cv::cuda与CUDA的NPP库、距离变换和分水岭并行版本尝试
因为不想什么函数都自己写设备核函数,看到opencv有对应的cuda版本的函数比如滤波,然而CUDA的NPP库也提供了对应的滤波函数,我不知道哪个性能更高(当然肯定要比纯CPU版本快,但我没测试过)
一、cv::cuda
#include
#include
#include
#include
#include
#include
#include
#define SIZE 25
int main()
{
cv::Mat ImageHost = cv::imread("E:\\CUDA\\imgs\\cv_cuda_testimg.png", cv::IMREAD_GRAYSCALE);
cv::Mat ImageHostArr[SIZE];
cv::cuda::GpuMat ImageDev;
cv::cuda::GpuMat ImageDevArr[SIZE];
ImageDev.upload(ImageHost);
for (int n = 1; n < SIZE; n++)
cv::resize(ImageHost, ImageHostArr[n], cv::Size(), 0.5*n, 0.5*n, cv::INTER_LINEAR);
for (int n = 1; n < SIZE; n++)
cv::cuda::resize(ImageDev, ImageDevArr[n], cv::Size(), 0.5*n, 0.5*n, cv::INTER_LINEAR);
cv::Mat Detected_EdgesHost[SIZE];
cv::cuda::GpuMat Detected_EdgesDev[SIZE];
std::ofstream File1, File2;
File1.open("E:\\CUDA\\imgs\\canny_cpu.txt");
File2.open("E:\\CUDA\\imgs\\canny_gpu.txt");
std::cout << "Process started... \n" << std::endl;
for (int n = 1; n < SIZE; n++) {
auto start = std::chrono::high_resolution_clock::now();
cv::Canny(ImageHostArr[n], Detected_EdgesHost[n], 2.0, 100.0, 3, false);
auto finish = std::chrono::high_resolution_clock::now();
std::chrono::duration elapsed_time = finish - start;
File1 << "Image Size: " << ImageHostArr[n].rows* ImageHostArr[n].cols << " " << "Elapsed Time: " << elapsed_time.count() * 1000 << " msecs" << "\n" << std::endl;
}
cv::Ptr canny_edg = cv::cuda::createCannyEdgeDetector(2.0, 100.0, 3, false);
for (int n = 1; n < SIZE; n++) {
auto start = std::chrono::high_resolution_clock::now();
canny_edg->detect(ImageDevArr[n], Detected_EdgesDev[n]);
auto finish = std::chrono::high_resolution_clock::now();
std::chrono::duration elapsed_time = finish - start;
File2 << "Image Size: " << ImageDevArr[n].rows* ImageDevArr[n].cols << " " << "Elapsed Time: " << elapsed_time.count() * 1000 << " msecs" << "\n" << std::endl;
}
std::cout << "Process ended... \n" << std::endl;
return 0;
} 我的电脑测出来:
Image Size: 49476 CPU Elapsed Time: 13.9905 msecs
Image Size: 198170 CPU Elapsed Time: 38.4235 msecs
Image Size: 446082 CPU Elapsed Time: 71.059 msecs
Image Size: 792680 CPU Elapsed Time: 103.162 msecs
Image Size: 1238230 CPU Elapsed Time: 141.263 msecs
Image Size: 1783530 CPU Elapsed Time: 165.636 msecs
Image Size: 2428048 CPU Elapsed Time: 195.356 msecs
Image Size: 3170720 CPU Elapsed Time: 246.407 msecs
Image Size: 4012344 CPU Elapsed Time: 300.643 msecs
Image Size: 4954250 CPU Elapsed Time: 334.725 msecs
Image Size: 5995374 CPU Elapsed Time: 367.368 msecs
Image Size: 7134120 CPU Elapsed Time: 422.822 msecs
Image Size: 8371818 CPU Elapsed Time: 468.351 msecs
Image Size: 9710330 CPU Elapsed Time: 546.653 msecs
Image Size: 11148060 CPU Elapsed Time: 589.476 msecs
Image Size: 12682880 CPU Elapsed Time: 617.778 msecs
Image Size: 14316652 CPU Elapsed Time: 682.61 msecs
Image Size: 16051770 CPU Elapsed Time: 784.524 msecs
Image Size: 17886106 CPU Elapsed Time: 802.988 msecs
Image Size: 19817000 CPU Elapsed Time: 829.102 msecs
Image Size: 21846846 CPU Elapsed Time: 912.721 msecs
Image Size: 23978570 CPU Elapsed Time: 954.053 msecs
Image Size: 26209512 CPU Elapsed Time: 978.438 msecs
Image Size: 28536480 CPU Elapsed Time: 1045.46 msecsImage Size: 49476 GPU Elapsed Time: 1.8581 msecs
Image Size: 198170 GPU Elapsed Time: 2.1446 msecs
