spark createDirectStream保存kafka offset(JAVA实现)
问题描述
原文地址:http://blog.csdn.net/xueba207/article/details/50381821
最近使用Spark streaming处理kafka的数据,业务数据量比较大,就使用了KafkaUtils的createDirectStream()方式,此方法直接从kafka的broker的分区中读取数据,跳过了zookeeper,并且没有receiver,是spark的task直接对接kakfa topic partition,能保证消息恰好一次语意,但是此种方式因为没有经过zk,topic的offset也就没有保存,当job重启后只能从最新的offset开始消费消息,造成重启过程中的消息丢失。
解决方案
一般,有两种方式可以先spark streaming 保存offset:spark checkpoint机制和程序中自己实现保存offset逻辑,下面分别介绍。
checkpoint机制
spark streaming job 可以通过checkpoint 的方式保存job执行断点,断点中有spark streaming context中的全部信息(包括有kakfa每个topic partition的offset)。checkpoint有两种方式,一个是checkpoint 数据和metadata,另一个只checkpoint metadata,一般情况只保存metadata即可,因此这里只介绍checkpoint metadata。
流程图
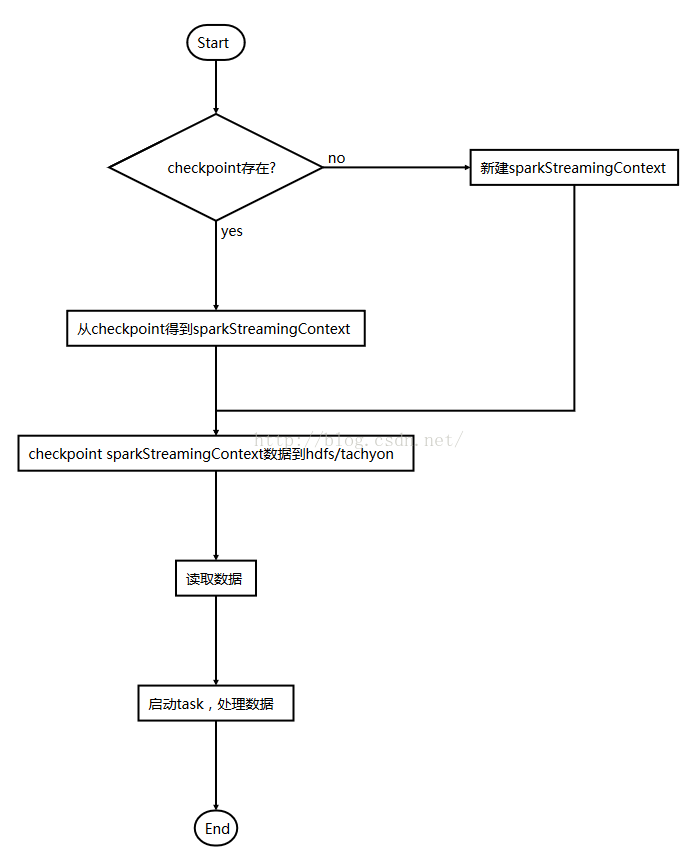
代码实现
package com.nsfocus.bsa.example;
import kafka.serializer.StringDecoder;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.streaming.Duration;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.api.java.JavaStreamingContextFactory;
import org.apache.spark.streaming.kafka.KafkaUtils;
import scala.Tuple2;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Set;
/**
* Checkpoint example
*
* @author Shuai YUAN
* @date 2015/10/27
*/
public class CheckpointTest {
private static String CHECKPOINT_DIR = "/checkpoint";
public static void main(String[] args) {
// get javaStreamingContext from checkpoint dir or create from sparkconf
JavaStreamingContext jssc = JavaStreamingContext.getOrCreate(CHECKPOINT_DIR, new JavaStreamingContextFactory() {
public JavaStreamingContext create() {
return createContext();
}
});
jssc.start();
jssc.awaitTermination();
}
public static JavaStreamingContext createContext() {
SparkConf sparkConf = new SparkConf().setAppName("tachyon-test-consumer");
Set topicSet = new HashSet();
topicSet.add("test_topic");
HashMap kafkaParam = new HashMap();
kafkaParam.put("metadata.broker.list", "test1:9092,test2:9092");
JavaStreamingContext jssc = new JavaStreamingContext(sparkConf, new Duration(2000));
// do checkpoint metadata to hdfs
jssc.checkpoint(CHECKPOINT_DIR);
JavaPairInputDStream message =
KafkaUtils.createDirectStream(
jssc,
String.class,
String.class,
StringDecoder.class,
StringDecoder.class,
kafkaParam,
topicSet
);
JavaDStream valueDStream = message.map(new Function, String>() {
public String call(Tuple2 v1) throws Exception {
return v1._2();
}
});
valueDStream.count().print();
return jssc;
}
} 自己实现保存offset到zk
开发者可以自己开发保存offset到zk的实现逻辑。spark streaming 的rdd可以被转换为HasOffsetRanges类型,进而得到所有partition的offset。
实现流程
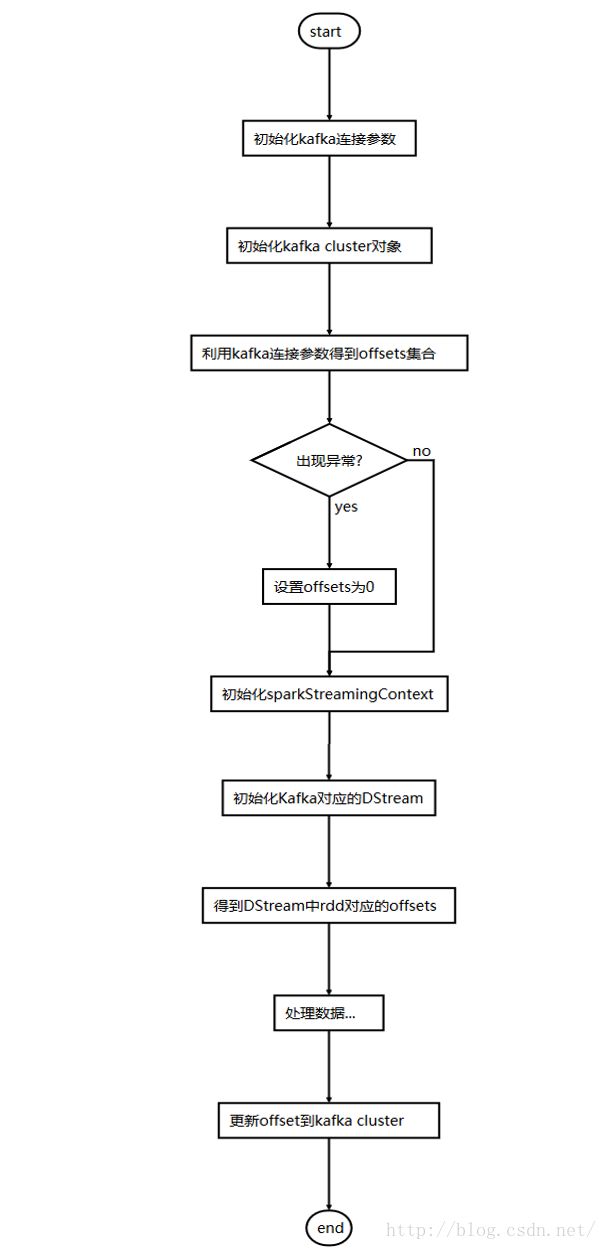
源码实现
scala的实现网上很容易搜到,这里贴个Java实现的代码。
