面试海量数据处理题总结
参考:https://blog.csdn.net/v_july_v/article/details/6279498/
目录
top k 问题
1、海量日志数据,提取出某日访问百度次数最多的那个IP。
2.统计最热门的10个查询串
3.有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词。
4.有10个文件,每个文件1G,每个文件的每一行存放的都是用户的query,每个文件的query都可能重复。要求你按照query的频度排序。
5.在海量数据中找出重复次数最多的一个?
6.上千万或上亿数据(有重复),统计其中出现次数最多的前N个数据。
int数字的重复数据查找(bitmap)
在2.5亿个整数中找出不重复的整数(内存不足以容纳这2.5亿个整数)
腾讯面试题:给40亿个不重复的unsigned int的整数,没排过序的,然后再给一个数,如何快速判断这个数是否在那40亿个数当中?
超大文件取数字交集
字符串重复
给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url
字符串统计(trie 树)
一个文本文件,大约有一万行,每行一个词,要求统计出其中最频繁出现的前10个词
海量数据中位数(计数排序)
主要参考:https://blog.csdn.net/v_july_v/article/details/6279498/
技巧总结(必看):https://blog.csdn.net/guoziqing506/article/details/81365315
MB和G都是在B的基础上
B:字节 = 8位
b:位(一个Int是32位,unsigned int也是)
2的10次 = 10的3次
top k 问题
1、海量日志数据,提取出某日访问百度次数最多的那个IP。
主要问题:
IP地址最多有2^32=4G种取值情况,所以不能完全加载到内存中处理
解决方案:
采用映射的方法,比如模1000,把整个大文件映射为1000个小文件
再找出每个小文中出现频率最大的IP(可以采用hash_map进行频率统计,然后再找出频率最大的几个)及相应的频率。然后再在这1000个最大的IP中,找出那个频率最大的IP
2.统计最热门的10个查询串
搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节。
假设目前有一千万个记录(这些查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就是越热门。),请你统计最热门的10个查询串,要求使用的内存不能超过1G。
主要问题:
内存不能超过1G,一千万条记录,每条记录是255Byte,很显然要占据2.375G内存,这个条件就不满足要求了。
解决方案:
第一步:Query统计:
解法一:多路归并排序
外部排序指的是大文件的排序,当待排序的文件很大时,无法将整个文件的所有记录同时调入内存进行排序,只能将文件存放在外存,这种排称为外部排序。外部排序的过程主要是依据数据的内外存交换和“内部归并”两者结合起来实现的。
外部排序最常用的算法是多路归并排序,即将原文件分解成多个能够一次性装入内存的部分分别把每一部分调入内存完成排序。然后,对已经排序的子文件进行归并排序。
我们可以采用归并排序,因为归并排序有一个比较好的时间复杂度O(NlgN)。排完序之后我们再对已经有序的Query文件进行遍历,统计每个Query出现的次数,再次写入文件中。综合分析一下,排序的时间复杂度是O(NlgN),而遍历的时间复杂度是O(N)
总体时间复杂度:O(N+NlgN)=O(NlgN)。
解法二:哈希表
300万的Query,每个Query255Byte,因此我们可以考虑把他们都放进内存中去,而现在只是需要一个合适的数据结构,在这里,Hash Table绝对是我们优先的选择,因为Hash Table的查询速度非常的快,几乎是O(1)的时间复杂度。
我们的算法:维护一个Key为Query字串,Value为该Query出现次数的HashTable,每次读取一个Query,如果该字串不在Table中,那么加入该字串,并且将Value值设为1;如果该字串在Table中,那么将该字串的计数加一即可。最终我们在O(N)的时间复杂度内完成了对该海量数据的处理。
时间复杂度:O(N)
第二步:找出Top 10
使用堆
借助堆结构,我们可以在log量级的时间内查找和调整/移动。
做法:
维护一个K(该题目中是10)大小的小根堆,然后遍历300万的Query,分别和根元素进行对比。
具体过程:
最先遍历到的k个数存放到最小堆中,并假设它们就是我们要找的最大的k个数,X1>X2...Xmin(堆顶)
