Spark Shuffle原理与源码解析
1、普通的shuffle过程
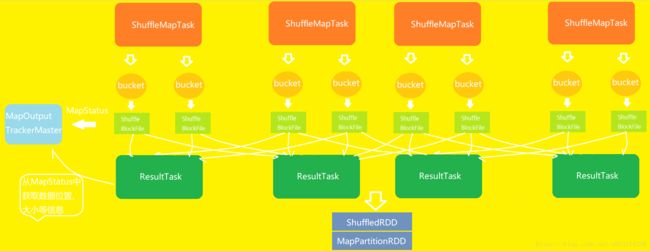
①假设节点上有4个ShuffleMapTask,节点上有2个cup core
②ShuffleMapTask的输出,称为shuffle过程的第一个rdd,即MapPartitionRDD
③每个ShuffleMapTask会为每一个task创建一份bucket内存缓存,以及对应的ShuffleBlockFile磁盘文件
④ShuffleMapTask输出结束后,封装输出数据信息和输出状态等MapStatus发送给DAGSchduler的MapOutputTrackerMaster中
⑤ResultTask通过BlockStoreShuffleFetcher从MapOutputTrackerMaster从MapOutputTrackerMaster的MapStatus中获取文件位置、文件大小等信息
⑥ResultTask获取到信息后,通过BlockManager拉取ShuffleBlockFile文件
⑦ResultTask获取到数据,形成一个rdd,即ShuffledRDD,数据优先放入内存,其次放入磁盘
⑧对每个ResultTask的数据聚合后,最终生成MapPartitionRDD
2、shuffle操作的两个特点
①在spark早期版本中,bucket缓存是非常重要的,因为ShuffleMapTask将所有的数据写入到内存后,才刷新数据到磁盘。存在的问题,如果map side的数据过多,容易造成内存溢出。在spark的新版本中,优化了内存是100KB,数据写入达到磁盘的阈值后,就会将数据一点一滴的刷新到磁盘。
新版本的优化,其优点是不容易发生内存溢出;缺点在于如果内存过小,可能发生过多的磁盘IO操作;所以,这个内存的大小在实际生产业务中会根据情况调优的。
②与Hadoop MapReduce相比,MapReduce是将所有的数据都写入到本地磁盘文件后,才启动reduce操作,因为mapreduce默认实现了要根据key对数据排序。Spark没有实现这一机制,在ShuffleMapTask端开始输出数据,ReduceTask就可以开始拉去数据,执行聚合函数和自定义算子。
spark这种机制的相对于mapreduce的数据输出,速度会快很多,但是mapreduce在reduce阶段可以对key对应的数据进行操作,spark提供不了这种机制,只有通过聚合函数,如groupByKey等,先shuffle,有MapPartitionRDD之后,调用算子对key对应的数据,进行操作。
3、优化后的shuffle操作原理
对于普通的shuffle操作,存在一个问题,100个ShuffleMapTask和100个ResultTask会存在100*100=1万个文件块,大量的磁盘IO操作很大程度地降低任务的速度。
在spark新版本中,引入了consolidation机制,提出了ShuffleGroup的概念。
原理示意图:
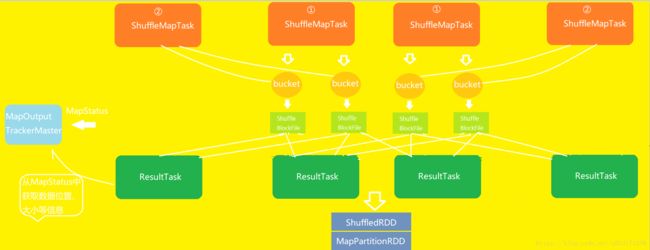
①假设一个节点上有4个ShuffleMapTask、2cup core, 分两批执行
②第二批执行的ShuffleMapTask将相同key的输出的数据写入到上一批ShuffleMapTask写入的bucket缓存中,相当于对ShuffleMapTask的输出数据进行了合并。这时候的每一个bucket-resultrask称作为ShuffleGroup。每个文件中都存储了多个ShuffleMapTask的数据,每个ShuffleMapTask的数据叫做segment。此外,还通过一些索引,偏移量来对不同的ShuffleMapTask的输出数据做区分。
③开启consolidation机制后的shuffle writer在一个节点上的输出文件数量,即cup数量 * ResultTask的数量,同样100个ResultTask数量的文件块数量为2*100 = 200。
④代码中设置:new SparkConf().set("spark.shuffle.consolidateFiles","true"
3、Shuffle 操作的读源码解析
ShuffleMapTask.scala
// ShuffleMapTask的 runTask 有 MapStatus返回值
override def runTask(context: TaskContext): MapStatus = {
// Deserialize the RDD using the broadcast variable.
val threadMXBean = ManagementFactory.getThreadMXBean
val deserializeStartTime = System.currentTimeMillis()
val deserializeStartCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime
} else 0L
// 对task要处理的数据,做反序列化操作
/*
问题:多个task在executor中并发运行,数据可能都不在一台机器上,一个stage处理的rdd都是一样的
task怎么拿到自己要处理的数据的?
