大数据技术之 --Apache Phoenix
简介
Phoenix是一个在Hbase上面实现的基于Hadoop的OLTP技术,具有低延迟、事务性、可使用SQL、提供JDBC接口的特点。 而且Phoenix还提供了Hbase二级索引的解决方案,丰富了Hbase查询的多样性,继承了Hbase海量数据快速随机查询的特点。
Phoenix完全使用Java编写,作为HBase内嵌的JDBC驱动。Phoenix查询引擎会将SQL查询转换为一个或多个HBase扫描,并编排执行以生成标准的JDBC结果集。直接使用HBase API、协同处理器与自定义过滤器,对于简单查询来说,其性能量级是毫秒,对于百万级别的行数来说,其性能量级是秒。
部署
![]()
parcel-repo包下 放置下载的文件
网址:https://archive.cloudera.com/phoenix/
分配激活重启服务即可
关于版本
使用版本 5.0.0-cdh6.2.0
Phoenix启动脚本使用Python2.x语法编写,所以使用时要退出conda环境
– conda deactivate 退出base环境 使用自带python2版本
– conda activate 重新进入conda环境 默认python3环境
基本使用
Phoenix作为应用层和HBASE之间的中间件,以下特性使它在大数据量的简单查询场景有着独有的优势
- 二级索引支持(global index + local index)
- 编译SQL成为原生HBASE的可并行执行的scan
- 在数据层完成计算,server端的coprocessor执行聚合
- 下推where过滤条件到server端的scan filter上
- 利用统计信息优化、选择查询计划(5.x版本将支持CBO)
- skip scan功能提高扫描速度
一般可以使用以下三种方式访问Phoenix
- JDBC API
- 使用Python编写的命令行工具(sqlline, sqlline-thin和psql等)
- SQuirrel
一、命令行工具psql使用示例
1.创建一个建表的sql脚本文件us_population.sql:
CREATE TABLE IF NOT EXISTS us_population (
state CHAR(2) NOT NULL,
city VARCHAR NOT NULL,
population BIGINT
CONSTRAINT my_pk PRIMARY KEY (state, city));
2. 创建csv格式的数据文件us_population.csv:
NY,New York,8143197
CA,Los Angeles,3844829
IL,Chicago,2842518
TX,Houston,2016582
PA,Philadelphia,1463281
AZ,Phoenix,1461575
TX,San Antonio,1256509
CA,San Diego,1255540
TX,Dallas,1213825
CA,San Jose,912332
3. 创建一个查询sql脚本文件us_population_queries.sql
SELECT state as "State",count(city) as "City Count",sum(population) as "Population Sum"
FROM us_population
GROUP BY state
ORDER BY sum(population) DESC;
4. 执行psql.py工具运行sql脚本
./psql.py <your_zookeeper_quorum> us_population.sql us_population.csv us_population_queries.sql
二、JDBC API使用示例
1. 使用Maven构建工程时,需要添加以下依赖
com.aliyun.phoenix
ali-phoenix-core
${version}
2. 创建名为test.java的文件
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.PreparedStatement;
import java.sql.Statement;
public class test {
public static void main(String[] args) throws SQLException {
Statement stmt = null;
ResultSet rset = null;
Connection con = DriverManager.getConnection("jdbc:phoenix:[zookeeper]");
stmt = con.createStatement();
stmt.executeUpdate("create table test (mykey integer not null primary key, mycolumn varchar)");
