JPA详解
JPA 的简介
- Java Persistence API(Java 持久层 API):用于对象持久化的 API
- 作用:使得应用程序以统一的方式访问持久层

JPA 与 Hibernate的什么关系:
1)JPA 是 一个标准的接口
2 Hibernate 是 JPA 的一个实现 :
Hibernate是如何实现与JPA的关系的?
通过hibernate-annotation、hibernate-entitymanager和hibernate-core三个组件来实现
JPA 包括三个方面的技术:
- ORM JavaBean和数据库中的数据表建立映射关系,支持 XML 和 注解(jdk5.0) 两种形式
- JPA 的 API
- 查询语言:JPQL,jpql其原型就是hibernate的hql
一般在实际开发中,优先考虑使用JPA注解,这样更有利于程序的移植和扩展
JPA版本:
- JPA.0 - 此版本于2009年下半年发布。以下是此版本的重要功能:
- 它支持验证。
- 它扩展了对象关系映射的功能。
- 它共享缓存支持的对象。它共享缓存支持的对象。
- JPA 2.1 - JPA 2.1于2013年发布,具有以下特性: -
- 它允许提取对象。
- 它为条件更新/删除提供支持。
- 它生成模式。
- JPA 2.2 - JPA 2.2在2017年作为维护开发而发布。它的一些重要特性是:
- 它支持Java 8的日期和时间。
- 它提供了@Repeatable注释,当想要将相同的注释应用到声明或类型用法时可以使用它。
- 它允许JPA注释在元注释中使用
- 它提供了流式查询结果的功能,就能实现分批次查询,避免一次返回数据过大导致OOM,什么是OOM?程序申请内存过大,虚拟机无法满足我们,然后溢出了
JPA 实现简单的CRUD
需要学习JPA,首先需要把环境搭起来,这里选择实现JPA规范的持久层框架是Hibernate,版本为5.0.7.Final,并且采用maven进行依赖包的管理,具体步骤如下:
1、创建Maven项目,这一步比较简单,可以直接在IDE创建。
2、添加hibernate-entitymanager依赖包:使用Hibernate来进行实体的管理,实现实体的CRUD操作,我们只需要引入这个hibernate-entitymanager依赖包即可,其它需要依赖的包将由maven自动引入,这样我们就不用关系具体需要依赖哪些jar包了。当然,junit和数据库驱动也是必不可少的。
①创建一个maven的java工程
pom.xml 依赖:
<dependencies>
<dependency>
<groupId>org.hibernategroupId>
<artifactId>hibernate-entitymanagerartifactId>
<version>5.3.6.Finalversion>
dependency>
<dependency>
<groupId>com.oraclegroupId>
<artifactId>ojdbc14artifactId>
<version>10.2.0.1.0version>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.12version>
dependency>
dependencies>
②创建一个jpa的核心配置文件src/main/resources/ META-INF/persistence.xml
文件名和位置固定
– 需要指定跟哪个数据库进行交互;
– 需要指定 JPA 使用哪个持久化的框架以及配置该框架的基本属性
<persistence version="2.1" xmlns="http://xmlns.jcp.org/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/persistence http://xmlns.jcp.org/xml/ns/persistence/persistence_2_1.xsd">
<persistence-unit name="jpademo" >
persistence-unit>
persistence>
③在jap的核心配置文件的配置三块基本的信息:
<persistence-unit name="jpademo">
<provider>org.hibernate.jpa.HibernatePersistenceProviderprovider>
<properties>
<property name="javax.persistence.jdbc.driver" value="oracle.jdbc.driver.OracleDriver" />
<property name="javax.persistence.jdbc.url" value="jdbc:oracle:thin:@localhost:1521:orcl" />
<property name="javax.persistence.jdbc.user" value="root" />
<property name="javax.persistence.jdbc.password" value="root" />
<property name="hibernate.dialect" value="org.hibernate.dialect.Oracle10gDialect" />
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="hibernate.hbm2ddl.auto" value="update"/>
properties>
persistence-unit>
④创建实体类,并用注解链接实体类和数据表自己的映射关系,这里用注解,但是和前面学过的xml配置都是对应的,没学过,但是应该看的懂
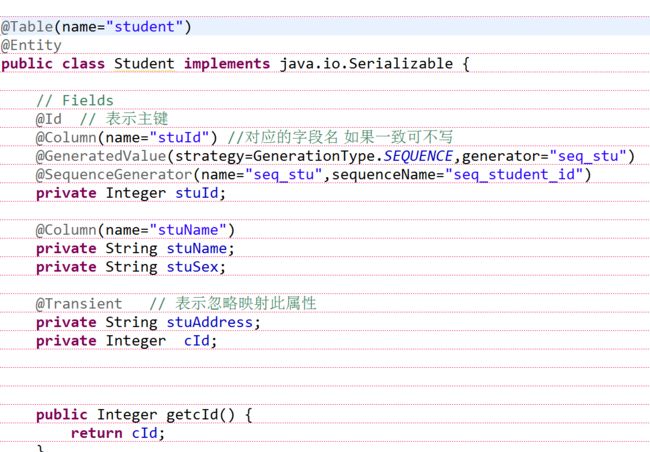
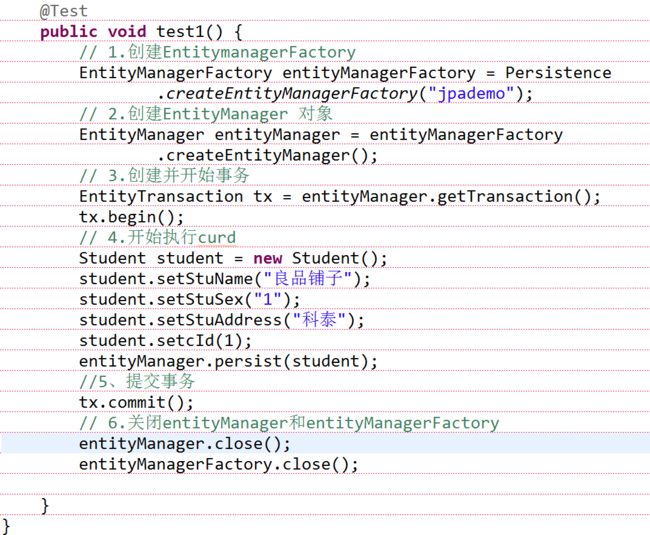
⑤创建单元测试方法做测试
JPA的注解解释
