开源物联网平台KAA 中文翻译文档(三)Architecture overview
Architecture overview
- Kaa cluster
- Control service
- Operations service
- Bootstrap service
- Third-party components
- Zookeeper
- SQL database
- NoSQL database
- Internode communications
- High availability and scalability
- Active load balancing
- Endpoint SDK requests
- REST API requests
- Kaa instance
- Further reading
This section discusses fundamental concepts behind Kaa architecture and logical design.
Kaa IoT platform consists of Kaa server, Kaa extensions, and the endpoint SDKs.
- Kaa server is the back-end part of the platform.It is used to manage tenants, applications, users and devices.Kaa server exposes integration interfaces and offers administrative capabilities.
-
Kaa extensions are independent software modules that improve the platform functionality.
NOTE: In this version of the documentation, you will notice that some extensions are actually managed within the core of the platform.Those are planned to be fully decoupled in future Kaa releases.
- Endpoint SDK is a library that provides client-side APIs for various Kaa platform features and handles communication, data marshalling, persistence, etc.Kaa SDKs are designed to facilitate the creation of client applications to be run on various connected devices.However, client applications that do not use Kaa endpoint SDK are also possible.There are several endpoint SDK types available in different programming languages.
Kaa cluster
Kaa server nodes use Apache ZooKeeper to coordinate services.Interconnected nodes make up a Kaa cluster associated with a particular Kaa instance.Kaa cluster requires NoSQL and SQL database instances to store endpoint data and metadata, accordingly.
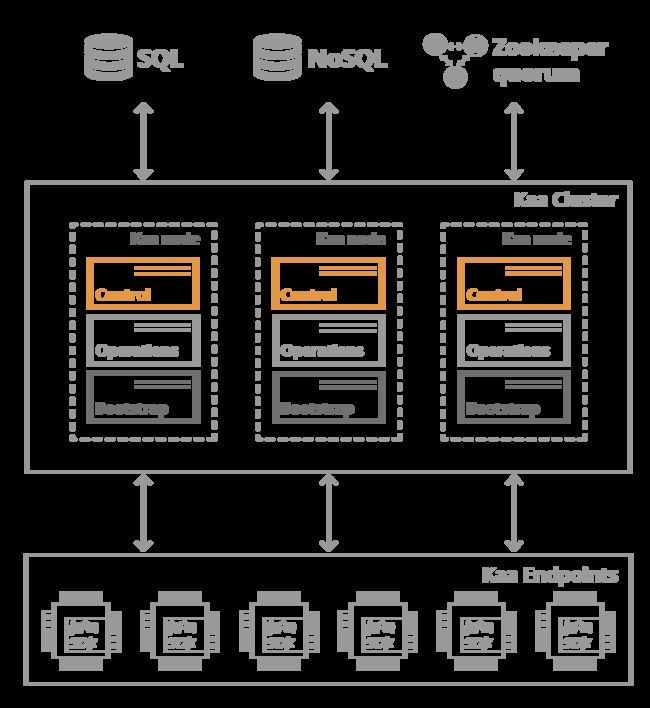
Kaa nodes in a cluster run a combination of Control, Operations, and Bootstrap services.
Control service
Kaa Control service manages overall system data, processes API calls from the web UI and external integrated systems, and sends notifications to Operations services.Control service maintains an up-to-date list of available Operations services by continuously receiving this information from ZooKeeper.Additionally, Control service runs embedded Administrative web UI component that uses Control service APIs to provide platform users with a convenientweb-based interface for managing tenants, user accounts, applications, application data, etc.
To support high availability (HA), a Kaa cluster must include at least two nodes with Control service enabled.In HA mode, one of the Control services acts as active and the other(s) function in standby mode.In case of the active Control service failure, ZooKeeper notifies one of the standby Control service and promotes it to the active Control service.
Operations service
The primary role of the Operations service is to communicate with multiple endpoints concurrently.Operations services process the endpoint requests and sends data to them.
For the purpose of horizontal scaling, you can set up a Kaa cluster with Operations service enabled for every node.In this case, all instances of Operations service will function concurrently.In case of an Operations service outage, previously connected endpoints switch to other available Operations services automatically.Kaa server can re-balance the load at run time, thus effectively routing endpoints to the less loaded nodes in the cluster.
Bootstrap service
Kaa Bootstrap service sends the information to the endpoints about Operations services connection parameters.Depending on the configured protocol stack, connection parameters may include IP address, TCP port, security credentials, etc.Kaa SDKs contain a pre-generated list of Bootstrap services available in the Kaa cluster that was used to generate the SDK library.Endpoints query Bootstrap services from this list to retrieve connection parameters for the currently available Operations services.Bootstrap services maintain their lists of available Operations services by coordinating with ZooKeeper.
