目录
本文将在学习Python中模块的概念的基础上,通过一些示例来继续学习模块标准模板、import、from…import 、深入理解模块、__name__属性、包等知识。
模块标准模板
在了解了Python中的模块知识以后,就来看一下Python中的模块标准模板。例子中模块名:17my_module.py。
如下:
# encoding: utf-8
#! F:\python_projects\17my_module.py
# 文件名: 17my_module.py
"""
Here is document note
这里是文档注释
"""
__author__ = 'Guang TouQiang'
import sys
print('命令行参数如下:')
for i in sys.argv:
print(i)
print('\n\nPython 路径为:', sys.path, '\n')
解释如下:
第1、第2和第3行是标准注释。其中:
第1行注释表示当前模块采用的是标准utf-8编码。
第2行注释表示可以让这个17my_module.py文件直接在Unix/Linux/Mac上运行。
第3行注释表示本模块名;
第4-7行是一个字符串,表示模块的文档注释,任何模块代码的第一个字符串都被视为模块的文档注释;
第8行使用_author_变量把作者写进去,这样当你公开源代码后别人就可以看到你的大名;
以上就是Python模块的标准文件模板,当然也可以全部删掉不写,但是,按标准办事肯定没错。
后面开始就是真正的代码部分。
你可能注意到了,使用sys模块的第一步,就是导入该模块:
import sys
导入sys模块后,我们就有了变量sys指向该模块,利用sys这个变量,就可以访问sys模块的所有功能。sys模块有一个argv变量,用list存储了命令行的所有参数。
import 语句
想使用 Python 源文件,只需在另一个源文件里执行 import 语句,语法如下:
import module1[, module2[,... moduleN]
当解释器遇到 import 语句,如果模块在当前的搜索路径就会被导入。
搜索路径是一个解释器会先进行搜索的所有目录的列表。例如:想要导入模块my_pi,需要把命令放在脚本的顶端:
my_pi.py源码如下:
# 割圆求π
# 获取正2N边形长度
def get_n(n):
# 正6边形边长等于圆的半径,假设圆的半径为1,则边长也为1
if n == 6.0:
print("L6 = 1.0")
return 1.0
else:
a = n / 2
result = math.sqrt(2 - math.sqrt(4 - math.pow(get_n(a), 2)))
print(r'内接正' + str(n).replace('.0', '') + r'边形边长 = ' + str(result))
return result
# 获取π
def get_pi(n):
return n * get_n(n) / 2
在my_module模块中导入,就可以使用了:
import my_pi
# 获取π
print(r'π = ' + str(my_pi.get_pi(384*8*8)))
运行结果如下:
L6 = 1.0
内接正12边形边长 = 0.5176380902050416
内接正24边形边长 = 0.2610523844401031
内接正48边形边长 = 0.13080625846028635
内接正96边形边长 = 0.0654381656435527
内接正192边形边长 = 0.03272346325297234
内接正384边形边长 = 0.01636227920787303
内接正768边形边长 = 0.008181208052471188
内接正1536边形边长 = 0.004090612582339534
内接正3072边形边长 = 0.0020453073607051096
内接正6144边形边长 = 0.00102265381399354
内接正12288边形边长 = 0.0005113269236068993
内接正24576边形边长 = 0.0002556634639747083
π = 3.1415926453212157
一个模块只会被导入一次,不管你执行了多少次import。这样可以防止导入模块被一遍又一遍地执行。
当我们使用import语句的时候,Python解释器是怎样找到对应的文件的呢?