Image Size: 446082 GPU Elapsed Time: 3.8053 msecs
Image Size: 792680 GPU Elapsed Time: 4.8882 msecs
Image Size: 1238230 GPU Elapsed Time: 5.9607 msecs
Image Size: 1783530 GPU Elapsed Time: 6.7705 msecs
Image Size: 2428048 GPU Elapsed Time: 7.3428 msecs
Image Size: 3170720 GPU Elapsed Time: 8.3768 msecs
Image Size: 4012344 GPU Elapsed Time: 9.8166 msecs
Image Size: 4954250 GPU Elapsed Time: 12.5099 msecs
Image Size: 5995374 GPU Elapsed Time: 14.9313 msecs
Image Size: 7134120 GPU Elapsed Time: 17.6367 msecs
Image Size: 8371818 GPU Elapsed Time: 20.3713 msecs
Image Size: 9710330 GPU Elapsed Time: 23.8835 msecs
Image Size: 11148060 GPU Elapsed Time: 25.3751 msecs
Image Size: 12682880 GPU Elapsed Time: 28.7937 msecs
Image Size: 14316652 GPU Elapsed Time: 31.7389 msecs
Image Size: 16051770 GPU Elapsed Time: 35.7431 msecs
Image Size: 17886106 GPU Elapsed Time: 38.3026 msecs
Image Size: 19817000 GPU Elapsed Time: 39.8344 msecs
Image Size: 21846846 GPU Elapsed Time: 43.0583 msecs
Image Size: 23978570 GPU Elapsed Time: 45.6539 msecs
Image Size: 26209512 GPU Elapsed Time: 54.4576 msecs
Image Size: 28536480 GPU Elapsed Time: 49.9312 msecscv::cuda比cv::竟然快这么多?!把两个函数放一起:
std::cout << "Process started... \n" << std::endl;
for (int n = 1; n < SIZE; n++) {
auto start = std::chrono::high_resolution_clock::now();
cv::resize(ImageHost, ImageHostArr[n], cv::Size(), 0.5*n, 0.5*n, cv::INTER_LINEAR);
cv::Canny(ImageHostArr[n], Detected_EdgesHost[n], 2.0, 100.0, 3, false);
auto finish = std::chrono::high_resolution_clock::now();
std::chrono::duration elapsed_time = finish - start;
File1 << "Image Size: " << ImageHostArr[n].rows* ImageHostArr[n].cols << " " << "CPU Elapsed Time: " << elapsed_time.count() * 1000 << " msecs" << "\n" << std::endl;
}
cv::Ptr canny_edg = cv::cuda::createCannyEdgeDetector(2.0, 100.0, 3, false);
for (int n = 1; n < SIZE; n++) {
auto start = std::chrono::high_resolution_clock::now();
cv::cuda::resize(ImageDev, ImageDevArr[n], cv::Size(), 0.5*n, 0.5*n, cv::INTER_LINEAR);
canny_edg->detect(ImageDevArr[n], Detected_EdgesDev[n]);
auto finish = std::chrono::high_resolution_clock::now();
std::chrono::duration elapsed_time = finish - start;
File2 << "Image Size: " << ImageDevArr[n].rows* ImageDevArr[n].cols << " " << "GPU Elapsed Time: " << elapsed_time.count() * 1000 << " msecs" << "\n" << std::endl;
}
std::cout << "Process ended... \n" << std::endl; Image Size: 49476 GPU Elapsed Time: 1.5971 msecs
Image Size: 198170 GPU Elapsed Time: 2.1869 msecs
Image Size: 446082 GPU Elapsed Time: 3.9316 msecs
Image Size: 792680 GPU Elapsed Time: 5.8947 msecs
Image Size: 1238230 GPU Elapsed Time: 6.8415 msecs
Image Size: 1783530 GPU Elapsed Time: 7.8679 msecs
Image Size: 2428048 GPU Elapsed Time: 8.4011 msecs
Image Size: 3170720 GPU Elapsed Time: 9.5377 msecs
Image Size: 4012344 GPU Elapsed Time: 11.3635 msecs
Image Size: 4954250 GPU Elapsed Time: 13.3181 msecs
Image Size: 5995374 GPU Elapsed Time: 16.5964 msecs
Image Size: 7134120 GPU Elapsed Time: 19.9122 msecs
Image Size: 8371818 GPU Elapsed Time: 22.7916 msecs
Image Size: 9710330 GPU Elapsed Time: 25.1661 msecs
Image Size: 11148060 GPU Elapsed Time: 28.3689 msecs
Image Size: 12682880 GPU Elapsed Time: 31.6261 msecs
Image Size: 14316652 GPU Elapsed Time: 34.7694 msecs
Image Size: 16051770 GPU Elapsed Time: 37.7313 msecs
