Java多线程复习(二):UnSafe与CAS、AQS与锁、CountDownLatch、CyclicBarrier、Semaphore
五、UnSafe与CAS
1、UnSafe
Unsafe类为单例实现,提供静态方法getUnsafe()获取Unsafe实例,当且仅当调用getUnsafe()方法的类为引导类加载器所加载时才合法,否则抛出SecurityException异常
AtomicInteger内部使用UnSafe来实现的,源码如下:
public class AtomicLong extends Number implements java.io.Serializable {
private static final long serialVersionUID = 1927816293512124184L;
//获取Unsafe实例
private static final Unsafe unsafe = Unsafe.getUnsafe();
//存放变量value的内存偏移量
private static final long valueOffset;
//判断JVM是否支持Long类型无锁CAS
static final boolean VM_SUPPORTS_LONG_CAS = VMSupportsCS8();
private static native boolean VMSupportsCS8();
static {
try {
//获取value在AtomicLong中的偏移量
valueOffset = unsafe.objectFieldOffset
(AtomicLong.class.getDeclaredField("value"));
} catch (Exception ex) { throw new Error(ex); }
}
//实际存放计数的变量,使用volatile修饰在多线程下保证内存可见性
private volatile long value;
public AtomicLong(long initialValue) {
value = initialValue;
}
public final int getAndIncrement() {
return unsafe.getAndAddInt(this, valueOffset, 1);
}
getAndIncrement()方法是通过调用Unsafe的getAndAddLong()方法来实现操作
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
/*
* CAS操作:如果相同,更新var5+var4并且返回true 如果不同,继续取值然后再比较,直到更新完成
* var1:当前对象(AtomicInteger)
* var2:该对象值的引用地址(内存地址偏移量)
* var4:需要变动的数量
* var5:通过var1 var2找出的主内存中真实的值
*/
} while (!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}
public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5);
每个线程通过baseAddress+valueOffset得到value的内存地址,进而拿到变量的当前值,然后使用CAS修改变量的值,如果设置失败,则循环继续尝试,直到设置成功
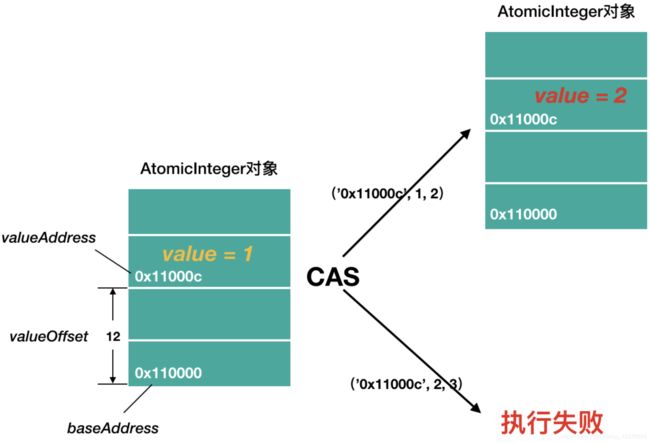
2、CAS
CAS全称是Compare-And-Swap,它是一条CPU并发原语。它的功能是判断内存某个位置的值是否是预期值,如果是则更改为新的值,这个过程是原子的
CAS并发原语体现在Java语言中就是sun.misc.Unsafe类中的各个方法。调用Unsafe类中的CAS方法,JVM会帮我们实现CAS汇编指令。这是一种完全依赖于硬件的功能,通过它实现了原子操作。由于CAS是一种系统原语,原语属于操作系统用语范畴,是由若干条指令组成的,用于完成某个功能的一个过程,并且原语的执行必须是连续的,在执行过程中不允许被中断,也就是说CAS是一条CPU的原子指令,不会造成所谓的数据不一致问题
CAS比较当前工作内存中的值和主内存中的值,如果相同则执行指定操作,否则继续比较直到主内存和工作内存中的值一致为止
CAS有3个操作数,内存值V,旧的预期值A,要修改的更新值B。当且仅当预期值A和内存值V相同时,将内存值V修改为B,否则什么都不做
1)、无锁方案的优点
无锁方案相对互斥锁方案,最大的好处就是性能。互斥锁方案为了保证互斥性,需要执行加锁、解锁操作,而加锁、解锁操作本身就消耗性能;同时拿不到锁的线程还会进入阻塞状态,进而触发线程切换,线程切换对性能的消耗也很大。相比之下,无锁方案则完全没有加锁、解锁的性能消耗,同时还能保证互斥性
2)、CAS实现原子操作的三大问题
1)循环时间长开销大
2)只能保证一个共享变量的原子操作
当对一个共享变量执行操作时,可以使用循环CAS的方式来保证原子操作,但是对多个共享变量操作时,循环CAS就无法保证操作的原子性,这个时候就可以用锁。还有一个办法,就是把多个共享变量合并成一个共享变量来操作。从Java1.5开始,JDK提供了AtomicReference类来保证引用对象之间的原子性,就可以把多个变量放在一个对象里进行CAS操作
public class AtomicReferenceDemo {
public static void main(String[] args) {
AtomicReference<User> atomicReference = new AtomicReference<>();
User zhangsan = new User("zhangsan", 21);
User lisi = new User("lisi", 21);
atomicReference.set(zhangsan);
System.out.println(atomicReference.compareAndSet(zhangsan, lisi) + " " + atomicReference.get().toString());
System.out.println(atomicReference.compareAndSet(zhangsan, lisi) + " " + atomicReference.get().toString());
}
}
执行效果:
true User{userName='lisi', age=21}
false User{userName='lisi', age=21}
3)ABA问题
因为CAS需要在操作值的时候,检查值有没有发生变化,如果没有发生变化则更新,但是如果一个值原来是A,变成了B,又变成了A,那么使用CAS进行检查时会发现它的值没有发生变化,但是实际上却变化了。ABA问题的解决思路就是使用版本号。在变量前面追加上版本号,每次变量更新的时候把版本号加1,那么A->B->A就变成1A->2B->3A。从Java1.5开始,JDK的Atomic包里提供了一个类AtomicStampedReference来解决ABA问题。这个类的compareAndSet()方法的作用是首先检查当前引用是否等于预期引用,并且检查当前标志是否等于预期标志,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值
public class AtomicStampedReferenceDemo {
static AtomicStampedReference<Integer> atomicStampedReference = new AtomicStampedReference<>(100, 1);
public static void main(String[] args) {
new Thread(() -> {