package com.xueba207.test;
import kafka.common.TopicAndPartition;
import kafka.message.MessageAndMetadata;
import kafka.serializer.StringDecoder;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.broadcast.Broadcast;
import org.apache.spark.sql.DataFrame;
import org.apache.spark.sql.SaveMode;
import org.apache.spark.sql.hive.HiveContext;
import org.apache.spark.streaming.Duration;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka.HasOffsetRanges;
import org.apache.spark.streaming.kafka.KafkaCluster;
import org.apache.spark.streaming.kafka.KafkaUtils;
import org.apache.spark.streaming.kafka.OffsetRange;
import scala.Predef;
import scala.Tuple2;
import scala.collection.JavaConversions;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
import java.util.Set;
import java.util.concurrent.atomic.AtomicReference;
/**
* KafkaOffsetExample
*
* @author Shuai YUAN
* @date 2015/10/28
*/
public class KafkaOffsetExample {
private static KafkaCluster kafkaCluster = null;
private static HashMap kafkaParam = new HashMap();
private static Broadcast> kafkaParamBroadcast = null;
private static scala.collection.immutable.Set immutableTopics = null;
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf().setAppName("tachyon-test-consumer");
Set topicSet = new HashSet();
topicSet.add("test_topic");
kafkaParam.put("metadata.broker.list", "test:9092");
kafkaParam.put("group.id", "com.xueba207.test");
// transform java Map to scala immutable.map
scala.collection.mutable.Map testMap = JavaConversions.mapAsScalaMap(kafkaParam);
scala.collection.immutable.Map scalaKafkaParam =
testMap.toMap(new Predef.$less$colon$less, Tuple2>() {
public Tuple2 apply(Tuple2 v1) {
return v1;
}
});
// init KafkaCluster
kafkaCluster = new KafkaCluster(scalaKafkaParam);
scala.collection.mutable.Set mutableTopics = JavaConversions.asScalaSet(topicSet);
immutableTopics = mutableTopics.toSet();
scala.collection.immutable.Set topicAndPartitionSet2 = kafkaCluster.getPartitions(immutableTopics).right().get();
// kafka direct stream 初始化时使用的offset数据
Map consumerOffsetsLong = new HashMap();
// 没有保存offset时(该group首次消费时), 各个partition offset 默认为0
if (kafkaCluster.getConsumerOffsets(kafkaParam.get("group.id"), topicAndPartitionSet2).isLeft()) {
System.out.println(kafkaCluster.getConsumerOffsets(kafkaParam.get("group.id"), topicAndPartitionSet2).left().get());
Set topicAndPartitionSet1 = JavaConversions.setAsJavaSet(topicAndPartitionSet2);
for (TopicAndPartition topicAndPartition : topicAndPartitionSet1) {
consumerOffsetsLong.put(topicAndPartition, 0L);
}
}