Image Size: 17886106 GPU Elapsed Time: 39.5111 msecs
Image Size: 19817000 GPU Elapsed Time: 43.407 msecs
Image Size: 21846846 GPU Elapsed Time: 46.8648 msecs
Image Size: 23978570 GPU Elapsed Time: 47.9306 msecs
Image Size: 26209512 GPU Elapsed Time: 50.2719 msecs
Image Size: 28536480 GPU Elapsed Time: 53.922 msecsImage Size: 49476 CPU Elapsed Time: 16.4558 msecs
Image Size: 198170 CPU Elapsed Time: 40.3942 msecs
Image Size: 446082 CPU Elapsed Time: 77.8448 msecs
Image Size: 792680 CPU Elapsed Time: 110.313 msecs
Image Size: 1238230 CPU Elapsed Time: 143.571 msecs
Image Size: 1783530 CPU Elapsed Time: 183.128 msecs
Image Size: 2428048 CPU Elapsed Time: 218.107 msecs
Image Size: 3170720 CPU Elapsed Time: 256.128 msecs
Image Size: 4012344 CPU Elapsed Time: 305.7 msecs
Image Size: 4954250 CPU Elapsed Time: 370.511 msecs
Image Size: 5995374 CPU Elapsed Time: 410.728 msecs
Image Size: 7134120 CPU Elapsed Time: 458.635 msecs
Image Size: 8371818 CPU Elapsed Time: 511.283 msecs
Image Size: 9710330 CPU Elapsed Time: 619.209 msecs
Image Size: 11148060 CPU Elapsed Time: 652.386 msecs
Image Size: 12682880 CPU Elapsed Time: 691.799 msecs
Image Size: 14316652 CPU Elapsed Time: 768.322 msecs
Image Size: 16051770 CPU Elapsed Time: 880.751 msecs
Image Size: 17886106 CPU Elapsed Time: 900.914 msecs
Image Size: 19817000 CPU Elapsed Time: 980.022 msecs
Image Size: 21846846 CPU Elapsed Time: 1037.32 msecs
Image Size: 23978570 CPU Elapsed Time: 1115.81 msecs
Image Size: 26209512 CPU Elapsed Time: 1123.15 msecs
Image Size: 28536480 CPU Elapsed Time: 1226.08 msecs依旧是快很多的。但是不好意思发现算上cv::Mat与cv::cuda::gpuMat之间的上传下载,如果只处理几张图片,cv::cuda总体是慢的:
int main()
{
cv::Mat ImageHost = cv::imread("E:\\CUDA\\imgs\\cv_cuda_testimg.png", cv::IMREAD_GRAYSCALE);
cv::Mat ImageHostArr[SIZE];
cv::Mat Detected_EdgesHost[SIZE];
std::ofstream File1, File2;
File1.open("E:\\CUDA\\imgs\\canny_cpu.txt");
File2.open("E:\\CUDA\\imgs\\canny_gpu.txt");
std::cout << "Process started... \n" << std::endl;
for (int n = 1; n elapsed_time = finish - start;
File1 << "Image Size: " << ImageHostArr[n].rows* ImageHostArr[n].cols << " " << "CPU Elapsed Time: " << elapsed_time.count() * 1000 << " msecs" << "\n" << std::endl;
}
auto start2 = std::chrono::high_resolution_clock::now();
cv::cuda::GpuMat ImageDev;
cv::cuda::GpuMat ImageDevArr[SIZE];
ImageDev.upload(ImageHost);
cv::cuda::GpuMat Detected_EdgesDev[SIZE];
cv::Mat gpuresult[SIZE];
auto finish2 = std::chrono::high_resolution_clock::now();
std::chrono::duration elapsed_time2 = finish2 - start2;
File2 << "GPU Elapsed Time: " << elapsed_time2.count() * 1000 << " msecs" << "\n" << std::endl;
cv::Ptr canny_edg = cv::cuda::createCannyEdgeDetector(2.0, 100.0, 3, false);
for (int n = 1; n detect(ImageDevArr[n], Detected_EdgesDev[n]);
(Detected_EdgesDev[n]).download(gpuresult[n]);
auto finish = std::chrono::high_resolution_clock::now();
std::chrono::duration elapsed_time = finish - start;
File2 << "Image Size: " << ImageDevArr[n].rows* ImageDevArr[n].cols << " " << "GPU Elapsed Time: " << elapsed_time.count() * 1000 << " msecs" << "\n" << std::endl;
}
std::cout << "Process ended... \n" << std::endl;
return 0;
} 看结果上传花了很多时间:
CPU Elapsed Time: 16.2129 msecsGPU Elapsed Time: 827.039 msecs
