Hadoop 2.7.2 HA 自动切换高可用集群配置详解
1、集群节点规划
| NameNode | node1 | node2 | |
| DataNode | node1 | node2 | node3 |
| JournalNode | node1 | node2 | node3 |
| zookeeper | node1 | node2 | node3 |
node1:172.16.73.143
node2:172.16.73.43
node3:172.16.73.211
1.1 各节点安装软件目录规划:
| JDK 目录 | /opt/package/jdk1.7.0_76 |
| hadoop | /opt/package/hadoop-2.7.2 |
| zookeeper | /opt/package/zookeeper-3.4.10 |
1.2 各节点临时目录规划
| hadoop临时目录 | /opt/data/hadoop_tmp_dir |
| journalNode 临时目录 | /opt/data/journal_tmp_dir |
| zookeeper临时目录 | /opt/package/zookeeper-3.4.10/dataLogDir /opt/package/zookeeper-3.4.10/dataDir |
1.3 相关软件
JDK 1.7.0_76
Hadoop:2.7.2
zookeeper: 3.4.10
2.配置Linux环境
推荐使用root用户登录linux
2.0.1 确保各个节点可以互相ping通
如果使用虚拟,确保是桥接方式,以便虚拟机里各个主机可以ping通
2.0.2 配置hostname
vi /etc/sysconfig/network
HOSTNAME=<主机名>
2.0.3 配置/etc/hosts
需要把集群内各个节点的映射都写进来
172.16.73.143 node1
172.16.73.43 node2
172.16.73.211 node3
例如下面是node3这个节点的/etc/hosts配置,如果集群里有多个节点,每个节点的hosts文件都要列出所有节点的映射关系

2.0.4 关闭防火墙
暂时关闭防火墙
service iptables stop
永久关闭防火墙
chkconfig iptables off
查看防火墙自动运行状态
chkconfig --list|grep iptables
关闭linux 安全策略 selinux
vim /etc/sysconfig/selinux
SELINUX=disabled
2.0.5 配置ssh免密码登录
确保在集群内的所有节点都可以互相免密码登录,并且可以免密码登录到自身
检查ssh服务是否正常运行
service sshd status
openssh-daemon (pid 1850) is running...
以上提示表示正常
如果要实现从主机A上免SSH密码登录到主机B,操作如下
在A上:
产生自己的公钥和私钥
ssh-keygen -t rsa
把自己的私钥放到远程的主机上,有3种方法:
方法1:
ssh-copy-id -i username@hostname
方法2:
ssh-copy-id -i ~/.ssh/id_rsa.pub root@node2
方法3:
ssh-copy-id -i hostname
如果想要实现双向免密码登录操作方法是相同的.
在一些情况下应用程序需要登录到当前自己所在的主机,叫做登录到自身主机,例如当前主机是node2,这样操作
ssh-copy-id -i ~/.ssh/id_rsa.pub node2
2.0.6 安装JDK
jdk 安装在 /opt/package/jdk1.7.0_76
修改/etc/profile,加入以下内容
export JAVA_HOME=/opt/package/jdk1.7.0_76
export HADOOP_HOME=/opt/package/hadoop-2.7.2
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
保存退出后执行
source /etc/profile
2.0.7 同步各个节点的时间
2.1 搭建zookeeper集群
zookeeper在NameNode所在的节点上运行一个FailoverContriler,它会监控NameNode的运行状态,如果一个是active一个是standby没有问题,如果NameNdoe的状态发生了变化,比如宕机zookeeper集群就能感知到这个集群的变化。集群通过FailoverContriler把相应的NameNode的状态改成active,实现自动切换。
2.1.1 解压zookeeper安装包
在node1上解压zookeeper安装包,产生zookeeper-3.4.10目录,把conf/zoo_sample.cfg重命名为zoo.cfg
并且创建两个目录dataDir和dataLogDir
修改配置文件conf/zoo.cfg
(1)
dataDar = /opt/package/zookeeper-3.4.10/dataDir
dataLogDir=/opt/package/zookeeper-3.4.10/dataLogDir
(2)增加以下内容
server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:3888
创建目录mkdir zookeeper/data
写入文件echo 1 >zookeeper/data/myid

2.2 修改Hadoop相关配置文件(hadoop-env.sh、core-site.xml、hdfs-site.xml、slaves)
在在node1上操作
2.2.1 hadoop-env.sh
export JAVA_HOME=/opt/package/jdk1.7.0_76
2.2.2 core-site.xml
fs.defaultFS
hdfs://cluster1
hadoop.tmp.dir
/opt/data/hadoop_tmp_dir