基于hibernate-jpa-2.1-api-1.0.0.Final版本
-
@Entity
@Entity public class Student { @Id private String stuId; //省略getter()和setter() }说明这个类是实体类,并且使用默认的orm规则(类名即表名,类属性名即表字段名)。
如果想改变这种默认的orm规则,就要使用**@Table来改变class名与表名的映射规则**,@Column来改变class中字段名与db中表的字段名的映射规则。
仅使用 @javax.persistence.Entity 和 @javax.persistence.Id 这两个注解,就可以作为一个实体类与数据库中的表相对应。
@Column
@Column(name = "NAME",columnDefinition = "varchar(158) not null")
private String name;
| 属性名 | 释义 | 值 | 默认值 |
|---|---|---|---|
| name | 所对应表字段的名称 | 字符串 | “” |
| unique | 是否为唯一标识(亦可在@Table注解中设置) | 布尔值 | false |
| nullable | 是否可为null值 | 布尔值 | true |
| insertable | 在使用’insert’时,是否插入该字段的值 | 布尔值 | true |
| updatable | 在使用’update’时,是否更新该字段的值 | 布尔值 | true |
| columnDefinition | 通过Entity生成DDL语句 | 字符串 | “” |
| table | 包含当前字段的表名 | 字符串 | “” |
| length | 字段长度(类型仅为varchar时生效) | 正整数或零 | 255 |
| precision | 数值的总长度(类型仅为double时生效) | 正整数或零 | 0 |
| scale | 保留小数点后数值位数(类型仅为double时生效) | 正整数或零 |
提示:此注解可以标注在getter方法或属性前。
@Temporal
@Temporal(TemporalType.TIMESTAMP)
private Date createTime;
默认为TemporalType.TIMESTAMP类型。
TemporalType枚举类型定义如下:
public enum TemporalType {
DATE, //java.sql.Date
TIME, //java.sql.Time
TIMESTAMP //java.sql.Timestamp
}
java.sql.Date、java.sql.Time和java.sql.Timestamp这三种类型不同,它们表示时间的精确度不同。三者的区别如表所示。
| 类型 | 说明 |
|---|---|
| java.sql.Date | 日期型,精确到年月日,例如“2008-08-08” |
| java.sql.Time | 时间型,精确到时分秒,例如“20:00:00” |
| java.sql.Timestamp | 时间戳,精确到纳秒,例如“2008-08-08 20:00:00.000000001” |
@Transient
一旦变量被transient修饰,变量将不再是对象持久化的一部分,该变量内容在序列化后无法获得访问(即:不与表字段映射)。
常用于某属性仅为临时变量时。
@Basic
表示一个简单的属性到数据库表的字段的映射,对于没有任何标注的属性,默认即为 @Basic。
@Basic(fetch = FetchType.LAZY)
@Column(name = "CONTENT")
private String content;
| 属性名 | 释义 | 值 | 默认值 |
|---|---|---|---|
| fetch | 加载方式 | FetchType.EAGER 即时加载 FetchType.LAZY 延迟加载 | FetchType.EAGER |
| optional | 是否可为null | 布尔值 | true |
属性optional表示属性是否可为null,不能用于Java基本数据类型byte、int、short、long、boolean、char、float、double的使用。
对于一些特殊的属性,比如长文本型text、字节流型blob型的数据,在加载Entity时,这些属性对应的数据量比较大,有时创建实体时如果也加载的话,可能严重造成资源的占用。要想解决这些问题,此时就需要设置实体属性的加载方式为延迟加载(LAZY)。
@Table
@Entity
@Table(name="STUDENT")
public class Student {
//省略此处冗余代码
}
当实体类与其映射的数据库表名不同名时需要使用 @Table 标注说明,该标注与 @Entity 标注并列使用。
| 属性名 | 释义 | 值 | 默认值 |
|---|---|---|---|
| name | 指定数据库表名称 若不指定则以实体类名称作为表名 | 字符串 | “” |
| schema | 指定该实体映射的schema | 字符串 | “” |
| catalog | 与schema属性相同 | 字符串 | “” |
| indexes | 索引 | @Index | {} |
| uniqueConstraints | 唯一约束 | @UniqueConstraint |
当实体类名和数据库表名不一致时,name属性可以实现映射,即使表名一致,也推荐使用,提高程序的可读性 。
@Id
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "seq_stu")
@SequenceGenerator(name = "seq_stu", sequenceName = "seq_student_id", initialValue = 2000, allocationSize = 1)
private String id;