Image Size: 49476 GPU Elapsed Time: 1.3695 msecs所以如果后续只处理一两张图,那就得不偿失了。所以网上有人建议要使用cv::cuda,最好cv::Mat与cv::cuda::gpuMat之间只转换一次,而不要频繁的转来转去,否则cv::cuda函数节约下来的时间赶不上转换消耗的时间,那总体就慢了。
Image Size: 49476 CPU Elapsed Time: 16.5117 msecs
Image Size: 198170 CPU Elapsed Time: 40.3025 msecs
Image Size: 446082 CPU Elapsed Time: 81.2121 msecs
Image Size: 792680 CPU Elapsed Time: 110.101 msecs
Image Size: 1238230 CPU Elapsed Time: 148.415 msecs
Image Size: 1783530 CPU Elapsed Time: 186.113 msecs
Image Size: 2428048 CPU Elapsed Time: 228.306 msecs
Image Size: 3170720 CPU Elapsed Time: 261.014 msecs
Image Size: 4012344 CPU Elapsed Time: 316.615 msecs
Image Size: 4954250 CPU Elapsed Time: 363.326 msecs
Image Size: 5995374 CPU Elapsed Time: 410.894 msecs
Image Size: 7134120 CPU Elapsed Time: 479.375 msecs
Image Size: 8371818 CPU Elapsed Time: 509.868 msecs
Image Size: 9710330 CPU Elapsed Time: 596.871 msecsGPU Elapsed Time: 811.702 msecs
Image Size: 49476 GPU Elapsed Time: 1.5237 msecs
Image Size: 198170 GPU Elapsed Time: 2.2596 msecs
Image Size: 446082 GPU Elapsed Time: 3.7014 msecs
Image Size: 792680 GPU Elapsed Time: 5.3606 msecs
Image Size: 1238230 GPU Elapsed Time: 6.7137 msecs
Image Size: 1783530 GPU Elapsed Time: 7.9725 msecs
Image Size: 2428048 GPU Elapsed Time: 9.5008 msecs
Image Size: 3170720 GPU Elapsed Time: 11.3495 msecs
Image Size: 4012344 GPU Elapsed Time: 13.556 msecs
Image Size: 4954250 GPU Elapsed Time: 16.0509 msecs
Image Size: 5995374 GPU Elapsed Time: 19.5233 msecs
Image Size: 7134120 GPU Elapsed Time: 22.7719 msecs
Image Size: 8371818 GPU Elapsed Time: 26.4892 msecs
Image Size: 9710330 GPU Elapsed Time: 28.1691 msecs我觉得cv::cuda真的只适合一次上传下载,然后很多很多函数处理或者是很多张图片的很多操作,这种情况。

的确是这样。
二、cuda提供的NPP库
暂时放弃
三、距离变换distanceTransform的CUDA版本
1、先直接用2020外文中提供的最优的JFA的距离变换方法,话说jump flood algorithmn这个算法为什么在中国网站里没介绍,搜都搜不到原理,因为看外文的还有点小地方不怎么理解,就是我没注释的第一个函数中。
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include "helper_math.h"
#include "book.h"
#include
#include
#include
#include
#include
#include
#include
#include
struct ipoint { int x, y; };
struct fpoint { float x, y; };
struct uipoint { unsigned int x, y; };
struct stack { unsigned int top, bot; };
/*这个部分涉及到jump flood算法原理(JFA),没懂
input:g---当前邻域点位置的水平、垂直方向的梯度幅值
或邻域点与中心点的横坐标、纵坐标位置差
a---原图在当前邻域点位置><=0.0的判断
*/
__device__ float edgedf(fpoint g, float a)
{
float df, glength, temp, al;
if ((g.x == 0) || (g.y == 0))
{
//此邻域点是背景点
//此邻域点在中心点的正上、正下、正左、正右位置
df = 0.5 - a;
}
else
{
//此邻域点是目标点
//此邻域点在中心点的斜对角位置
glength = sqrtf(g.x*g.x + g.y*g.y);
if (glength > 0)
{
g.x = g.x / glength;
g.y = g.y / glength;
}
g.x = fabs(g.x);
g.y = fabs(g.y);
if (g.x < g.y)
{
temp = g.x;
g.x = g.y;
g.y = temp;
}
al = 0.5f*g.y / g.x;
if (a < al)
{
df = 0.5f*(g.x + g.y) - sqrt(2.0f*g.x*g.y*a);
}
else if (a < (1.0f - al))
{
df = (0.5f - a)*g.x;
}
else
{
df = -0.5f*(g.x + g.y) + sqrt(2.0f*g.x*g.y*(1.0f - a));
}
}
return df;
}
/*
input:from-----当前中心像素点位置
to-------当前邻域点位置
grad-----当前邻域点位置的梯度幅值
img------设备原图
imgSize--设备原图尺寸
return :计算当前邻域点到中心点的XX距离(位置距离+另一种距离(涉及JFA原理))
*/
__device__ float dist(ipoint from, ipoint to, fpoint grad, uchar* img, uipoint imgSize)
{
//再次判断当前邻域点位置是否为背景点
if (to.x < 0 || to.y < 0)
return imgSize.x*3.0f;
/*计算原图在此邻域点位置的像素值
*/
int id = to.y*imgSize.x + to.x;
float a = img[id];
if (a > 1) a = 1.0f;//若是目标点,其实按道理此时只可能是这种
if (a < 0) a = 0.0f;//原图不可能有小于0的像素值??