fs.trash.interval
1440
ha.zookeeper.quorum
node1:2181,node2:2181,node3:2181
2.2.3 hdsf-site.xml
dfs.replication
3
dfs.nameservices
cluster1
dfs.ha.nameservice.cluster1
node1,node2
dfs.ha.namenodes.cluster1
node1,node2
dfs.namenode.rpc-address.cluster1.node1
node1:9000
dfs.namenode.http-address.cluster1.node1
node1:50070
dfs.namenode.rpc-address.cluster1.node2
node2:9000
dfs.namenode.http-address.cluster1.node2
node2:50070
dfs.ha.automatic-failover.enabled.cluster1
true
dfs.namenode.shared.edits.dir
qjournal://node1:8485;node2:8485;node3:8485/cluster1
dfs.journalnode.edits.dir
/opt/data/journal_tmp_dir
dfs.ha.fencing.methods
sshfence
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_rsa
dfs.client.failover.proxy.provider.cluster1
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
node1
node2
node3
这个配置文件每一行只能写一个hostname,作为DataNode
2.3 同步部署信息
上面部署的JDK、Zookeeper、Hadoop 都只是在node1上完成的,目前node2、node3上还都没有部署,下面用shell脚本,把部署信息批量复制到Node2、Node3
在node1上新建一个shell脚本
vi deploy.sh
#!/bin/bash
for i in 2 3
do
mkdr /opt/data/hadoop_tmp_dir
mkdir /opt/data/journalnode_tmp_dir
#下面这个命令会把/opt下的所有目录包括子目录和文件复制到node2 node3上面
scp -rq /otp node$i:/opt
done
执行deploy.sh
然后修改node2 ndoe3 上的zookeeper配置文件
node2 的zookeeper配置文件/opt/package/zookeeper-3.4.10/dataDir/myid 把里面的值修改成2
node3 的zookeeper配置文件/opt/package/zookeeper-3.4.10/dataDir/myid 把里面的值修改成3
分别启动node1、node2、node3的zookeeper服务
bin/zkServer.sh start
启动之后,每个节点上都应该有QuorumPeerMain这个进程。
上面的deploy.sh 看来似乎太简单了,其实我们后续还可以对这个脚本进行扩展。在实际工作当中灵活运用shell脚本能带来非常大的便利。
2.4 启动集群
2.4.1 格式化zk集群
在ndoe1上执行 bin/hdfs zkfc -formatZK,格式化之后,会在zookeeper里面创建一个hadoop-ha/cluster1这两个节点,验证一下看看,随便进入node1---node3任何一个节点的zookeeper的bin目录,然后执行./zkCli.sh

2.4.2 启动journalNode节点
在node1 node2 node3上分别执行sbin/hadoop-daemon.sh start journalnode,启动之后每个节点上都应该有JournalNode这个进程
2.4.3 格式化并启动nameNode
在node1上执行
bin/hdfs namenode -format
[root@node1 bin]# ./hdfs namenode -format
17/07/04 11:44:40 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = node1/172.16.73.143
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.7.2
STARTUP_MSG: classpath =
STARTUP_MSG: build = https://git-wip-us.apache.org/repos/asf/hadoop.git -r b165c4fe8a74265c792ce23f546c64604acf0e41; compiled by 'jenkins' on 2016-01-26T00:08Z
STARTUP_MSG: java = 1.7.0_76
************************************************************/
17/07/04 11:44:40 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT]
17/07/04 11:44:40 INFO namenode.NameNode: createNameNode [-format]
17/07/04 11:44:42 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Formatting using clusterid: CID-c5cf000d-0dc4-4391-97c8-8ff8067818a5
17/07/04 11:44:43 INFO namenode.FSNamesystem: No KeyProvider found.