int stamp = atomicStampedReference.getStamp();
System.out.println(Thread.currentThread().getName() + " 第一次版本号:" + stamp);
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
atomicStampedReference.compareAndSet(100, 101, atomicStampedReference.getStamp(), atomicStampedReference.getStamp() + 1);
atomicStampedReference.compareAndSet(101, 100, atomicStampedReference.getStamp(), atomicStampedReference.getStamp() + 1);
}, "Thread-1").start();
new Thread(() -> {
int stamp = atomicStampedReference.getStamp();
System.out.println(Thread.currentThread().getName() + " 第一次版本号:" + stamp);
try {
//暂停3秒保证线程Thread-1完成了一次ABA操作
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
boolean result = atomicStampedReference.compareAndSet(100, 101, stamp, stamp + 1);
System.out.println(Thread.currentThread().getName() + " 是否修改成功:" + result + " 当前实际最新版本号:" + atomicStampedReference.getStamp());
}, "Thread-2").start();
}
}
执行效果:
Thread-1 第一次版本号:1
Thread-2 第一次版本号:1
Thread-2 是否修改成功:false 当前实际最新版本号:3
六、AQS与锁
synchronized与lock对比:
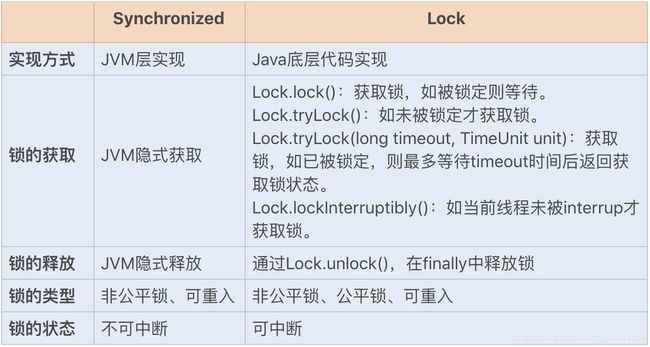
lock锁是基于Java实现的锁,Lock是一个接口类,常用的实现类有ReentrantLock、ReentrantReadWriteLock(RRW),它们都是依赖AbstractQueuedSynchronizer(AQS)类实现的
1、AQS
队列同步器AbstractQueuedSynchronizer是用来构建锁或者其他组件的基本框架,它使用了一个int成员变量表示同步状态,通过内置的FIFO队列来完成资源获取线程的排队工作
1)、队列同步器的接口
同步器的设计是基于模板方法模式的,使用者需要继承同步器并重写指定的方法,随后将同步器组合在自定义同步组件的实现中,并调用同步器提供的模板方法,而这些模板方法将会调用使用者重写的方法
同步器提供的功能可以分为独占功能和共享功能两类
1)重写同步器的指定方法时,需要使用同步器提供的如下3个方法来访问或修改同步状态:
//同步状态共享变量,使用volatile修饰保证线程可见性
private volatile int state;
//获取当前同步状态
protected final int getState() {
return state;
}
//设置当前同步状态
protected final void setState(int newState) {
state = newState;
}
//使用CAS设置当前状态,该方法能保证状态设置的原子性
protected final boolean compareAndSetState(int expect, int update) {
return unsafe.compareAndSwapInt(this, stateOffset, expect, update);
}
2)同步器中可重写的方法如下:
//独占模式:
//独占式获取同步状态,实现该方法需要查询当前状态并判断同步状态是否符合预期,然后再进行CAS设置同步状态
protected boolean tryAcquire(int arg)
//独占式释放同步状态,等待获取同步状态的线程将有机会获取同步状态
protected boolean tryRelease(int arg)
//共享模式:
//共享式获取同步状态,返回大于等于0的值,表示获取成功,反之,获取失败
protected int tryAcquireShared(int arg)
//共享式释放同步状态
protected boolean tryReleaseShared(int arg)
//当前同步器是否在独占模式下被线程占用,一般该方法表示是否被当前线程所独占
protected boolean isHeldExclusively()
3)同步器提供的模板方法基本上分为3类:独占式获取与释放同步状态、共享式获取与释放同步状态和查询同步队列中的等待线程情况,具体如下:
//独占式获取同步状态,如果当前线程获取同步状态成功,则由该方法返回,否则,将会进入同步队列等待,该方法将会调用重写的tryAcquire(int arg)
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
//与acquire(int arg)相同,但是该方法响应中断,当前线程未获取到同步状态而进入同步队列中,如果当前线程被中断,则该方法会抛出InterruptedException并返回
public final void acquireInterruptibly(int arg)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
if (!tryAcquire(arg))
doAcquireInterruptibly(arg);
}
//在acquireInterruptibly(int arg)基础上增加了超时限制,如果当前线程在超时时间内没有获取到同步状态,那么将会返回false,如果获取到了返回true
public final boolean tryAcquireNanos(int arg, long nanosTimeout)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
return tryAcquire(arg) ||
doAcquireNanos(arg, nanosTimeout);
}
//共享式的获取同步状态,如果当前线程未获取到同步状态,将会进入同步队列等待,与独占模式的主要区别是在同一时刻可以有多个线程获取到同步状态
public final void acquireShared(int arg) {
if (tryAcquireShared(arg) < 0)
doAcquireShared(arg);
}
//与acquireShared(int arg)相同,该方法响应中断
public final void acquireSharedInterruptibly(int arg)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
if (tryAcquireShared(arg) < 0)
doAcquireSharedInterruptibly(arg);
}
//在acquireSharedInterruptibly(int arg)基础上增加了超时限制
public final boolean tryAcquireSharedNanos(int arg, long nanosTimeout)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