stmt.executeUpdate("upsert into test values (1,'Hello')");
stmt.executeUpdate("upsert into test values (2,'World!')");
con.commit();
PreparedStatement statement = con.prepareStatement("select * from test");
rset = statement.executeQuery();
while (rset.next()) {
System.out.println(rset.getString("mycolumn"));
}
statement.close();
con.close();
}
}
3.执行test.java
javac test.java
java -cp "../phoenix-[version]-client.jar:." test
三、数据类型
24个简单数据类型和1个ARRAY复杂数据类型
1. INTEGER
2. UNSIGNED_INT
3. BIGINT
4. UNSIGNED_LONG
5. TINYINT
6. UNSIGNED_TINYINT
7. SMALLINT
8. UNSIGNED_SMALLINT
9. FLOAT
10. UNSIGNED_FLOAT
11. DOUBLE
12. UNSIGNED_DOUBLE
13. DECIMAL
14. BOOLEAN
15. TIME
16. DATE
17. TIMESTAMP
18. UNSIGNED_TIME
19. UNSIGNED_DATE
20. UNSIGNED_TIMESTAMP
21. VARCHAR
22. CHAR
23. BINARY
24. VARBINARY
25. ARRAY
四、DML基本语法
1.Select
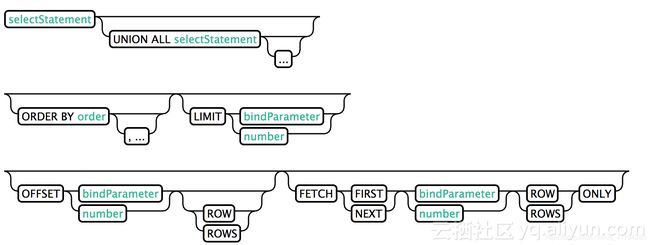
从一个或者多个表中查询数据。
LIMIT(或者FETCH FIRST) 在ORDER BY子句后将转换为top-N查询。
OFFSET子句指定返回查询结果前跳过的行数
示例
SELECT * FROM TEST LIMIT 1000;
SELECT * FROM TEST LIMIT 1000 OFFSET 100;
SELECT full_name FROM SALES_PERSON WHERE ranking >= 5.0
UNION ALL SELECT reviewer_name FROM
CUSTOMER_REVIEW WHERE score >= 8.0
要注意一点:如果HBase中已经有表,需要在Phoenix中创建view来进行查询
2.Upsert
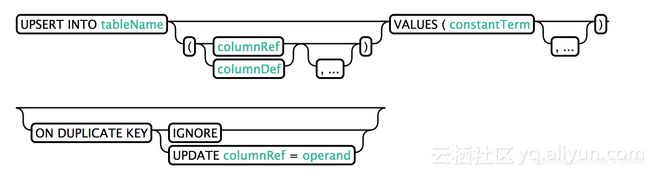
此处upsert语义有异于标准SQL中的Insert,当写入值不存在时,表示写入数据,否则更新数据。其中列的声明是可以省略的,当省略时,values指定值的顺序和目标表中schema声明列的顺序需要一致。
ON DUPLICATE KEY是4.9版本中的功能,表示upsert原子写入的语义,在写入性能上弱于非原子语义。相同的row在同一batch中按照执行顺序写入。
UPSERT INTO TEST VALUES('foo','bar',3);
UPSERT INTO TEST(NAME,ID) VALUES('foo',123);
UPSERT INTO TEST(ID, COUNTER) VALUES(123, 0) ON DUPLICATE KEY UPDATE COUNTER = COUNTER + 1;
UPSERT INTO TEST(ID, MY_COL) VALUES(123, 0) ON DUPLICATE KEY IGNORE;
3.Upsert Select

从另外一张表中读取数据写入到目标表中,如果数据存在则更新,否则插入数据。插入目标表的值顺序和查询表指定查询字段一致。当auto commit被打开并且select子句没有聚合时,写入目标表这个过程是在server端完成的,否则查询的数据会先缓存在客户端再写入目标表中(phoenix.mutate.upsertBatchSize表示从客户端一次commit的行数,默认10000行)。
UPSERT INTO test.targetTable(col1, col2) SELECT col3, col4 FROM test.sourceTable WHERE col5 < 100
UPSERT INTO foo SELECT * FROM bar;
4.Delete

删除选定的列。如果auto commit打开,删除操作将在server端执行。
DELETE FROM TABLENAME;
DELETE FROM TABLENAME WHERE PK=123;
DELETE FROM TABLENAME WHERE NAME LIKE '%';
五、加盐表
1. 什么是加盐?