17/07/04 11:44:43 INFO namenode.FSNamesystem: fsLock is fair:true
17/07/04 11:44:43 INFO blockmanagement.DatanodeManager: dfs.block.invalidate.limit=1000
17/07/04 11:44:43 INFO blockmanagement.DatanodeManager: dfs.namenode.datanode.registration.ip-hostname-check=true
17/07/04 11:44:43 INFO blockmanagement.BlockManager: dfs.namenode.startup.delay.block.deletion.sec is set to 000:00:00:00.000
17/07/04 11:44:43 INFO blockmanagement.BlockManager: The block deletion will start around 2017 Jul 04 11:44:43
17/07/04 11:44:43 INFO util.GSet: Computing capacity for map BlocksMap
17/07/04 11:44:43 INFO util.GSet: VM type = 64-bit
17/07/04 11:44:43 INFO util.GSet: 2.0% max memory 966.7 MB = 19.3 MB
17/07/04 11:44:43 INFO util.GSet: capacity = 2^21 = 2097152 entries
17/07/04 11:44:43 INFO blockmanagement.BlockManager: dfs.block.access.token.enable=false
17/07/04 11:44:43 INFO blockmanagement.BlockManager: defaultReplication = 3
17/07/04 11:44:43 INFO blockmanagement.BlockManager: maxReplication = 512
17/07/04 11:44:43 INFO blockmanagement.BlockManager: minReplication = 1
17/07/04 11:44:43 INFO blockmanagement.BlockManager: maxReplicationStreams = 2
17/07/04 11:44:43 INFO blockmanagement.BlockManager: replicationRecheckInterval = 3000
17/07/04 11:44:43 INFO blockmanagement.BlockManager: encryptDataTransfer = false
17/07/04 11:44:43 INFO blockmanagement.BlockManager: maxNumBlocksToLog = 1000
17/07/04 11:44:43 INFO namenode.FSNamesystem: fsOwner = root (auth:SIMPLE)
17/07/04 11:44:43 INFO namenode.FSNamesystem: supergroup = supergroup
17/07/04 11:44:43 INFO namenode.FSNamesystem: isPermissionEnabled = true
17/07/04 11:44:43 INFO namenode.FSNamesystem: Determined nameservice ID: cluster1
17/07/04 11:44:43 INFO namenode.FSNamesystem: HA Enabled: true
17/07/04 11:44:43 INFO namenode.FSNamesystem: Append Enabled: true
17/07/04 11:44:44 INFO util.GSet: Computing capacity for map INodeMap
17/07/04 11:44:44 INFO util.GSet: VM type = 64-bit
17/07/04 11:44:44 INFO util.GSet: 1.0% max memory 966.7 MB = 9.7 MB
17/07/04 11:44:44 INFO util.GSet: capacity = 2^20 = 1048576 entries
17/07/04 11:44:44 INFO namenode.FSDirectory: ACLs enabled? false
17/07/04 11:44:44 INFO namenode.FSDirectory: XAttrs enabled? true
17/07/04 11:44:44 INFO namenode.FSDirectory: Maximum size of an xattr: 16384
17/07/04 11:44:44 INFO namenode.NameNode: Caching file names occuring more than 10 times
17/07/04 11:44:44 INFO util.GSet: Computing capacity for map cachedBlocks
17/07/04 11:44:44 INFO util.GSet: VM type = 64-bit
17/07/04 11:44:44 INFO util.GSet: 0.25% max memory 966.7 MB = 2.4 MB
17/07/04 11:44:44 INFO util.GSet: capacity = 2^18 = 262144 entries
17/07/04 11:44:44 INFO namenode.FSNamesystem: dfs.namenode.safemode.threshold-pct = 0.9990000128746033
17/07/04 11:44:44 INFO namenode.FSNamesystem: dfs.namenode.safemode.min.datanodes = 0
17/07/04 11:44:44 INFO namenode.FSNamesystem: dfs.namenode.safemode.extension = 30000
17/07/04 11:44:44 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.window.num.buckets = 10
17/07/04 11:44:44 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.num.users = 10
17/07/04 11:44:44 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.windows.minutes = 1,5,25
17/07/04 11:44:44 INFO namenode.FSNamesystem: Retry cache on namenode is enabled
17/07/04 11:44:44 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis
17/07/04 11:44:44 INFO util.GSet: Computing capacity for map NameNodeRetryCache
17/07/04 11:44:44 INFO util.GSet: VM type = 64-bit
17/07/04 11:44:44 INFO util.GSet: 0.029999999329447746% max memory 966.7 MB = 297.0 KB
17/07/04 11:44:44 INFO util.GSet: capacity = 2^15 = 32768 entries
17/07/04 11:44:46 INFO namenode.FSImage: Allocated new BlockPoolId: BP-456015986-172.16.73.143-1499139886625
17/07/04 11:44:46 INFO common.Storage: Storage directory /opt/data/hadoop_tmp_dir/dfs/name has been successfully formatted.
