论文笔记:Hashtag Recommendation for Multimodal Microblog Using Co-Attention Network
感想
1 介绍
近几年,微博已经成为最流行了信息产生和扩散,以及各种社交媒体的社交的服务之一,像Twitter和新浪微博,根据Twitter的季度报告显示,每个月有3.17亿活跃用户。用户用有限数量的字去记录生活或者表达感情。因此,微博被广泛用于舆情分析,预测等许多其他的应用。微博包含一种元数据标签形式(metadata tag, hashtag),hashtag是一串前缀为#的字符串。在微博内,Hashtags被当做关键字或者话题,有着广泛的应用,比如微博检索(microblog retrieval),查询展开(query expansion),情感分析(sentiment analysis)。
可是,只有很少的用户才会为微博打上hashtags,因此,自动推荐hashtags的任务变成了很重要的研究课题,最近几年受到了很大的关注。针对这一任务,研究人员使用了多个模型的特征进行建模,协同过滤(collaborative filtering),生成式模型(generativemodels),深度神经网络。即使在这个话题上有很多的研究,大多数的研究都集中在使用文本特征。可是,根据Twitter上的数据检索显示,超过30%的信息是包含图片和文本的。因此,仅仅使用文本信息来推荐hashtags是不那么容易的。

图1描述了一个多模态微博,有hashtag#dog,但是在这个tweet中没有关于狗的信息。仅仅从文本信息中,我们可能提取到了hashtag 就是#birthday。可是,hashtag #dog很难辨识出来。
为了解决这个问题,我们提出了一个结合文本和视觉信息的模型。前面的工作是简单的把图片特征向量和文本特征向量结合起来。可是,正确的hashtags经常只和图片或者文本的一小部分相关。因此,使用一个全局向量去表示图片或者文本会导致局部最优的结果,这是由于图片或者文本的不相关噪声引起的。受图片问答(image QA)任务和看图说话(image captioning)任务的启发,我们引入了注意力机制(attention mechanism),注意力机制使得模型能够集中在输入的特定部分。imagecaptioning和iamge QA主要集于图片处理,上面的这些工作仅仅是通过引入注意力机制对图片特征进行建模。可是,在多模态微博中,文本信息是hashtag推荐的本质部分。除了文本信息以外,图像也为文本的特征提取有用。在这个工作中,我们引入共同注意力网络(co-attention network),他能够把文本和图片之间的相互信息(mutualinfluence)考虑在内。
为了证明我们的模型的有效性,我们用很大的数据集来做实验,这些数据来自Twitter.实验结果是我们提出的方法能够比仅仅使用文本信息方法的效果更好。
2 贡献
1 我们引入了视觉和文本信息的集成框架,用于标签推荐任务(hashtag recommendation tasks)。
2. 我们提出了一个co-attention网络,它集成了tweet的视觉attention和图片的文本attention.
3. 实验结果使用了一个从Twitter上筹集的数据集,结果证明,该方法取得了不错的结果。
3 模型
给定一个Tweet和与之对应的图片,我们的任务是自动为这条tweet产生合适的hashtags.为了把这个任务用到多模态tweets上,我们把这个任务作为一个多类别分为问题(multi-classclassification problem)。

模型的整个结构如上图,网络的输入是一张图片和一个可变长度文字的tweet。输出是一个向量,向量表示的每一个维度代表一个hashtag的概率。
3.1 特征提取
图片特征提取
我们使用了一个预训练的 16层VGGNet,它用来提取一幅图片的特征图(image feature map)。我们首先把图片调整为224*224的固定大小。不像前面的工作那样使用全局向量作为图片特征,我们想要不同区域的空间特征,这包含更多的原图片的信息。我们把一张图片分为一个N*N的网格,我们使用VGGNet去抽取每个网格区域的D维特征向量。因此,一幅图片可以表示为vI={vi|vi∈R^D,i=1,2,..,m}
其中,m=NxN,为图片的区域数量,在我们这里m=49,vi是一个对应每个区域i的512维的特征向量。为了计算的方便,我们使用一个一层感知机来把每个图片转换成一个新的向量,这个向量有和tweet特征向量有相同的维度。
文本特征提取