在密码学中,加盐是指在散列之前将散列内容(例如:密码)的任意固定位置插入特定的字符串。这个在散列中加入字符串的方式称为“加盐”。其作用是让加盐后的散列结果和没有加盐的结果不相同,在不同的应用情景中,这个处理可以增加额外的安全性。而Phoenix中加盐是指对pk对应的byte数组插入特定的byte数据。
2. 加盐能解决什么问题?
加盐能解决HBASE读写热点问题,例如:单调递增rowkey数据的持续写入,使得负载集中在某一个RegionServer上引起的热点问题。
3. 怎么对表加盐?
在创建表的时候指定属性值:SALT_BUCKETS,其值表示所分buckets(region)数量, 范围是1~256。
CREATE TABLE mytable (my_key VARCHAR PRIMARY KEY, col VARCHAR) SALT_BUCKETS = 8;
4. 加盐的原理是什么?
加盐的过程就是在原来key的基础上增加一个byte作为前缀,计算公式如下:
new_row_key = ((byte) (hash(key) % BUCKETS_NUMBER) + original_key
以上公式中 BUCKETS_NUMBER 代表创建表时指定的 salt buckets 大小,hash 函数的实际计算方式如下:
public static int hash (byte a[], int offset, int length) {
if (a == null)
return 0;
int result = 1;
for (int i = offset; i < offset + length; i++) {
result = 31 * result + a[i];
}
return result;
}
5. 一个表“加多少盐合适”?
- 当可用block cache的大小小于表数据大小时,较优的slated bucket是和region server数量相同,这样可以得到更好的读写性能。
- 当表的数量很大时,基本上会忽略blcok cache的优化收益,大部分数据仍然需要走磁盘IO。比如对于10个region server集群的大表,可以考虑设计64~128个slat buckets。
6. 加盐时需要注意
- 创建加盐表时不能再指定split key。
- 加盐属性不等同于split key, 一个bucket可以对应多个region。
- 太大的slated buckets会减小range查询的灵活性,甚至降低查询性能。
六、二级索引
一、概要
目前HBASE只有基于字典序的主键索引,对于非主键过滤条件的查询都会变成扫全表操作,为了解决这个问题Phoenix引入了二级索引功能。然而此二级索引又有别于传统关系型数据库的二级索引
二、二级索引
示例表如下(为了能够容易通过HBASE SHELL对照表内容,我们对属性值COLUMN_ENCODED_BYTES设置为0,不对column family进行编码):
CREATE TABLE TEST (
ID VARCHAR NOT NULL PRIMARY KEY,
COL1 VARCHAR,
COL2 VARCHAR
) COLUMN_ENCODED_BYTES=0;
upsert into TEST values('1', '2', '3');
1. 全局索引
全局索引更多的应用在读较多的场景。它对应一张独立的HBASE表。对于全局索引,在查询中检索的列如果不在索引表中,默认的索引表将不会被使用,除非使用hint。
创建全局索引:
CREATE INDEX IDX_COL1 ON TEST(COL1)
通过HBASE SHELL观察生成的索引表IDX_COL1。我们发现全局索引表的RowKey存储了索引列的值和原表RowKey的值,这样编码更有利于提高查询的性能。
hbase(main):001:0> scan 'IDX_COL1'
ROW COLUMN+CELL
2\x001 column=0:_0, timestamp=1520935113031, value=x
1 row(s) in 0.1650 seconds
实际上全局索引的RowKey将会按照如下格式进行编码。

- SALT BYTE: 全局索引表和普通phoenix表一样,可以在创建索引时指定
SALT_BUCKETS或者split key。此byte正是存储着salt。 - TENANT_ID: 当前数据对应的多租户ID。
- INDEX VALUE: 索引数据。
- PK VALUE: 原表的RowKey。
2. 本地索引
因为本地索引和原数据是存储在同一个表中的,所以更适合写多的场景。对于本地索引,查询中无论是否指定hint或者是查询的列是否都在索引表中,都会使用索引表。
创建本地索引:
create local index LOCAL_IDX_COL1 ON TEST(COL1);
通过HBASE SHELL观察表’TEST’, 我们可以看到表中多了一行column为L#0:_0的索引数据。
hbase(main):001:0> scan 'TEST'
ROW COLUMN+CELL
\x00\x002\x001 column=L#0:_0, timestamp=1520935997600, value=_0
1 column=0:COL1, timestamp=1520935997600, value=2
1 column=0:COL2, timestamp=1520935997600, value=3
1 column=0:_0, timestamp=1520935997600, value=x
2 row(s) in 0.1680 seconds