17/07/04 11:44:47 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
17/07/04 11:44:47 INFO util.ExitUtil: Exiting with status 0
17/07/04 11:44:47 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at node1/172.16.73.143
************************************************************/
[root@node1 bin]#
执行tree /opt/data查看这个目录树的机构
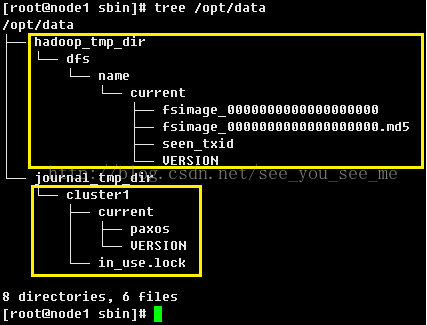 、
、
黄色方框内的内容都是格式化之后创建的
启动node1上的NameNode
sbin/hadoop-daemon.sh start namenode
执行之后通过jps查看会有一个NameNode节点在运行
在node2上执行:
bin/hdfs namenode -bootstrapStandby
[root@node2 bin]# ./hdfs namenode -bootstrapStandby
17/07/04 18:14:59 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = node2/172.16.73.43
STARTUP_MSG: args = [-bootstrapStandby]
STARTUP_MSG: version = 2.7.2
STARTUP_MSG: classpath = 略
STARTUP_MSG: build = https://git-wip-us.apache.org/repos/asf/hadoop.git -r b165c4fe8a74265c792ce23f546c64604acf0e41; compiled by 'jenkins' on 2016-01-26T00:08Z
STARTUP_MSG: java = 1.7.0_76
************************************************************/
17/07/04 18:14:59 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT]
17/07/04 18:14:59 INFO namenode.NameNode: createNameNode [-bootstrapStandby]
17/07/04 18:15:01 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
=====================================================
About to bootstrap Standby ID node2 from:
Nameservice ID: cluster1
Other Namenode ID: node1
Other NN's HTTP address: http://node1:50070
Other NN's IPC address: node1/172.16.73.143:9000
Namespace ID: 1521343093
Block pool ID: BP-456015986-172.16.73.143-1499139886625
Cluster ID: CID-c5cf000d-0dc4-4391-97c8-8ff8067818a5
Layout version: -63
isUpgradeFinalized: true
=====================================================
17/07/04 18:15:03 INFO common.Storage: Storage directory /opt/data/hadoop_tmp_dir/dfs/name has been successfully formatted.
17/07/04 18:15:05 INFO namenode.TransferFsImage: Opening connection to http://node1:50070/imagetransfer?getimage=1&txid=0&storageInfo=-63:1521343093:0:CID-c5cf000d-0dc4-4391-97c8-8ff8067818a5
17/07/04 18:15:05 INFO namenode.TransferFsImage: Image Transfer timeout configured to 60000 milliseconds
17/07/04 18:15:05 INFO namenode.TransferFsImage: Transfer took 0.01s at 0.00 KB/s
17/07/04 18:15:05 INFO namenode.TransferFsImage: Downloaded file fsimage.ckpt_0000000000000000000 size 351 bytes.
17/07/04 18:15:05 INFO util.ExitUtil: Exiting with status 0
17/07/04 18:15:05 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at node2/172.16.73.43
************************************************************/
[root@node2 bin]#
我们看看执行这个之后在node2上产生了什么
[root@node2 bin]# tree /opt/data
/opt/data
├── hadoop_tmp_dir
│ └── dfs
│ └── name
│ └── current
│ ├── fsimage_0000000000000000000
│ ├── fsimage_0000000000000000000.md5
│ ├── seen_txid
│ └── VERSION
└── journal_tmp_dir
└── cluster1
├── current
│ ├── paxos
│ └── VERSION
└── in_use.lock