if (a == 0) return imgSize.x*3.0f;//原图在邻域点是背景
//计算邻域点与当前中心点的距离
float dx = to.x - from.x;
float dy = to.y - from.y;
float di = sqrtf(dx*dx + dy*dy);
float df;
if (di == 0.0f)
{
//当前邻域点就是中心点
df = fmaxf(edgedf(grad, a), 0.0f);
}
else
{
//另8个邻域点
df = edgedf({ dx,dy }, a);
}
return di + df;
}
/*计算梯度图像grad和标记背景位置图closest
input:img---------需要计算的图像
imgSize-----图像尺寸
output:closest----把背景区域置-1
grad-------梯度图像,背景区域的梯度为0,目标区域梯度幅值计算并归一化
*/
__global__ void setup(ipoint *closest, fpoint *grad, uchar *img, uipoint imgSize)
{
int idx = blockIdx.x*blockDim.x + threadIdx.x;
int idy = blockIdx.y*blockDim.y + threadIdx.y;
int id = idy*imgSize.x + idx;
#define SQRT2 1.4142136f
if (img[id] > 0.0f)
{
closest[id].x = idx;
closest[id].y = idy;
if (idx > 0 && idx < imgSize.x - 1 && idy>0 && idy < imgSize.y - 1)
{
grad[id].x = -img[id - imgSize.x - 1] - SQRT2*img[id - 1] - img[id + imgSize.x - 1] + img[id - imgSize.x + 1]
+ SQRT2*img[id + 1] + img[id + imgSize.x + 1];
grad[id].y = -img[id - imgSize.x - 1] - SQRT2*img[id - imgSize.x] - img[id - imgSize.x + 1] + img[id + imgSize.x - 1]
+ SQRT2*img[id + imgSize.x] + img[id + imgSize.x + 1];
float g = grad[id].x*grad[id].x + grad[id].y*grad[id].y;
if (g > 0.0f)
{
g = sqrtf(g);
grad[id].x /= g;
grad[id].y /= g;
}
}
else
{
grad[id].x = 0;
grad[id].y = 0;
}
}
else
{
closest[id].x = -1;
closest[id].y = -1;
grad[id].x = 0;
grad[id].y = 0;
}
}
/*
input:closest----背景区域位置标记图
grad-------梯度幅值图
img--------设备原图
imgSize----设备原图尺寸
stepSize---设备原图列位置
output:voronoi---XX距离图像对应的位置图像
out-------XX距离图像
*/
__global__ void propagateSites(ipoint *closest, ipoint *voronoi, fpoint *grad, uchar *img,
float *out, uipoint imgSize, int stepSize)
{
int idx = blockIdx.x*blockDim.x + threadIdx.x;
int idy = blockIdx.y*blockDim.y + threadIdx.y;
int id = idy*imgSize.x + idx;
//以当前点位置为中心,上下左右斜对角stepSize距离的点位置,共9个邻域点
ipoint neighbors[9] = { { idx - stepSize,idy + stepSize },{ idx,idy + stepSize },
{ idx + stepSize,idy + stepSize },{ idx - stepSize,idy },{ idx,idy },{ idx + stepSize,idy },
{ idx - stepSize,idy - stepSize },{ idx,idy - stepSize },{ idx + stepSize,idy - stepSize }
};
//因为在图像内,所以不可能有距离值大于3倍图像尺寸
float bestDist = imgSize.x*3.0f;
ipoint bestSite = { -1,-1 };
//针对当前中心点,计算9个邻域点中XX距离最小的为此中心点最终的XX距离
//并把此中心点XX距离最小的邻域点的位置标记下来
for (int i = 0; i < 9; ++i)
{
ipoint n = neighbors[i];
//如果邻域点位置无效,则忽略,即超出了图像实际像素点的位置范围
if (n.x >= imgSize.x || n.x < 0 || n.y >= imgSize.y || n.y < 0) continue;
//查看这个邻域点位置是背景点还是目标点,-1代表背景
ipoint nSite = closest[n.x + n.y*imgSize.x];
/*如果这个点是背景点,那么就赋值为一个不可能达到的非常大的距离值imgSize.x*3.0f
如果这个点是目标点,就计算此邻域点与中心点的XX距离
*/
float newDist = (nSite.x < 0) ? imgSize.x*3.0f : dist({ idx,idy },
nSite, grad[nSite.x + nSite.y*imgSize.x], img, imgSize);
if (newDist < bestDist)
{
bestDist = newDist;
bestSite = nSite;
}
}
////针对当前中心点,计算9个邻域点中XX距离最小的为此中心点最终的XX距离
voronoi[id] = bestSite;
out[id] = bestDist;
}
/*
input:img----输入图像
size---输入图像的长宽
output:edt---距离变换后的图像
*/
void JFA(float *edt, uchar *img, uipoint size)
{
uchar *dev_img = 0;
fpoint *dev_grad = 0;
float *dev_edt = 0;
ipoint *dev_closest = 0;
ipoint *dev_voronoi = 0;
cudaEvent_t start, stop;
HANDLE_ERROR(cudaEventCreate(&start));
HANDLE_ERROR(cudaEventCreate(&stop));
HANDLE_ERROR(cudaEventRecord(start, 0));
cudaSetDevice(0);
cudaMalloc((void**)&dev_grad, size.x*size.y * sizeof(fpoint));
cudaMalloc((void**)&dev_edt, size.x*size.y * sizeof(float));