而后遍历后续的N-K个数,一一与堆顶元素进行比较,如果遍历到的Xi大于堆顶元素Xmin,则把Xi放入堆中,而后更新整个堆,更新的时间复杂度为logK,如果Xi 时间复杂度: O(K)+O((N-K)*logK)=O(N*logK)。 分析: (1)分文件(在外存中进行) 顺序读文件中,对于每个词x,取hash(x)%5000,然后按照该值存到5000个小文件(记为x0,x1,...x4999)中。这样每个文件大概是200k左右。 如果其中的有的文件超过了1M大小,还可以按照类似的方法继续往下分,直到分解得到的小文件的大小都不超过1M。 (2)文件内排序(内存中) (3)归并 下一步就是把这5000个文件进行归并(类似与归并排序)的过程了。 (1)读取文件,重复的合并到一个文件中 顺序读取10个文件,按照hash(query)%10的结果将query写入到另外10个文件(记为)中。这样新生成的文件每个的大小大约也1G(假设hash函数是随机的)。 (2)排序 (3)归并 对这10个文件进行归并排序(内排序与外排序相结合)。 先做hash,然后求模映射为小文件 求出每个小文件中重复次数最多的一个,并记录重复次数。 然后找出上一步求出的数据中重复次数最多的一个就是所求。 方案1: 上千万或上亿的数据,现在的机器的内存应该能存下。 采用hash_map/搜索二叉树/红黑树等来进行统计次数。 然后就是取出前N个出现次数最多的数据了,可以用堆机制完成。 BitMap算法详解:https://www.cnblogs.com/senlinyang/p/7885685.html 方案1: 数量计算: int有4个字节,32位bit,最多可表示 扫描: 然后扫描这2.5亿个整数,查看Bitmap中相对应位,如果是00变01,01变10,10保持不变。所描完事后,查看bitmap,把对应位是01的整数输出即可。 假设某数据为9。9=8*1+1,即对8的商为1,对8取模为1。应该存在byte[1],将byte[1]的值改为00000002,即把2的一次方赋予byte[1]。 注意:新开数组的所需大小并不取决于数据量的大小,而是取决于某数据值的大小,新开的数组byte的大小N与所需处理的数据集之中的最大值Max有关,N>=Max/8。那么,先得到最大值,再进行查重可不可行呢,效率相对于直接开大空间有多大的提升呢?有待探究。 具体代码实现:https://blog.csdn.net/brk1985/article/details/18732267 方案2: 也可采用与上1题类似的方法,进行划分小文件的方法。然后在小文件中找出不重复的整数,并排序。然后再进行归并,注意去除重复的元素。 快速排序+二分查找过于慢。以下是其它更好的方法: 申请512M的内存,一个bit位代表一个unsigned int值。读入40亿个数,设置相应的bit位,读入要查询的数,查看相应bit位是否为1,为1表示存在,为0表示不存在。 问题:现有两个各有20亿行的文件,每一行都只有一个数字,求这两个文件的交集。 解决: 采用bitset进行问题解决 因为int的最大数是2^32 - 1 == 4G,用一个二进制的下标来表示一个int值,大概需要4G个bit位,即约4G/8 = 552M的内存。这可以解决问题了。 如果都是正数: 用int存的话,4G bit/32b = 2的32次/2的5次 = 2的27次 = 128M个 建立int [128M] 的数组,对于每个数,先 /32,确定在数组哪个位置,然后%32,确定在该int的哪一位 然后对这个数组取并集即可统计 正负都有 1.首先遍历文件,将每个文件按照数字的正数,负数标记到2个BitSet上为:正数BitSetA_positive,负数BitSetA_negative 2.遍历另为一个文件,生成正数:BitSetB_positive ,BitSetB_negative 3.取BitSetA_positive and BitSetB_positive 得到2个文件的正数的交集,同理得到负数的交集。 4.合并,问题解决。 这里一次只能解决全正数,或全负数,所以要分两次。 问题: 可以估计每个文件安的大小为5G×64=320G(5*10^9*64 = 320 * 10^9 B),远远大于内存限制的4G(4*10^9 B)。所以不可能将其完全加载到内存中处理。考虑采取分而治之的方法。 解决: (1)分文件: 遍历文件a,对每个url求取hash(url)%1000,然后根据所取得的值将url分别存储到1000个小文件(记为a0,a1,...,a999)中。这样每个小文件的大约为300M。 遍历文件b,采取和a相同的方式将url分别存储到1000小文件(记为b0,b1,...,b999)。