「三分钟系列02」3分钟看懂最高效的快速排序分析与优化
——“随机化快速排序可以满足一个人一辈子的人品需求。”
快速排序是一种很高效且有多种优化方法的排序算法,具体的介绍和实现在我的专栏01.其实我之前只知道快速排序的平均时间复杂度为O(n×log(n)),却不知具体原因,今天抽空证明一下,内容主要来自《算法导论》。
首先再介绍一遍快排的思想:
通过一趟排序将待排记录分割成独立的两部分,其中一部分记录的关键字均比另一部分记录的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序的目的。
| 排序方法 | 时间复杂度 | 空间复杂度 | 稳定性 | 复杂性 | ||
| 平均情况 | 最坏情况 | 最好情况 | ||||
| 快速排序 | O(nlog2n) | O(n2) | O(nlog2n) | O(log2n) | 不稳定 | 较复杂 |
1、最优时间复杂度
在最优情况下,Partition每次都划分得很均匀,如果排序n个关键字,其递归树的深度就为 [log2n]+1( [x] 表示不大于 x 的最大整数),即仅需递归 log2n 次,需要时间为T(n)的话,第一次Partiation应该是需要对整个数组扫描一遍,做n次比较。然后,获得的枢轴将数组一分为二,那么各自还需要T(n/2)的时间(注意是最好情况,所以平分两半)。于是不断地划分下去,就有了下面的不等式推断:
实际上使用master定理,可以非常简单的推导出快速排序的时间复杂度:
T[n] = 2T[n/2] + n ----------------第一次递归令:n = n/2 = 2 { 2 T[n/4] + (n/2) } + n ----------------第二次递归
= 2^2 T[ n/ (2^2) ] + 2n令:n = n/(2^2) = 2^2 {2 T[n/(2^3)] + n/(2^2)} + 2n ----------------第三次递归
= 2^3 T[n/ (2^3)] + 3n
令:n = n/( 2^(m-1) ) = 2^m T[1] + mn -----------------第m次递归得到:T[n/ (2^m) ] = T[1] > n = 2^m >> m = logn
此时,T[n] = 2^m T[1] + mn ;其中m = logn
T[n] = 2^(logn) T[1] + nlogn = n T[1] + nlogn = n + nlogn ;其中n为元素个数
又因为当n >= 2时:nlogn >= n (也就是logn > 1),所以取后面的 nlogn
综上所述:快速排序最优的情况下时间复杂度为:O( nlogn )
2、最坏时间复杂度
最坏情况的快速排序退化为冒泡排序。当待排序的序列为正序或逆序排列时,且每次划分只得到一个比上一次划分少一个记录的子序列,注意另一个为空。如果递归树画出来,它就是一棵斜树。此时需要执行n‐1次递归调用,且第i次划分需要经过n‐i次关键字的比较才能找到第i个记录,也就是枢轴的位置,因此比较次数为

,
最终其时间复杂度为O(n^2)。
3、平均时间复杂度
最后来看一下一般情况,平均的情况,设枢轴的关键字应该在第k的位置(1≤k≤n),那么:
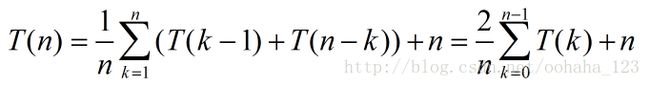
4、快速排序的优化
快排是一种基于分治的算法,对于分治算法,当每次划分时,算法若都能分成两个等长的子序列时,那么分治算法效率会达到最大。也就是说,基准的选择是很重要的。选择基准的方式决定了两个分割后两个子序列的长度,进而对整个算法的效率产生决定性影响。
最理想的方法是,选择的基准恰好能把待排序序列分成两个等长的子序列。
测试数据
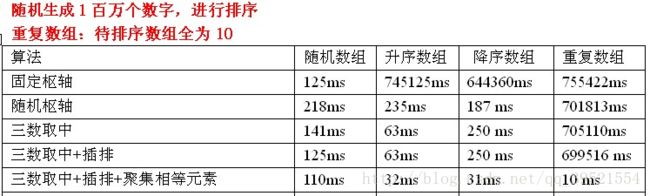
以上测试基于三种主要优化方法
-
随机枢轴(random pivot)
如果输入序列是随机的,处理时间可以接受的。如果数组已经有序时,此时的分割就是一个非常不好的分割。因为每次划分只能使待排序序列减一,此时为最坏情况,快速排序沦为起泡排序,时间复杂度为Θ(n^2)。而且,输入的数据是有序或部分有序的情况是相当常见的。因此,使用第一个元素作为枢纽元是非常糟糕的,为了避免这个情况,就引入了下面两个获取基准的方法。
-
三数取中(median-of-three)
最佳的划分是将待排序的序列分成等长的子序列,最佳的状态我们可以使用序列的中间的值,也就是第N/2个数。可是,这很难算出来,并且会明显减慢快速排序的速度。这样的中值的估计可以通过随机选取三个元素并用它们的中值作为枢纽元而得到。事实上,随机性并没有多大的帮助,因此一般的做法是使用左端、右端和中心位置上的三个元素的中值作为枢纽元。显然使用三数中值分割法消除了预排序输入的不好情形,并且减少快排大约14%的比较次数
-
同元聚类(same-element cluster)
针对已排序的数组,是没有任何用处的。因为待排序序列是已经有序的,那么每次划分只能使待排序序列减一。此时,插排是发挥不了作用的。所以这里看不到时间的减少。另外,三数取中选择枢轴+插排还是不能处理重复数组,在一次分割结束后,可以把与Key相等的元素聚在一起,继续下次分割时,不用再对与key相等元素分割
具体过程:在处理过程中,会有两个步骤
- 第一步,在划分过程中,把与key相等元素放入数组的两端
- 第二步,划分结束后,把与key相等的元素移到枢轴周围
举例:
待排序序列 1 4 6 7 6 6 7 6 8 6
三数取中选取枢轴:下标为4的数6
转换后,待分割序列:6 4 6 7 1 6 7 6 8 6
枢轴key:6
第一步,在划分过程中,把与key相等元素放入数组的两端
结果为:6 4 1 6(枢轴) 7 8 7 6 6 6, 此时,与6相等的元素全放入在两端了
第二步,划分结束后,把与key相等的元素移到枢轴周围
结果为:1 4 66(枢轴) 6 6 6 7 8 7,此时,与6相等的元素全移到枢轴周围了。之后,在1 4 和 7 8 7两个子序列进行快排
代码实现(原始版本):
void quick_sort(int *a, int left, int right)
{
if(left >= right)/*如果左边索引大于或者等于右边的索引就代表已经整理完成一个组了*/
{
return ;
}
int i = left;
int j = right;