cudaMalloc((void**)&dev_closest, size.x*size.y * sizeof(ipoint));
cudaMalloc((void**)&dev_voronoi, size.x*size.y * sizeof(ipoint));
//为原图在device上分配空间,将数据拷贝到设备全局 1~2ms
cudaMalloc((void**)&dev_img, size.x*size.y * sizeof(uchar));
cudaMemcpy(dev_img, img, size.x*size.y * sizeof(uchar), cudaMemcpyHostToDevice);
dim3 block = { 8,8 };
dim3 grid = { size.x / 8,size.y / 8 };
//计算得到归一化的梯度幅值图像dev_grad和标记背景位置图dev_closest
setup << > >(dev_closest, dev_grad, dev_img, size);
cudaDeviceSynchronize();
for (int i = size.x / 2; i > 0; i /= 2)
{
//计算以i为间隔,每个像素点的XX距离图以及最新的位置标记图
propagateSites << > >(dev_closest, dev_voronoi, dev_grad, dev_img,
dev_edt, size, i);
/*将上次的背景区域位置标记图dev_closest与刚刚核函数得到的
XX距离图像对应的位置图像dev_voronoi交换,即更新背景区域位置标记图
*/
ipoint *tmp = dev_closest;
dev_closest = dev_voronoi;
dev_voronoi = tmp;
cudaDeviceSynchronize();
}
cudaMemcpy(edt, dev_edt, size.x*size.y * sizeof(float), cudaMemcpyDeviceToHost);
HANDLE_ERROR(cudaEventRecord(stop, 0));
HANDLE_ERROR(cudaEventSynchronize(stop));
float elapsedTime;
HANDLE_ERROR(cudaEventElapsedTime(&elapsedTime, start, stop));
printf("Time on GPU: %3.1f ms\n", elapsedTime);
HANDLE_ERROR(cudaEventDestroy(start));
HANDLE_ERROR(cudaEventDestroy(stop));
cudaFree(dev_closest);
cudaFree(dev_grad);
cudaFree(dev_img);
cudaFree(dev_edt);
cudaFree(dev_voronoi);
return;
}
int main()
{
char srclowfolder[400] = { 0 };
for (int index = 0; index <= 56; index++)
{
sprintf(srclowfolder, "E:\\CUDA\\imgs\\jinxinginput\\101\\%d_lowbw.jpg", index);
cv::Mat low_binary_A = cv::imread(srclowfolder, cv::IMREAD_UNCHANGED);
/*
auto cpustart = std::chrono::high_resolution_clock::now();
cv::Mat dist_image;
distanceTransform(low_binary_A, dist_image, cv::DIST_L2, 3);
auto cpufinish = std::chrono::high_resolution_clock::now();
std::chrono::duration elapsed_time = cpufinish - cpustart;
std::cout << "CPU distanceTransform Elapsed Time: " << elapsed_time.count() * 1000 << " ms" << "\n" << std::endl;
*/
float *dist_image_gpu=0;
uipoint imgrealsize;
imgrealsize.x = low_binary_A.cols;
imgrealsize.y = low_binary_A.rows;
JFA(dist_image_gpu, low_binary_A.data, imgrealsize);
}
return 0;
} 我对比了一下,纯CPU版本的distanceTransform耗时是2~3ms,而CUDA版本竟然要100+ms!!!我看了下,主要是for里面对整幅图每次以像素点stepsize附近9个邻域点求距离最小值,stepsize越来越小,所有点的计算量越来越大
。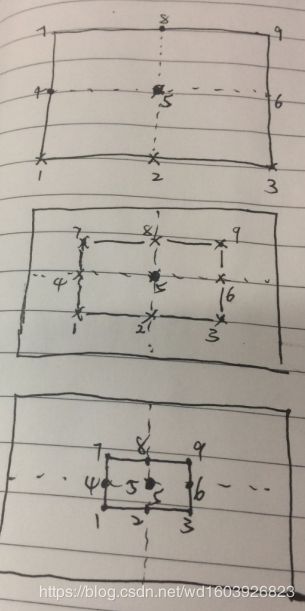 很好理解,以图像中央像素点为例,第一次时是由这9个邻域点计算出最小距离,并相当于将最小距离赋值给中央像素点;第二次时又计算新的9个邻域点的最小距离....可以看到当stepsize很大时,有的点也许实际只用算2、3、4...个点,并不用算满9个点。所以for后面的时间会比前一次for更长。
很好理解,以图像中央像素点为例,第一次时是由这9个邻域点计算出最小距离,并相当于将最小距离赋值给中央像素点;第二次时又计算新的9个邻域点的最小距离....可以看到当stepsize很大时,有的点也许实际只用算2、3、4...个点,并不用算满9个点。所以for后面的时间会比前一次for更长。
我以为论文上的就是最优的,可是比cv::distanceTransform长太多了。我其实很想查到cv::distanceTransform详细的原理,然后自己写核函数。
2、按照https://www.cnblogs.com/yrm1160029237/p/11937744.html 中介绍的原理自己实现
找了几个理论:https://blog.csdn.net/weixin_44128918/article/details/103754674?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase 其实就是第一遍是走正Z字形,从左上角扫描到右下角,比较每个像素左、上点中的最小值点,加上自身像素值;第二遍走倒Z字形,从右下角扫描到左上,比较每个像素右、下点中的最小值,加上自身像素值;比较这两次扫描的最小值作为最终的distanceTranceform的结果(此种不是float)

开始时我想这样设计,分析发现依赖很严重。后来想换一种依赖不这么严重的方式: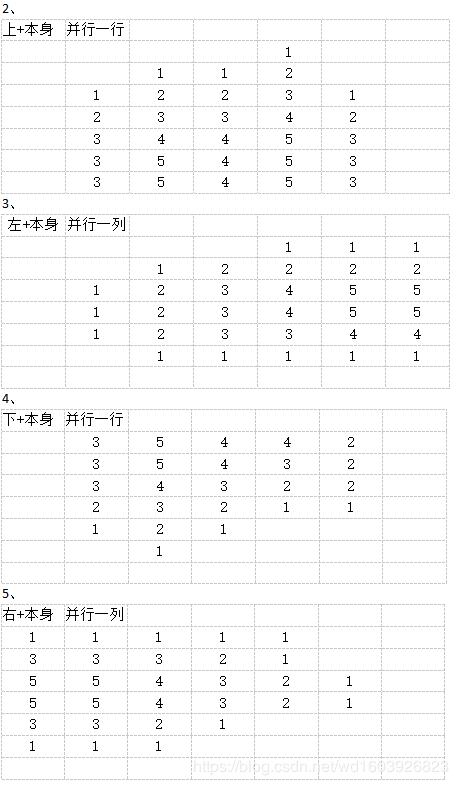 这种方式与上一种严格按原理来的那种方式结果一致。但是我测试了一下,这个版本距离变换CUDA总时间基本是3.3ms,也就是比CPU版本还是慢了近1ms。然后我测试了只计算核函数的时间是2.5ms,比CPU版本快。因为这是我设计的第一版,然后图像是500x1216,图像大一些按这个思路应该会比CPU快得更明显,而且我还没有使用纹理内存以及CUDA调度方式边复制变执行kernel,我觉得优化一下更快。刚刚又尝试了下这个优化方向,但是我之前配置时以为不用opengl相关的,就没编译,所以使用不了纹理内存...........
