论文笔记:Connectionist Temporal Classification: Labelling Unsegmented Sequence
感想
介绍
标记未分割的序列数据是现实世界序列学习中普遍存在的问题,并且在一些感知任务中是普遍实用的,例如手写字体识别,语音识别,手势识别(gesture recognition)。在感知任务中,带有噪声的实值输入流用一串离散的标签进行标注。例如字母或者单词。
当前,图模型,例如HMM,CRFs和他们的变体是序列标注的主要框架,而这些方法已经被证明对很多问题有用,但他们也有一些缺点:
(1) 这些模型通常需要大量与任务相关的专业知识,例如设计HMMs的状态模型,选择CRFs的输入特征。
(2) 模型需要明显的依赖假设使得推理可行(tractable,即多项式时间内可解)的,例如HMMs的观察状态的独立性假设。
(3) 对于标准的HMMs,是生成式的训练,但是序列标注是判别式的。
循环神经网络(RNNs),不需要任何先验知识,出了输入和输出的表示之外,他们可以进行判别式训练,他们的内部状态提供了一个强有力且通用的机制为时间序列建模。另外,他们对于时间和空间的噪声都是健壮的。
现在,对于序列标注,使用RNNs的方式是让它结合HMMs构成的混合方法(hybrid approach),混合系统使用HMMs去为长序列结构(long-range sequential structure)的数据进行建模,神经网络提供局部的分类。HMMs组件可以自动在训练中切分序列,把网络分类转换成标签序列(labelsequences)。由于HMMs本身具有前述的局限性,混合系统(hybrid systems)未能完全利用RNNs的序列建模的潜能。
贡献
这篇文章提出了一个用RNNs标记序列数据的新方法,移除了预先分割训练数据和后处理输出的必要,模型只用了一个网络结构就能处理序列的所有问题。基本想法是在给定输入序列的情况下,把网络的输出作为所有可能标记序列的概率分布。给定这个分布,目标函数目标函数就可以直接得到最大概率的正确标记,目标函数是判别式的,所以这个网络可以用标准的反向传播进行训练。
Temporal Classification(时间分类)
S是一个服从一个固定分布DX*Z的训练样例集合.输入空间X=(Rm)*是一个集合所有序列的m维实数值向量.目标空间Z=L*是所有字母L的标记序列的集合。通常,我们把L*作为标记序列或者标签,每一个S中的样例由一对(x,z)序列组成.目标序列为z=(z1,z2,…,zU)最多和输入序列x=(x1,x2,…,xT)一样长,例如U<=T.因为输入序列和目标序列通常不是一样长的,所以没有任何先验的方式去对齐。
使用S去训练一个时间分类器h:X->Z的目的是分类原先未见过的输入序列,使得一些与任务相关的误差评估最小。
Label Error Rate
给定一个测试集S’⸦DX*Z, S‘和S集合不相交,定义一个时间分类h的labelerror rate(LER)为平均归一化编辑距离,编辑距离在S’上的分类和目标进行的。

ED(p,q)是序列p和q的编辑距离,即把p变为q所需要的插入,替换,删除的最少次数。
最小编辑距离的实现就是一个递归,如果读者不懂,可以自行百度了。Connectionist Temporal Classification
一个CTC网络有一个softmax输出层,出了序列的输出外,还增加了一个额外的输出单元,最开始激励的|L|个单元被解释成在这个时刻对应标签的观察概率,激励的额外的单元是一个空白的观察概率或者无标签的观察概率。这些输出定义为在给定输入序列的情况下,所有可能的对齐所有标记序列的方式。标记序列的概率是所有可能对齐方式的概率和。
更正式的讲,输入序列x,长度为T,定义一个RNN,有m个输入,n个输出,权重向量w作为一个连续映射Nw:(Rm)->(Rn)T.让y=Nw(x)为网络的序列输出,ykt是单元k在时刻t的激励。Ykt解释为时刻t标记k的观察概率,这定义了一个在集合L’T的长度为T的序列分布,L’=L+{blank}:
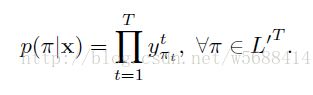
L’T的所有元素,我们成为路径,L‘T是所有路径的集合,π表示其中的一个路径。上式隐含的有一个假设,给定网络的内部状态,网络在不同时刻的输出是条件独立的。这就要求输出层没有反馈连接到他自身或者网络。
下一步是定义多到一的映射β:L’T->L<=T,L<=T是可能标记的集合。我们简单的移除所有的空白(blanks)和重复的标签。

上图是帧级(Framewise)和CTC网络分类一个语音信号,阴影线是输出激励,对应特定时刻的音素的观察概率,CTC仅仅预测音素序列(典型的一系列的尖状物(a series of spikes),用blank分开了,或者没有预测),帧级网络(framewise network)尝试和人工分割的边缘对齐(垂直的线)。帧级网络接收了一个错误的对齐边界,虽然它预测了正确的音素(dh).当一个音素一直出现并靠近另一个音素时(dcl总是以d结尾),CTC预测的是一个双尖状物(a double spike)。标记的选择可以直接从CTC的输出进行得到,而帧级网络必须经过后处理(post-processed)才能获得。
最终,β定义为一个给定序列l属于L<=T的条件概率,条件概率是所有路径的概率和。公式如下:

构造分类器
分类器的输出应该是在给定输入序列下的最可能的标记输出,

利用HMMs,我们把寻找这个标记过程记为解码,但是我们找不到一个通用并且tractable的解码算法,下面是两个近似的算法,在实践中给出了良好的结果。
第一个方法是最佳路径解码(best path decoding),基于的假设:最可能的路径会对应最可能表标签,
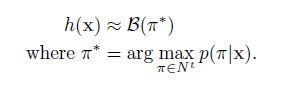
最佳路径解码非常容易计算,π*仅仅就是每个时间步的最可能输出的连接。但是它不能保证找到最有可能的标记。
第二种方法是前缀查找解码(prefix search decoding),通过修改前向后向算法(forward-backward algorithm),我们可以高效的计算出标记前缀的后继拓展的概率。
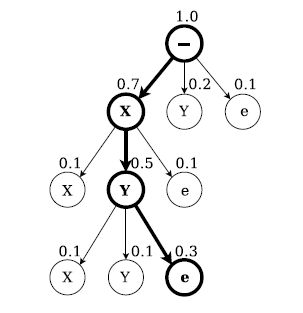
如图,前缀查找解码字母X,Y.每个节点要么以“e”结尾,要么从父节点进行拓展前缀,在每个end节点上面的数字是单个标记重点在父节点的概率(The number above an end node is the probability of the single labelling ending at its parent,翻译得云里雾里,我就直接上原文了,看图相信就会懂了),在每一次迭代中,对最可能留下前缀的拓展进行探索。当有一个标记(这里是’XY’)比其他标记的概率更大时,搜索就终止了。
一个训练的CTC网络的输出倾向于形成一系列的尖状物(spikes),尖状物被预测的blanks分隔开,我们把输出的序列分为几部分,这几个部分可能都是是以一个blank开始和结尾。我们选择边界点,这些边界点的是blank标记的观察概率超过一个给定的阈值,然后我们对每个部分计算器最可能的标记序列,然后把他们连接起来得到最终的分类。
实践中,前缀搜索在这个启发式下工作得很好,通常超过了最佳路径解码,但是在有些情况下,效果不佳,例如,当相同的标签在一个部分边界的两侧都概率很低(if the same label is
predicted weakly on both sides of a section boundary,这个我也不是很明白,直接上原文)。
网络训练
目标函数是从最大似然估计的规则中衍生出来的,即最小化log似然估计目标序列。给定目标函数,它的导数和网络输出有关,因此我们可以通过标准的反向传播计算权重梯度,网络通过任何基于梯度优化算法进行训练,
前向后向算法
我们需要一个高效的方式去计算每一个标记的条件概率p(l|x),乍一看,对一个给定标签的所有路径求和似乎有些不可能,通常,路径太多了。
这个问题可以用动态规划算法(dynamic programming algorithm)解决,类似于HMMs的前向后向算法,核心思想是对一个标记的所有路径求和可以被分解为一个迭代路径的求和,路径对应标记的前缀,这个迭代过程可以用递归的前向和后向变量高效的计算。
对于一些长度为r的序列q,用q1:p表示开始的p个符号,qr-p:r表示最后的p个符号。然后对于一个标记l,定义前向变量αt(s),表示在时刻t,l1:s的概率和。

Αt(s)可以递归的用αt-1(s)和αt-1(s-1)进行递归计算。
考虑到输出路径中海油空白(blanks),我们在每一对标签之间插入了空白,在开始和末尾也加入了空白,这样我们用l‘表示这个新的标记,l’的长度就为2|l|+1’.在计算l’前缀的概率中,我们允许空白和非空白标签之间转移,我们允许所有的前缀要么以一个空白(b)开始,要么是l(l1)的第一个标签开始.
公式如下:

加这个条件是因为这些变量对应的状态没有留下足够的时间步去完成这个序列,如下图右上角未连接的圆圈:
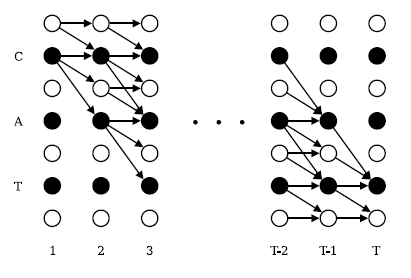
前向后向算法运用到标记‘CAT’序列的例子,黑圈代表标签(labels),白圈代表空白。箭头代表允许的转移。前向变量王箭头方向进行跟新,后向变量往箭头的反方向更新。
L的概率是l’所有概率的求和,并且去除了T时刻的最后的blank得到的。