Third-party components
Zookeeper
Apache ZooKeeper enables highly reliable distributed coordination of Kaa cluster nodes.Each Kaa node continuously pushes information about connection parameters, enabled services and the corresponding services load.Other Kaa nodes use this information to get the list of their siblings and communicate with them.Active Control service uses the information about available Bootstrap services and their connection parameters during the SDK generation.
SQL database
SQL database instance is used to store tenants, applications, endpoint groups and other metadata that does not grow as the number of endpoints increases.
High availability of a Kaa cluster is achieved by deploying the SQL database in HA mode.Kaa officially supports MariaDB and PostgreSQL as the embedded SQL databases at the moment.
NoSQL database
NoSQL database instance is used to store endpoint-related data that grows linearly as the number of endpoints increases.
NoSQL database nodes can be co-located with Kaa nodes on the same physical or virtual machines, and should be deployed in HA mode for the overallhigh availability of the system.Kaa officially supports Apache Cassandra and MongoDB as the embedded NoSQL database at the moment.
Internode communications
Kaa services use Apache Thirft to communicate across processes and nodes.Each service obtains metadata about its siblings using Apache ZooKeeper.This metadata contains information about the Thrift host and port.
High availability and scalability
Kaa cluster scales horizontally and linearly; there is no single point of failure in Kaa cluster architecture.Kaa Operations and Bootstrap services are identical and function in active-active HA mode.One of the cluster nodes contains an active Control service.In case that node fails, a standby Control service in another node is promoted to become active.High availability of Kaa Cluster also depends on HA of SQL and NoSQL databases.
Active load balancing
Kaa SDK chooses Bootstrap and Operations service instances pseudo-randomly during session initiation.Two load balancing methods are used depending on the on the originator of requests to the Kaa cluster: Kaa endpoint SDK or REST API.
Endpoint SDK requests
Kaa SDK chooses the Bootstrap and the Operations service instances pseudo-randomly during the session initiation.However, if the cluster is heavily loaded, random distribution of endpoints may not be efficient.Also, when a new node joins the cluster, it is required to re-balance the load in the updated topology for optimal performance.
Kaa server uses the active load balancing approach to instruct some of the endpoints to reconnect to a different Operations service thus equalizing the load across the nodes.The algorithm takes the server load data (connected endpoints count, load average, etc.) published by Kaa nodes as an input, and periodically recalculates the weight values of each node.Then, the overloaded nodes are instructed to redirect to a different node some of endpoints that request connection.
A similar approach can be used to take some load off a node by means of a scheduled service, or to gradually migrate the cluster across the physical or virtual machines.To do that, you need to set up a custom load balancing strategy by implementing the Rebalancer interface.See the default implementation for more details.
REST API requests
For REST API load balancing, you can use the existing HTTP(s) load balancing solutions with sticky session support, such as Nginx, AWS Elastic Load balancing, Google Cloud LB.
Kaa instance
Kaa instance (Kaa deployment) is a particular installation of the Kaa platform, either asa single node, or a clustered deployment.
An application in Kaa defines a set of data models, types of communication between the endpoints and Kaa server, and processing rules.Kaa applications are not specific to the target platform, operating system, or the client software implementation.For example, two firmware implementations for a pressure sensor will differ between Arduino and STM32 platforms, yet will be considered the same application in Kaa as long as they report identically structured telemetry data.
Kaa platform is multi-tenant.A single Kaa instance can support multiple independent business entities.Applications belong to tenants, while endpoints register within applications (see the picture below).
An endpoint (EP) is an abstraction that represents a separately managed entity within a Kaa deployment.Practically speaking, an endpoint is a specific Kaa client registered (or waiting to be registered) within a Kaa instance.Depending on the use case, different level physical entities can be considered endpoints.In an industrial setting, a single air quality sensor can represent an individual endpoint, while in a fleet tracking application, a truck (despite carryingon board multiple sensors that report data) may be a more appropriate entity to be declared as an endpoint.

To distinguish endpoints by different properties, rather than use one ID, Kaa uses endpoint profiles.
Endpoint profile is a custom structured data set that describes characteristics of a specific endpoint within an application.Every endpoint profile comprises the client-side, server-side, and system parts.Initial values for the client-side part are specified by the the client developer using data schemas for the endpoint SDK.Then, the client-side endpoint profile is generated during registration of a new endpoint.The server-side and system parts of the endpoint profile data are managed by the Kaa server.
See also Endpoint profiles.