这就涉及到Python的搜索路径,搜索路径是由一系列目录名组成的,Python解释器就依次从这些目录中去寻找所引入的模块。这看起来很像环境变量,事实上,也可以通过定义环境变量的方式来确定搜索路径。搜索路径是在Python编译或安装的时候确定的,安装新的库应该也会修改。
from…import 语句
Python的from语句让你从模块中导入一个指定的部分到当前命名空间中,语法如下:
from modname import name1[, name2[, ... nameN]]
例如:my_pi.py模块中,添加了两个函数,get_standard_pi、get_simple_pi源码如下:
# 割圆求π
# 获取正2N边形长度
def get_n(n):
# 正6边形边长等于圆的半径,假设圆的半径为1,则边长也为1
if n == 6.0:
print("L6 = 1.0")
return 1.0
else:
a = n / 2
result = math.sqrt(2 - math.sqrt(4 - math.pow(get_n(a), 2)))
print(r'内接正' + str(n).replace('.0', '') + r'边形边长 = ' + str(result))
return result
# 获取标准pi
def get_standard_pi():
return 3.1415926
# 获取简单Pi
def get_simple_pi():
return 3.14
# 利用割圆方法获取π
def get_pi(n):
return n * get_n(n) / 2
错误示例
在模块my_module中,这次只导入get_standard_pi函数。导入get_standard_pi,仍调用my_pi.get_pi(),则会报错NameError,代码如下:
from my_pi import get_standard_pi
# 获取π
print(r'π = ' + str(my_pi.get_pi(384*8*8)))
运行结果:
Traceback (most recent call last):
File "F:/python_projects/17my_module.py", line 13, in
print(r'π = ' + str(my_pi.get_pi(384*8*8)))
NameError: name 'my_pi' is not defined
原因是:由于from my_pi import get_standard_pi,这个声明不会把整个my_pi模块导入到当前的命名空间中,它只会将my_pi里的get_standard_pi函数引入进来。而实际调用时,调用的get_pi(),所以提示:NameError: name 'my_pi' is not defined,my_pi未定义。
正确示例
在模块my_module中,这次只导入get_standard_pi()函数。导入get_standard_pi,仍调用my_pi.get_standard_pi(),代码如下:
from my_pi import get_standard_pi
# 获取π
print(r'π = ' + str(get_standard_pi()))
运行结果:
π = 3.1415926
From…import* 语句
把一个模块的所有内容全都导入到当前的命名空间也是可行的,只需使用如下声明:
from module_name import *
这提供了一个简单的方法来导入一个模块中的所有项目。然而这种声明不该被过多地使用,此处也不再举例。
深入理解模块
每个模块有各自独立的符号表,在模块内部为所有的函数当作全局符号表来使用。所以,模块的作者可以放心大胆的在模块内部使用这些全局变量,而不用担心把其他用户的全局变量搞污染。
在一个模块(或者脚本,或者其他地方)的最前面使用 import 来导入一个模块,当然这只是一个惯例,而不是强制的。被导入的模块的名称将被放入当前操作的模块的符号表中。
例如:上面例子中的
import my_pi
这样做并没有把直接定义在my_pi中的函数名称写入到当前符号表里,只是把模块my_pi的名字写到了那里。
还有一种导入的方法,可以使用 import 直接把模块内(函数,变量的)名称导入到当前操作模块。比如:
from my_pi import get_standard_pi
这种导入的方法不会把被导入的模块的名称放在当前的字符表中(所以在这个例子里面,my_pi这个名称是没有定义的)。
这还有一种方法,可以一次性的把模块中的所有(函数,变量)名称都导入到当前模块的字符表:
from module_name import *
这将把所有的名字都导入进来,但是那些由单一下划线_开头的名字不在此例。大多数情况, Python程序员不使用这种方法,因为引入的其它来源的命名,很可能覆盖了已有的定义。
这也是三种导入方式的重要区别。
__name__属性
一个模块被另一个程序第一次引入时,其主程序将运行。如果我们想在模块被引入时,模块中的某一程序块不执行,我们可以用__name__属性来使该程序块仅在该模块自身运行时执行。
基于此,设计如下实例进行验证:
我们创建2个模块:my_name.py、18name.py,模块名分别:my_name、18name;在18name模块中导入my_name模块。
其中my_name.py源码如下:
# 定义一个测试函数
def name_test():
if __name__ == '__main__':
print('A: __name__ is __main__')
else:
print('B: __name__ is ', __name__)
18name.py源码如下:
# 导入my_name模块
import my_name
# 调用my_name模块中的name_test函数
my_name.name_test()
运行模块18name,运行结果如下:
B: __name__ is my_name
修改:my_name.py源码如下:
# 定义一个测试函数
def name_test():
if __name__ == '__main__':
print('A: __name__ is __main__')
else:
print('B: __name__ is ', __name__)
# 在本模块中调用定义好的测试函数
name_test()
运行模块my_name,运行结果如下:
A: __name__ is __main__
说明: 每个模块都有一个__name__属性,当其值是'__main__'时,表明该模块自身在运行,否则是被引入。
提示:__name__ 与 __main__ 底下是双下划线, _ _ 是这样去掉中间的那个空格。
包
通过前面的学习,我们已经知道,在解决和其他人的模块同名时,我们引入了包。此时,模块的名字就变成了:包名.模块名。
注意:
目录只有包含一个叫做__init__.py的文件才会被认作是一个包,主要是为了避免一些滥俗的名字(比如叫做 string)不小心的影响搜索路径中的有效模块。
最简单的情况,放一个空的 __init__.py就可以了。当然这个文件中也可以包含一些初始化代码或者为(将在后面介绍的) __all__变量赋值。
注意当使用from package import item这种形式的时候,对应的item既可以是包里面的子模块(子包),或者包里面定义的其他名称,比如函数,类或者变量。
import语法会首先把item当作一个包定义的名称,如果没找到,再试图按照一个模块去导入。如果还没找到,恭喜,一个ImportError异常被抛出了。
反之,如果使用形如import item.subitem.subsubitem这种导入形式,除了最后一项,都必须是包,而最后一项则可以是模块或者是包,但是不可以是类,函数或者变量的名字。
从一个包中导入*
使用形如from package.xxx import *时,Python会做哪些事情呢?
