轻量级实时语义分割经典BiSeNet
基于轻量化网络模型的设计作为一个热门的研究方法,许多研究者都在运算量、参数量和精度之间寻找平衡,希望使用尽量少的运算量和参数量的同时获得较高的模型精度。目前,轻量级模型主要有SqueezeNet、MobileNet系列和ShuffleNet系列等,这些模型在图像分类领域取得了不错的效果,可以作为基本的主干网络应用于语义分割任务当中。
然而,在语义分割领域,由于需要对输入图片进行逐像素的分类,运算量很大。通常,为了减少语义分割所产生的计算量,通常而言有两种方式:减小图片大小和降低模型复杂度。减小图片大小可以最直接地减少运算量,但是图像会丢失掉大量的细节从而影响精度。降低模型复杂度则会导致模型的特征提取能力减弱,从而影响分割精度。
本文对之前的实时性语义分割算法进行了总结,发现当前主要有三种加速方法:
1)通过剪裁或 resize 来限定输入大小,以降低计算复杂度。尽管这种方法简单而有效,空间细节的损失还是让预测打了折扣,尤其是边界部分,导致度量和可视化的精度下降;
2)通过减少网络通道数量加快处理速度,尤其是在骨干模型的早期阶段,但是这会弱化空间信息。
3)为追求极其紧凑的框架而丢弃模型的最后阶段(比如ENet)。该方法的缺点也很明显:由于 ENet 抛弃了最后阶段的下采样,模型的感受野不足以涵盖大物体,导致判别能力较差。
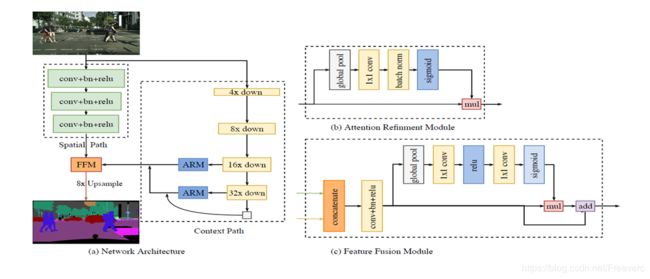
首先,设计了一个带有小步长的空间路径来保留空间位置信息生成高分辨率的特征图;同时设计了一个带有快速下采样率的语义路径来获取客观的感受野。在这两个模块之上引入一个新的特征融合模块将二者的特征图进行融合,实现速度和精度的平衡。
具体来说,空间路径Spatial Path使用较多的 Channel、较浅的网络来保留丰富的空间信息生成高分辨率特征;上下文路径Context Path使用较少的 Channel、较深的网络快速 downsample来获取充足的 Context。基于这两路网络的输出,文中还设计了一个Feature Fusion Module(FFM)来融合两种特征。
Spatial Path
减少下采样次数,只包含三个 stride=2 的 Conv+BN+Relu,输出特征图的尺寸为原图的 1/8。由于它利用了较大尺度的特征图,所以可以编码比较丰富的空间信息。
class SpatialPath(nn.Module):
def __init__(self, *args, **kwargs):
super(SpatialPath, self).__init__()
self.conv1 = ConvBNReLU(3, 64, ks=7, stride=2, padding=3)
self.conv2 = ConvBNReLU(64, 64, ks=3, stride=2, padding=1)
self.conv3 = ConvBNReLU(64, 64, ks=3, stride=2, padding=1)
self.conv_out = ConvBNReLU(64, 128, ks=1, stride=1, padding=0)
self.init_weight()
def forward(self, x):
feat = self.conv1(x)
feat = self.conv2(feat)
feat = self.conv3(feat)
feat = self.conv_out(feat)
return featContext Path
语义路径的作用则是获取足够大的感受野,从而判断目标的分类。该模块先采用一个轻量级网络如Xception,随后加入全局平均池化,处理轻量级网络的输出,以获取最大的感受野。算法最后使用注意力精炼模块(Attention Refinement Module,ARM)将全局平均池化的输出结果上采样,与轻量级网络的输出结合,在几乎不增加计算量的情况下优化语义路径的输出结果。

class ContextPath(nn.Module):
def __init__(self, *args, **kwargs):
super(ContextPath, self).__init__()
self.resnet = Resnet18()
self.arm16 = AttentionRefinementModule(256, 128)
self.arm32 = AttentionRefinementModule(512, 128)
self.conv_head32 = ConvBNReLU(128, 128, ks=3, stride=1, padding=1)
self.conv_head16 = ConvBNReLU(128, 128, ks=3, stride=1, padding=1)
self.conv_avg = ConvBNReLU(512, 128, ks=1, stride=1, padding=0)
self.init_weight()
def forward(self, x):
H0, W0 = x.size()[2:]
feat8, feat16, feat32 = self.resnet(x)
H8, W8 = feat8.size()[2:]
H16, W16 = feat16.size()[2:]
H32, W32 = feat32.size()[2:]
avg = F.avg_pool2d(feat32, feat32.size()[2:])
avg = self.conv_avg(avg)
avg_up = F.interpolate(avg, (H32, W32), mode='nearest')
feat32_arm = self.arm32(feat32)
feat32_sum = feat32_arm + avg_up
feat32_up = F.interpolate(feat32_sum, (H16, W16), mode='nearest')