return tryAcquireShared(arg) >= 0 ||
doAcquireSharedNanos(arg, nanosTimeout);
}
//独占式的释放同步状态,该方法会在释放同步状态之后,将同步队列中第一个节点包含的线程唤醒
public final boolean release(int arg) {
if (tryRelease(arg)) {
Node h = head;
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);
return true;
}
return false;
}
//共享式的释放同步状态
public final boolean releaseShared(int arg) {
if (tryReleaseShared(arg)) {
doReleaseShared();
return true;
}
return false;
}
//获取等待在同步队列上的线程集合
public final Collection<Thread> getQueuedThreads() {
ArrayList<Thread> list = new ArrayList<Thread>();
for (Node p = tail; p != null; p = p.prev) {
Thread t = p.thread;
if (t != null)
list.add(t);
}
return list;
}
2)、同步队列
同步器依赖内部的同步队列(一个FIFO双向队列)来完成同步状态的管理,当前线程获取同步状态失败时,同步器会将当前线程以及等待状态等信息构造成为一个节点并将其加入同步队列,同时会阻塞当前线程,当同步状态释放时,会把首节点中的线程唤醒,使其再次尝试获取同步状态
同步队列中的节点(Node结点类)用来保存获取同步状态失败的线程引用、等待状态以及前驱和后继节点
static final class Node {
//标记一个正在共享模式中等待的节点
static final Node SHARED = new Node();
//标记一个正在独占模式中等待的节点
static final Node EXCLUSIVE = null;
static final int CANCELLED = 1;
static final int SIGNAL = -1;
static final int CONDITION = -2;
static final int PROPAGATE = -3;
volatile int waitStatus;
//前驱结点,当节点加入同步队列时被设置(尾部添加)
volatile Node prev;
//后继节点
volatile Node next;
//获取同步状态的线程
volatile Thread thread;
//连接到下个等待状态的结点,或者特殊值SHARED。因为条件队列只有在独占模式中保持时才会被访问,所以只需要一个简单的队列来在节点等待Condition时保持节点。然后,被转移到队列重新获取。因为Condition只能是排他的,所以使用特殊值来指示共享模式
Node nextWaiter;
waitStatus用来表示等待状态,包含如下状态:
- CANCELLED:值为1,由于在同步队列中等待的线程等待超时或者被中断,需要从同步队列中取消等待,节点进入该状态将不会变化
- SIGNAL:值为-1,后继节点的线程处于等待状态,而当前节点的线程如果释放呃同步状态或者被取消,将会通知后继节点,使后继节点的线程得以运行
- CONDITION:值为-2,节点在等待队列中,节点线程等待在Condition上,当其他线程对Condition调用了
signal()方法后,该节点将会从等待队列中转移到同步队列中,加入到对同步状态的获取中 - PROPAGATE:值为-3,表示下一次共享式同步状态获取将会无条件地被传播下去
- INITIAL:值为0,初始状态
节点是构成同步队列的基础,同步器拥有首节点和尾节点,没有成功获取同步状态的线程将会成为节点加入该队列的尾部
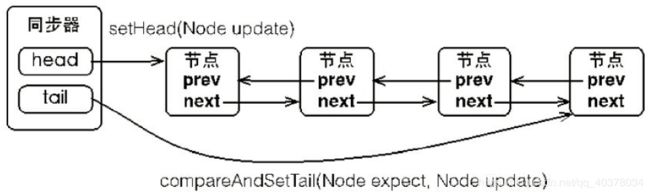
同步器包含了两个节点类型的引用,一个指向头节点,而另一个指向尾节点。当一个线程成功地获取了同步状态(或者锁),其他线程将无法获取到同步状态,转而被构造称为节点并加入到同步队列中,而这个加入队列的过程必须要保证线程安全,因此同步器提供了一个基于CAS的设置尾节点的方法:compareAndSetTail(Node expect, Node update),它需要传递当前线程认为的尾节点和当前节点,只有设置成功后,当前节点才正式与之前的尾节点建立关联
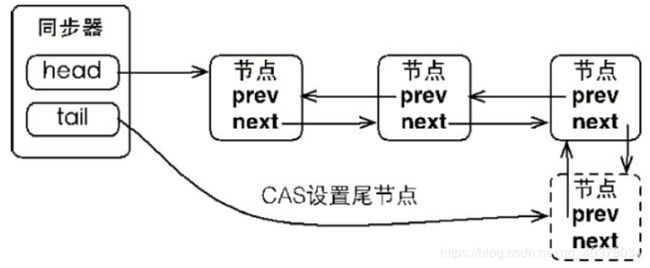
同步队列遵循FIFO,首节点是获取同步状态成功的节点,首节点的线程在释放同步状态时,将会唤醒后继节点,而后继节点将会在获取同步状态成功时将自己设置为首节点
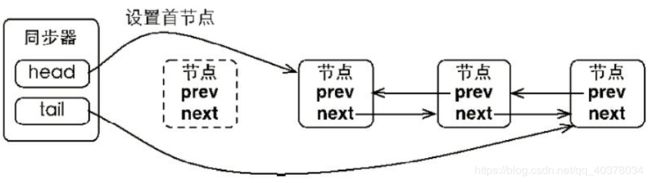
设置首节点是通过获取同步状态成功的线程来完成的,由于只有一个线程能够成功获取到同步状态,因此设置头节点的方法并不需要使用CAS来保证,它只需要将首节点设置成为原首节点的后继节点并断开原首节点的next引用即可
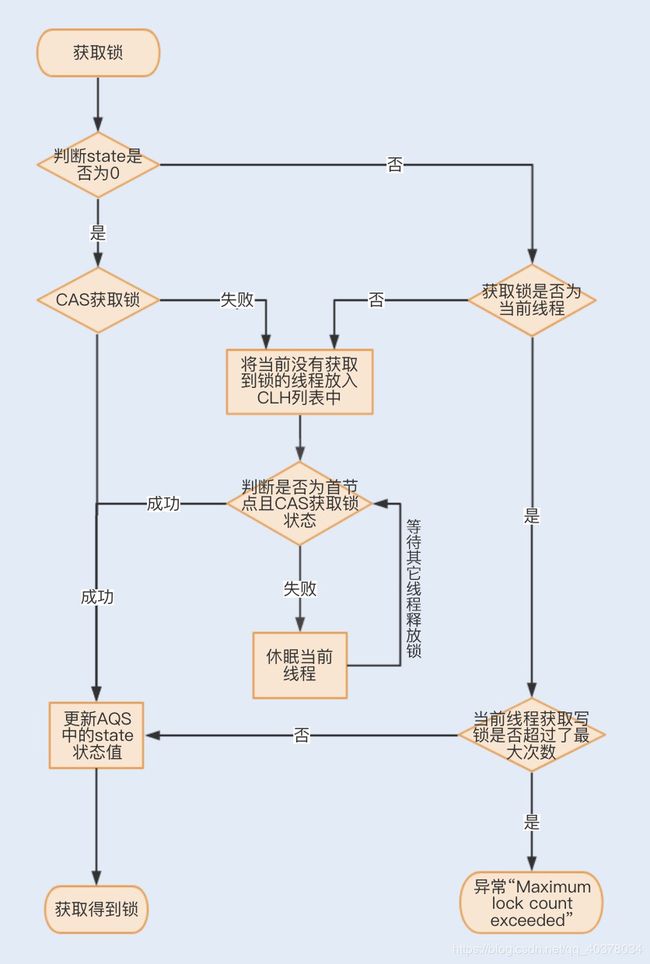
2、独占锁ReentrantLock实现原理
3、读写锁ReentrantReadWriteLock
1)、什么是读写锁
读写锁遵循以下三条基本原则:
- 允许多个线程同时读共享变量
- 只允许一个线程写共享变量
- 如果一个写线程正在执行写操作,此时禁止读线程读共享变量
读写锁与互斥锁的一个重要区别就是读写锁允许多个线程同时读共享变量,而互斥锁是不允许的,这是读写锁在读多写少场景下性能优于互斥锁的关键。但读写锁的写操作是互斥的,当一个线程在写共享变量的时候,是不允许其他线程执行写操作和读操作
ReentrantReadWriteLock的特性:
| 特性 | 说明 |
|---|---|
| 公平性选择 | 支持非公平(默认)和公平的锁获取方式,吞吐量还是非公平优于公平 |
| 可重入 | 该锁支持重进入,以读写线程为例:读线程在获取了读锁之后,能够再次获取读锁。而写线程在获取了写锁之后能够再次获取写锁,同时也可以获取读锁 |
| 锁降级 | 遵循获取写锁、获取读锁再释放写锁的次序,写锁能够降级成为读锁 |
2)、读写锁的降级
锁降级指的是写锁降级成为读锁。锁降级是指当前拥有写锁,再获取到读锁,随后释放当前拥有的写锁的过程
ReentrantReadWriteLock不支持锁升级(把持读锁、获取写锁,最后释放读锁的过程)。目的也是保证数据可见性,如果读锁已被多个线程获取,其中任意线程成功获取了写锁并更新了数据,则其更新对其他获取到读锁的线程是不可见的
锁降级的使用场景:对变量的值比较敏感,对一个变量进行修改,下面马上要对变量进行读操作
public class CachedData {
Object data;
volatile boolean cacheValid;
final ReadWriteLock rwl = new ReentrantReadWriteLock();
//读锁
final Lock readLock = rwl.readLock();
//写锁
final Lock writeLock = rwl.writeLock();
void processCachedData() {
//获取读锁
readLock.lock();
if (!cacheValid) {
//释放读锁,因为不允许读锁的升级
readLock.unlock();
//获取写锁
writeLock.lock();
try {
//再次检查状态
if (!cacheValid) {
data = ...