这种方式与上一种严格按原理来的那种方式结果一致。但是我测试了一下,这个版本距离变换CUDA总时间基本是3.3ms,也就是比CPU版本还是慢了近1ms。然后我测试了只计算核函数的时间是2.5ms,比CPU版本快。因为这是我设计的第一版,然后图像是500x1216,图像大一些按这个思路应该会比CPU快得更明显,而且我还没有使用纹理内存以及CUDA调度方式边复制变执行kernel,我觉得优化一下更快。刚刚又尝试了下这个优化方向,但是我之前配置时以为不用opengl相关的,就没编译,所以使用不了纹理内存...........
因为还有一个膨胀函数也要放到GPU上,我测试了一下,CPU版本distanceTransform+dilate耗时是:
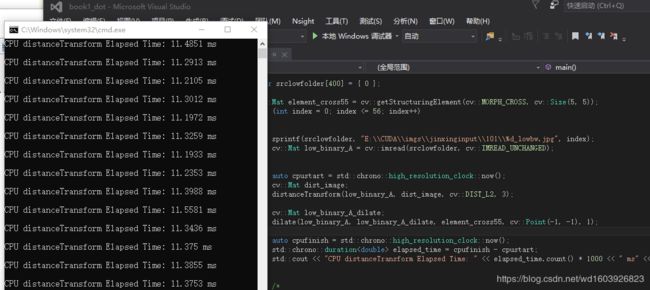
然后GPU版本distanceTransform+dilate的耗时是如下

这么看这个未优化版本已经开始呈现优势了。
不好意思,上面的距离变换的原理有误,所以出来数据不对。然后我又重新按照这个C++版本:
float Distance(int x1, int y1, int x2, int y2)
{
return sqrt(float((x2 - x1)*(x2 - x1) + (y2 - y1)*(y2 - y1)));
}
void cpu_dt(cv::Mat input, cv::Mat &output)
{
cv::Mat BinaryImage = input;
uchar *pRowOne;
uchar *pRowNext;
float distance;
float Mindis;
for (int i = 1; i <= BinaryImage.rows - 2; i++)
{
pRowOne = BinaryImage.ptr(i);
for (int j = 1; j <= BinaryImage.cols-1; j++)
{
pRowNext = BinaryImage.ptr(i - 1);
distance = Distance(i, j, i - 1, j - 1);//q1
Mindis = min((float)pRowOne[j], distance + pRowNext[j -1]);
distance = Distance(i, j, i -1, j);//q2
Mindis = min(Mindis, distance + pRowNext[j]);
pRowNext = BinaryImage.ptr(i);
distance = Distance(i, j, i, j -1);//q3
Mindis = min(Mindis, distance + pRowNext[j]);
pRowNext = BinaryImage.ptr(i + 1);//q4
distance = Distance(i, j, i + 1, j - 1);
Mindis = min(Mindis, distance + pRowNext[j - 1]);
pRowOne[j] = (uchar)round(Mindis);
}
}
for(int i = BinaryImage.rows -2; i > 0; i--)
{
pRowOne = BinaryImage.ptr(i);
for(int j = BinaryImage.cols -2; j > 0;j--)
{
pRowNext = BinaryImage.ptr( i + 1);
distance = Distance(i, j, i + 1, j);//q1
Mindis = min((float)pRowOne[j], distance + pRowNext[j]);
distance = Distance(i, j, i + 1, j + 1 );//q2
Mindis = min(Mindis, distance + pRowNext[j + 1]);
pRowNext = BinaryImage.ptr(i);//q3
distance = Distance(i, j, i, j + 1);
Mindis = min(Mindis, distance + pRowNext[j + 1]);
pRowNext = BinaryImage.ptr(i - 1);//q4
distance = Distance(i, j, i -1, j + 1);
Mindis = min(Mindis, distance + pRowNext[j + 1]);
pRowOne[j] = (uchar)round(Mindis);
}
}
output = BinaryImage;
}
//:https ://blog.csdn.net/qinzihangxj/article/details/105601108 实际这个版本也不完全对,因为与opencv的distanceTransform还是有差别 然后我又按另一个原理写了一个CPU版本:
然后我又按另一个原理写了一个CPU版本:
 可以看到原理哪怕稍微一点点差别,结果出来也不一样。但是我现在只要求基本和opencv结果一样。
可以看到原理哪怕稍微一点点差别,结果出来也不一样。但是我现在只要求基本和opencv结果一样。
我用了第二个模板写对应CUDA版本,但是说实话这个算法原理步骤依赖性太强,所以并行性很小。
写了对应的一个CUDA版本:
#define GEN2 1.41421356
/*
500x1216的图像,实际线程1214个:1个block,每个block里607x2个线程
*/
__global__ void distanceTransform(uchar *bwinput, uisize sizes, uchar *dtimg)
{
__shared__ uchar tmpmin[500][1216];
int idx = threadIdx.y*blockDim.x + threadIdx.x;
//首尾两行、首尾两列 不用处理 直接填0
int tid = idx;
int r = tid / sizes.cols;
int c = tid % sizes.cols;
while (r < sizes.rows && c upleftvalue)
{
minvalue = upleftvalue;
}
uchar upvalue = 1 + bwinput[upid];
if (minvalue > upvalue)
{
minvalue = upvalue;
}
uchar uprightvalue = GEN2 + bwinput[uprightid];