本地索引的RowKey将会按照如下格式进行编码:

- REGION START KEY : 当前row所在region的start key。加上这个start key的好处是,可以让索引数据和原数据尽量在同一个region, 减小IO,提升性能。
- INDEX ID : 每个ID对应不同的索引表。
- TENANT ID :当前数据对应的多租户ID。
- INDEX VALUE: 索引数据。
- PK VALUE: 原表的RowKey。
3. 覆盖索引
覆盖索引的特点是把原数据存储在索引数据表中,这样在查询到索引数据时就不需要再次返回到原表查询,可以直接拿到查询结果。
创建覆盖索引:
create index IDX_COL1_COVER_COL2 on TEST(COL1) include(COL2);
通过HBASE SHELL 查询表IDX_COL1_COVER_COL2, 我们发现include的列的值被写入到了value中。
hbase(main):003:0> scan 'IDX_COL1_COVER_COL2'
ROW COLUMN+CELL
2\x001 column=0:0:COL2, timestamp=1520943893821, value=3
2\x001 column=0:_0, timestamp=1520943893821, value=x
1 row(s) in 0.0180 seconds
对于类似select col2 from TEST where COL1='2'的查询,查询一次索引表就能获得结果。其查询计划如下:
+--------------------------------------------------------------------------------------+-----------------+----------------+---+
| PLAN | EST_BYTES_READ | EST_ROWS_READ | E |
+--------------------------------------------------------------------------------------+-----------------+----------------+---+
| CLIENT 1-CHUNK PARALLEL 1-WAY ROUND ROBIN RANGE SCAN OVER IDX_COL1_COVER_COL2 ['2'] | null | null | n |
+--------------------------------------------------------------------------------------+-----------------+----------------+---+
4. 函数索引
函数索引的特点是能根据表达式创建索引,适用于对查询表,过滤条件是表达式的表创建索引。例如:
//创建函数索引
CREATE INDEX CONCATE_IDX ON TEST (UPPER(COL1||COL2))
//查询函数索引
SELECT * FROM TEST WHERE UPPER(COL1||COL2)='23'
三、什么是Phoenix的二级索引?
Phoenix的二级索引我们基本上已经介绍过了,我们回过头来继续看Phoenix二级索引的官方定义:Secondary indexes are an orthogonal way to access data from its primary access path。通过以下例子我们再理解下这个定义。
- 对表
TEST的COL1创建全局索引
CREATE INDEX IDX_COL1 ON TEST(COL1);
- 查询所有字段。
select * from TEST where COL1='2';
以上查询的查询计划如下:
+----------------------------------------------------------------+-----------------+----------------+--------------+
| PLAN | EST_BYTES_READ | EST_ROWS_READ | EST_INFO_TS |
+----------------------------------------------------------------+-----------------+----------------+--------------+
| CLIENT 1-CHUNK PARALLEL 1-WAY ROUND ROBIN FULL SCAN OVER TEST | null | null | null |
| SERVER FILTER BY COL1 = '2' | null | null | null |
+----------------------------------------------------------------+-----------------+----------------+--------------+
- 查询id字段:
select id from TEST where COL1='2';
查询计划如下
+---------------------------------------------------------------------------+-----------------+----------------+--------------+