标记属性的主键(一个实体中可以出现多个@Id注解,但需要@IdClass配合使用,以表示联合主键)。
@Entity @IdClass(ProjectId.class)
public class Project {
@Id int departmentId;
@Id long projectId;
}
一旦标注了主键,该实体属性的值可以指定,也可以根据一些特定的规则自动生成。
@Id标识数据类型
| 分类 | 类型 |
|---|---|
| Java基本数据类型 | byte、int、short、long、char |
| Java基本数据类型对应的封装类 | Byte、Integer、Short、Long、Character |
| 大数值型类 | java.math.BigInteger |
| 字符串类型 | String |
| 时间日期型 | java.util.Date、java.sql.Date |
double和float浮点类型和它们对应的封装类不能作为主键,这是因为判断是否唯一是通过equals方法来判断的,不能够准确的匹配
@GeneratedValue
标注主键的生成策略
| 属性名 | 释义 | 值 | 默认值 |
|---|---|---|---|
| strategy | 主键的生成策略 | GenerationType.TABLE 通过表产生主键,框架借由表模拟序列产生主键 GenerationType.SEQUENCE 通过序列产生主键(不支持MySql) GenerationType.IDENTITY 自增长(不支持Oracle) GenerationType.AUTO 自动选择合适的策略 | GenerationType.AUTO |
| generator | 自定义生成策略 | 字符串(对应@GenericGenerator注解的name属性值) | “” |
需要注意的是,同一张表中自增列最多只能有一列,GenerationType.SEQUENCE在oracle数据库时使用,配合@SequenceGenerator指定使用哪个序列名
@SequenceGenerator(name="teacherSEQ",sequenceName="teacherSEQ_DB")
@GeneratedValue(strategy=GenerationType.SEQUENCE,generator="teacherSEQ")
<property name="hibernate.dialect">org.hibernate.dialect.Oracle10gDialectproperty>
orcl.user=scott
orcl.password=scott
orcl.driverClass=oracle.jdbc.OracleDriver
orcl.jdbcUrl=jdbc:oracle:thin:@localhost:1521:orcl
<dependency>
<groupId>com.oraclegroupId>
<artifactId>ojdbc6artifactId>
<version>12.1.0.1-atlassian-hostedversion>
dependency>
JPA的api
- 标准API历史
- 在JPA2.0中,标准查询API,查询的标准化开发。
- 在JPA2.1,标准更新和删除(批量更新和删除)都包括在内。
标准查询结构
该标准与JPQL是密切相关的,并允许使用类似的操作符在他们的查询设计。它遵循javax.persistence.criteria包设计一个查询。查询结构指的语法条件查询。
下面简单的条件查询返回数据源中的实体类的所有实例。
EntityManagerFactory entityManagerFactory
= Persistence.createEntityManagerFactory(“jpademo”);
EntityManager entityManager = entityManagerFactory.createEntityManager();
EntityTransaction transaction = entityManager.getTransaction();
transaction.begin();
User user = new User();
user.setAge(11);
user.setEmail(“[email protected]”);
user.setPasword(“pppp”);
user.setUsername(“admin”);
entityManager.persist(user);
transaction.commit();
entityManager.close();
entityManagerFactory.close();
从第一个jpa案例中,我使用到的几个基本的jpa的API类:
①Persistence:主要作用就是通过它的静态方法createEntityManagerFactory获取EntityManagerFactory(相当于Hibernate的SessionFactory)
②EntityManagerFactory :主要作用就是获取****EntityManager **的实例对象,**EntityManager 相当于Hibernate的Session
**③EntityManager操作数据库的方法:**主要作用就是操作数据库,执行增删改查,对应的方法persist(增),find和getReferenc(查一条记录),remove (删),merge(改)
④EntityManager的其他方法:flush()、refresh()和hibernate课程里讲的一样,这里即不赘述了
⑤EntityManager的createQuery(),createNamedQuery(), createNativeQuery()这些方法也和hibernate里的方法非常类似,我们讲jpql查询的时候会具体使用的,到时再讲**
⑥EntityTransaction:jpa里的事务管理,begin(),commit(),rollback()等等常用方法和hibernate里也是一样的