Profile data is used to attribute endpoints to endpoint groups — independently managed entities defined by profile filters.Those endpoints whose profiles match the profile filters of a specific endpoint group automatically become members of this group.An endpoint can be a member of unlimited number of groups at the same time.
Endpoints can also be associated with owners.Depending on the application, owners can be persons, groups of people, or organizations.
Further reading
Use the following guides and references to learn more about Kaa features.
| Guide | What it is for |
|---|---|
| Key platform features | Learn about Kaa key features, such as endpoint profiling, data collection, configuration management, events, notifications, and others. |
| Installation guide | Install and configure Kaa platform on a single Linux node or in a cluster environment. |
| Contribute to Kaa | Learn how to contribute to Kaa project and which code/documentation style conventions we adhere to. |
体系结构概述
- KAA群集
- 控制服务
- 业务服务
- 引导服务
- 第三方组件
- Zookeeper
- SQL 数据库
- NoSQL 数据库
- 节间通信
- 高可用性和可伸缩性
- 活动负载平衡
- 端点 SDK 请求
- REST API 请求
- KAA实例
- 进一步阅读
本节讨论了KAA体系结构和逻辑设计背后的基本概念。
KAA平台由KAA服务器、KAA扩展和端点 sdk组成。
- KAA服务器是平台的后端部分。它用于管理租户、应用程序、用户和设备。KAA服务器公开集成接口并提供管理功能。
-
KAA扩展是独立的软件模块, 用于改进平台功能。
注意:在本版本的文档中, 您将注意到某些扩展实际上是在平台的核心中管理的。这些计划在未来的KAA版本中完全脱钩。
- 端点 SDK 是一个库, 为各种KAA平台功能提供客户端 api, 并处理通信、数据编组、持久性等。KAA sdk 旨在帮助创建客户端应用程序, 以便在各种连接的设备上运行。但是, 不使用KAA端点 SDK 的客户端应用程序也是可能的。有多个端点SDK 类型可用于不同的编程语言。
KAA群集
KAA服务器节点使用Apache ZooKeeper来协调服务。互联节点构成与特定KAA实例关联的KAA群集。卡卡群集要求 NoSQL 和 SQL 数据库实例存储端点数据和元数据。
群集中的KAA结节点运行控件、操作和引导服务的组合。
控制服务
KAA控制服务管理整个系统数据, 从 web UI 和外部集成系统处理API 调用, 并将通知发送到操作服务。控制服务通过不断从动物园管理员那里收到此信息来维护可用操作服务的最新列表。此外, 控制服务还运行嵌入式管理 web UI 组件, 使用控制服务 api 为平台用户提供一个方便的基于 web 的界面, 用于管理租户、用户帐户、应用程序、应用程序数据等。
要支持高可用性 (HA), 卡阿群集必须至少包含两个启用了控制服务的节点。在 HA 模式中, 其中一个控制服务在待机模式下充当活动和其他 (s) 函数。在活动控制服务失败的情况下, 管理员会通知某个备用控制服务, 并将其升级到主动控制服务。
运营服务
操作服务的主要角色是同时与多个端点通信。操作服务处理端点请求并向它们发送数据。
为了进行水平缩放, 您可以为每个节点设置启用操作服务的阿卡群集。在这种情况下, 操作服务的所有实例都将同时运行。在操作服务中断的情况下, 以前连接的终结点会自动切换到其他可用的操作服务。卡卡服务器可以在运行时重新平衡负载, 从而有效地将端点路由到群集中较少的节点。
引导服务
KAA引导服务将信息发送到有关操作服务连接参数的端点。根据配置的协议栈, 连接参数可能包括 IP 地址、TCP 端口、安全凭据等。KAA sdk 包含一个预先生成的引导服务列表, 它用于生成 SDK 库。端点查询引导服务从此列表中检索当前可用操作服务的连接参数。通过与动物园管理员协调, 引导服务维护其可用操作服务的列表。