// offset已存在, 使用保存的offset
else {
scala.collection.immutable.Map consumerOffsetsTemp = kafkaCluster.getConsumerOffsets("com.nsfocus.bsa.ys.test", topicAndPartitionSet2).right().get();
Map consumerOffsets = JavaConversions.mapAsJavaMap(consumerOffsetsTemp);
Set topicAndPartitionSet1 = JavaConversions.setAsJavaSet(topicAndPartitionSet2);
for (TopicAndPartition topicAndPartition : topicAndPartitionSet1) {
Long offset = (Long)consumerOffsets.get(topicAndPartition);
consumerOffsetsLong.put(topicAndPartition, offset);
}
}
JavaStreamingContext jssc = new JavaStreamingContext(sparkConf, new Duration(5000));
kafkaParamBroadcast = jssc.sparkContext().broadcast(kafkaParam);
// create direct stream
JavaInputDStream message = KafkaUtils.createDirectStream(
jssc,
String.class,
String.class,
StringDecoder.class,
StringDecoder.class,
String.class,
kafkaParam,
consumerOffsetsLong,
new Function, String>() {
public String call(MessageAndMetadata v1) throws Exception {
return v1.message();
}
}
);
// 得到rdd各个分区对应的offset, 并保存在offsetRanges中
final AtomicReference offsetRanges = new AtomicReference();
JavaDStream javaDStream = message.transform(new Function, JavaRDD>() {
public JavaRDD call(JavaRDD rdd) throws Exception {
OffsetRange[] offsets = ((HasOffsetRanges) rdd.rdd()).offsetRanges();
offsetRanges.set(offsets);
return rdd;
}
});
// output
javaDStream.foreachRDD(new Function, Void>() {
public Void call(JavaRDD v1) throws Exception {
if (v1.isEmpty()) return null;
//处理rdd数据,这里保存数据为hdfs的parquet文件
HiveContext hiveContext = SQLContextSingleton.getHiveContextInstance(v1.context());
DataFrame df = hiveContext.jsonRDD(v1);
df.save("/offset/test", "parquet", SaveMode.Append);
for (OffsetRange o : offsetRanges.get()) {
// 封装topic.partition 与 offset对应关系 java Map
TopicAndPartition topicAndPartition = new TopicAndPartition(o.topic(), o.partition());
Map topicAndPartitionObjectMap = new HashMap();
topicAndPartitionObjectMap.put(topicAndPartition, o.untilOffset());
// 转换java map to scala immutable.map
scala.collection.mutable.Map testMap =
JavaConversions.mapAsScalaMap(topicAndPartitionObjectMap);
scala.collection.immutable.Map scalatopicAndPartitionObjectMap =
testMap.toMap(new Predef.$less$colon$less, Tuple2>() {
public Tuple2 apply(Tuple2 v1) {
return v1;
}
});
// 更新offset到kafkaCluster
kafkaCluster.setConsumerOffsets(kafkaParamBroadcast.getValue().get("group.id"), scalatopicAndPartitionObjectMap);
// System.out.println(
// o.topic() + " " + o.partition() + " " + o.fromOffset() + " " + o.untilOffset()
// );
}
return null;
}
});
jssc.start();
jssc.awaitTermination();
}
}