Entity
实体的状态:
1、新建状态: 新创建的对象,尚未拥有持久性主键;
2、持久化状态:已经拥有持久性主键并和持久化建立了上下文环境;
3、游离状态:拥有持久化主键,但是没有与持久化建立上下文环境;
4、删除状态: 拥有持久化主键,已经和持久化建立上下文环境,但是从数据库中删除。
find方法
find (Class entityClass,Object primaryKey):返回指定的 OID 对应的实体类对象。
第一个参数为被查询的实体类类型,第二个参数为待查找实体的主键值。
如果这个实体存在于当前的持久化环境,则返回一个被缓存的对象;否则会创建一个新的 Entity, 并加载数据库中相关信息;若 OID 不存在于数据库中,则返回一个 null。
getReference方法
getReference (Class entityClass,Object primaryKey):与find()方法类似。
不同的是:如果缓存中不存在指定的 Entity, EntityManager 会创建一个 Entity 类的代理,但是不会立即加载数据库中的信息,只有第一次真正使用此 Entity 的属性才加载,所以如果此 OID 在数据库不存在,getReference() 不会返回 null 值, 而是抛出EntityNotFoundException。
persist方法
persist (Object entity):用于将新创建的 Entity 纳入到 EntityManager 的管理。该方法执行后,传入 persist() 方法的 Entity 对象转换成持久化状态。
如果传入 persist() 方法的 Entity 对象已经处于持久化状态,则 persist() 方法什么都不做。
如果对删除状态的 Entity 进行 persist() 操作,会转换为持久化状态。
如果对游离状态的实体执行 persist() 操作,可能会在 persist() 方法抛出 EntityExistException(也有可能是在flush或事务提交后抛出)。
remove方法
remove (Object entity):删除实例。
如果实例是被管理的,即与数据库实体记录关联,则同时会删除关联的数据库记录。
merge方法
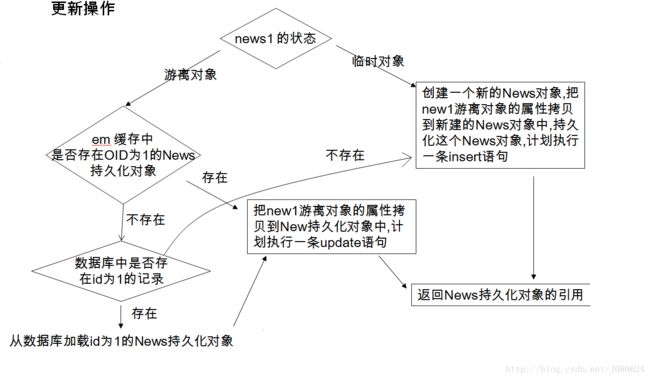
merge (T entity):merge() 用于处理 Entity 的同步。即数据库的插入和更新操作。
原理图如下
flush方法
顾名思义,强制刷新。同步持久上下文环境,即将持久上下文环境的所有未保存实体的状态信息保存到数据库中。
refresh 方法
refresh (Object entity):用数据库实体记录的值更新实体对象的状态,即更新实例的属性值。
即,刷新内存中对象的属性。
clear 方法
clear ():清除持久上下文环境,断开所有关联的实体。如果这时还有未提交的更新则会被撤消。
contains方法
判断一个实例是否属于当前持久上下文环境管理的实体。
isOpen方法
判断当前的实体管理器是否是打开状态。
getTransaction
返回资源层的事务对象。
EntityTransaction实例可以用于开始和提交多个事务。
close 方法
关闭实体管理器。之后若调用实体管理器实例的方法或其派生的查询对象的方法都将抛出 IllegalstateException 异常,除了getTransaction 和 isOpen方法(返回 false)。
不过,当与实体管理器关联的事务处于活动状态时,调用 close 方法后持久上下文将仍处于被管理状态,直到事务完成。
createQuery方法
createQuery (String qlString):创建一个查询对象。
createNamedQuery 方法
createNamedQuery (String name):
根据命名的查询语句块创建查询对象。参数为命名的查询语句。
createNativeQuery (String sqlString):
使用标准 SQL语句创建查询对象。参数为标准SQL语句字符串。
createNativeQuery (String sqls, String resultSetMapping):
使用标准SQL语句创建查询对象,并指定返回结果集 Map的 名称。
jpa里用注解进行关系映射
1. 单向多对一关联