int key = a[left];
while(i < j) /*控制在当组内寻找一遍*/
{
while(i < j && key <= a[j])
/*而寻找结束的条件就是,1,找到一个小于或者大于key的数(大于或小于取决于你想升
序还是降序)2,没有符合条件1的,并且i与j的大小没有反转*/
{
j--;/*向前寻找*/
}
a[i] = a[j];
/*找到一个这样的数后就把它赋给前面的被拿走的i的值(如果第一次循环且key是
a[left],那么就是给key)*/
while(i < j && key >= a[i])
/*这是i在当组内向前寻找,同上,不过注意与key的大小关系停止循环和上面相反,
因为排序思想是把数往两边扔,所以左右两边的数大小与key的关系相反*/
{
i++;
}
a[j] = a[i];
}
a[i] = key;/*当在当组内找完一遍以后就把中间数key回归*/
quick_sort(a, left, i - 1);/*最后用同样的方式对分出来的左边的小组进行同上的做法*/
quick_sort(a, i + 1, right);/*用同样的方式对分出来的右边的小组进行同上的做法*/
/*当然最后可能会出现很多分左右,直到每一组的i = j 为止*/
}
三数取中优化版本:
/***********快速排序算法
采用递归函数|版本1*********/
//因为与第一个过程相似,故不再注释#include
#include
#define N 10
void quick_sort(int a[], int low, int high);
int split(int a[], int low, int high);
int main(void)
{
int a[N], i;
printf("Please enter %d number of sorting: ", N);
for(i = 0; i < N; i++)
{
scanf("%d", &a[i]);
}
quick_sort(a, 0, N - 1);
printf("In sorted order: ");
for(i = 0; i < N; i++)
{
printf("%d \n", a[i]);
}
return 0;
}
void quick_sort(int a[], int low, int high)
{
int middle;
if(low >= high) return;
middle = split(a, low, high);
quick_sort(a, 0, middle - 1);
quick_sort(a, middle + 1, N - 1);
}
int split(int a[], int low, int high)
{
int value = a[low];
for(;;)
{
while (low < high && value <= a[high])
high--;
if (low >= high) {
break;}
a[low++] = a[high];
//low++;
while (low < high && value >= a[low])
low++;
if (low >= high) break;
a[high--] = a[low];
//high--;
}
a[high] = value;
return high;
} 三数取中+同元聚类版本:
void QSort(int arr[],int low,int high)
{
int first = low;
int last = high;
int left = low;
int right = high;
int leftLen = 0;
int rightLen = 0;
if (high - low + 1 < 10)
{
InsertSort(arr,low,high);
return;
}
//一次分割
int key = SelectPivotMedianOfThree(arr,low,high);//使用三数取中法选择枢轴
while(low < high)
{
while(high > low && arr[high] >= key)
{
if (arr[high] == key)//处理相等元素
{
swap(arr[right],arr[high]);
right--;
rightLen++;
}
high--;
}
arr[low] = arr[high];
while(high > low && arr[low] <= key)
{
if (arr[low] == key)
{
swap(arr[left],arr[low]);
left++;
leftLen++;
}
low++;
}
arr[high] = arr[low];
}
arr[low] = key;
//一次快排结束
//把与枢轴key相同的元素移到枢轴最终位置周围
int i = low - 1;
int j = first;
while(j < left && arr[i] != key)
{
swap(arr[i],arr[j]);
i--;
j++;
}
i = low + 1;
j = last;
while(j > right && arr[i] != key)
{
swap(arr[i],arr[j]);
i++;
j--;
}
QSort(arr,first,low - 1 - leftLen);
QSort(arr,low + 1 + rightLen,last);
}
参考文章:
1. Discrete mathematics and its applications, Kenneth H·Rosen
2. Introduction to Algorithms, Third Edition, Thomas H.Cormen / Charles E.Leiserson / Ronald L.Rivest / Clifford Stein
3. 三种快排优化:http://blog.csdn.net/insistgogo/article/details/7785038
4. 快速排序讲解:快速排序的本质
欢迎大家扫码关注微信公众号「图灵的猫」,除了有更多AI、算法、Python相关文章分享,还有免费的SSR节点和外网学习资料。其他平台(微信/知乎/B站)也是同名「图灵的猫」,不要迷路哦~