cacheValid = true;
}
//释放写锁前,降级为读锁
readLock.lock();
} finally {
//释放写锁
writeLock.unlock();
}
//此处依然持有读锁
try {
use(data);
} finally {
readLock.unlock();
}
}
}
}
3)、实现原理
RRW也是基于AQS实现的,它的自定义同步器(继承 AQS)需要在同步状态state上维护多个读线程和一个写线程的状态,读写锁将变量切分成了两个部分,高16位表示读,低16位表示写
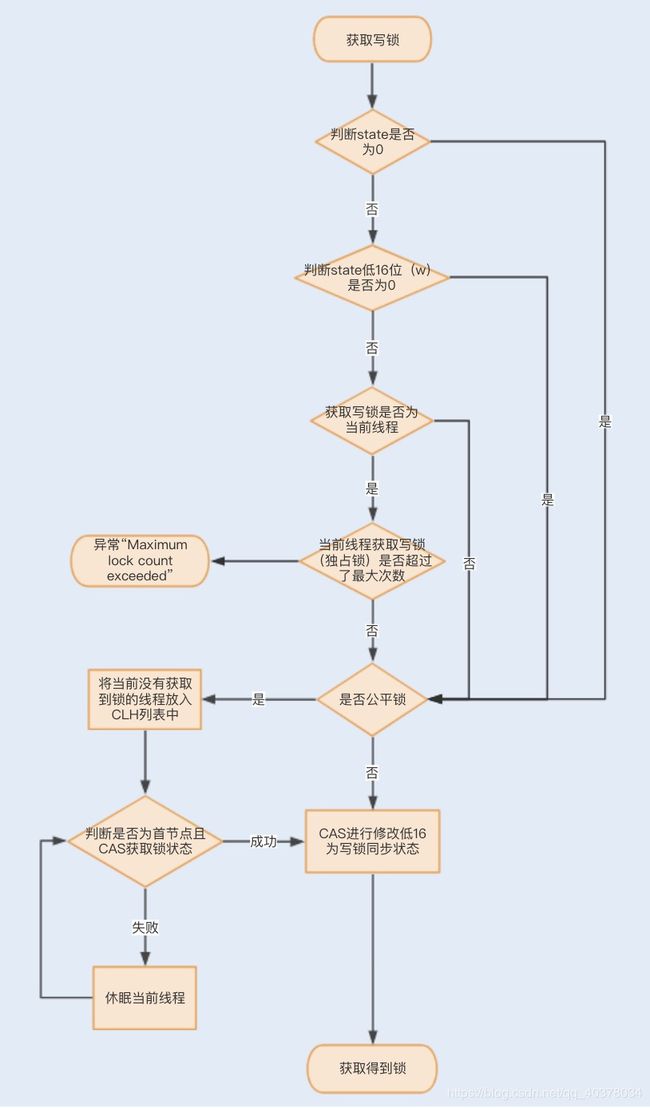
一个线程尝试获取写锁时,会先判断同步状态state是否为0。如果state等于0,说明暂时没有其它线程获取锁;如果state不等于0,则说明有其它线程获取了锁
此时再判断同步状态state的低16位(w)是否为0,如果w为0,则说明其它线程获取了读锁,此时进入CLH队列进行阻塞等待;如果w不为 0,则说明其它线程获取了写锁,此时要判断获取了写锁的是不是当前线程,若不是就进入CLH队列进行阻塞等待;若是,就应该判断当前线程获取写锁是否超过了最大次数,若超过,抛异常,反之更新同步状态
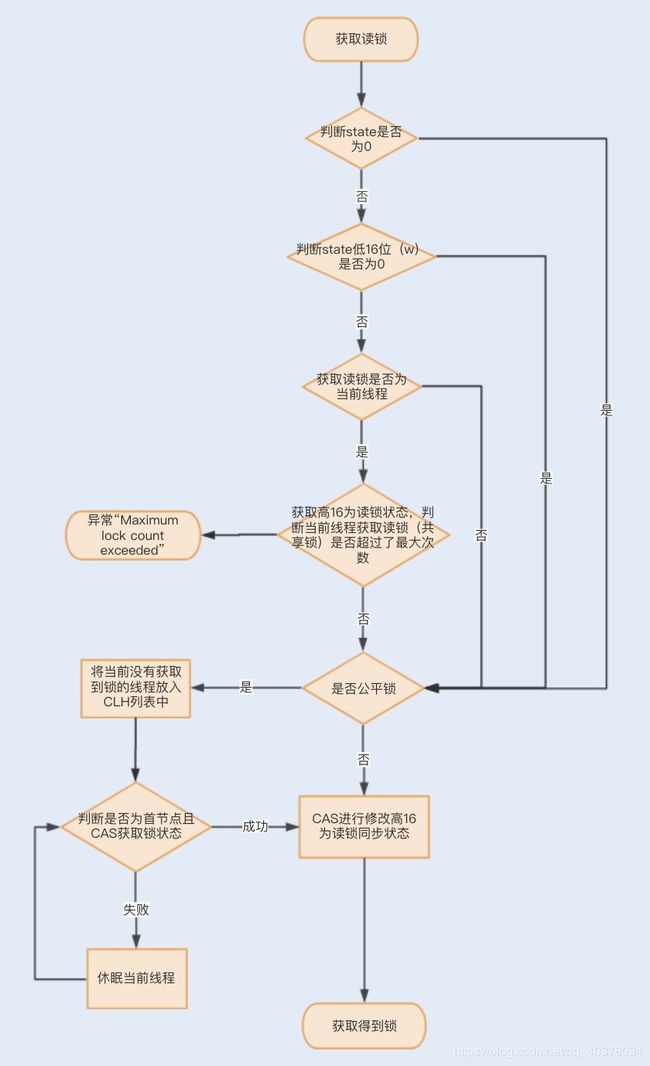
一个线程尝试获取读锁时,同样会先判断同步状态state是否为0。如果state等于0,说明暂时没有其它线程获取锁,此时判断是否需要阻塞,如果需要阻塞,则进入CLH队列进行阻塞等待;如果不需要阻塞,则CAS更新同步状态为读状态
如果state不等于0,会判断同步状态低16位,如果存在写锁,则获取读锁失败,进入CLH阻塞队列;反之,判断当前线程是否应该被阻塞,如果不应该阻塞则尝试CAS同步状态,获取成功更新同步锁为读状态
4、StampedLock
1)、StampedLock支持的三种模式
ReadWriteLock支持两种模式:一种是读锁,一种是写锁。而StampedLock支持三种模式,分别是:写锁、悲观读锁和乐观读。写锁、悲观读锁的语义和ReadWriteLock的写锁、读锁的语义非常类似,允许多个线程同时获取悲观读锁,但是只允许一个线程获取写锁,写锁和悲观读锁是互斥的。不同的是:StampedLock里的写锁和悲观读锁加锁成功之后,都会返回一个stamp;然后解锁的时候,需要传入这个stamp
final StampedLock sl = new StampedLock();
//获取/释放悲观读锁示意代码
long stamp = sl.readLock();
try {
//省略业务相关代码
} finally {
sl.unlockRead(stamp);
}
//获取/释放写锁示意代码
long stamp = sl.writeLock();
try {
//省略业务相关代码
} finally {
sl.unlockWrite(stamp);
}
StampedLock的性能之所以比ReadWriteLock要好关键是因为StampedLock支持乐观读的方式。ReadWriteLock支持多个线程同时读,但是当多个线程同时读的时候,所有的写操作会被阻塞;而StampedLock提供的乐观读,是允许一个线程获取写锁的,也就是说不是所有的写操作都被阻塞。乐观读操作是无锁的
public class Point {
private int x, y;
final StampedLock sl = new StampedLock();
//计算到原点的距离
double distanceFromOrigin() {
//乐观读
long stamp = sl.tryOptimisticRead();
//读入局部变量,
//读的过程数据可能被修改
int curX = x, curY = y;
//判断执行读操作期间,
//是否存在写操作,如果存在,sl.validate返回false
if (!sl.validate(stamp)) {
//升级为悲观读锁
stamp = sl.readLock();
try {
curX = x;
curY = y;
} finally {
//释放悲观读锁
sl.unlockRead(stamp);
}
}
return Math.sqrt(curX * curX + curY * curY);
}
}
在distanceFromOrigin()方法中,首先通过调用tryOptimisticRead()获取一个stamp,这里的tryOptimisticRead()就是乐观读。之后将共享变量x和y读入方法的局部变量中,由于tryOptimisticRead()是无锁的,所以共享变量x和y读入方法局部变量时,x和y有可能被其他线程修改了。因此最后读完之后,还需要再次验证一下是否存在写操作,这个验证操作是通过调用validate(stamp)来实现的
如果执行乐观读操作的期间,存在写操作,会把乐观读升级为悲观读锁。这个做法挺合理的,否则就需要在一个循环里反复执行乐观读,直到乐观读操作的期间没有写操作(只有这样才能保证x和y的正确性和一致性),而循环读会浪费大量的CPU
2)、StampedLock使用注意事项
StampedLock不支持重入
StampedLock的悲观读锁、写锁都不支持条件变量
如果线程阻塞在StampedLock的readLock()或者writeLock()上时,此时调用该阻塞线程的interrupt()方法,会导致CPU飙升
使用StampedLock一定不要调用中断操作,如果需要支持中断功能,一定使用可中断的悲观读锁readLockInterruptibly()和写锁writeLockInterruptibly()
StampedLock读模板:
final StampedLock sl = new StampedLock();
//乐观读
long stamp = sl.tryOptimisticRead();
//读入方法局部变量
......
