迈出数据分析与机器学习的第一步
数据分析机器学习-牛刀小试

数据分析太火爆,怎奈机器学习太难懂!随着人工智能的浪潮卷卷袭来,机器学习已经越来越火爆啦。数据分析与机器学习岗位可谓供不应求,但是入门的门槛也是蛮高的,究竟了机器学习太难学还是咱们木有挑选到趁手的兵器呢?今天咱们的任务就是尝试用Python去开启一场数据分析和机器学习建模之旅,用最简单的方式带大家迈出机器学习的第一步!
机器学习:数据分析很好理解,就是挖掘出来我们需要的有价值的信息,那么机器学习又是什么呢?刚接触这个领域的同学可能有些迷茫,这个词看起来蛮高端的,我就来通俗的解释一下,机器学习也就是我们要让机器(咱们的电脑)在历史的数据中去学习到一些数据分布的规则然后应用到新的数据中,这样新的数据来了我们就可以做一系列任务啦,比如银行根据历史数据得出来什么样的人我会借给他多少钱,那么一个新来的同学来借钱,银行就会得出一个明确值,借给他多少钱!机器学习的应用已经涉及到我们生活中的各个角落啦,随着人工智能业的发展,相信机器学习的力量会使得我们生活的环境更上一层楼!
故事背景:今天要讲的故事是咱们家喻户晓的泰坦尼克号,那么咱们是要来回顾一下jack和rose的经典动作吗?这些只是咱们故事的开始,我们要做一件非常有意思的事情,去预测一下泰坦尼克号中,哪些成员能获救。

挑选兵器:任务已经明确下达,接下来的目的就是挑选几个合适的兵器去进行预测的工作啦,咱们的主线是使用Python,因为在数据分析与机器学习界Python已经成为一哥啦!首先介绍下咱们的兵器谱!
Numpy-科学计算库 主要用来做矩阵运算,什么?你不知道哪里会用到矩阵,那么这样想吧,咱们的数据就是行(样本)和列(特征)组成的,那么数据本身不就是一个矩阵嘛。
Pandas-数据分析处理库 很多小伙伴都在说用python处理数据很容易,那么容易在哪呢?其实有了pandas很复杂的操作我们也可以一行代码去解决掉!
Matplotlib-可视化库 无论是分析还是建模,光靠好记性可不行,很有必要把结果和过程可视化的展示出来。
Scikit-Learn-机器学习库 非常实用的机器学习算法库,这里面包含了基本你觉得你能用上所有机器学习算法啦。但还远不止如此,还有很多预处理和评估的模块等你来挖掘的!
数据简介:拿上这些趁手的兵器,我们赶紧干活吧,首先来看一下咱们的数据是长什么样子的!接下来我们就用这些武器来应对问题!
import pandas #ipython notebook
titanic = pandas.read_csv("titanic_train.csv")
titanic.head(5)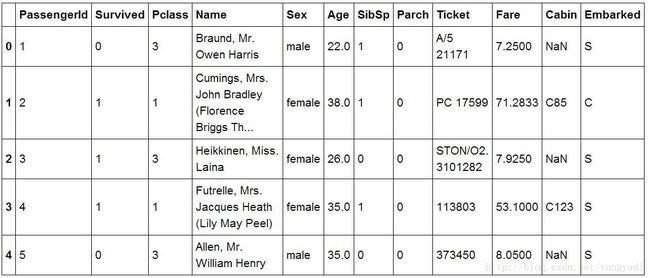
Pandas首先登场,我们用它来进行数据处理和分析是灰常方便的,首先读取了.csv文件,又显示了它的前5行数据。来简单介绍一下数据中每一列都是什么意思。
PassengerId:一个乘客的ID号,这对我们来说好像没啥大用呢,获不获救跟ID貌似没啥大关系,暂且不用它!
Survived:这个就很重要了,它就是咱们的标签(LABEL)标志着这个人到底是获救了,还是没获救。
Pclass:乘客的船舱等级,是贵族还是平民呢?有3个船舱的等级。
Name:乘客的姓名,老外的名字真长啊~
Sex:只有二种~
Age:各个年龄段的都有的
SibSp:与该船员一起登船的兄弟姐妹个数
Parch:老人和孩子个数
Ticket:船票~貌似咱们用不上这个编码
Fare:船票的价格,贵族票还是蛮贵的
Cabin:太多的缺失值了,直接给它pass掉不用了
Embarked:登船的码头,只有3个地点
titanic["Age"] = titanic["Age"].fillna(titanic["Age"].median())
print titanic.describe()
观察可以发现,对于Age这一列来说,只有714个值,而其他列都是891个值,这说明了什么呢?粗大事了,有缺失值,那怎么办呢?这可以用很多种方法啦,用均值,众数,中位数都可以进行填充嘛。在这里我们使用中位数来对缺失值进行了填充。这个不是个别现象,对于一份真实的数据来说,缺失值是灰常常见的现象!
print titanic["Sex"].unique()
# Replace all the occurences of male with the number 0.
titanic.loc[titanic["Sex"] == "male", "Sex"] = 0
titanic.loc[titanic["Sex"] == "female", "Sex"] = 1
['male' 'female']再观察一下数据,数据中很多列的属性值都是字符型的,这对我们有什么影响呢?咱们人类可以认识这些male和female但是计算机就不认识啦,它只认识数值,所以我们需要把字符值转换成数值类型的。
from sklearn import cross_validation
from sklearn.linear_model import LogisticRegression
# Initialize our algorithm
alg = LogisticRegression(random_state=1)
# Compute the accuracy score for all the cross validation folds. (much simpler than what we did before!)
scores = cross_validation.cross_val_score(alg, titanic[predictors], titanic["Survived"], cv=3)
# Take the mean of the scores (because we have one for each fold)
print(scores.mean())核武器登场啦,使用scikit-learn可以轻松建议一个机器学习模型,这里我们使用逻辑回归(经典的二分类)完成这个案例,首先还是先来介绍下逻辑回归是什么吧! 