这样处理后,所有可能相同的url都在对应的小文件(a0vsb0,a1vsb1,...,a999vsb999)中,不对应的小文件不可能有相同的url。然后我们只要求出1000对小文件中相同的url即可。 (2)逐个找重复: 求每对小文件中相同的url: 把其中一个小文件的url存储到hash_set中,然后遍历另一个小文件的每个url,看其是否在刚才构建的hash_set中,如果是,那么就是共同的url,存到文件里面就可以了。 方案1: 这题是考虑时间效率。 用trie树统计每个词出现的次数,时间复杂度是O(n*le)(le表示单词的平准长度)。 然后是找出出现最频繁的前10个词,可以用堆来实现,前面的题中已经讲到了,时间复杂度是O(n*lg10)。 总的时间复杂度,是O(n*le)与O(n*lg10)中较大的哪一个。 只有2G内存的pc机,在一个存有10G个整数的文件,从中找到中位数,写一个算法。 关于中位数:数据排序后,位置在最中间的数值。即将数据分成两部分,一部分大于该数值,一部分小于该数值。中位数的位置:当样本数为奇数时,中位数=(N+1)/2 ; 当样本数为偶数时,中位数为N/2与1+N/2的均值(那么10G个数的中位数,就第5G大的数与第5G+1大的数的均值了)。 分析: 明显是一道工程性很强的题目,和一般的查找中位数的题目有几点不同。 2. 若看成从N个数中找出第K大的数,如果K个数可以读进内存,可以利用最小或最大堆,但这里K=N/2,有5G个数,仍然不能读进内存。 解法1:桶排序 首先假设是32位无符号整数。整数范围是0 - 2^32 - 1,一共有4G种取值 故需划分区间,每个区间用来计数,需要计数的下10G(10*2^32 )这么大的数,因为可能一个数字重复10G次,故每个区间最少需要64位无符号整数来作为计数,即8B 故区间个数共:2G/8B = 256M个 要把4G个数映射到256M个区间,每个区段有16(4G/256M = 16)种值,每16个值算一段, 0~15是第1段,16~31是第2段,……2^32-16 ~2^32-1是第256M段。 操作: 1. 读一遍10G个整数,把整数映射到256M个区段中,用一个64位无符号整数给每个相应区段记数。 2. 从前到后对每一段的计数累加,当累加的和超过5G时停止,找出这个区段(即累加停止时达到的区段,也是中位数所在的区段)的数值范围,设为[a,a+15],同时记录累加到前一个区段的总数,设为m。然后,释放除这个区段占用的内存。 3. 再读一遍10G个整数,把在[a,a+15]内的每个值计数,即有16个计数。 4. 对新的计数依次累加,每次的和设为n,当m+n的值超过5G时停止,此时的这个计数所对应的数就是中位数。 复杂度: 上面的海量数据寻找中位数,其实就是利用了“分割”思想,每次将 问题空间 大约分解成原问题空间的一半左右。(划分成两个文件,直接丢弃其中一个文件),故总的复杂度可视为O(logN) N=10亿。 现在 有10亿个int型的数字(JAVA中 int 型占4B),以及一台可用内存为1GB的机器,如何找出这10亿个数字的中位数? 解法2:利用二进制分文件 && 快速排序算法中的“分割思想” 2的10次 = 10的3次 10亿个数字,每个数字在内存中占4B,10亿个数字完全加载到内存中需要:10*108*4B ,约为:4GB内存。显然不能把所有的数字都装入内存。 具体如下: (1)利用二进制分文件 假设10亿个数字保存在一个大文件中,依次读一部分文件到内存(不超过内存的限制:1GB),将每个数字用二进制表示,比较二进制的最高位(第32位),如果数字的最高位为0,则将这个数字写入 file_0文件中;如果最高位为 1,则将该数字写入file_1文件中。【这里的最高位类似于快速排序中的枢轴元素】 从而将10亿个数字分成了两个文件(几乎是二分的),假设 file_0文件中有 6亿 个数字,file_1文件中有 4亿 个数字。那么中位数就在 file_0 文件中,并且是 file_0 文件中所有数字排序之后的第 1亿 个数字。 【为什么呢?因为10亿个数字的中位数是10亿个数排序之后的第5亿个数。现在file_0有6亿个数,file_1有4亿个数,file_0中的数都比file_1中的数要大(最高位为符号位,file_1中的数都是负数,file_0中的数都是正数,也即这里一共只有4亿个负数,排序之后的第5亿个数一定是正数,那么排序之后的第5亿个数一定位于file_0中)】。除去4亿个负数,中位数就是6亿个正数从小到大排序之后 的第 1 亿个数。 现在,我们只需要处理 file_0 文件了(不需要再考虑file_1文件)。对于 file_0 文件,同样采取上面的措施处理:将file_0文件依次读一部分到内存(不超内存限制:1GB),将每个数字用二进制表示,比较二进制的 次高位(第31位),如果数字的次高位为0,写入file_0_0文件中;如果次高位为1,写入file_0_1文件 中。 