| PLAN | EST_BYTES_READ | EST_ROWS_READ | EST_INFO_TS |
+---------------------------------------------------------------------------+-----------------+----------------+--------------+
| CLIENT 1-CHUNK PARALLEL 1-WAY ROUND ROBIN RANGE SCAN OVER IDX_COL1 ['2'] | null | null | null |
| SERVER FILTER BY FIRST KEY ONLY | null | null | null |
+---------------------------------------------------------------------------+-----------------+----------------+--------------+
两个查询都没有通过hint强制指定索引表,查询计划显示,查询所有字段时发生了需要极力避免的扫全表操作(一般数据量在几十万级别的扫全表很容易造成集群不稳定),而查询id时利用索引表走了点查。从现象来看,当查询中出现的字段都在索引表中时(可以是索引字段或者数据表主键,也可以是覆盖索引字段),会自动走索引表,否则查询会退化为全表扫描。
在我们实际应用中一个数据表会有多个索引表,为了能让我们的查询使用合理的索引表,目前都需要通过Hint去指定。
四、索引Building
Phoenix的二级索引创建有同步和异步两种方式。
- 在执行
CREATE INDEX IDX_COL1 ON TEST(COL1)时会进行索引数据的同步。此方法适用于数据量较小的情况。 - 异步build索引需要借助MR,创建异步索引语法和同步索引相差一个关键字:
ASYNC。
//创建异步索引
CREATE INDEX ASYNC_IDX ON DB.TEST (COL1) ASYNC
//build 索引数据
${HBASE_HOME}/bin/hbase org.apache.phoenix.mapreduce.index.IndexTool --schema DB --data-table TEST --index-table ASYNC_IDX --output-path ASYNC_IDX_HFILES
五、索引问题汇总
1. 创建同步索引超时怎么办?
在客户端配置文件hbase-site.xml中,把超时参数设置大一些,足够build索引数据的时间。
hbase.rpc.timeout
60000000
hbase.client.scanner.timeout.period
60000000
phoenix.query.timeoutMs
60000000
2. 索引表最多可以创建多少个?
建议不超过10个
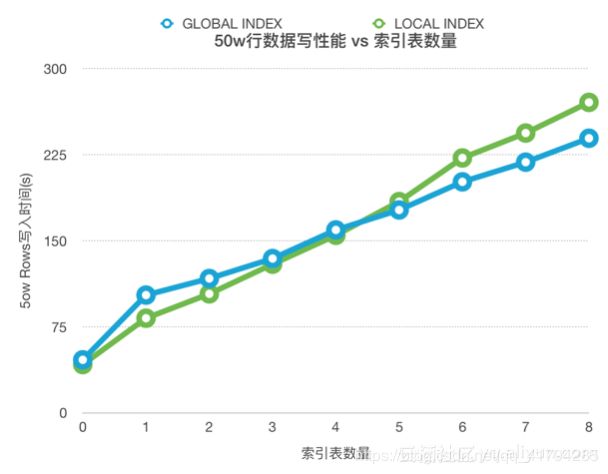
3. 为什么索引表多了,单条写入会变慢?
索引表越多写放大越严重。写放大情况可以参考下图。
七、如何使用自增ID
在传统关系型数据库中设计主键时,自增ID经常被使用。不仅能够保证主键的唯一,同时也能简化业务层实现。
1、创建自增序列
CREATE SEQUENCE [IF NOT EXISTS] SCHEMA.SEQUENCE_NAME
[START WITH number]
[INCREMENT BY number]
[MINVALUE number]
[MAXVALUE number]
[CYCLE]
[CACHE number]
start用于指定第一个值。如果不指定默认为1.increment指定每次调用next value for后自增大小。 如果不指定默认为1。minvalue和maxvalue一般与cycle连用, 让自增数据形成一个环,从最小值到最大值,再从最大值到最小值。cache默认为100, 表示server端生成100个自增序列缓存在客户端,可以减少rpc次数。此值也可以通过phoenix.sequence.cacheSize来配置。
CREATE SEQUENCE my_sequence;-- 创建一个自增序列,初始值为1,自增间隔为1,将有100个自增值缓存在客户端。
CREATE SEQUENCE my_sequence START WITH -1000
CREATE SEQUENCE my_sequence INCREMENT BY 10
CREATE SEQUENCE my_cycling_sequence MINVALUE 1 MAXVALUE 100 CYCLE;
CREATE SEQUENCE my_schema.my_sequence START 0 CACHE 10
2、删除自增序列
DROP SEQUENCE [IF EXISTS] SCHEMA.SEQUENCE_NAME
DROP SEQUENCE my_sequence
DROP SEQUENCE IF EXISTS my_schema.my_sequence
3、案例
对现有的书籍进行编号并存储,要求编号是惟一的。存储书籍信息的建表语句如下:
create table books(
id integer not null primary key,
name varchar,
author varchar
)SALT_BUCKETS = 8;
由于自增ID作为rowkey,容易造成集群热点问题,所以在创建表时最好通过加盐方式解决 SALT_BUCKTES = 8即是加盐操作
-
创建自增序列,初始值为10000,自增间隔为1,缓存大小为1000.