//校验stamp
if (!sl.validate(stamp)) {
//升级为悲观读锁
stamp = sl.readLock();
try {
//读入方法局部变量
.....
} finally {
//释放悲观读锁
sl.unlockRead(stamp);
}
}
//使用方法局部变量执行业务操作
......
StampedLock写模板:
long stamp = sl.writeLock();
try {
//写共享变量
......
} finally {
sl.unlockWrite(stamp);
}
3)、StampedLock锁降级
StampedLock支持锁的降级(通过tryConvertToReadLock()方法实现)和升级(通过tryConvertToWriteLock()方法实现),下面的代码中存在一个Bug
private double x, y;
final StampedLock sl = new StampedLock();
//存在问题的方法
void moveIfAtOrigin(double newX, double newY) {
long stamp = sl.readLock();
try {
while (x == 0.0 && y == 0.0) {
long ws = sl.tryConvertToWriteLock(stamp);
if (ws != 0L) {
x = newX;
y = newY;
break;
} else {
sl.unlockRead(stamp);
stamp = sl.writeLock();
}
}
} finally {
sl.unlock(stamp);
}
}
在锁升级成功的时候,最后没有释放最新的锁,可以在if块的break上加一个stamp=ws进行释放
八、CountDownLatch、CyclicBarrier、Semaphore
1、等待多线程完成的CountDownLatch
1)、案例介绍
public class CountDownLatchDemo {
private static CountDownLatch countDownLatch = new CountDownLatch(2);
public static void main(String[] args) throws InterruptedException {
ExecutorService executorService = Executors.newFixedThreadPool(2);
executorService.execute(() -> {
try {
TimeUnit.SECONDS.sleep(1);
System.out.println("child threadOne over");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
countDownLatch.countDown();
}
});
executorService.execute(() -> {
try {
TimeUnit.SECONDS.sleep(1);
System.out.println("child threadTwo over");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
countDownLatch.countDown();
}
});
System.out.println("wait all child thread over");
countDownLatch.await();
System.out.println("all child thread over");
executorService.shutdown();
}
}
创建了一个CountDownLatch实例,因为有两个子线程所以构造函数的传参为2。主线程调用countDownLatch.await()方法后会被阻塞。子线程执行完毕后调用countDownLatch.countDown()方法让countDownLatch内部的计数器减1,所有子线程执行完毕并调用countDown()方法后计数器会变为0,这时候主线程的await()方法才会返回
2)、CountDownLatch源码分析
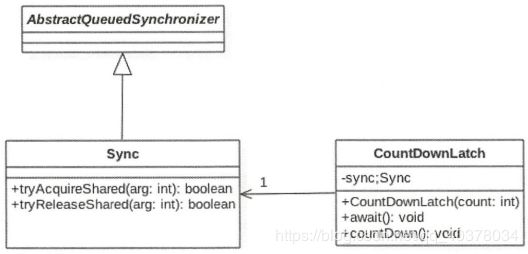
CountDownLatch是使用AQS实现的,通过下面的构造函数把计数器的值赋给了AQS的状态变量state,也就是使用AQS的状态值来表示计数器值
public CountDownLatch(int count) {
if (count < 0) throw new IllegalArgumentException("count < 0");
this.sync = new Sync(count);
}
Sync(int count) {
setState(count);
}
1)await()方法
当线程调用CountDownLatch对象的await()方法后,当前线程会被阻塞,直到下面的情况之一发生才会返回:当所有线程都调用了CountDownLatch对象的countDown()方法后,也就是计数器的值为0时;其他线程调用了当前线程的interrupt()方法中断了当前线程,当前线程就会抛出InterruptedException异常,然后返回
public void await() throws InterruptedException {
//调用AQS中的模板方法acquireSharedInterruptibly
sync.acquireSharedInterruptibly(1);
}
AQS中的acquireSharedInterruptibly方法:
//AQS获取共享资源时可被中断的方法
public final void acquireSharedInterruptibly(int arg)
throws InterruptedException {
//如果线程被中断则抛出异常
if (Thread.interrupted())
throw new InterruptedException();
//调用CountDownLatch中sync重写的tryAcquireShared方法,查看当前计数器值是否为0,为0则直接返回,否则进入AQS的队列等待
if (tryAcquireShared(arg) < 0)
doAcquireSharedInterruptibly(arg);
}
sync类实现的AQS的接口:
protected int tryAcquireShared(int acquires) {
return (getState() == 0) ? 1 : -1;
}
2)countDown()方法
public void countDown() {
//调用AQS中的模板方法releaseShared
sync.releaseShared(1);
}
AQS中的releaseShared方法:
public final boolean releaseShared(int arg) {
//调用CountDownLatch中sync重写的tryReleaseShared方法
if (tryReleaseShared(arg)) {
//AQS的释放资源方法
doReleaseShared();
return true;
}
return false;
}
sync类实现的AQS的接口:
protected boolean tryReleaseShared(int releases) {
//循环进行CAS,直到当前线程成功完成CAS使计数器值(状态值state)减1并更新到state
for (;;) {
int c = getState();
//如果当前状态值为0则直接返回(为了防止当计数器值为0后,其他线程又调用了countDown方法,防止状态值变为负数)
if (c == 0)
return false;
//使用CAS让计数器值减1
int nextc = c-1;
if (compareAndSetState(c, nextc))
return nextc == 0;
}
}
}
2、同步屏障CyclicBarrier
1)、案例介绍
public class CyclicBarrierDemo {
private static CyclicBarrier cyclicBarrier = new CyclicBarrier(2, new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + "执行回调方法");
}
});
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(2);
executorService.execute(() -> {
try {