现假设 file_0_0文件中有3亿个数字,file_0_1中也有3亿个数字,则中位数就是:file_0_0文件中的数字从小到大排序之后的第1亿个数字。 抛弃file_0_1文件,继续对 file_0_0文件 根据 次次高位(第30位) 划分,假设此次划分的两个文件为:file_0_0_0中有0.5亿个数字,file_0_0_1中有2.5亿个数字,那么中位数就是 file_0_0_1文件中的所有数字排序之后的 第 0.5亿 个数。 ...... (2)快速排序算法中的“分割思想” 按照上述思路,直到划分的文件可直接加载进内存时(比如划分的文件中只有5KW个数字了),就可以直接对数字进行快速排序,找出中位数了。当然,你也使用“快排的分割算法”来找出中位数(比使用快速排序要快) 思路: 一个数若可以进行因数分解,那么分解时得到的两个数一定是一个小于等于sqrt(n),一个大于等于sqrt(n),据此,上述代码中并不需要遍历到n-1,遍历到sqrt(n)即可,因为若sqrt(n)左侧找不到约数,那么右侧也一定找不到约数。 第一、100000名实时遍历系统一定承受不了或者说这样做代价太大,那么可以首先遍历一遍,挑选出战斗力最高的1000名,然后后面只遍历这1000名就可以了,因为前500名大概率都是前一千名产生的,减少系统开销。 第二、为了防止某些玩家充钱了,大幅提升战斗力,那么可以设置一个阈值,如果某个玩家战斗力增加速度超过阈值,那么这个玩家也应该纳入实时排序过程中。 第三、最后100000名玩家的战斗力可以定期在服务器压力不大的时候,比如休服时期或者夜间,做整体排序,以便校验数据的准确性。 (1)建立统计字典,时间O(N) 一个字典:记录每个词出现的行号,最后字典大小为词表大小 (2)获取连通块(这步时间复杂度也是O(N)) 以一个词为起点,通过行号,去扩展连通块,最后能获得一个同义词合集,作为一行输出(被加入的词从字典中删去) 然后继续判断下一个词 3.有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词。
对每个小文件,统计每个文件中出现的词以及相应的频率(可以采用trie树/hash_map等),并取出出现频率最大的100个词(可以用含100个结点的最小堆),并把100个词及相应的频率存入文件,这样又得到了5000个文件。4.有10个文件,每个文件1G,每个文件的每一行存放的都是用户的query,每个文件的query都可能重复。要求你按照query的频度排序。
找一台内存在2G左右的机器,依次对用hash_map(query, query_count)来统计每个query出现的次数。利用快速/堆/归并排序按照出现次数进行排序。将排序好的query和对应的query_cout输出到文件中。这样得到了10个排好序的文件(记为)。5.在海量数据中找出重复次数最多的一个?
6.上千万或上亿数据(有重复),统计其中出现次数最多的前N个数据。
int数字的重复数据查找(bitmap)
在2.5亿个整数中找出不重复的整数(内存不足以容纳这2.5亿个整数)
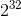 个正整数,即4G个正整数(1G=
个正整数,即4G个正整数(1G=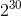 ,1K=
,1K=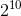 )
)
用2Bitmap法,每个正整数用两个bit的标志位,00表示没有出现,01表示出现1次,10表示出现多次。
开辟一个用2Bitmap法标志4G个正整数的桶数组,则总共需要4G*2bit=1G内存。
腾讯面试题:给40亿个不重复的unsigned int的整数,没排过序的,然后再给一个数,如何快速判断这个数是否在那40亿个数当中?
方案1:超大文件取数字交集
字符串重复
给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url
字符串统计(trie 树)
一个文本文件,大约有一万行,每行一个词,要求统计出其中最频繁出现的前10个词
海量数据中位数(计数排序)
1. 原数据不能读进内存,不然可以用快速选择,如果数的范围合适的话还可以考虑桶排序或者计数排序,但这里假设是32位整数,仍有4G种取值,需要一个16G大小的数组来计数。
写出10万以内的质数
100000个玩家的战斗力,要排名前500名,而且需要实时更新,怎么处理?
一个文件每一行有多个同义词,最后要求分行输出,每一行是合并的同义词集合