CREATE SEQUENCE book_sequence START WITH 10000 INCREMENT BY 1 CACHE 1000; -
通过自增序列,写入数据信息。
UPSERT INTO books(id, name, author) VALUES( NEXT VALUE FOR book_sequence,'DATA SCIENCE', 'JHONE'); UPSERT INTO books(id, name, author) VALUES( NEXT VALUE FOR book_sequence,'Effective JAVA','Joshua Bloch'); -
查看结果
八、动态列(灵活的功能)
动态列是指在查询中新增字段,操作创建表时未指定的列。传统关系型数据要实现动态列目前常用的方法有:设计表结构时预留新增字段位置、设计更通用的字段、列映射为行和利用json/xml存储字段扩展字段信息等,这些方法多少都存在一些缺陷,动态列的实现只能依赖逻辑层的设计实现。由于Phoenix是HBase上的SQL层,借助HBase特性实现的动态列,避免了传统关系型数据库动态列实现存在的问题。
示例表(用于语法说明)
CREATE TABLE EventLog (
eventId BIGINT NOT NULL,
eventTime TIME NOT NULL,
eventType CHAR(3)
CONSTRAINT pk PRIMARY KEY (eventId, eventTime)) COLUMN_ENCODED_BYTES=0
- Upsert
在插入数据时指定新增列字段名和类型,并在values对应的位置设置相应的值。语法如下:
upsert into
(exists_col1, exists_col2, ... (new_col1 time, new_col2 integer, ...))
VALUES
(v1, v2, ... (v1, v2, ...))
动态列写入示例:
UPSERT INTO EventLog (eventId, eventTime, eventType, lastGCTime TIME, usedMemory BIGINT, maxMemory BIGINT) VALUES(1, CURRENT_TIME(), 'abc', CURRENT_TIME(), 512, 1024);
查询看一下
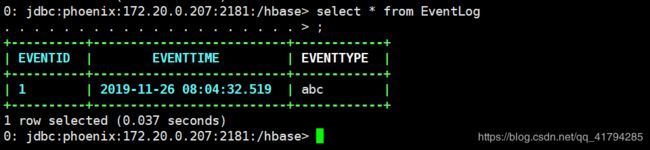
查询发现并没新增列的数据,也就是通过动态列插入值时并没有对表的schema直接改变。
实际上HBase表中已经新增列以及数据。那通过动态列添加的数据怎么查询呢?
- Select
动态列查询语法
select [*|table.*|[table.]colum_name_1[AS alias1][,[table.]colum_name_2[AS alias2] …], ]
FROM tableName ( [, ...])
[where clause]
[group by clause]
[having clause]
[order by clause]
动态列查询示例
SELECT eventId, eventTime, lastGCTime, usedMemory, maxMemory FROM EventLog(lastGCTime TIME, usedMemory BIGINT, maxMemory BIGINT) where eventId=1
查询结果如下:

总结
Phoneix的动态列功能是非SQL标准语法,它给我们带来更多的灵活性,不再为静态schema的字段扩展问题而困扰。然而我们在实际应用中,应该根据自己的业务需求决定是否真的使用动态列,因为动态列的滥用会大幅度的增加我们的维护成本。