System.out.println(Thread.currentThread().getName() + " step1");
cyclicBarrier.await();
System.out.println(Thread.currentThread().getName() + " step2");
cyclicBarrier.await();
System.out.println(Thread.currentThread().getName() + " step3");
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
});
executorService.execute(() -> {
try {
System.out.println(Thread.currentThread().getName() + " step1");
cyclicBarrier.await();
System.out.println(Thread.currentThread().getName() + " step2");
cyclicBarrier.await();
System.out.println(Thread.currentThread().getName() + " step3");
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
});
executorService.shutdown();
}
}
运行结果:
pool-1-thread-1 step1
pool-1-thread-2 step1
pool-1-thread-2执行回调方法
pool-1-thread-1 step2
pool-1-thread-2 step2
pool-1-thread-2执行回调方法
pool-1-thread-1 step3
pool-1-thread-2 step3
多个线程之间是相互等待的,假如计数器值为N,那么随后调用await()方法的N-1个线程都会因为到达屏障点而被阻塞,当第N个线程调用await()后,计数器值为0了,这时候第N个线程才会发出通知唤醒前面的N-1个线程。也就是当全部线程都到达屏障点时才能一块继续向下执行
此外从上面的案例中还可以得知,CyclicBarrier的计数器具备自动重置的功能,可以循环利用,回调任务是由最后一个到达屏障的线程执行的
2)、CyclicBarrier源码分析
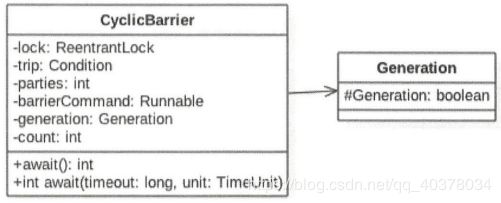
CyclicBarrier基于独占锁实现,本质底层还是基于AQS的。parties用来记录线程个数,这里表示多少线程调用await()后,所有线程才会冲破屏障继续往下运行。而count—开始等于parties,每当有线程调用await()方法就递减1,当count为0时就表示所有线程都到了屏障点。而parties始终用来记录总的线程个数,当count计数器值变为0后,会将parties的值赋给count,从而进行复用
public CyclicBarrier(int parties, Runnable barrierAction) {
if (parties <= 0) throw new IllegalArgumentException();
this.parties = parties;
this.count = parties;
this.barrierCommand = barrierAction;
}
还有一个变量barrierCommand也通过构造函数传递,这是一个任务,这个任务的执行时机是当所有线程都到达屏障点后。使用lock首先保证了更新计数器count的原子性,另外使用lock的条件变量trip支持线程间使用await()和signal()操作进行同步
在变量generation内部有一个变量broken,其用来记录当前屏障是否被打破。这里的broken并没有被声明为volatile的,因为是在锁内使用变量,所以不需要声明
private static class Generation {
boolean broken = false;
}
await()方法:
当前线程调用CyclicBarrier的该方法时会被阻塞,直到满足下面条件之一才会返回:parties个线程都调用了await()方法,也就是线程都到了屏障点;其他线程调用了当前线程的interrupt()方法中断了当前线程,则当前线程会抛出InterruptedException异常而返回;与当前屏障点关联的Generation对象的broken标志被设置为true时,会抛出BrokenBarrierException异常,然后返回
public int await() throws InterruptedException, BrokenBarrierException {
try {
//调用内部的dowait()方法,第一个参数为flase表示不设置超时时间
return dowait(false, 0L);
} catch (TimeoutException toe) {
throw new Error(toe); // cannot happen
}
}
dowait()方法:
private int dowait(boolean timed, long nanos)
throws InterruptedException, BrokenBarrierException,
TimeoutException {
final ReentrantLock lock = this.lock;
lock.lock();
try {
final Generation g = generation;
if (g.broken)
throw new BrokenBarrierException();
if (Thread.interrupted()) {
breakBarrier();
throw new InterruptedException();
}
//如果index==0则说明所有线程都到了屏障点,此时执行初始化时传递的任务
int index = --count;
if (index == 0) { // tripped
boolean ranAction = false;
try {
final Runnable command = barrierCommand;
//执行任务
if (command != null)
command.run();
ranAction = true;
//激活其他因调用await方法而被阻塞的线程,并重置CyclicBarrier
nextGeneration();
//返回
return 0;
} finally {
if (!ranAction)
breakBarrier();
}
}
//index!=0
for (;;) {
try {
//没有设置超时时间
if (!timed)
trip.await();
//设置了超时时间
else if (nanos > 0L)
nanos = trip.awaitNanos(nanos);
} catch (InterruptedException ie) {
if (g == generation && ! g.broken) {
breakBarrier();
throw ie;
} else {
Thread.currentThread().interrupt();
}
}
if (g.broken)
throw new BrokenBarrierException();
if (g != generation)
return index;
if (timed && nanos <= 0L) {
breakBarrier();
throw new TimeoutException();
}
}
} finally {
lock.unlock();
}
}
nextGeneration()方法:
private void nextGeneration() {
//唤醒条件队列里面阻塞的线程
trip.signalAll();
//重置CyclicBarrier
count = parties;
generation = new Generation();
}
3、使用CountDownLatchDown和CyclicBarrier优化对账系统
对账系统业务:用户通过在线商城下单,会生成电子订单,保存在订单库;之后物流会生成派送单给用户发货,派送单保存在派送单库。为了防止漏派送或者重复派送,对账系统每天还会校验是否存在异常订单
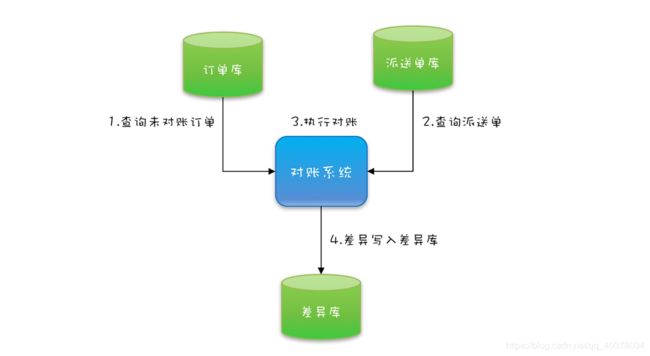
对账系统的核心代码如下,就是在一个单线程里面循环查询订单、派送单,然后执行对账,最后将写入差异库
while (存在未对账订单) {
//查询未对账订单
pos = getPOrders();
//查询派送单
dos = getDOrders();
//执行对账操作
