并发下HashMap引发死循环及元素丢失
HashMap不是线程安全的。那么HashMap在多线程环境下又会有什么问题呢?
public class HashMapThread extends Thread
{
private static AtomicInteger ai = new AtomicInteger(0);
private static Map map = new HashMap(1);
public void run()
{
while (ai.get() < 100000)
{
map.put(ai.get(), ai.get());
ai.incrementAndGet();
}
}
}
这个线程的作用很简单,给AtomicInteger不断自增并写入HashMap中,其中AtomicInteger和HashMap都是全局共享的,也就是说所有线程操作的都是同一个AtomicInteger和HashMap。开5个线程操作一下run方法中的代码:
public static void main(String[] args)
{
HashMapThread hmt0 = new HashMapThread();
HashMapThread hmt1 = new HashMapThread();
HashMapThread hmt2 = new HashMapThread();
HashMapThread hmt3 = new HashMapThread();
HashMapThread hmt4 = new HashMapThread();
hmt0.start();
hmt1.start();
hmt2.start();
hmt3.start();
hmt4.start();
}运行几次之后死循环就出来了,我大概运行了7次、8次的样子,其中有几次是数组下标越界异常ArrayIndexOutOfBoundsException。这里面要提一点,多线程环境下代码会出现问题并不意味着多线程环境下一定会出现问题,但是只要出现了问题,或者是死锁、或者是死循环,那么你的项目除了重启就没有什么别的办法了,所以代码的线程安全性在开发、评审的时候必须要重点考虑到。OK,看一下控制台:

红色方框一直亮着,说明代码死循环了。死循环问题的定位一般都是通过jps+jstack查看堆栈信息来定位的:
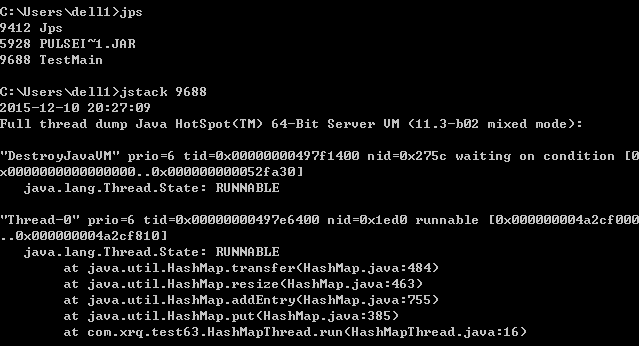
看到Thread-0处于RUNNABLE,而从堆栈信息上应该可以看出,这次的死循环是由于Thread-0对HashMap进行扩容而引起的。
所以,本文就解读一下,HashMap的扩容为什么会引起死循环。
正常的扩容过程
先来看一下HashMap一次正常的扩容过程。简单一点看吧,假设我有三个经过了最终rehash得到的数字,分别是5 7 3,HashMap的table也只有2,那么HashMap把这三个数字put进数据结构了之后应该是这么一个样子的:

这应该很好理解。然后看一下resize的代码,上面的堆栈里面就有:
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry e = table[bucketIndex];
table[bucketIndex] = new Entry(hash, key, value, e);
if (size++ >= threshold)
resize(2 * table.length);
}
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry e = src[j];
if (e != null) {
src[j] = null;
do {
Entry next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
我总结一下这三段代码,HashMap一次扩容的过程应该是:
1、取当前table的2倍作为新table的大小
2、根据算出的新table的大小new出一个新的Entry数组来,名为newTable
3、轮询原table的每一个位置,将每个位置上连接的Entry,算出在新table上的位置,并以链表形式连接
4、原table上的所有Entry全部轮询完毕之后,意味着原table上面的所有Entry已经移到了新的table上,HashMap中的table指向newTable
补充说明:扩容过程中,每次都是将元素放在对应数组位置的第一个元素,也就是头插法,而后面的死锁就是因为这个原因。
这样就完成了一次扩容,用图表示是这样的:
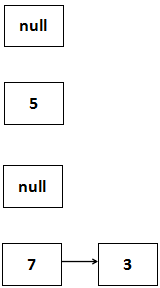
HashMap的一次正常扩容就是这样的,这很好理解。
扩容导致的死循环
既然是扩容导致的死循环,那么继续看扩容的代码:
1 void transfer(Entry[] newTable) {
2 Entry[] src = table;
3 int newCapacity = newTable.length;
4 for (int j = 0; j < src.length; j++) {
5 Entry e = src[j];
6 if (e != null) {
7 src[j] = null;
8 do {
9 Entry next = e.next;
10 int i = indexFor(e.hash, newCapacity);
11 e.next = newTable[i];
12 newTable[i] = e;
13 e = next;
14 } while (e != null);
15 }
16 }
17 }
补充说明:9-13行代码就是一个头插法的经典过程

两个线程,线程A和线程B。假设第9行执行完毕,线程A切换,那么对于线程A而言,是这样的:
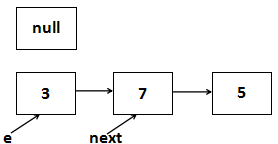
CPU切换到线程B运行,线程B将整个扩容过程全部执行完毕,于是就形成了:

此时CPU切换到线程A上,执行第8行~第14行的do...while...循环,首先放置3这个Entry:
补充说明:resize函数中的table = newTable;所以A线程的src数组已经变为扩容以后的数组,但是A线程执行到e=3的位置,仍然后将3放到新建数组的头部,这样死循环就形成了。
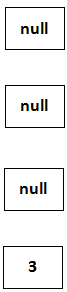
我们必须要知道,由于线程B已经执行完毕,因此根据Java内存模型(JMM),现在table里面所有的Entry都是最新的,也就是7的next是3,3的next是null。3放置到table[3]的位置上了,下面的步骤是:
1、e=next,即e=7
2、判断e不等于null,循环继续
3、next=e.next,即next=7的next,也就是3
4、放置7这个Entry
所以,用图表示就是:
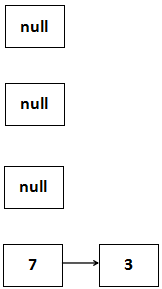
放置完7之后,继续运行代码:
1、e=next,也就是说e=3
2、判断e不等于null,循环继续
3、next=e.next,即3的next,也就是null
4、放置3这个Entry
把3移到table[3]上去,死循环就出来了:

3移到table[3]上去了,3的next指向7,由于原先7的next指向3,这样就成了一个死循环。
此时执行13行的e=next,那么e=null,循环终止。尽管此次循环确实结束了,但是后面的操作,只要涉及轮询HashMap数据结构的,无论是迭代还是扩容,都将在table[3]这个链表处出现死循环。这也就是前面的死循环堆栈出现的原因,transfer的484行,因为这是一次扩容操作,需要遍历HashMap数据结构,transfer方法是扩容的最后一个方法。
元素丢失的情况分析:
多线程put的时候可能导致元素丢失
HashMap另外一个并发可能出现的问题是,可能产生元素丢失的现象。
考虑在多线程下put操作时,执行addEntry(hash, key, value, i),如果有产生哈希碰撞,
导致两个线程得到同样的bucketIndex去存储,就可能会出现覆盖丢失的情况:
| 1 2 3 4 5 6 7 |
|