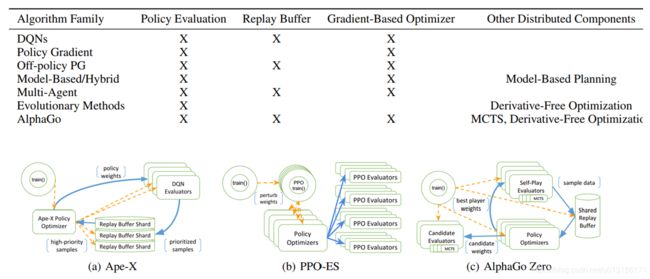
Ray强化学习分布式框架及RLlib
最近阅读了
Ray: A Distributed Framework for Emerging AI Applications
RLlib: Abstractions for Distributed Reinforcement Learning
两篇文章,然而发现对应的博客解读还是比较少,所以简单总结下这两篇文章。
首先这是一个开源项目,相关的文档已经可以轻松在网上获得。分布式框架
https://ray.readthedocs.io/en/latest/rllib.html
https://github.com/ray-project/ray/blob/master/doc/source/rllib-training.rst

ray是一个针对强化学习及类似学习过程而设计的一个框架,它是为了解决其它框架都无法统一直接地完成强化学习计算的问题而设计的一款可以将强化学习主要计算囊括并分布式化的框架,事实上它并不特别复杂。
首先它将强化学习普遍存在的最重要的几个计算归结为training(模型训练)serving(模型推理) simulation(仿真,这个基本其它框架方案没有满足的,因为它一般是有状态的且大小时间都难以确定,甚至是黑盒)
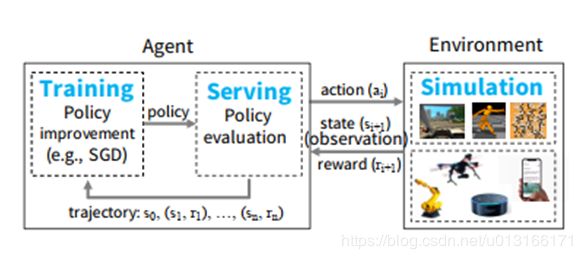
一般过程,伪代码做过RL的容易读懂:

Ray的主要贡献是、
第一个整合三种计算需求的分布式框架,适合RL
该框架表示并控制这三种计算,主要做到三种功能:
1可伸缩性
2动态负载平衡仿真
3处理大型输入和输出
4一致性(事实上只是通过避免一致性问题来解决),容灾(通过redis数据库),和失败恢复(幂等性的传输只需要重传即可)
另外它只是框架,并不替代tensorflow而是可叠合tensorflow使用,无缝集成。
在目前,Ray还不够完善,但已经可以使用
对于Simulation,因为有可能是黑盒,大小不一,可能有状态(如airsim,openai gym等),所以这类任务看成是粗粒度的(不可分割的),而另外一些如training,serving,它则将其主要视为可以分割的任务(但实际具体的分割还需要自己写,或者直接调用他们写好的RLlib库)这两个分别为:
Task:无状态,可进行细分的任务,优先本地处理,也可轻松移植到空闲服务器上做运算(之所以是无状态的是因为运算内容存在redis中,如果数据不在本机会自动取别的机子取,所以运算实际需要做的是从数据库中取出计算,在将内容存进redis中)
Actors:有状态,粗粒度,异构硬件,异构时间(硬件相关,粗粒度,or黑盒)
相互间调度的方法主要是RPC,对使用者使用方法很简单,用对应的python函数或者注解可以完成,类似与操作系统陷入内核的操作,远程调用执行,一段时间后直接从缓冲区取数据即可,其余的分配任务到远程的行为框架会根据其算法自动完成。

