拿去任务执行。
ForkJoin特点:工作窃取
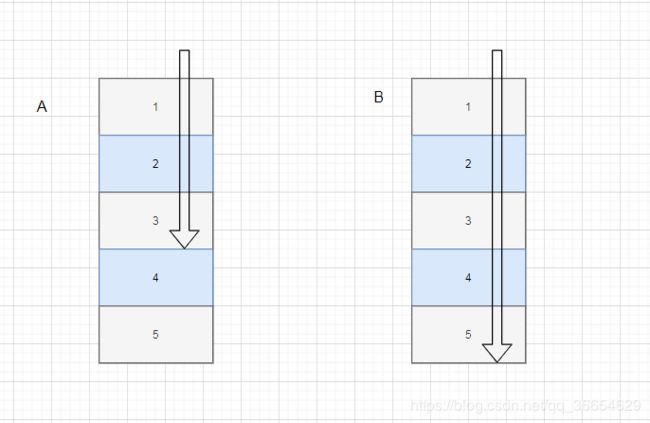
A执行队列中的任务1,2,3,4,5,执行到3
B执行任务,已先执行完成,则帮A执行任务(从A任务的尾部开始窃取任务执行)。
ForkJoinTask
ForkJoinTask就是ForkJoinPool里面的每一个任务。他主要有两个子类:RecursiveAction和RecursiveTask。然后通过fork()方法去分配任务执行任务,通过join()方法汇总任务结果。
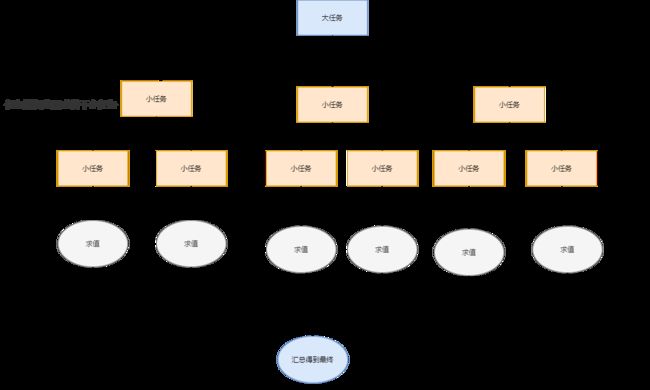
他有两个子类,使用这两个子类都可以实现我们的任务分配和计算。
(1)RecursiveAction 一个递归无结果的ForkJoinTask(没有返回值)
(2)RecursiveTask 一个递归有结果的ForkJoinTask(有返回值)
ForkJoinPool由ForkJoinTask数组和ForkJoinWorkerThread数组组成,ForkJoinTask数组负责存放程序提交给ForkJoinPool的任务,而ForkJoinWorkerThread数组负责执行这些任务。
下面我们看看如何使用的。
RecursiveTask
RecursiveTask :有返回结果
第一步:创建MyRecursiveTask类继承RecursiveTask,重写compute方法
package com.jp.forkjointest;
import java.util.concurrent.RecursiveTask;
/**
* @className:
* @PackageName: com.jp.forkjointest
* @author: youjp
* @create: 2020-06-14 13:17
* @description: TODO
* 求和计算任务
* 测试递归拆分任务有返回结果。泛型是计算后返回的结果类型
* @Version: 1.0
*/
public class MyRecursiveTask extends RecursiveTask {
//开始值
private long start;
//结束值
private long end;
//临界值
private static final long temp = 10000L;
public MyRecursiveTask(long start, long end) {
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
//如果任务小的不能拆分,就直接计算
if (end - start <= temp) {
long sum = 0;
for (long i = start; i <= end; i++) {
sum += i;
}
return sum;
} else {
//获取中间值
long middle = (end + start) / 2;
// fork()会不断的循环
//第一个任务
MyRecursiveTask task1 = new MyRecursiveTask(start, middle);
task1.fork(); //拆分任务,将任务压入线程队列
//第2个任务
MyRecursiveTask task2 = new MyRecursiveTask(middle + 1, end);
task2.fork();//拆分任务,将任务压入线程队列
//合并结果
return task1.join()+task2.join();
}
}
}
二、使用ForkJoinPool进行执行
task要通过ForkJoinPool来执行,分割的子任务也会添加到当前工作线程的双端队列中,
进入队列的头部。当一个工作线程中没有任务时,会从其他工作线程的队列尾部获取一个任务(工作窃取)。
package com.jp.forkjointest;
import com.sun.org.apache.xerces.internal.dom.PSVIAttrNSImpl;
import java.util.concurrent.ForkJoinPool;
/**
* @className:
* @PackageName: com.jp.forkjointest
* @author: youjp
* @create: 2020-06-14 13:39
* @description: 计算1到10,0000,0000的和
*
* @Version: 1.0
*/
public class Test {
public static void main(String[] args) {
long startTime = System.currentTimeMillis();
//1.创建forkjoinpool
ForkJoinPool pool=new ForkJoinPool();
//2.创建ForkJoinTask
MyRecursiveTask recursiveTask=new MyRecursiveTask(0L,10_0000_0000L);
//3.ForkJoinPoll对象调用invoke执行,并将ForkJoinTask对象放入ForkJoinPool中
long sum= pool.invoke(recursiveTask);
long endTime = System.currentTimeMillis();
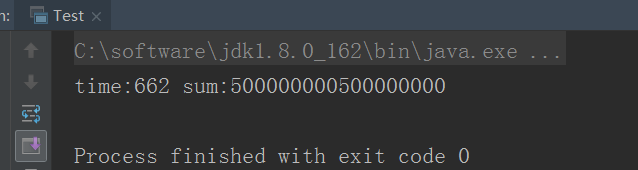
System.out.println("time:"+(endTime-startTime)+" sum:"+sum);
}
}
计算结果
性能测试
package com.jp.forkjointest;
import com.sun.org.apache.xerces.internal.dom.PSVIAttrNSImpl;
import java.util.concurrent.ForkJoinPool;
import java.util.stream.LongStream;
/**
* @className:
* @PackageName: com.jp.forkjointest
* @author: youjp
* @create: 2020-06-14 13:39
* @description: 计算1到10,0000,0000的和
*
* @Version: 1.0
*/