diff = check(pos, dos);
//差异写入差异库
save(diff);
}
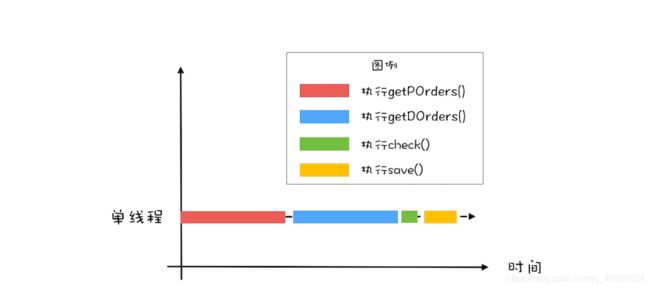
首先要优化性能,就要找到这个对账系统的瓶颈所在:目前的对账系统,由于订单量和派送单量巨大,所以查询未对账订单getPOrders()和查询派送单getDOrders()相对较慢,目前对账系统是单线程执行的,图形化后是下图这个样子
查询未对账订单getPOrders()和查询派送单getDOrders()这两个操作并没有先后顺序的依赖可以并行处理,执行过程如下图所示。对比一下单线程的执行示意图,在同等时间内,并行执行的吞吐量近乎单线程的2倍
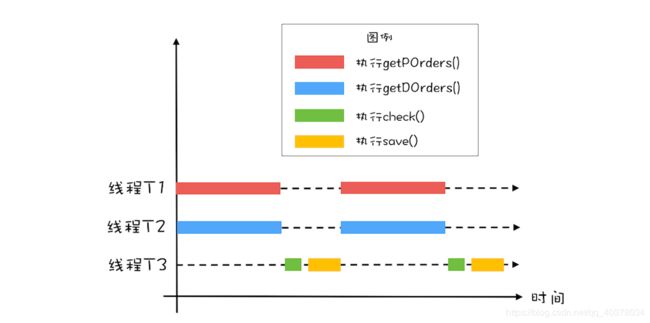
1)、用CountDownLatch实现线程等待
//创建2个线程的线程池
Executor executor = Executors.newFixedThreadPool(2);
while (存在未对账订单) {
//计数器初始化为2
CountDownLatch latch = new CountDownLatch(2);
//查询未对账订单
executor.execute(() -> {
pos = getPOrders();
latch.countDown();
});
//查询派送单
executor.execute(() -> {
dos = getDOrders();
latch.countDown();
});
//等待两个查询操作结束
latch.await();
//执行对账操作
diff = check(pos, dos);
//差异写入差异库
save(diff);
}
在while循环里面,创建了一个CountDownLatch,计数器的初始值等于2,之后在pos = getPOrders();和dos = getDOrders();两条语句的后面对计数器执行减1操作,这个对计数器减1的操作是通过调用latch.countDown();来实现的。在主线程中,通过调用latch.await()来实现对计数器等于0的等待
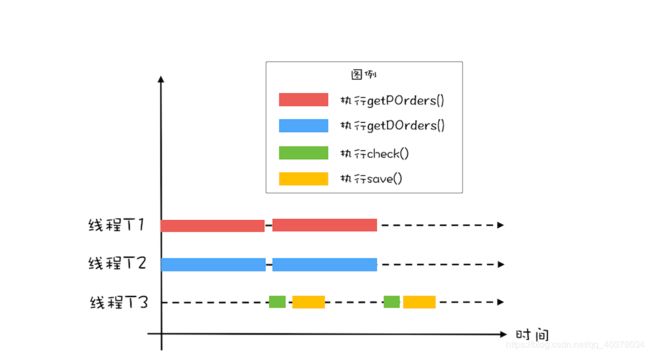
2)、进一步优化性能
getPOrders()和getDOrders()这两个查询操作和对账操作check()、save()之间也是可以并行的,也就是说,在执行对账操作的时候,可以同时去执行下一轮的查询操作,如下图所示
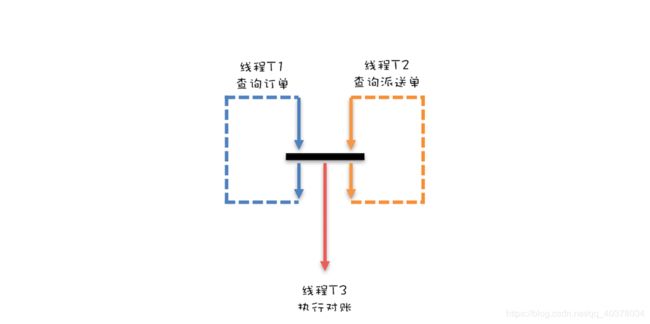
针对对账这个项目,设计了两个队列,并且两个队列的元素之间还有对应关系。具体如下图所示,订单查询操作将订单查询结果插入订单队列,派送单查询操作将派送单插入派送单队列,这两个队列的元素之间是有一一对应的关系的。两个队列的好处是,对账操作可以每次从订单队列出一个元素,从派送单队列出一个元素,然后对这两个元素执行对账操作,这样数据一定不会乱掉

线程T1和线程T2只有都生产完1条数据的时候,才能一起向下执行,也就是说,线程T1和线程T2要互相等待,步调要一致;同时当线程T1和T2都生产完一条数据的时候,还要能够通知线程T3执行对账操作
3)、用CyclicBarrier实现线程同步
//订单队列
Vector<P> pos;
//派送单队列
Vector<D> dos;
//执行回调的线程池
Executor executor = Executors.newFixedThreadPool(1);
final CyclicBarrier barrier = new CyclicBarrier(2, () -> {
executor.execute(() -> check());
});
void check() {
P p = pos.remove(0);
D d = dos.remove(0);
//执行对账操作
diff = check(p, d);
//差异写入差异库
save(diff);
}
void checkAll() {
//循环查询订单库
Thread T1 = new Thread(() -> {
while (存在未对账订单) {
//查询订单库
pos.add(getPOrders());
//等待
barrier.await();
}
});
T1.start();
//循环查询运单库
Thread T2 = new Thread(() -> {
while (存在未对账订单) {
//查询运单库
dos.add(getDOrders());
//等待
barrier.await();
}
});
T2.start();
}
首先创建了一个计数器初始值为2的CyclicBarrier,还传入了一个回调函数,当计数器减到0的时候,会调用这个回调函数
线程T1负责查询订单,当查出一条时,调用barrier.await()来将计数器减1,同时等待计数器变为0;线程T2负责查询派送单,当查出一条时,也调用barrier.await()来将计数器减1,同时等待计数器变为0;当T1和T2都调用barrier.await()的时候,计数器会减到0,此时T1和T2就可以执行下一条语句了,同时会调用barrier的回调函数来执行对账操作
CyclicBarrier的计数器有自动重置的功能,当减到0的时候,会自动重置设置的初始值
回调函数中使用了一个固定大小为1的线程池。首先使用线程池是为了异步操作,否则回调函数是同步调用的,也就是本次对账操作执行完才能进行下一轮的检查;其次线程数量固定为1,防止了多线程并发导致的数据不一致,因为订单和派送单是两个队列,只有单线程去两个队列中取消息才不会出现消息不匹配的问题
4)、总结
CountDownLatch主要用来解决一个线程等待多个线程的场景,而CyclicBarrier是一组线程之间互相等待,而且CyclicBarrier的计数器具备自动重置的功能,可以循环利用,CyclicBarrier还可以设置回调函数
4、信号量Semaphore
1)、信号量模型
信号量模型包括一个计数器,一个等待队列,三个方法。在信号量模型里,计数器和等待队列对外是透明的,所以只能通过信号量模型提供的三个方法来访问它们,这三个方法分别是:init()、down()和up()
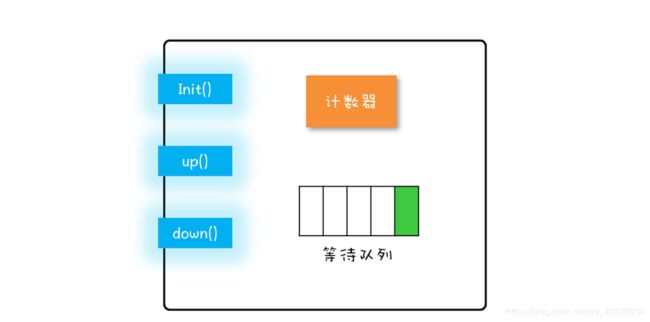
init():设置计数器的初始值down():计数器的值减1;如果此时计数器的值小于0,则当前线程将被阻塞,否则当前线程可以继续执行up():计数器的值加1;如果此时计数器的值小于或者等于0,则唤醒等待队列中的一个线程,并将其从等待队列中移除
init()、down()和up()三个方法都是原子性的。在Java SDK里面,信号量模型是由java.util.concurrent.Semaphore实现的,Semaphore这个类能够保证这三个方法都是原子操作
信号量模型里面down()、up()这两个操作历史上最早称为P操作和V操作,所以信号量模型也被称为PV原语。在Semaphore中,down()和up()对应的则是acquire()和release()
2)、Semaphore使用
1)使用Semaphore实现累加器(互斥)
static int count;
//初始化信号量
static final Semaphore semaphore = new Semaphore(1);
//用信号量保证互斥
static void addOne() {
try {
semaphore.acquire();
count += 1;
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
semaphore.release();
}
}
假设两个线程T1和T2同时访问addOne()方法,当它们同时调用acquire()的时候,由于acquire()是一个原子操作,所以只能由一个线程(假设T1)把信号量里的计数器减为0,另外一个线程(T2)则是将计数器减为-1。对于线程T1,信号量里面的计数器的值是0,大于等于0,所以线程T1会继续执行;对于线程T2,信号量里面的计数器的值是-1,小于0,按照信号量模型里的对down()操作的描述,线程T2将被阻塞。所以此时只有线程T1会进入临界区执行count += 1
当线程T1执行release()操作,也就是up()操作的时候,信号量里计数器的值是-1,加1之后的值是0,小于等于0,按照信号量模型里对up()操作的描述,此时等待队列中的T2将会被唤醒。于是T2在T1执行完临界区代码之后才获得了进入临界区执行的机会,从而保证了互斥性
2)使用Semaphore控制同时访问特定资源的线程数量
public class SemaphoreDemo {
public static void main(String[] args) {
Semaphore semaphore = new Semaphore(8);
