nodejs原理
即使还没有用nodejs写过什么项目,但是,核心中的核心,原理中的原理,maybe已经掌握到了。
先说nodejs和java对于并发处理上到区别。
java是最熟悉的了,所有人都知道,java在处理并发业务的时候是直接开一个线程去做。如下图所示
即使新开了线程,在并发更高的情况下,还是会出现等待,这是必然的。多个线程的并行运行,cpu会不断的在线程的上下文之间切换,会增加服务器的负担,多线程的创建和删除也会产生内存上的负担和GC的负担。当一个线程去完成一个业务的时候如果遇到IO操作还是会让线程进行阻塞,也就是说拜托不了任务同步的问题。
但是nodejs的处理方式是孑然不同,因为它的特点是单线程,异步IO,事件循环。
先说nodejs的单线程。关于它的单线程,有一个最直观的理解就是开发者不能自己新建线程去处理一个任务,对于web应用所有的请求的处理都是在一个主线程中完成的,所有请求的处理和请求的响应都是在一个线程中。这样的话当前的cpu只对当前的任务进行处理,不会同时处理多个请求,自然也就不需要像java那样需要锁,加锁,解锁,死锁各种问题。但是你也不能理解成进来一个请求就处理,处理完之后再处理下一个请求,这样的话也太low了吧。这里就提到了异步io
异步io的意思就是当主线程处理请求遇到io操作的时候不会由主线程自己去完成(因为这样会造成主线程的阻塞),而是交给libuv(这个是nodejs架构中的一部分,下面会详细描述)中的线程池去完成,线程池中的线程完成之后交给事件循环,主线程通过事件循环来拿io操作的结果,然后通过回调函数来进行处理。
关于事件循环,主要的实现是在libuv中,在下面会有详细的描述。
那么很明了的可以看到和java的处理的区别,nodejs主线程只有在遇到io操作的时候才会去交给线程池去处理,在主线程的业务执行完之后,开始事件循环,然后通过事件循环来得到io处理的结果,然后主线程通过回调函数完成io操作之后的业务,再去事件循环找io操作的返回结果,这么一直循环下去。
那你肯定也会说nodejs的io操作还是通过多线程来完成的,怎么就提高了并发的效率了?因为nodejs可以不断的接受请求,但是不立即返回结果,请求的处理,io的操作交给线程池去处理,处理之后再返回。这样不会产生阻塞,也就是可以提高吞吐量,而不会拒绝请求或者让请求等待。
其实这样也暴露了很大的问题就是,不能利用多核芯啊,现在的cpu都是多核芯,可以并行处理多个任务,nodejs这种单线程的运行方式,一次只处理一个业务,对于多核芯也是一种浪费。
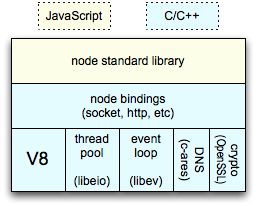
nodejs组成部分:v8 engine, libuv,(就是上图中的threadpoll和eventloop,这两者是libuv的两个部分) builtin modules, native modules以及其他辅助服务。
v8 engine:主要有两个作用 1.虚拟机的功能,执行js代码(自己的代码,第三方的代码和native modules的代码)。
2.提供C++函数接口,为nodejs提供v8初始化,创建context,scope等。
libuv:它是基于事件驱动的异步IO模型库,我们的js代码发出请求,最终由libuv完成,而我们所设置的回调函数则是在libuv触发。
builtin modules:它是由C++代码写成各类模块,包含了crypto,zlib, file stream etc 基础功能。(v8提供了函数接口,libuv提供异步IO模型库,以及一些nodejs函数,为builtin modules提供服务)。
native modules:它是由js写成,提供我们应用程序调用的库,同时这些模块又依赖builtin modules来获取相应的服务支持
先说这个线程池
说道线程池,在java领域中,jdk本身就提供了多种线程池实现,几乎所有的线程池都遵循以下模型(任务队列+线程池):
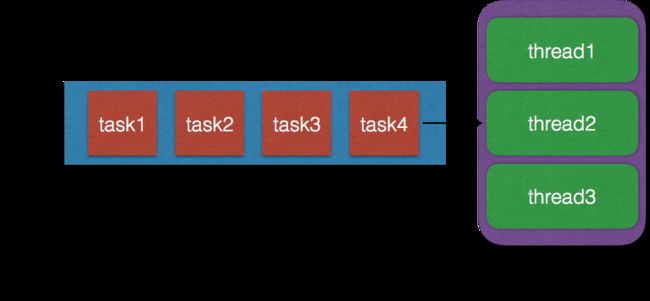
libuv自身定义了一个非常精炼、高效的队列(双向循环链表),只用了几个简单的宏定义将其实现。具体队列和线程池的操作上的细节的细节我也看不懂了。。。
libuv对异步io操作分成两个部分Network I/O的相关请求,另一部分File I/O,DNS Ops和User Code组成。将他们分开,那肯定是因为两者的处理方式上有很大的区别。细节的东西这里就不做分析了。
上一个图就很明了了
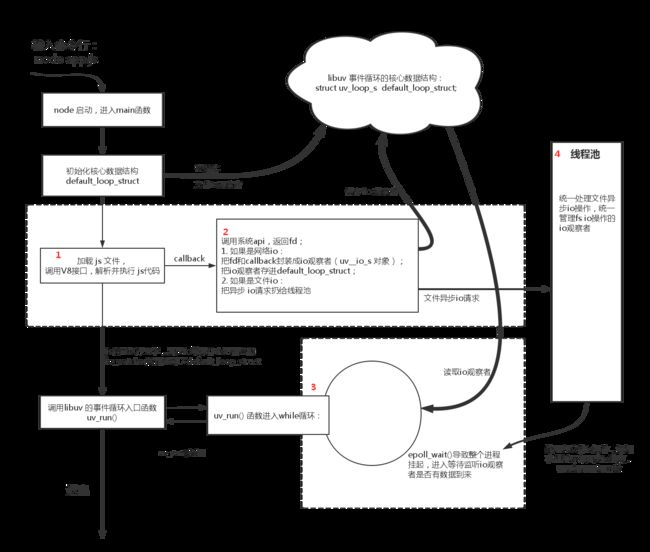
关于观察者,从上图中可以很明显的看到,在整个事件循环过程中承担了最基本的数据结构的角色,所有的io请求或者网络请求都被封装成了观察者对象,事件循环通过观察者对象来调用回调函数。这里可以很明确的看到,观察者就是文件描述符表和callbach的和。这个图太直观,太明了了,事件循环的一切细节都在上面了。