public class Test {
public static void main(String[] args) {
//test1();
test2();
//test3();
}
//普通方法计算求和
public static void test1(){
long startTime = System.currentTimeMillis();
long sum = 0L;
for (long i = 0L; i <= 10_0000_0000L; i++) {
sum += i;
}
long endTime = System.currentTimeMillis();
System.out.println("方法1--time:"+(endTime-startTime)+" sum:"+sum);
}
//2.使用forkjoin任务拆分并行求和
public static void test2(){
long startTime = System.currentTimeMillis();
//1.创建forkjoinpool
ForkJoinPool pool=new ForkJoinPool();
//2.创建ForkJoinTask
MyRecursiveTask recursiveTask=new MyRecursiveTask(0L,10_0000_0000L);
//3.ForkJoinPoll对象调用invoke执行,并将ForkJoinTask对象放入ForkJoinPool中
long sum= pool.invoke(recursiveTask);
long endTime = System.currentTimeMillis();
System.out.println("方法2--time:"+(endTime-startTime)+" sum:"+sum);
}
//3. Stream并行流测试
public static void test3(){
long startTime=System.currentTimeMillis();
long sum=LongStream.rangeClosed(0L,10_0000_0000L).parallel().reduce(0L,Long::sum);
long endTime = System.currentTimeMillis();
System.out.println("方法3--time:"+(endTime-startTime)+" sum:"+sum);
}
}
测试了一下,按理来说,strem并行流计算效率最高,然后forkjoin其次,但我的电脑不知道什么原因,没有测试出预期接口。。。
RecursiveAction
RecursiveAction在exec后是不会保存返回结果,因此RecursiveAction与RecursiveTask区别在与RecursiveTask是有返回结果而RecursiveAction是没有返回结果。
例子:控制台打印结果,遍历指定目录(含子目录)寻找指定txt结尾的文件
public class FindDirsFiles extends RecursiveAction{
private File path;//当前任务需要搜寻的目录
public FindDirsFiles(File path) {
this.path = path;
}
public static void main(String [] args){
try {
// 用一个 ForkJoinPool 实例调度总任务
ForkJoinPool pool = new ForkJoinPool();
FindDirsFiles task = new FindDirsFiles(new File("F:/"));
pool.execute(task);//异步调用
System.out.println("Task is Running......");
Thread.sleep(1);
//为了证明异步执行其他步骤
int otherWork = 0;
for(int i=0;i<100;i++){
otherWork = otherWork+i;
}
System.out.println("Main Thread done sth......,otherWork="+otherWork);
task.join();//阻塞的方法,等待异步完成
System.out.println("Task end");
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
protected void compute() {
List subTasks = new ArrayList<>();//定义子任务个数
File[] files = path.listFiles();//获取目录所有文件和目录
if(files!=null) {
for(File file:files) {
if(file.isDirectory()) {//如果是目录,就加入子任务中查询
subTasks.add(new FindDirsFiles(file));
}else {
//遇到文件,检查
if(file.getAbsolutePath().endsWith("txt")) {
System.out.println("文件:"+file.getAbsolutePath());
}
}
}
if(!subTasks.isEmpty()) {
for(FindDirsFiles subTask:invokeAll(subTasks)) {
subTask.join();//等待子任务执行完成
}
}
}
}
}
ForJoin注意点
使用ForkJoin将相同的计算任务通过多线程的进行执行。从而能提高数据的计算速度。在google的中的大数据处理框架mapreduce就通过类似ForkJoin的思想。通过多线程提高大数据的处理。但是我们需要注意:
- 使用这种多线程带来的数据共享问题,在处理结果的合并的时候如果涉及到数据共享的问题,我们尽可能使用JDK为我们提供的并发容器。
- 在使用JVM的时候我们要考虑OOM的问题,如果我们的任务处理时间非常耗时,并且处理的数据非常大的时候。会造成OOM。
- ForkJoin也是通过多线程的方式进行处理任务。那么我们不得不考虑是否应该使ForkJoin。因为当数据量不是特别大的时候,我们没有必要使用ForkJoin。因为多线程会涉及到上下文的切换。所以数据量不大的时候使用串行比使用多线程快。