答案:通过broadcast value 广播变量获取
*/
val ser = SparkEnv.get.closureSerializer.newInstance()
val (rdd, dep) = ser.deserialize[(RDD[_], ShuffleDependency[_, _, _])](
ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)
_executorDeserializeTime = System.currentTimeMillis() - deserializeStartTime
_executorDeserializeCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime - deserializeStartCpuTime
} else 0L
var writer: ShuffleWriter[Any, Any] = null
try {
// 拿到shuffleManager
val manager = SparkEnv.get.shuffleManager
// 拿到shuffleWriter
writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)
// 首先,调用rdd的iterator方法,并且传入了当前要处理的partition
// 核心逻辑就在rdd的iterator()方法中
// 执行完成rdd之后,rdd或返回处理过后的partition数据,这些数据通过shuffleWriter
// 在经过HashPartitioner写入对应的分区中
writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])
// 返回结果 MapStatus ,里面封装了ShuffleMapTask存储在哪里,其实就是BlockManager相关信息
writer.stop(success = true).get
} catch {
case e: Exception =>
try {
if (writer != null) {
writer.stop(success = false)
}
} catch {
case e: Exception =>
log.debug("Could not stop writer", e)
}
throw e
}
}
HashShuffleWriter.scala
/** Write a bunch of records to this task's output */
override def write(records: Iterator[Product2[K, V]]): Unit = {
// 判断是否需要在map端聚合 dep.aggregator.isDefined 和 dep.mapSideCombine都为ture就会在map端聚合
val iter = if (dep.aggregator.isDefined) {
if (dep.mapSideCombine) {
// 本地聚合,如(hello,1)(hello,1)聚合为(hello,2)
dep.aggregator.get.combineValuesByKey(records, context)
} else {
records
}
} else {
require(!dep.mapSideCombine, "Map-side combine without Aggregator specified!")
records
}
// 遍历数据,默认是HashPartitioner生成bucketId
// 也就决定了每一份数据写入那一个bucket
for (elem <- iter) {
val bucketId = dep.partitioner.getPartition(elem._1)
// 获取到bucketId之后,调用ShuffleBlockManager.forMapTask()方法,生成bucketId对应的writer
// 然后将数据写入bucket
shuffle.writers(bucketId).write(elem._1, elem._2)
}
}在spark的高版本中取消了HashShuffleWriter的读取文件
4、Shuffle 操作的读源码解析
ShuffledRDD.scala
override def compute(split: Partition, context: TaskContext): Iterator[(K, C)] = {
val dep = dependencies.head.asInstanceOf[ShuffleDependency[K, V, C]]
// ResultTask或ShuffleMapTask执行到ShuffledRDD的时候,计算当前RDD的partition数据
// 会调用ShuffleManager的getReader() 获取到HashShuffleReader,然后调用read()方法
// 读取ResultTask或ShuffleMapTask的数据
SparkEnv.get.shuffleManager.getReader(dep.shuffleHandle, split.index, split.index + 1, context)
.read()
.asInstanceOf[Iterator[(K, C)]]
}在spark高版本中,取消了HashShuffleWriter.scala,下面给出BlockStoreShuffleReader
BlockStoreShuffleReader.scala
override def read(): Iterator[Product2[K, C]] = {
// ResultTask在读取数据的时候,调用ShuffleBlockFetcherIterator从那个DAGSchduler的mapOutputTracker中获取数据
// 通过BlockManager从对应的位置读取
val blockFetcherItr = new ShuffleBlockFetcherIterator(
context,
blockManager.shuffleClient,
blockManager,
mapOutputTracker.getMapSizesByExecutorId(handle.shuffleId, startPartition, endPartition),
// Note: we use getSizeAsMb when no suffix is provided for backwards compatibility
SparkEnv.get.conf.getSizeAsMb("spark.reducer.maxSizeInFlight", "48m") * 1024 * 1024)
// Wrap the streams for compression based on configuration
val wrappedStreams = blockFetcherItr.map { case (blockId, inputStream) =>
blockManager.wrapForCompression(blockId, inputStream)
....ShuffleBlockFetcherIterator.scala
private[this] def initialize(): Unit = {
// Add a task completion callback (called in both success case and failure case) to cleanup.
context.addTaskCompletionListener(_ => cleanup())
// Split local and remote blocks.
val remoteRequests = splitLocalRemoteBlocks()
// Add the remote requests into our queue in a random order
fetchRequests ++= Utils.randomize(remoteRequests)
// Send out initial requests for blocks, up to our maxBytesInFlight
fetchUpToMaxBytes()
val numFetches = remoteRequests.size - fetchRequests.size
logInfo("Started " + numFetches + " remote fetches in" + Utils.getUsedTimeMs(startTime))
// Get Local Blocks
fetchLocalBlocks()
logDebug("Got local blocks in " + Utils.getUsedTimeMs(startTime))
} private def fetchUpToMaxBytes(): Unit = {
// Send fetch requests up to maxBytesInFlight
// 这里有一个重要的参数,max.bytes.in.flight 它决定了最多能拉取多少数据到本地
// 然后就开始执行reduce中自定义算子
while (fetchRequests.nonEmpty &&
(bytesInFlight == 0 || bytesInFlight + fetchRequests.front.size <= maxBytesInFlight)) {
// 发送请求到远程获取数据
sendRequest(fetchRequests.dequeue())
}
}