for (int i = 0; i < 10; i++) {
new Thread(() -> {
try {
semaphore.acquire();
System.out.println(Thread.currentThread().getName() + "开始执行");
TimeUnit.SECONDS.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
semaphore.release();
}
}).start();
}
}
}
**运行结果:**第一次有8个线程执行了打印,等待5秒后,后两个线程执行了打印
3)使用Semaphore实现一个对象池
public class ObjPool<T, R> {
final List<T> pool;
//用信号量实现限流器
final Semaphore sem;
//构造函数
ObjPool(int size, T t) {
pool = new Vector<T>();
for (int i = 0; i < size; i++) {
pool.add(t);
}
sem = new Semaphore(size);
}
//利用对象池的对象,调用func
R exec(Function<T, R> func) throws InterruptedException {
T t = null;
sem.acquire();
try {
t = pool.remove(0);
return func.apply(t);
} finally {
pool.add(t);
sem.release();
}
}
public static void main(String[] args) throws InterruptedException {
//创建对象池
ObjPool<Long, String> pool = new ObjPool<Long, String>(10, 2L);
//通过对象池获取t,之后执行
pool.exec(t -> {
System.out.println(t);
return t.toString();
});
}
}
Semaphore可以允许多个线程访问一个临界区,用Vector保存对象实例,Vector是线程安全的,用Semaphore 实现限流器。关键的代码是ObjPool里面的exec()方法,这个方法里面实现了限流的功能。在这个方法里面,我们首先调用acquire()方法(与之匹配的是在finally里面调用release()方法),假设对象池的大小是10,信号量的计数器初始化为10,那么前10个线程调用acquire()方法,都能继续执行,而其他线程则会阻塞在acquire()方法上。对于通过信号灯的线程,我们为每个线程分配了一个对象t(这个分配工作是通过pool.remove(0)实现的),分配完之后会执行一个回调函数func,而函数的参数正是前面分配的对象t;执行完回调函数之后,它们就会释放对象(这个释放工作是通过pool.add(t)实现的),同时调用release()方法来更新信号量的计数器。如果此时信号量里计数器的值小于等于0,那么说明有线程在等待,此时会自动唤醒等待的线程
3)、Semaphore源码分析
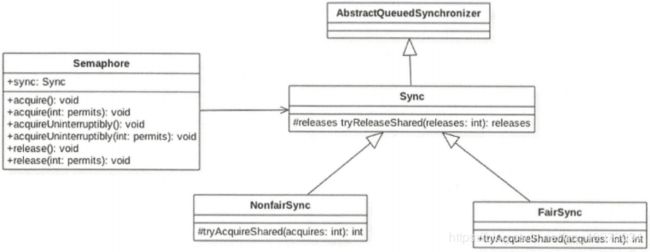
Semaphore还是使用AQS实现的。Sync只是对AQS的一个修饰,并且Sync有两个实现类,用来指定获取信号量时是否采用公平策略
public Semaphore(int permits) {
sync = new NonfairSync(permits);
}
public Semaphore(int permits, boolean fair) {
sync = fair ? new FairSync(permits) : new NonfairSync(permits);
}
Sync(int permits) {
setState(permits);
}
Semaphore默认釆用非公平策略,如果需要使用公平策略则可以使用带两个参数的构造函数来构造Semaphore对象
如CountDownLatch构造函数传递 的初始化信号量个数permits被赋给了AQS的state状态变量一样,这里AQS的state值表示当前持有的信号量个数
1)acquire()方法
public void acquire() throws InterruptedException {
//调用AQS中的模板方法acquireSharedInterruptibly
sync.acquireSharedInterruptibly(1);
}
AQS中的acquireSharedInterruptibly方法:
public final void acquireSharedInterruptibly(int arg)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
//调用Semaphore中sync重写的tryAcquireShared方法,根据构造函数确定使用的公平策略
if (tryAcquireShared(arg) < 0)
//如果获取失败则放入阻塞队列。然后再次尝试,如果失败则调用park方法挂起当前线程
doAcquireSharedInterruptibly(arg);
}
非公平策略:
protected int tryAcquireShared(int acquires) {
return nonfairTryAcquireShared(acquires);
}
final int nonfairTryAcquireShared(int acquires) {
for (;;) {
//获取当前信号量值
int available = getState();
//计算当前剩余值
int remaining = available - acquires;
//如果当前剩余值小于0或者CAS设置成功则返回
if (remaining < 0 ||
compareAndSetState(available, remaining))
return remaining;
}
}
如果线程A先调用了aquire()方法获取信号量,但是当前信号量个数为0,那么线程A会被放入AQS的阻塞队列。过一段时间后线程C调用了release()方法释放了一个信号量,如果当前没有其他线程获取信号量,那么线程A就会被激活,然后获取该信号量,但是假如线程C释放信号量后,线程C调用了aquire()方法,那么线程C就会和线程A去竞争这个信号量资源。如果采用非公平策略,线程C完全可以在线程A被激活前,或者激活后先于线程A获取到该信号量,也就是在这种模式下阻塞线程和当前请求的线程是竞争关系,而不遵循先来先得的策略
公平策略:
protected int tryAcquireShared(int acquires) {
for (;;) {
//公平策略是看当前线程节点的前驱节点是否也在等待获取该资源,如果是则自己放弃获取的权限, 然后当前线程会被放入AQS阻塞队列,否则就去获取
if (hasQueuedPredecessors())
return -1;
int available = getState();
int remaining = available - acquires;
if (remaining < 0 ||
compareAndSetState(available, remaining))
return remaining;
}
}
}
2)release()方法
public void release() {
//调用AQS中的模板方法releaseShared
sync.releaseShared(1);
}
AQS中的releaseShared方法:
public final boolean releaseShared(int arg) {
//尝试释放资源
if (tryReleaseShared(arg)) {
//释放资源成功则调用park方法唤醒AQS队列里面最先挂起的线程
doReleaseShared();
return true;
}
return false;
}
Sync中重写的tryReleaseShared方法:
protected final boolean tryReleaseShared(int releases) {
for (;;) {
//获取当前信号量值
int current = getState();
//将当前信号量值增加releases
int next = current + releases;
if (next < current)
throw new Error("Maximum permit count exceeded");
//使用CAS保证更新信号量值的原子性
if (compareAndSetState(current, next))
return true;
}
}