同样,后向变量βt(s)是t时刻ls:|s|的概率和,

实际上,上面的递归将会迅速导致任何电脑的下溢,因此,我们需要变换一下。用α^代替α,用β^代替β

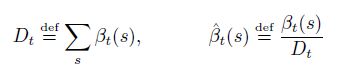
为了评估最大似然误差,我们需要用到自然对数。

极大似然训练(一大波公式来袭,不过按照它的推导 也很容易)
训练的目标是同时最大化训练集上所有正确分类的log概率,意味着优化下式:

为了用梯度下降训练网络,我们需要就网络输出进行微分(differentiate),训练样例是独立地,我们可以单独来考虑

我们可以用前向后向算法计算上式。主要思想是:对于一个标记l,在给定s和t的情况下,前向和后向变量的内积是对应l所有可能路径的概率。表达式为:
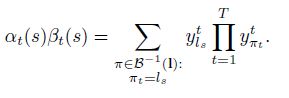
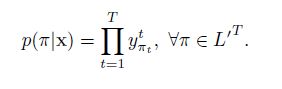
因此由上式我们可以得出:


由上述式子可以看出,提示是p(l|x)的概率,由于这些路径经过了Ls和时刻t,我们可以求所有的s和t得出:
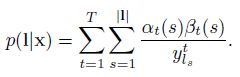
由于网络的输出是条件独立的,我们需要考虑路径在时刻t经过标记k,得到p(l|t)的偏导数,这是杜宇ykt而言的,注意到相同的标签肯能会重复几次再一个标记l中,我们定义了一个位置集合,标签k出现,记为lab(l,k)={s:ls=k},它可能是空的。我们然后去求微分(differentiate)
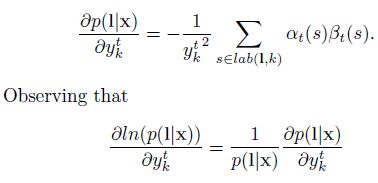
当l=z时,我们可以利用前面的公式推导(很简单,我刚刚把论文的几个公式一摆,然后求个导就变成这个样子,具体细节就不说了,跟着论文的公式进行推导即可)推导成这个式子。
最后,对于softmax层的反向传播的梯度,我们需要对未归一化的输出ukt的目标函数进行推导。
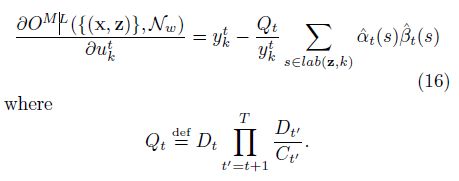
公式16是网络训练期间的误差信号“errorsignal”如下图

这是训练期间CTC误差信号的评估,左边的一列是训练不同阶段同一个序列的输出激励(虚线是blank单元),右边一列与之对应的是误差信号,误差在水平轴上增加了与之对应的输出激励,在水平轴下面的代表减少了与之对应的输出激励。(a)一开始网络有少量的随机权重,误差仅由目标序列决定。(b)网络开始做预测,错误开始呈现局部化。(c)网络强烈的预测正确的标签,错误几乎消失了。
实验结果

数据集是TIMIT,CTC和混合的结果是5次运行的均值,+-标准差,所有的差别是明显的,除了BLSTM/HMM的权重误差和CTC(Best path)。声音数据是经过预处理的10ms的帧,滑动窗口移动时,覆盖前面的5ms,使用12 Mel-Frequency Cepstrum Coefficients(MFCCS),log-energy也包含所有协方差的一阶导数,每帧26个系数(coefficients)的向量。训这些系数归一化为均值为0,标准差为1.
CTC网络使用了一个拓展的BLSTM结构,100个块在每个前向和后向隐层,输入与输出cell的函数是双曲正切激励函数(hyperbolic tangent),和门(gates)是一个[0,1]范围的sigmoid的激励函数。
隐含层是全连接他们自身和输出层,隐藏层也和输入层全连接。输入层大小是26,softmax的输出大小是62,61个音素和1个blank标签,权重的大小为114662.训练用了反向传播算法,SGD,SGD的学习率为10^-4,momentum设置的是0.9。网络激励在开始训练每一个训练样例时被重置为0.对于前缀搜索解码,blank的概率阈值设为99.99%,权重使用均匀分布[-0.1,0.1]初始化。训练期间,输入的时候加入了高斯噪声,高斯噪声的标准差为0.6,以增加网络的泛化能力。
其它比较模型的参数详情见原文。
单词
Differentiate 表明…间的差别,构成…间差别的特征; [数学] 求…的微分:计算导数或(函数的)微分;
Derivatives 衍生性金融商品; 派生物,引出物( derivative的名词复数 ); 导数;
Dashed 虚线;
参考文献
[1] Alex Graves, Santiago Fernández,Faustino J. Gomez, Jürgen Schmidhuber:
Connectionist temporal classification:labelling unsegmented sequence data with recurrent neural networks. ICML 2006:369-376
[2] 论文笔记:CTC.http://blog.csdn.net/lebula/article/details/53118543