feat32_up = self.conv_head32(feat32_up)
feat16_arm = self.arm16(feat16)
feat16_sum = feat16_arm + feat32_up
feat16_up = F.interpolate(feat16_sum, (H8, W8), mode='nearest')
feat16_up = self.conv_head16(feat16_up)
return feat16_up, feat32_up # x8, x16ARM使用在上下文路径中,用于优化每一阶段的特征,使用全局平均池化指导特征学习,计算成本可以忽略。ARM应用全局平均池化来获取全局语义信息然后计算一个attention vector来知到特征学习。这个结构能够精细画Context Path中各个阶段的结果。它可以不用上采样就集成全局语义信息,计算代价较小。
class AttentionRefinementModule(nn.Module):
def __init__(self, in_chan, out_chan, *args, **kwargs):
super(AttentionRefinementModule, self).__init__()
self.conv = ConvBNReLU(in_chan, out_chan, ks=3, stride=1, padding=1)
self.conv_atten = nn.Conv2d(out_chan, out_chan, kernel_size= 1, bias=False)
self.bn_atten = BatchNorm2d(out_chan, activation='none')
self.sigmoid_atten = nn.Sigmoid()
self.init_weight()
def forward(self, x):
feat = self.conv(x)
atten = F.avg_pool2d(feat, feat.size()[2:])
atten = self.conv_atten(atten)
atten = self.bn_atten(atten)
atten = self.sigmoid_atten(atten)
out = torch.mul(feat, atten)
return out融合模块
在特征表示的层面上,两个网络的特征并不相同。因此不能简单地加权这些特征。由 Spatial Path 捕获的空间信息编码了绝大多数的丰富细节信息。而 Context Path 的输出特征主要编码语境信息。换言之,Spatial Path 的输出特征是低层级的,Context Path 的输出特征是高层级的。因此,提出一个独特的特征融合模块以融合这些特征。为了空间路径和上下文路径更好的融合,提出了特征融合模块FFM还有注意力优化模块ARM。特征融合模块首先连接 Spatial Path 和 Context Path 的输出特征;接着,通过批归一化平衡特征的尺度。把相连接的特征池化为一个特征向量,并计算一个权重向量。这一权重向量可以重新加权特征,起到特征选择和结合的作用,类似于注意力机制。

class FeatureFusionModule(torch.nn.Module):
def __init__(self, num_classes, in_channels):
super().__init__()
self.in_channels = in_channels
self.convblock = ConvBlock(in_channels=self.in_channels,
out_channels=num_classes,
stride=1)
self.conv1 = nn.Conv2d(num_classes, num_classes, kernel_size=1)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(num_classes, num_classes, kernel_size=1)
self.sigmoid = nn.Sigmoid()
self.avgpool = nn.AdaptiveAvgPool2d(output_size=(1, 1))
def forward(self, input_1, input_2):
x = torch.cat((input_1, input_2), dim=1)
assert self.in_channels == x.size(
1), 'in_channels of ConvBlock should be {}'.format(x.size(1))
feature = self.convblock(x)
x = self.avgpool(feature)
x = self.relu(self.conv1(x))
x = self.sigmoid(self.conv2(x))
x = torch.mul(feature, x)
x = torch.add(x, feature)
return x在速度方面,空间路径虽然处理的图像尺寸较大,但是只有三个卷积层,因此计算量较低,而语义路径则采用轻量级的网络,也可以进行快速的下采样。两个模块可以并行计算进一步提升速度。精度上,空间路径拥有丰富的空间细节信息,语义路径则提供了大感受野,两者相互补偿,使得算法能达到满意的精度。
损失函数:通过辅助损失函数监督模型的训练,通过主损失函数监督整个 BiSeNet 的输出。另外,还通过添加一个特殊的辅助损失函数监督 Context Path 的输出,就像多层监督一样。上述所有损失函数都是 Softmax。最后借助参数 α 以平衡主损失函数与辅助损失函数的权重,两个loss同时传播,辅助loss有助于优化学习过程,主loss仍是主要的优化方向,然后使用不同的权重,共同优化参数。后续的实验证明这样做有利于快速收敛。