论文阅读:TensorMask: A Foundation for Dense Object Segmentation
Tensor Mask
文章
何恺明还有RBG大神的新作(一作陈鑫磊这个名字也很熟悉啊)。之前在instance segmentation方面只看过mask R-CNN的论文,看到这篇文章是dense object segmentation,由于在做one-stage detector方面的工作,所以想看看这篇论文能不能对自己有什么启发。
文章的motivation在于:object detection中有dense的方法(如yolo,ssd,retinanet),也有R-CNN这类two-stage的方法;然而在instance segmentation中,目前却没有dense方面的工作,本文的目的就是要用dense的方法来做一下instance segmentation,希望能促进这方面的研究。我对dense object detection的理解就是,直接通过一个end-to-end的网络得到一个HxWxC的输出,这个输出就代表了原图的HxW个位置上的检测结果(但是一个位置上可能又有多个结果,比如yolo一个位置有9个anchor对应9个结果),dense detection比较好做的原因之一就是,bounding box只需要4个变量就可以表示,然而instance segmentation的mask就没那么简单了,因此本文要解决的第一个问题就是,怎么利用CNN的输出tensor来表示dense的segmentation结果,本文提出用一个4D的tensor来表示。
本文4D的tensor形状具体为(V,U,H,W),(H,W)代表原图上不同的位置,(V,U)则代表一个mask。要理解好这个4D的tensor,一个很重要的点是(H,W)和(V,U)对应到原图上不一定是(H,W)和(V,U)pixel大小的区域。比如对于ResNet-50,stride为16,因此在HxW的subtensor上移动1个pixel对应原图上移动16个pixel,这样才能保证HxW能均匀分布在原图上。文章称这个为unit of length,H,W方向的为δ_HW,V,U方向上的为δ_VU,如果δ_VU=1,则对应原图上一个VxU的window的mask,如果δ_VU=2,则对应一个2Hx2W的window,至于具体δ怎么确定,这在下面的多尺度部分会说到。另外定义α=δ_VU/δ_HW。
文章研究了两种用4Dtensor表示segmentation结果的方法,如下图

1. Natural representation:(V,U)的sub-tensor表示中心在原图(y,x)处的一个mask
2. Aligned representation:(V,U)的sub-tensor表示VxU个在(y,x)处有overlap的mask在(y,x)处的mask值。
PS:对于1来说,(v,u,y,x)取值范围是
表示的应该是原图上(yδ_HW+vδ_VU, xδ_HW+uδ_VU)的mask value,如果以δ_HW为unit的话,则是代表(y+αv,x+αu)位置的mask value。表示2的好处在于,对于某个(y,x)位置,subtensor(V,U)表示的始终是该位置的mask value,也就是在像素上aligned,这个性质在进行upsample的时候非常好,但是作为segmentation结果的话却不是很直观。因此文章还提出在两种表示方法之间的变换:
align2nat:
![]()
nat2align:
![]()
文章设计了一个tensor bipyramid(TBP),motivation就是分割小物体的mask可以小一些但是分布得要密集,而对于大物体,mask则要大一些,但分布较稀疏。文章还与**feature pyramid(FP)**进行了对比如下:
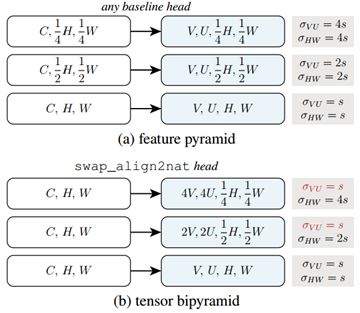
第一个明显不同就是TBP每一个level的特征尺寸相同,是使用下图的结构做到的
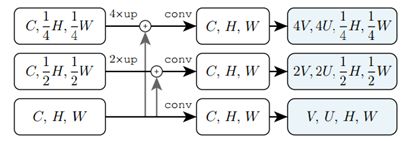
还有就是为了在不同level得到不同尺寸的mask,FP使用的相同的VU不同的δ_VU,而TBP使用了不同的VU,相同的δ_VU。
要达到这样的输出效果,文章分为了两步:1.每一层的第一步输出都是VxUxHxW;2.对第一步的输出进行分别在V,U进行upsample和在H,W进行downsample。文章为第一步设计了如下几种mask prediction head:
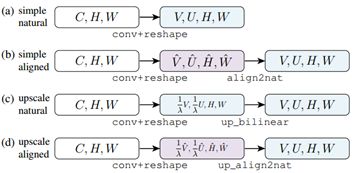
第二步则需要用到文章定义的一个swap_align2nat_op的操作,而这个操作又需要up_align2nat来构成,具体如下:

当然两步之间需要先进行nat2align的变换。另外文章再进行swap_align2nat_op的时候,取了一个巧,因为subsample需要丢弃掉一部分数据,所以在前面up_align2nat的时候,并没有进行全部的计算(λ^2*VUHW),而只是进行了最后不会丢弃的数据的计算(VUHW),减少了很多的计算量。
关于训练的话,很重要的就是如何确定正负样本和损失函数。正样本的确定有如下3条原则:
1. 某个VxU的window必须包含住一个mask,且这个mask的长边至少要是window的1/2。
2. mask的bbox中心应该落在这个window里面。
3. 对于这一个window,只有1个mask满足上述的条件。
满足了这三个条件的window就可以设置为正样本,然后将mask的每个位置看做一个分类任务,使用γ=2,α=5的focal loss。
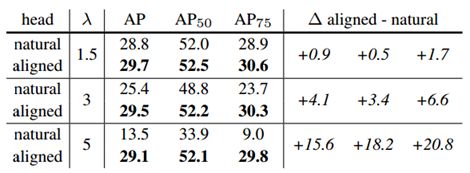
实验部分,文章做了蛮多比较的。首先是mask prediction head的比较,对于没有进行upscale的head

可以看出是否进行align的差距并不大,但对于更effective的upscale head来说,align带来的好处就很大了,而且在upscale越大时越明显。
对于upsample,文章也比较了nearest和bilinear两种方式,
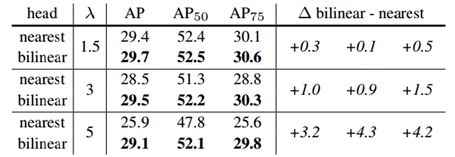
另外为了验证tensor bipyramid的有效性,也和feature pyramid进行了比较
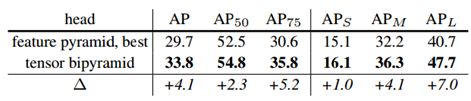
和yolo,ssd采用多个anchor一样,文章也试验了一个位置设置2个window,效果也得到了提高
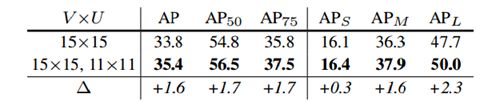
最后当然是和mask R-CNN的比较
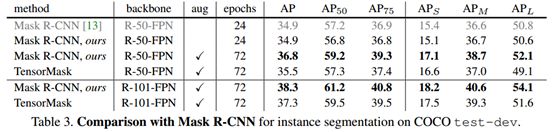
可以看到ap其实差得不多,但关键在于,tensorpyramid的速度还有待提升,文章说在V100上是0.38s/im,而mask R-CNN是0.09s/im,但我们也要知道tensor pyramid由于是dense的,计算了超过100k个window的mask,而mask R-CNN只计算了小于100个box的结果,所以对tensor mask的加速是接下来很重要的也很有意义的工作。
关于NMS其实我觉得文章也有一定的问题,本文对mask的NMS是用对bbox的NMS代替了,我觉得也可以有所改进。但总得来说,这篇文章真的是很有意思也很有意义的一个工作,填补了在instance segmentation这块儿没有dense方面工作的空白。赞!