8 directories, 6 files
[root@node2 bin]#
/opt/data/journal_tmp_dir/cluster1
这两个新目录及其下面的文件是新产生的。
然后启动node2上的NameNode
sbin/hadoop-daemon.sh start namenode
启动节点后用jps查看会发现新增加了一个NameNode进程
[root@node2 sbin]# jps
25051 QuorumPeerMain
25964 Jps
25922 NameNode
25570 JournalNode
[root@node2 sbin]#
node1 ndoe2上都应该有NameNode进程存在。
2.4.4 启动DataNode
在node1上执行
sbin/hadoop-daemons.sh start datanode
这个是启动整个集群中的所有datanode,注意这里用的是hadoop-daemons.sh这个启动脚本。
[root@node1 sbin]# ./hadoop-daemons.sh start datanode
node1: starting datanode, logging to /opt/package/hadoop-2.7.2/logs/hadoop-root-datanode-node1.out
node2: starting datanode, logging to /opt/package/hadoop-2.7.2/logs/hadoop-root-datanode-node2.out
node3: starting datanode, logging to /opt/package/hadoop-2.7.2/logs/hadoop-root-datanode-node3.out
[root@node1 sbin]#
2.4.5 启动zkfc
在有NameNode的节点上(node1 node2)启动上启动zkFc,执行
sbin/hadoop-daemon.sh start zkf
启动后应该有DFSZKFailoverController进程存在
OK ,到目前为止,所有的服务完全启动完毕
各个节点上的进程如下
======================node1=============================
4034 DataNode
3749 NameNode
2466 QuorumPeerMain
4216 DFSZKFailoverController
3029 JournalNode
======================node2=============================
25051 QuorumPeerMain
26053 DataNode
26229 DFSZKFailoverController
25922 NameNode
25570 JournalNode
======================node3=============================
30422 DataNode
29691 QuorumPeerMain
29868 JournalNode
可以看到在node1和node2上都有NameNode、JournalNode 这个是JournalNode集群的相关服务,用来实现当某一个NameNode宕机之后自动切换到另一个备用的NameNode
3.测试
通过下面的URL来查看这个自动切换的HA集群上的两个NameNode的情况,其中必然有一个是active,一个是standby
172.16.73.143 node1
172.16.73.43 node2
50070是NameNode的WEB管理端口,通过这个端口可以用HTTP协议访问NameNode,查看各种重要的关键信息。
http://172.16.73.143:50070
http://172.16.73.43:50070
因为使用JournalNode集群来实现HA,所以集群内的NameNode节点个数必须是2个
下面是node1的情况,同时也列出了3个DataNode的情况,可以发现node1是active状态

node2:
node2是standby状态。
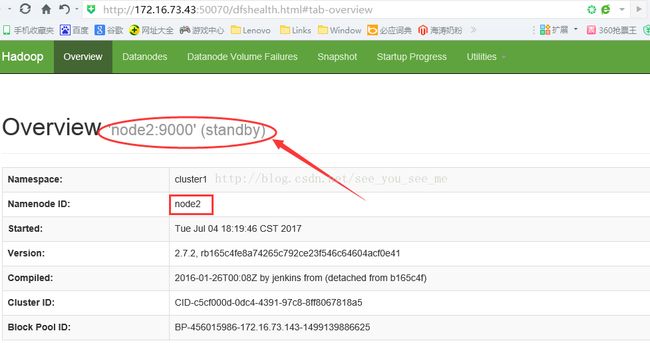
当我们把node1上的NameNode停止之后,看看Node2的情况:

可以发现node2很快切换成active状态,此时启动node1上的namenode,然后查看状态,发现Node1已经是standby状态。完美的解决了Hadoop的单点故障问题。
4 HA 自动切换高可用集群的启动和停止
经过前面若干步骤的安装之后,HA自动切换高可用集群已经完整的搭建起来了,当需要停止和再次启动是什么样的顺序呢?
4.1 启动集群
4.1.1 终止zkfc
在node1、node2上执行 hadoop-daemon.sh stop zkfc
4.1.2 终止datanode
在node1上执行 hadoop-daemons.sh stop datanode
4.1.3 终止namenode
在node1、node2上执行 hadoop-daemon.sh stop namenode
4.1.4 终止journalNode
在node1、node2上执行 hadoop-daemon.sh stop journalnode
4.1.5 终止zk集群
./zkServer.sh stop
4.2 停止集群
4.2.1 启动zkServer集群
在node1、node2、node3上,分别执行bin/zkServer.sh start
启动后会有QuorumPeerMain的进程
4.2.2 启动JournalNode集群
在node1 node2 node3上分别执行sbin/hadoop-daemon.sh start journalnode
启动后会有JournalNode进程
4.2.3 启动NameNode
在node1 node2上分别执行hadoop-daemon.sh start namenode
启动后会有NameNode进程
4.2.4 启动DataNode
在node1或node2上执行hadoop-daemons.sh start datanode
启动后node1 node2 node3 上会有DataNode进程
4.2.5 启动zkfc
在node1 node2上执行hadoop-daemon.sh start zkfc
启动后会有DFSZKFailoverController进程
上面的这些启动和停止的操作看起来就让人头晕,其实我们可以借助shell脚本来方便的处理。敬请期待