第三方组件
饲养员
Apache 管理员可以对KAA群集节点进行高度可靠的分布式协调。每个KAA节点不断推送有关连接参数、已启用服务和相应服务负载的信息。其他KAA节点使用此信息获取其同级的列表并与它们进行通信。活动控制服务在 SDK 生成期间使用有关可用引导服务及其连接参数的信息。
SQL 数据库
SQL 数据库实例用于存储租户、应用程序、终结点组和其他不随端点数量增加而增长的元数据。
通过在 HA 模式下部署 SQL 数据库, 可实现阿卡群集的高可用性。卡卡目前正式支持MariaDB和PostgreSQL作为嵌入式 SQL 数据库。
NoSQL 数据库
NoSQL 数据库实例用于存储与端点相关的数据, 随着端点数量的增加而线性增长。
NoSQL 数据库节点可以与同一个物理或虚拟机上的卡卡节点共同定位, 并且应以 HA 模式部署, 以获得系统的整体高可用性。卡卡目前正式支持Apache 卡珊德拉和MongoDB作为嵌入式 NoSQL 数据库。
节间通信
KAA服务使用Apache Thirft跨进程和节点进行通信。每个服务都使用Apache 管理员获取有关其同级的元数据。此元数据包含有关节俭主机和端口的信息。
高可用性和可伸缩性
KAA簇水平和线性缩放;在KAA群集体系结构中没有单点故障。KAA操作和引导服务是相同的, 并在主动活动 HA 模式中起作用。其中一个群集节点包含活动控件服务。如果该节点出现故障, 另一个节点中的备用控制服务将被提升为活动状态。KAA群集的高可用性还取决于 SQL 和 NoSQL 数据库的 HA。
活动负载平衡
KAA SDK 在会话启动过程中随机选择引导和操作服务实例。两种负载平衡方法的使用取决于请求的发起方对KAA群集: KAA端点 SDK 或 REST API。
端点 SDK 请求
KAA SDK 在会话启动过程中随机选择引导和操作服务实例。但是, 如果群集负载很大, 则端点的随机分布可能不太有效。另外, 当新节点加入群集时, 需要在更新的拓扑中重新平衡负载以获得最佳性能。
KAA服务器使用活动负载平衡方法指示某些端点重新连接到不同的操作服务, 从而使负载在各个节点之间均衡。该算法将由KAA节点发布的服务器负载数据 (连接端点计数、负载平均值等) 作为输入, 并定期重新计算每个节点的权重值。然后, 指示重载节点重定向到其他节点, 这些端点请求连接。
类似的方法可用于通过定时服务从节点上取一些负载, 或者逐步跨物理或虚拟机迁移群集。为此, 需要通过实现Rebalancer接口来设置自定义负载平衡策略。有关详细信息, 请参阅默认实现。
REST API 请求
对于 REST API 负载平衡, 可以使用具有粘滞会话支持的现有 HTTP 负载平衡解决方案, 如Nginx、 AWS 弹性负载平衡、 Google 云 LB。
KAA实例
KAA实例 (KAA部署)是KAA平台的特定安装, 无论是单节点还是群集部署。
KAA中的应用程序定义了一组数据模型、端点和KAA服务器之间的通信类型以及处理规则。KAA应用程序不特定于目标平台、操作系统或客户端软件实现。例如, 压力传感器的两个固件实现在 Arduino 和 STM32 平台之间会有所不同, 但只要它们报告相同的结构化遥测数据, 就会将其视为相同的应用程序。
KAA平台是多租户。一个KAA实例可以支持多个独立的业务实体。应用程序属于租户, 而端点在应用程序内注册 (请参见下面的图片)。
端点 (EP)是一个抽象, 表示在KAA部署中单独托管的实体。实际上, 端点是在KAA实例中注册 (或等待注册) 的特定KAA客户端。根据用例, 可以将不同级别的物理实体视为端点。在工业环境中, 单个空气质量传感器可以代表单个端点, 而在舰队跟踪应用中, 卡车 (尽管载有报告数据的多个传感器) 可能是作为端点声明的更合适的实体。
为了区分端点由不同的属性, 而不是使用一个 ID, KAA使用端点配置文件。
端点配置文件是一个自定义结构化数据集, 用于描述应用程序中特定端点的特征。每个端点配置文件包括客户端、服务器端和系统部件。客户端部件的初始值由客户端开发人员使用终结点 SDK的数据架构指定。然后, 客户端端点配置文件在注册新端点时生成。端点配置文件数据的服务器端和系统部分由卡卡服务器管理。
另请参见端点配置文件。
配置文件数据用于将终结点归因于终结点组-由配置文件筛选器定义的独立托管实体。其配置文件与特定端点组的配置文件筛选器匹配的端点自动成为此组的成员。端点可以是不受限制的组数的成员。
端点也可以与所有者关联。根据应用程序的不同, 所有者可以是个人、团体或组织。
进一步阅读
使用以下参考线和参考资料了解有关卡卡功能的更多信息。
| 指导 | 它是什么 |
|---|---|
| 关键平台功能 | 了解卡卡的关键功能, 如端点分析、数据收集、配置管理、事件、通知等。 |
| 安装指南 | 在单个 Linux 节点或群集环境中安装和配置阿卡平台。 |
| 贡献卡卡 | 了解如何对卡卡项目以及我们遵守的代码/文档样式约定作出贡献。 |