注意:注解@ManyToOne(fetch=FetchType.EAGER)默认的是立即加载,需要懒加载的时候,要加fetch参数修改
可以使用targetEntity属性指定关联实体类型 @ManyToOne(targetEntity=Classes.class)
2. 单向一对多的关联

注意:注解@OneToMany(fetch=FetchType.LAZY)默认的是懒加载,需要懒加载的时候,要加fetch参数修改,使用@JoinColumn(name=“c_id”) 设置关联外键
3.双向的一对多的关联
一的这端:Classes
mappedBy: 设置关联的外键 避免出现中间表和

多的这端:Student

注意:
①双向关联关系,两遍默认都会维护关系,可能冲突,也影响效率,正常情况关系交给“多”的一端维护,一的这端@OneToMany(mappedBy=“classes”,这个属性放弃关系维护
②一旦使用 mappedBy属性,那么@JoinColumn这个注解就不能使用了,用了会出错
4.双向多对多的关联

@JoinTable(name="中间表",
joinColumns={@JoinColumn(name="当前对象在中间表的外键名",referencedColumnName="当前对象表的主键")},
inverseJoinColumns={@JoinColumn(name="关联表在中间表的外键名",referencedColumnName="关联表的主键")})
Student这边维护关系,subject就要放弃关系的维护,使用mappedBy将维护权交给另外一方
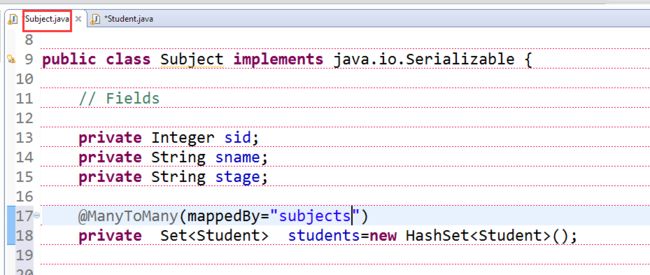
注意:在真项目开发中,我们处理双向多对多的关联,还可以变通来处理,就是将对对多关联,转换为两个一对多的关联
5.双向的一对一的关联