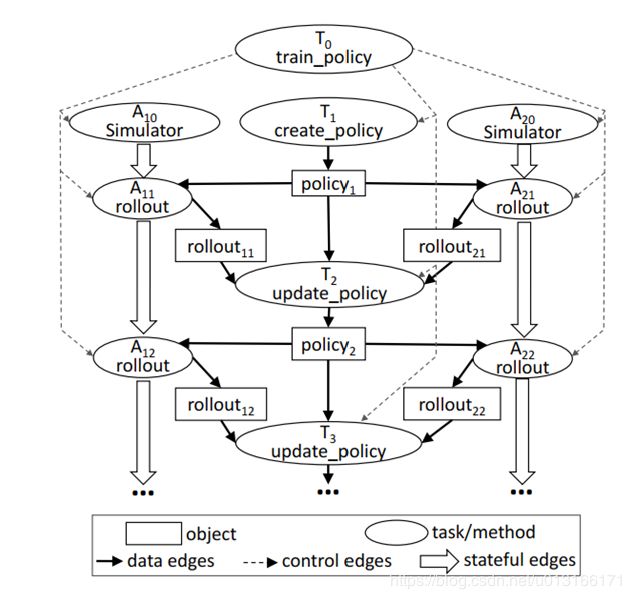
在Ray里,需要将计算抽象成对应计算图进行管理,
中间传输的主要是数据对象(长方形)和远程函数调用信息
边分为三种 数据边、控制边(控制信号),状态边(actor状态的保持)
点分为2种(球型的),task, actor
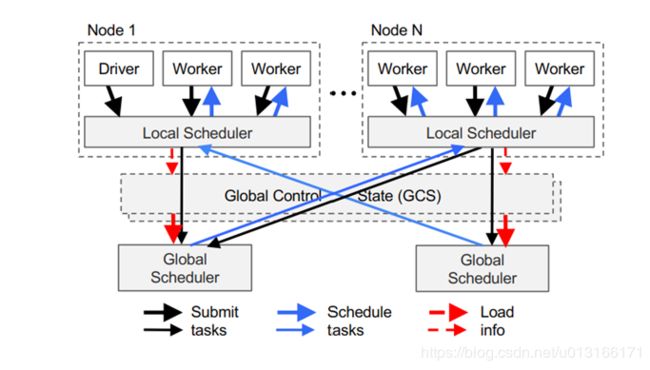
具体的实际系统层面的话分成两层:应用层(写程序在这层) 系统层(实际调配层),如下图所示
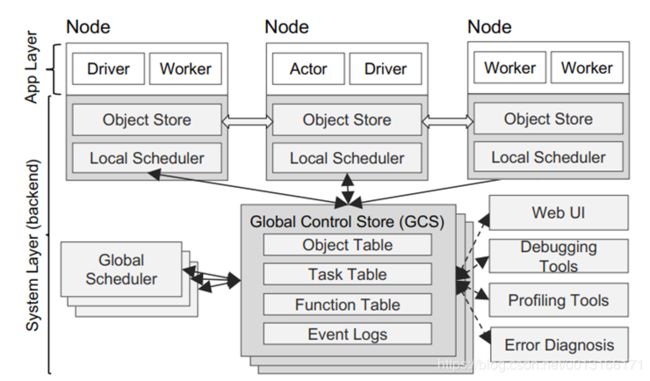
driver就是用户写的调用ray remote的函数,worker就是完成task的工人,actor则是需要完成的actor任务,每个分节点上都有局部调度器,及数据对象存储(一般数据对象只在Node节点上调度,减少总节点的负载,总结点负责全局调度,不存有具体数据,只存储数据在分节点的位置)
GCS:全局redis,调度器要安排在主要链路之外,调整redis内对象和消息队列进行异步调度
GCS大大简化了Ray的总体设计,因为它使系统中的每个组件都处于无状态。这不仅简化了对容错的支持(即故障时,组件只需重新启动并从GCS读取沿袭),而且可以轻松地独立地扩展分布式对象存储和调度程序
自底而上的调度:
一般对于worker和task,最方便且消耗最小的就是直接在自己节点上运算,所以该框架设计task优先在本Node上调度,在性能不足时才会向总调度器请求往别的机子取调度。
还有个小插曲是这个框架设计大量RPC和复制,于是相关大佬对此做了更多的优化,如与redis共享内存等。
更多介绍详见:
https://www.zhihu.com/question/265485941/answer/298822348
https://www.zhihu.com/question/265485941
最后是一个官方例子(矩阵a+b),嫌麻烦直接贴英文说明


RLlib:
虽然有了ray,但对于某一算法(如DQN,DDPG)一般不了解这个框架的人不知道怎么写,怎么样让task划分并行,于是该实验室就基于Ray这个库实现了多种RL算法形成一个可以方便直接调用的库,包括DQN DDPG等
其设计理念是这样的:
基于ray框架,组件化实现强化学习经典方法
构建了不同形式的计算模型,无导优化,model base,策略优化,多种异步任务
且需要保证可以集中统一控制
对于每个分布式的rl算法,可以编写一个等价的算法,显示逻辑上的集中式程序控制。同时算法子任务交给别机器进行处理。
整体设计大任务,然后单任务分小块并行
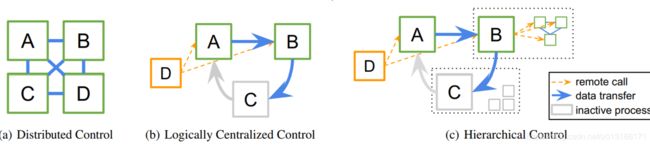
rllib将算法的实现分离为特定于算法的策略图的声明和与算法无关的策略优化器(如重要性采样)的选择。
具体子方法算法无关的实现,从而可以互相组合。
如策略优化器负责分布式采样、参数更新和管理重放缓冲区等性能关键任务。