Tweet t中的每个单词首先用一个one hot向量表示,向量的大小为词汇表的大小。之后,每一个one-hot向量嵌入到一个实值向量xi,这个向量分布在一个连续的空间上。我们对嵌入向量求和,以获取一个句子级别的tweet表达:t=x1,x2,…,xT
其中,T是Tweet的最大长度。在我们的工作中,句子的长度少于T的用0来补齐。
因为LSTM在理解文本上表现了良好的性能,它在最近几年被广泛的应用。我们利用它来产生文本特征。
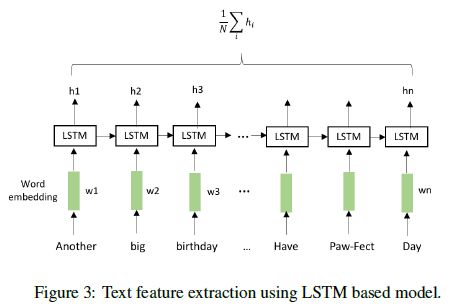
如图3,在每个时间步,LSTM单元接受输入向量(在这个示例中,是嵌入向量),输出一个隐含层向量ht,使用一个输入门it,记忆单元(cell)ct,遗忘门ft,输出门ot.详细解释如下:
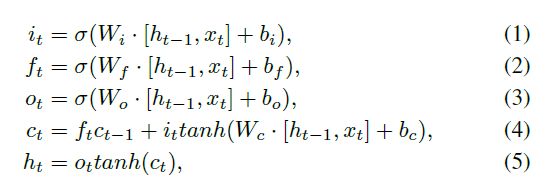
通过在每个时间步结合ht状态,我们构造tweet特征矩阵vT:
vT={hi|hi∈R^d,i=1,2,…,T}
其中,d是LSTM的维度,T是一个Tweet的最大长度。
3.2 Co-Attention Network
Tweet-guided visual attention
在大多数情况下,hashtag仅仅和一幅图片的特定区域有关。例如,在图1中,图片中有很多物体: balloons, a dog, a blackboard和grass。但是hashtag #dog仅仅和图片的小狗相关。因此,我们把图片分成网格,然后从每个格子上提取特征向量,去获取一个特征矩阵vI。我们之后用了一个tweet-guided注意力层来过滤掉噪声,并且找到和对应hashtags对应的相关区域。
就3.1节而言,我们首先使用平均池化操作把Tweet特征归结为一个向量h_ave;接着,我们提出了一个基于tweet 概述(tweet summary)h_ave的图片注意力。我们使用一单层神经网络结合tweet和图片特征。然后使用一个softmax层去产生一个图片注意力分布。这些操作的公式为:
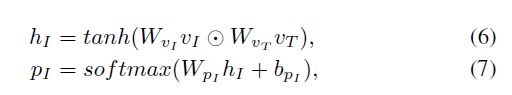
基于每一个区域i的注意力概率pi,图片的新表达是其权重图片向量的和

我们使用新图片的表达来指导文本注意力。
Image-guided textual attention
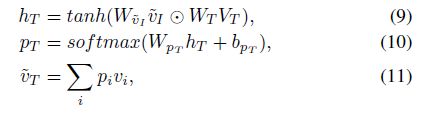
Stacked co-attention network
对于更多复杂的tweets,我们可以试图探索文本和图片之间的微妙关系,因此我们使用新产生的表示不断的查询图像和文本的原特征矩阵。正式地,公式总结如下:
对于第k个 co-attention层,我们单独的计算视觉和文本注意力的分布,昌盛基于注意力概率的对于输入图片的新表达。新的查询向量通过给前面的特征向量加入新的特征向量,这个图片注意力等式如下:
3.3 预测
最后,hashtags的预测使用了多类别分类。我们采用了一个单个的softmax分类器层,损失函数为交叉熵,输入是attention操作产生的特征的结合。最终的向量是f=v ̃T+v ̃I
我们通过使用线面的公式得到第d个tweet的hashtags的分数:
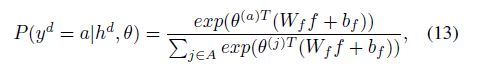
其中,Wf,bf,θ是参数,A是一个候选hashtags的集合。
根据最后一层softmax层的输出的分数,我们可以得到每个tweet的hashtags的排序列表,我们推荐top-ranked的hashtags给用户。
3.4 训练
在我们的工作中,训练目标函数是: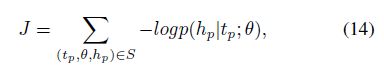
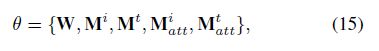
其中,hp是tp的hashtag, S是训练集。W是词嵌入(words embeddings),M^i,M^t分别是图片和文本的特征参数;M_att^i和M_att^t是文本和视觉注意力层的参数;剩下的参数属于全连接层。
这些参数使用随机梯度下降进行训练,用了adam更新规则,Dropout正则化已经被证明是一个有效地方法,并且已用于我们的工作。
4 实验
4.1 数据集和设置
我们开始利用Twitter API筹集公共随机选择的用户的tweets,结合包含2.8222亿调微博,110万用户产生的。从这个微博中,我们提取那些包含图片和hashtags的微博。在这一步中,抽取了227万条微博。有些hashtags很少出现,我们因此过滤掉了这些hashtags.最后,我们筹集的集合包含402782条tweets,有与之对应的图片和高频的hashtags.详细的统计如下表:
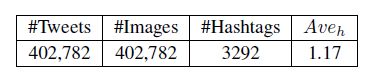