双向关联,一边要放弃关系维护

注意:负责维护关系的一端,要配置唯一约束,因为一对一关联,两边都是唯一的
默认关联策略是:立即查询
jpa的jpql语言
什么是JPQL
在 Java EE 中,JPQL( Java 持久性查询语言)是专门为Java 应用程序访问和导航实体实例设计的。JPQL是EJB2使用的查询语言EJB QL的扩展,它继承了EJB QL并对其做了一些改变。
二、JPQL与SQL
JPQL 和 SQL 有很多相似之处。归根结底,它们都用于访问和操作数据库数据。而且,二者都使用非过程语句 — 通过特殊解释程序识别的命令。此外,JPQL 在语法上与 SQL 也相似。
JPQL 和 SQL 的主要区别在于,前者处理 JPA 实体,后者直接在数据库空间内对表、列、行等关系数据进行处理
三、使用JPQL
要从 Java 代码内发出 JPQL 查询,您需要利用 EntityManager API 和 Query API 的相应方法,执行以下一般步骤:
- 使用注入或通过 EntityManagerFactory 实例获取一个 EntityManager 实例。
- 通过调用相应 EntityManager 的方法(如 createQuery),创建一个 Query 实例。
- 如果有查询参数,使用相应 Query 的 setParameter 方法进行设置。
- 如果需要,使用 setMaxResults 和/或 setFirstResult 方法设置要检索的实例的最大数量和/或指定检索的起始实例位置。
- 如果需要,使用 setHint() 方法设置供应商特定的提示。
- 如果需要,使用 setFlushMode( ) 方法设置查询执行的刷新模式,覆盖实体管理器的刷新模式。
- 执行查询使用相应 Query 的方法 getSingleResult 或 getResultList 。
8、进行更新或删除操作,使用 executeUpdate 方法,它返回已更新或删除的实体实例的数量。
JPQL的查询可以分为命名查询和动态查询。
动态查询
可以使用EntityManager.createQuery方法创建动态查询,唯一的要求是把合法的JPQL语句传递给此方法。如下:
Query query = em.createQuery(“select p from Person p where p.id=1033”);
其中where语句是可选的。在这里JPQL看上去和SQL语句很像,但应当注意到的是from后边的Person是实体Bean而不是数据表。
在所写的JPQL语句中你可以像示例中那样的直接将查询条件写在语句中。但是还有更好的方法。在这里你可以使用设置查询参数的方式,其中又有位置参数和命名参数的分别。
使用位置参数如下所示:
Query query = em.createQuery(“select p from Person p where p.id=?1”);
Query.setParameter(1, 1033);//第一个参数是位置,第二个参数查询条件
使用命名参数如下所示:
Query query = em.createQuery(“select p from Person p where p.id=:id”);
Query.setParameter(“id”, 1033);//第一个参数是参数名称,第二个参数查询条件
需要注意的是位置参数的是位置前加符号”?”,命名参数是名称前是加符号”:”。
如果你需要传递java.util.Date或java.util.Calendar参数进一个参数查询,你需要使用一个特殊的setParameter()方法。因为一个Date或Calendar对象能够描述一个真实的日期、时间或时间戳.所以我们需要告诉Query对象怎么使用这些参数,我们把javax.persistence.TemporalType作为参数传递进setParameter方法,告诉查询接口在转换java.util.Date或java.util.Calendar参数到本地SQL时使用什么数据库类型。
查询结果
使用Query. getSingleResult方法得到查询的单个实例,返回Object。要确保使用此方法时查询只检索到一个实体。
使用Query. getResultList方法得到查询的实例集合,返回List。
通常的,我们会如示例中所示的是获取查询返回的是实体,但是在JPQL里我们也可以得到实体的部分属性,就如同使用SQL得到表中的部分列一样。如果是获取部分属性的话,Query.getResultList方法返回的会是Object数组的List每个Object数组项相当于是一条结果,数组的成员是属性值,顺序和所写的JPQL中的SELECT中所写顺序一致。
查询中使用构造器(Constructor)
可以在SELECT子句中使用构造器返回一个或多个java实例。如下所示:
Query query = em.createQuery(“select new com.demo.bean.Person(p.id, p.name) from Person p order by p.id desc”);
查询分页
JPA提供了在结果集合中使用分页的功能,使用这个功能我们可以轻松的达到对查询结果分页的目的。如下
Query.setMaxResults(10);//设置分页大小,在这里为每页10条记录
Query.setFirstResult(10);//指定第一个结果的位置。这里是指定第11条作为起始结果。
这里只要在setFirstResult中使用动态参数即可方便的对结果进行分页了。
使用操作符
在where子句中我们可以使用一些操作符来进行条件的选择。
NOT操作符
select p from Person p where not(p.id = 1036)
//查询id不是1036的所有人
BETWEEN操作符
select p from Person p where p.age between 20 and 26
//查询年龄在20到26的所有人;上限和下限必须是相同的数据类型
IS NULL操作符
select p from Person p where p.name is not null
//查询名字不为NULL的所有人
IS EMPTY操作符
IS EMPTY是针对集合属性(Collection)的操作符。可以和NOT 一起使用。注:低版权的MySQL 不支持IS EMPTY