Python 会进入文件系统,找到这个包里面所有的子模块,一个一个的把它们都导入进来。
但是很不幸,这个方法在 Windows平台上工作的就不是非常好,因为Windows是一个大小写不区分的系统。
在这类平台上,没有人敢担保一个叫做 ECHO.py 的文件导入为模块 echo 还是 Echo 甚至 ECHO。
(例如,Windows 95就很讨厌的把每一个文件的首字母大写显示)而且 DOS 的 8+3 命名规则对长模块名称的处理会把问题搞得更纠结。
为了解决这个问题,只能烦劳包的作者提供一个精确的包的索引了。
导入语句遵循如下规则:
如果包定义文件__init__.py存在一个叫做__all__的列表变量,那么在使用from package import *的时候就把这个列表中的所有名字作为包内容导入。
作为包的作者,可别忘了在更新包之后保证__all__也更新了啊。你说我就不这么做,我就不使用导入*这种用法,好吧,没问题,谁让你是老板呢。
例如:我们项目中有一个登陆包,包名:login。
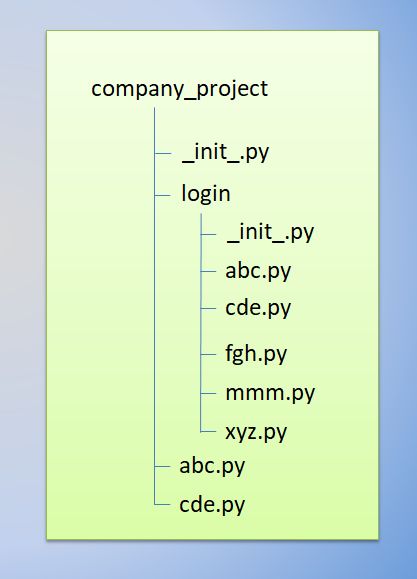
如上图,在
company_project/login/__init__.py中包含如下代码:
__all__ = ["abc", "cde", "xyz"]
这表示当你使用
from company_project.login import *这种用法时,你只会导入包里面这三个子模块。
如果 __all__ 真的没有定义,那么使用from company_project.login import *这种语法的时候,就不会导入包 login 里的任何子模块。他只是把包company_project.login和它里面定义的所有内容导入进来(可能运行__init__.py里定义的初始化代码)。这会把 __init__.py 里面定义的所有名字导入进来。并且他不会破坏掉我们在这句话之前导入的所有明确指定的模块。
通常我们并不主张使用*这种方法来导入模块,因为这种方法经常会导致代码的可读性降低。不过这样倒的确是可以省去不少敲键的功夫,而且一些模块都设计成了只能通过特定的方法导入。
记住,使用from Package import specific_submodule这种方法永远不会有错。事实上,这也是推荐的方法。除非是你要导入的子模块有可能和其他包的子模块重名。
如果在结构中login包是一个子包(比如这个例子中对于包company_project来说),而你又想导入兄弟包(同级别的包,图中没有,假设有个网络请求的network包)你就得使用导入绝对的路径来导入。比如,如果模块company_project.login 要使用包company_project.network中的模块query,你就要写成 from company_project.network import query。
无论是隐式的还是显式的相对导入都是从当前模块开始的。主模块的名字永远是"__main__",一个Python应用程序的主模块,应当总是使用绝对路径引用。
包还提供一个额外的属性__path__。这是一个目录列表,里面每一个包含的目录都有为这个包服务的__init__.py,你得在其他__init__.py被执行前定义哦。可以修改这个变量,用来影响包含在包里面的模块和子包。
说明: 这个功能并不常用,一般用来扩展包里面的模块。
小结
本文在学习Python3中模块概念的基础上,通过一些示例来继续学习了模块标准模板、import、from…import 、深入理解模块、__name__属性、包等知识。
当前所在位置(局部视图)
当前所在位置(全局视图)