每条tweet的平均hashtags是1.17.我们把数据集分为一个训练集和一个测试集。比率为8:2.随机选取训练集的10%作为development set。
对于文本单词,我们过滤掉消停词和低频率的词。我们构造的词汇表包含278000个单词。对于图片,我们通过检索的url下载图片,并把它们规整为224x224大小。之后我们把他们输入到一个预训练的VGG-16的网络。VGG网络的最后一层的输出作为图片的特征提取。
我们使用Precision(P), recall(R),和F1-score(F1)去评估性能。为每个tweet推荐的hashtags的数量用k表示,k={1,2,3,4,5}.因此,相应的度量也可以表示为Pk,Rk,F1k。
4.2 基准线
为了和我们的模型作比较,在我们构造的数据集上,我们评估了下面的方法:
l 朴素贝叶斯(Naive Bayes, NB):hashtag推荐任务被定义为一个分类任务。在给定微博的文本和视觉信息的情况下,我们利用NB去对每个hashtag的后验概率进行建模。
l 支持向量机(Support Vector Machine,SVM):我们也利用SVM用于解决标签推荐问题。
l TTM(The topical translation model):TTM提出来是用于hashtag推荐上的,它只使用了文本信息。话题翻译模型(The topical translation model)用来推荐hashtags。
l CNN-Attention:CNN-Attention是2016年提出来的,它是一个卷机网络结构,使用了注意力机制融合了词触发,这是16年最好的模型。
l Image-Att:Image-Att是一个我们提出的网络的一个变体,它只使用文本进行去产生视觉注意力分布。
l Co-Att-2layer:这也是我们提出的模型的一个变体。我们利用一个栈式的两层co-attention网络对图片和tweets进行建模。
4.3 结果和讨论
我们从以下的角度评估了我们提出的方法:
1. 使用真实世界的数据集来比较。
2. 识别参数的影响。
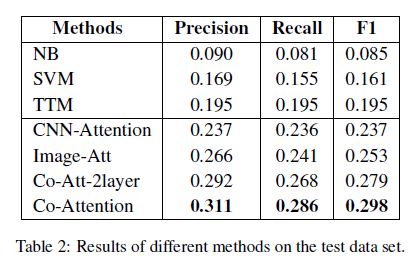
表2显示了我们提出的方法和现在最好的判别方法和生成方法的比较,这是在构造的评估集合上比的。基于这些结果,我们观察到,本文的方法比其它的方法好,判别式方法比生成式方法更差。有视觉信息和没有视觉信息的结果证明,视觉信息可以提高P和R.
根据CNN-attention和我们的模型的比较观察,图片可以提高hashtag推荐任务的性能。越来越多的用户更喜欢发一条有图片的tweet,找到一个能整合文本和视觉信息的方式是非常有意义的。
对于性能较低,我们相信有很多因素会导致这个结果,包括大量的labels。数据集可能是非常困惑且很难区分的,因为所有的结果在评估数据集上都很低。另外,图片类型和源的多样性可能影响使用视觉信息的效果。我们使用的VGG网络是在ILSVRC数据集上预训练的,其图片集包含1000个类别,大多数是户外的场景。可是,从Twitter上爬取的图片是不规则的,有些是在墙上乱涂乱写的(graffiti),自拍照(selfies),或者甚至是智能手机的截图,因此,简单的采用一个预训练的权重可能造成偏差(deviations)。
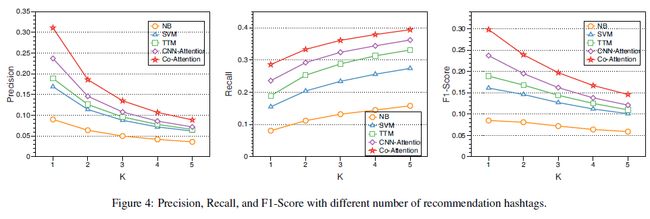
我们比较了该方法的变体的precision,recall和F1-score,Image-att仅仅使用文本信息去产生视觉注意力分布。

表3结果表明,co-attention模型比只是用tweet-guided视觉注意力的模型的效果更好,我们相信tweet的长度较短,这限制了层数的拓展。增加网络的层数会使得模型变得更加复杂,训练时间会更长,结果也没有显著的改进,我们在co-attention层数上就没有做更多的尝试。
4.4 参数影响
表3的结果显示嵌入维度对性能的贡献。更高的嵌入维度会使得性能更好。我们可以看到,当维数达到100的时候,结果会很差,我们提出的模型在高维嵌入上的表现更好。维度从100到300的时候,性能提升很大,但是当维度从300到500的时候,性能提升的很小了,嵌入维度的大小代表每个单词的表达能力,高维的词嵌入可以增强文本的表达能力。
参考文献
[1] Qi Zhang, Jiawen Wang, Haoran Huang,Xuanjing Huang, Yeyun Gong: Hashtag Recommendation for Multimodal MicroblogUsing Co-Attention Network. IJCAI 2017: 3420-3426