select p from Person p where p.interest is empty
//查询兴趣(是集合)是空的所有人
IN 操作符
select p from Person p where p.id in (101,102)
//查询id是101和102的人
EXISTS 操作符
[NOT]EXISTS 需要和子查询配合使用。注:低版权的Mysql 不支持EXISTS
select p from Person p where exists (select b from Book b where b.name like ‘%EJB%’ )
//如果书籍名字中包含有EJB字样,则得到所有人
MEMBER OF操作符
可以使用MEMBER OF操作符检查集合-值路径表达式中是否存在标识符变量、单一值表达式或是输入参数。
select p from Person p where :interest member of p.interest
//查询兴趣(是集合)是中包含所输入的兴趣实体实例(:interest)的所有人
使用字符串函数
JPQL定义了内置函数方便使用。这些函数的使用方法和SQL中相应的函数方法类似。包括:
\1. CONCAT 字符串拼接
\2. SUBSTRING 字符串截取
\3. TRIM 去掉空格
\4. LOWER 转换成小写
\5. UPPER 装换成大写
\6. LENGTH 字符串长度
\7. LOCATE 字符串定位
使用算术函数
JPQL仅仅支持了最低限度的算术函数集合,可以在JPQL的where和having子句中使用算术函数。JPQL定义的算术函数包括:
ABS 绝对值
SQRT 平方根
MOD 取余数
SIZE 取集合的数量
使用时间函数
JPQL像大多数语言一样提供了获得当前日期、时间或是时间标记的函数。这些函数转换为数据库专有的SQL函数,从数据库检索当前日期、时间或时间标记。包含的时间函数如下:
CURRENT_DATE 返回当前日期
CURRENT_TIME 返回当前时间
CURRENT_TIMESTAMP 返回当前时间标记
联结(连接/关联)
JPQL仍然支持和SQL中类似的关联语法:
left out join/left join
left out join/left join等,都是允许符合条件的右边表达式中的Entities 为空(需要显式使用left join/left outer join 的情况会比较少。)
inner join
inner join 要求右边的表达式必须返回Entities。
left join fetch/inner join fetch
在默认的查询中,Entity中的集合属性默认不会被关联,集合属性默认是延迟加载( lazy-load )。那么,left fetch/left out fetch/inner join fetch提供了一种灵活的查询加载方式来提高查询的性能(集合属性被关联,同Entity同时加载而不是在需要时再加载,这样就转换为SQL语句时为一条SQL语句,而不是加载Entity时一条语句,加载集合属性时有N(等于Entity数量)条语句,避免了N+1问题,提高了查询性能)。
使用聚合函数
JPQL提供的聚合函数有AVG、COUNT、MAX、MIN、SUM。在AVG、MAX、MIN、SUM函数中只能使用持久化字段,而在COUNT中可以使用任何类型的路径表达式或标识符。
COUNT返回的类型是Long,AVG是Double,SUM可能返回Long或Double。
分组
如果聚合函数不是select…from的唯一一个返回列,需要使用"GROUP BY"语句。"GROUP BY"应该包含select 语句中除了聚合函数外的所有属性。如果还需要加上查询条件,需要使用"HAVING"条件语句而不是"WHERE"语句
select p.grade, count§ from Person p where p.age > 20 group by p.grade having count(*)>120
//返回年龄大于20的各年级的总人数(人数大于120)
排序
在JPQL中像SQL一样使用order by 来进行排序。"ASC"和"DESC"分别为升序和降序,JPQL中默认为ASC升序。
批删除和批更新
JPQL支持批量删除和批量更新的操作。和查询相同的是也是要使用EntityManager.createQuery方法来创建一个Query实例,不同的是在这里要使用Query.executeUpdate方法来直行删除和更新,该方法返回的值是操作的记录数。
命名查询
可以在实体bean上通过@NamedQuery or @NamedQueries预先定义一个或多个查询语句,减少每次因书写错误而引起的BUG。通常把经常使用的查询语句定义成命名查询。
定义单个命名查询:
@NamedQuery(name=“getPerson”, query= “select p from Person p where p.id=?1”)
@Entity
public class Person implements Serializable{
如果要定义多个命名查询,应在@javax.persistence.NamedQueries里定义@NamedQuery:
@NamedQueries({
@NamedQuery(name=“getPerson”, query= “select p from Person p where p.id=?1”),
@NamedQuery(name=“getPersonList”, query= “select p from Person as p where p.age>?1”)
})
@Entity
public class Person implements Serializable{
当命名查询定义好了之后,我们就可以通过名称执行其查询。代码如下:
Query query = em.createNamedQuery(“getPerson”);
query.setParameter(1, 1);
四、注意
\1. JPQL语句的大小写敏感性:除了Java 类和属性名称外,查询都是大小写不敏感的。
\2. 使用参数查询的时候除了基本类型的参数还可以使用实体参数。
你们下来仔细地把上面的笔记过一遍,基本上和hql的使用没太大的区别,所以我们重点看下面的实例:
①用jpql获取id值小于3的Course信息:

②获取部分字段的数据

和hibernate没什么别,也可以封装成对应的对象,这样javabean里要有对应的构造器

③命名查询@NamedQuery
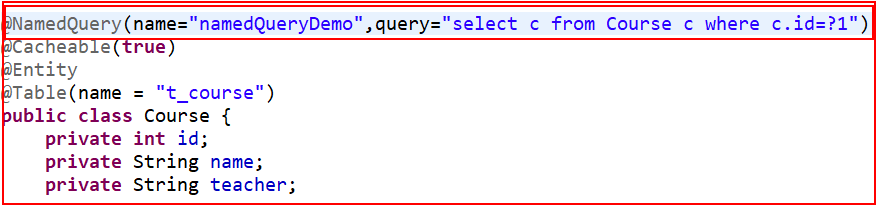
测试:

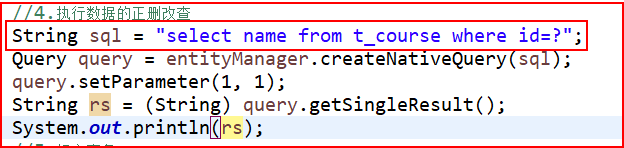
④执行原生的sql语句
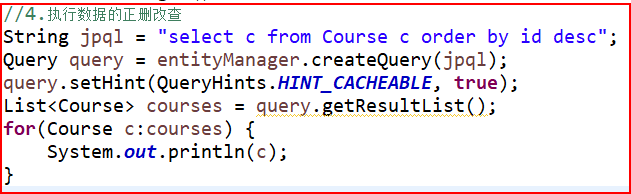
⑤ORDER BY排序查询,按照id降序排列
⑥GROUP BY …HAVING分组查询,查询每个老师有多少个学生

⑦关联查询

⑧子查询和使用函数(这里字符串函数举例)


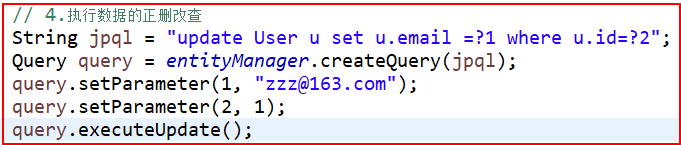
⑨executeUpdate完成修改和删除

jpa的缓存
**这里用我们用的是jpa的hibernate实现,当然肯定是有一级和二级缓存的,**首先来看一级缓存:

**二级缓存:**和Hibernate一样,一级缓存是默认就开启的,不用我们管理,二级缓存默认是关闭的
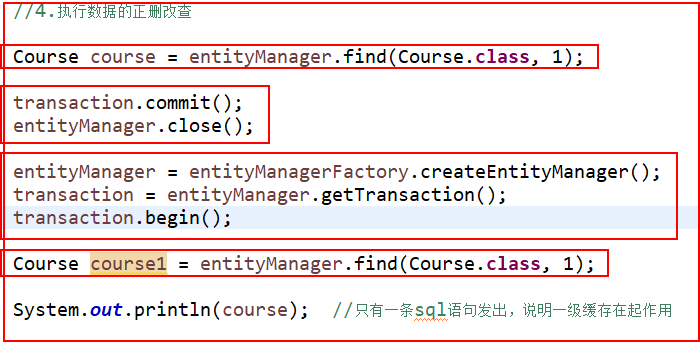
两次查询中间,提交了事务,关闭了EntityManger,一级缓存失效,发出两天sql语句,想要减少访问数据库的次数,就要开启二级缓存,我们像前面讲过的Hibernate一样使用ehcache作为二级缓存,配置步骤:
①配置pom.xml,导入jar包
org.hibernate
hibernate-ehcache
5.2.17.Final
②在jpa的核心配置文件中,配置开启二级缓存,和hibernate课程中讲的配置一样
开启二级缓存
配置二级缓存技术提供者
开启查询缓存
③把ehcache的配置文件ehcache.xml加进来
maxElementsInMemory=“10000” eternal=“false” timeToIdleSeconds=“120” timeToLiveSeconds=“120” overflowToDisk=“true” /> ④在实体类上加开启二级缓存的注解@cacheable(true)和配置文件中properties标签前配置缓存策略: ENABLE_SELECTIVE 相当于前面讲的配置: shared-cached-mode这个标签有5个值: a)ALL:缓存所有实体类 b)NONE:所有实体类都不缓存 **c)**ENABLE-SELECTED:有@cacheable(true)的实体类被缓存 d)DISABLE-SELECTED:除了有**@cacheable(false)这个注解外的所有实体类** e)UNSPECIFIED:默认值,jpa的实现的默认值 最后在来看看,jpa的查询缓存: 配置文件中开启查询缓存: query中开启查询缓存:![]()
