分布式事务精华总结篇
- 总述 -
咱们前面分别对分布式事务的几个分支:XA、2PC、3PC、TCC、Saga、事务消息、最大努力事务进行的详细介绍。本篇作为分布式事务设计的收尾篇,讲对前面的内容查缺补漏和总结,最后对市面的一些开源框架做一些介绍。

- 查缺补漏 -
1. 补偿型事务
柔性事务分补偿型事务和通知型事务。但对补偿型事务没有进行详细介绍,那什么是补偿型事务呢,在Atomikos 公司Guy Pardon的论文《Business_Activities》中有这样的描述:
大致含义是,"补偿是一个独立的支持ACID特性的本地事务,用于在逻辑上取消了先前ACID交互的影响。对于一个长事务来说,基于补偿的方法可将事务资源锁定时间保持在最低程度,从而避免了事务资源长期占用等缺点。”。
2.TCC事务模型补充
咱们前面文章说了不推荐TCC,并且认为Seata的AT模式从理论上来说更像是Saga的变种,而非TCC的变种。目前有很多资料自行将TCC分了几个分支:
-
通用型TCC:标准TCC模型实现,从业务服务需要提供try、confirm、cancel
-
补偿性TCC:子服务只需要提供 Do 和 Compensate 两个接口
-
异步确保型 TCC:主服务是可靠消息服务,而子服务则通过消息服务解耦,作为消息服务的消费端,异步地执行。可靠消息服务需要提供 Try、Confirm、Cancel 三个接口。Try 接口只负责持久化记录存储消息数据;Confirm 接口确认发送,这时才开始真正的投递消息;Cancel 接口取消发送,删除消息数据。
原始论文《Life beyond Distributed Transactions》和 Atomikos 官网上并没有类似的划分,这些划分其实是一些公司在内部实践中,自行提出的概念。但是并未找到比较大的公司进行背书。所以其实咱们从论文上去看:
-
补偿性TCC并未提供Try接口,其实已经更接近Saga了,反而应该认为是Saga的变种。
-
异步确保型 TCC中 子服务不需要提供try、confirm、cancel三个接口,称为TCC貌似也不合适,从本质上其实事务消息的一种可靠投递方式而已。
3. Saga 事务模型补充
咱们说过Saga设计必须遵循允许空补偿、保持幂等性、防止资源悬挂三个策略,因为Saga事务不保证隔离性,在极端情况下可能由于脏写无法完成回滚操作。比如举一个极端的例子, 分布式事务内先给用户A充值, 然后给用户B扣减余额, 如果在给A用户充值成功, 在事务提交以前, A用户把余额消费掉了, 如果事务发生回滚, 这时则没有办法进行补偿了。这就是缺乏隔离性造成的典型的问题, 实践中一般的应对方法是:
-
业务流程设计时遵循“宁可长款, 不可短款”的原则, 长款意思是客户少了钱机构多了钱, 以机构信誉可以给客户退款, 反之则是短款, 少的钱可能追不回来了。所以在业务流程设计上一定是先扣款。
-
有些业务场景可以允许让业务最终成功, 在回滚不了的情况下可以继续重试完成后面的流程, 所以要求Saga除了提供“回滚”能力还需要提供“向前”恢复上下文继续执行的能力, 让业务最终执行成功, 达到最终一致性的目的。
Saga 实现分两种,一种是Saga 状态机实现,一种是Saga AOP Proxy实现,但是前文缺少对比,补充如下:

Saga 状态机实现,在关于参与者服务编排实现又有集中式和协同式两种分支,他们的对比详情如下:
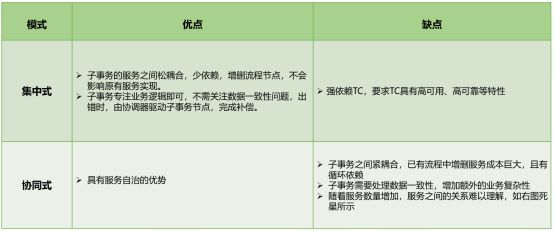 4.TCC VS Saga
4.TCC VS Saga
补偿型事务事务主要分TCC 和 Saga。咱们前文中说到Saga 没有Try行为,直接commit,所以会留下原始事务操作痕迹。TCC Cancel是完美补偿的Rollback,补偿操作会彻底清理之前的原始事务操作,用户是感知不到事务取消之前的状态信息的。最近回看文章时,发现比较多人对此有疑问,所以进行补充诠释下:
-
从业务流程上说,TCC的Try行为是尝试阶段, Comfirm 和Cannel是确认/回滚。是两阶段的广义实现,在页面表现上可以使用定时回查结果,那么对客户的说就是完美补偿行为。而Saga直接commit,在业务流程上存在的客户感官上的脏读现象。
-
在数据层面上来说,TCC利用了数据的中间态,Cannel针对中间台数据进行回滚,从而不存在数据污染问题;而Saga使用的是反向操作,存在数据变化记录影响,有数据污染嫌疑。
TCC 和Saga 的对比 补充一个适用场景的相关对比信息:
-
TCC 适用于执行时间确定且较短、对一致性要求比较高、数据隔离强的业务,比如支付场景。
-
Saga 适用于业务流程长、业务流程多的业务,在银行业金融机构使用广泛。比如互联网微贷、渠道整合场景
- 总结 -
单数据库事务可以满足事务ACID 四个特性,提供强一致性保证,但在分布式事务要完全遵循 ACID 特性会比较困难。在互联网时代中,我们通常追求分布式系统的高可用和高吞吐,所以分布式事务一般选择最终一致性。
咱们把提供强一致性的事务称之为刚性事务,把提供最终一致性的事务称之为柔性事务。刚性事务可以完全满足 ACID 四个特性,柔性事务对事务的 ACID 特性的支持情况如下:
-
原子性:完全支持。
-
一致性:只提供最终一致性支持。
-
隔离性:不完全保证,通常为了系统的吞吐和性能,会一定程度上放弃对隔离性的要求。
-
持久性:完全支持。
在分布式系统中,CAP理论通常是指导思维,而BASE理论是CAP理论中的AP延申,是对 CAP 中的一致性和可用性进行一个权衡的结果,理论的核心思想就是:我们无法做到强一致,但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性。而柔性事务其实就是BASE理论的实践产物。
因为分布式事务难免会对系统造成一定的性能损耗,所以在互联网高可用和高吞吐的要求下。我们通常处理分布式事务的原则是:业务规避 > BASE柔性事务 > CP刚性事务。柔性事务通常推荐 同步Saga、异步事务消息;刚性事务推荐 2PC实现。
- 开源框架推荐 -
从结论上我们可以看出业务规避其实已经没有了分布式事务的必要性,因此如果实在无法业务规避或者规避成本更加昂贵下,我们必须有分布式事务来处理数据一致性问题。这时我们需要选择一个合适的分布式框架来处理事务。我对业界常见分布式事务做了一定比较,其实有大厂背景背书、经过大量生产实践、开源组件的只有华为的ServiceComb Saga、阿里的Seata、Apache Camel Saga。但是华为ServiceComb Saga和 Apache Camel Saga只提供了Saga实现,而阿里Seata提供了AT、Saga、XA(刚出不久,不建议马上使用)。从广度上来说,其实Seata是占比较大的优势,我刚好对Seata又有比较深的研究,所以强烈推荐Seata。