说到这个观察者对象,有人会觉得难道这就是传说设计模式中的观察者模式吗?nonono,观察者模式是定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。而反观上面的事件循环机制,我们封装了一个又一个的观察者对象,然后事件循环通过观察者对象来获取异步操作结束之后返回的数据,并交给主线程来处理。
仔细想想这是一种典型的生产者消费者模式。生产者是libuv中的线程池,线程池通对io处理返回数据给观察者,实现循环检查观察者来获取返回数据来操作,那么事件循环中检查观察者的线程就是一个消费者。所以这是一个典型的生产者消费者模式。
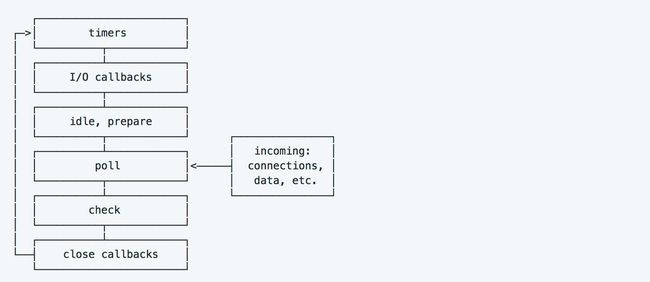
上面说了事件循环的整体逻辑,但是实际上事件循环在真正的运行的时候还要分几个不同的阶段来执行,如下图所示。
eventloop.jpg
上述的五个阶段都是按照先进先出的规则执行回调函数。按顺序执行每个阶段的回调函数队列,直至队列为空或是该阶段执行的回调函数达到该阶段所允许一次执行回调函数的最大限制后,才会将操作权移交给下一阶段。
每个阶段的简单概要:
- timers: 执行setTimeout() 和 setInterval() 预先设定的回调函数。
- I/O callbacks: 大部分执行都是timers 阶段或是setImmediate() 预先设定的并且出现异常的回调函数事件。
- idle, prepare: nodejs 内部函数调用。
- poll: 搜寻I/O事件,nodejs进程在这个阶段会选择在该阶段适当的阻塞一段时间。
- check: setImmediate() 函数会在这个阶段执行。
- close callbacks: 执行一些诸如关闭事件的回调函数,如socket.on('close', ...) 。
每一个阶段都有一个装有callbacks的fifo queue(队列),当event loop运行到一个指定阶段时,
node将执行该阶段的fifo queue(队列),当队列callback执行完或者执行callbacks数量超过该阶段的上限时,
event loop会转入下一下阶段
timers
指定线程执行定时器(setTimeout和 setInterval)的回调函数,但是大多数的时候定时器的回调函数执行的时间要远大于定时器设定的时间。因为必须要等poll phrase中的poll queue队列为空时,poll才会去查看timer中有没有到期的定时器然后去执行定时器中的回调函数。
I/O callbacks
该阶段执行一些诸如TCP的errors回调函数。
check
如果poll中已没有排队的队列,并且存在setImmediate() 立即执行的回调函数,这是event loop不会在poll阶段阻塞等待相应的I/O事件,而是直接去check阶段执行setImmediate() 函数。
close callback
该阶段执行close的事件函数。
poll阶段:
在node.js里,任何异步方法(除timer,close,setImmediate之外)完成时,都会将其callback加到poll queue里,并立即执行。
poll 阶段有两个主要的功能:
- 处理poll队列(poll quenue)的事件(callback);
- 执行timers的callback,当到达timers指定的时间时;
如果event loop进入了 poll阶段,且代码未设定timer,将会发生下面情况:
- 如果poll queue不为空,event loop将同步的执行queue里的callback,直至queue为空,或执行的callback到达系统上限;
- 如果poll queue为空,将会发生下面情况:
- 如果代码已经被setImmediate()设定了callback, event loop将结束poll阶段进入check阶段,并执行check阶段的queue (check阶段的queue是 setImmediate设定的)
- 如果代码没有设定setImmediate(callback),event loop将阻塞在该阶段等待callbacks加入poll queue;
如果event loop进入了 poll阶段,且代码设定了timer:
- 如果poll queue进入空状态时(即poll 阶段为空闲状态),event loop将检查timers,如果有1个或多个timers时间时间已经到达,event loop将按循环顺序进入 timers 阶段,并执行timer queue.