假设现在有两个特征,工资和年龄。我们要根据这两个指标来预测一下银行会借给这个人多少钱。那么我们就可以建立出来这样一个方程式!也就是说要找到最合适的一组参数使得我们最终预测的值和真实值越接近越好!但是我们现在要做的是一个分类任务呀!也就是说要得到一个类别值究竟是获救了还是没获救,那么还需要往下再走一步。 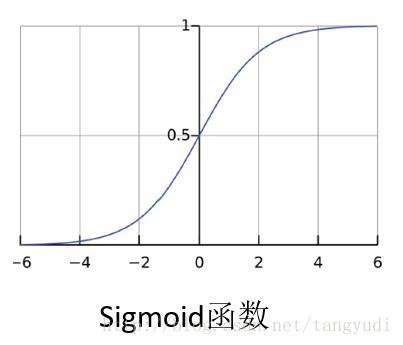
这个函数可厉害了,我们来观察一下,首先这个sigmoid函数的自变量取值范围是负无穷到正无穷的,值域是在0到1区间上,那么也就是说任何一个数值进入sigmoid函数之后都会得到一个(0,1)区间上的值,相当于是一个概率值了,那么我们就可以设置这样一个阈值。比如一个概率值>0.5我们把它当成1这个类别(获救啦),概率值<0.5我们把它当成0这个类别(很遗憾~)。在木有调节任何参数的情况下精度已经接近百分之八十啦!
模型评估:刚才咱们说了一下模型的精度,也就是指预测的结果和真实值之间有多少个是一致的,然后除以样本的总个数。精度可不是唯一的衡量标准,在机器学习的世界,我们有很多的标准,比如我们要进行一个检测的任务,目的是检测出所有病人中患癌症的是哪几个,这回就不能只用精度了而要考虑最终的目标-检测到癌症病人,这回可以使用召回率(RECALL)来完成这个任务,也就是检测到癌症病人个数除以癌症病人总个数,并不去计算正常病人我有木有检测到,因为这并不是我的目标!
特征选择:现在我们要好好想一想啦,我们最终的预测结果的准确程度和什么有关呢?一方面是我们选择的机器学习模型另一方面还有我们输入的特征数据呀,所以我们还得动动脑筋什么样的特征更适合预测呢。脑洞大开时间到啦,这回我们把一个成员的家庭数量也统计了出来,就是兄弟姐妹+老人孩子,还有名字的长度(玄学)以及称谓Mr,Miss,Master等。加入这些的目的就是让我们的特征更丰富一些,要想模型建立的好,特征的选择很关键,在起步阶段我们需要尽可能多的提供有价值的特征。
建立好模型还木有结束呀,对于一个分析任务来说,我们也需要知道这些特征对最后的结果产生了怎样的影响,例如是性别对结果影响比较大还是年龄呢?这回我们也可以通过预测的结果和真实值之间进行对比来分析一不同特征的重要程度!下图中可以分析得出不同特征的重要程度的差异还是蛮大的,我们还可以进行取舍以及进一步分析啦!
使用Matplotlib来画一个最简单的条形图,只需指定条形位置以及柱的高度即可,要进行可视化展示我们得长和它打交道啦!
plt.bar(range(len(predictors)), scores)
plt.xticks(range(len(predictors)), predictors, rotation='vertical')
plt.show()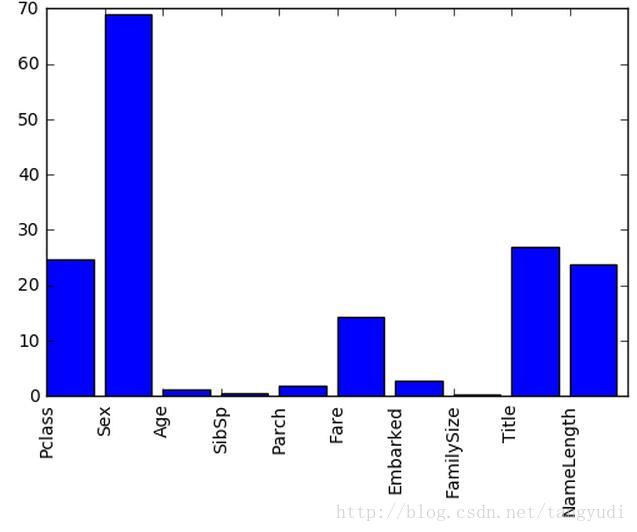
这样咱们完成了一个灰常简单的预测任务,首先通过数据预处理把我们的数据做的纯净一些,然后把这些字符值转换成机器认识的数值,接下来让机器通过这批历史数据去学习一下什么样的参数能够最好的拟合咱们的数据,建立完模型后还需要不断的反思如何调节参数能够使得模型的效果更好以及给出一个合理的评估方法,最终输出来一个预测结果就完成这个机器学习的任务啦!