if (minvalue > uprightvalue)
{
minvalue = uprightvalue;
}
tmpmin[r][idx+1] = minvalue;//bwinput[centerid]=minvalue;
__syncthreads();
if (idx == 0)
{
for (int c = 1; c != sizes.cols - 1; c++)
{
int globalid = r*sizes.cols + c;
uchar leftvalue = 1 + bwinput[globalid - 1];
if (tmpmin[r][c] > leftvalue)
{
tmpmin[r][c] = leftvalue;
}
}
}
__syncthreads();
}
//除了首尾两行、首尾两列的都要处理,反向扫描
for (int r = sizes.rows - 2; r != 0; r--)
{
uchar minvalue = tmpmin[r][idx + 1];
uchar upleftvalue = GEN2 + tmpmin[r+1][idx];
if (minvalue > upleftvalue)
{
minvalue = upleftvalue;
}
uchar upvalue = 1 + tmpmin[r + 1][idx+1];
if (minvalue > upvalue)
{
minvalue = upvalue;
}
uchar uprightvalue = GEN2 + tmpmin[r + 1][idx + 2];
if (minvalue > uprightvalue)
{
minvalue = uprightvalue;
}
tmpmin[r][idx + 1] = minvalue;//bwinput[centerid]=minvalue;
__syncthreads();
if (idx == 0)
{
for (int c = sizes.cols - 2; c != 0; c--)
{
float leftvalue = 1 + tmpmin[r][c+1];
float tmpminvalue = tmpmin[r][c];
if (tmpminvalue > leftvalue)
{
tmpmin[r][c] = leftvalue;
}
}
}
__syncthreads();
}
//所有线程合作将共享变量的值填充到全局变量
tid = idx;
r = tid / sizes.cols;
c = tid % sizes.cols;
while (r < sizes.rows && c CUDACOMPILE : ptxas error : Entry function '_Z17distanceTransformPh6uisizeS_' uses too much shared data (0x94700 bytes, 0xc000 max)但是我的硬件资源限制了,跑不起来,共享内存超出了限制。然后我又重写了一个,
#define GEN2 1.41421356
float Distance(int x1, int y1, int x2, int y2)
{
return sqrt(float((x2 - x1)*(x2 - x1) + (y2 - y1)*(y2 - y1)));
}
void cpu_dt_mine(cv::Mat input, cv::Mat &output)
{
for (int i = 1; i < input.rows - 1; i++)
{
for (int j = 1; j < input.cols - 1; j++)
{
float tmpmin = input.ptr(i)[j];
float left = 1 + input.ptr(i)[j - 1];
if (tmpmin > left)
{
tmpmin = left;
}
float up = 1 + input.ptr(i - 1)[j];
if (tmpmin > up)
{
tmpmin = up;
}
float upleft = GEN2 + input.ptr(i - 1)[j - 1];
if (tmpmin > upleft)
{
tmpmin = upleft;
}
float upright = GEN2 + input.ptr(i - 1)[j + 1];
if (tmpmin > upright)
{
tmpmin = upright;
}
output.ptr(i)[j] = tmpmin;
input.ptr(i)[j] = int(tmpmin);
}
}
for (int i = input.rows - 2; i >0; i--)
{
for (int j = input.cols - 2; j >0; j--)
{
float tmpmin = output.ptr(i)[j];
float left = 1 + output.ptr(i)[j + 1];
if (tmpmin > left)
{
tmpmin = left;
}
float up = 1 + output.ptr(i + 1)[j];
if (tmpmin > up)
{
tmpmin = up;
}
float upleft = GEN2 + output.ptr(i + 1)[j - 1];
if (tmpmin > upleft)
{
tmpmin = upleft;
}
float upright = GEN2 + output.ptr(i + 1)[j + 1];
if (tmpmin > upright)
{
tmpmin = upright;
}
output.ptr(i)[j] = tmpmin;
}
}
}
void cpu_dt(cv::Mat input, cv::Mat &output)
{
cv::Mat BinaryImage = input;
uchar *pRowOne;
uchar *pRowNext;
float distance;
float Mindis;
for (int i = 1; i <= BinaryImage.rows - 2; i++)
{
pRowOne = BinaryImage.ptr(i);
for (int j = 1; j <= BinaryImage.cols - 1; j++)
{
pRowNext = BinaryImage.ptr(i - 1);
distance = Distance(i, j, i - 1, j - 1);//q1
Mindis = min((float)pRowOne[j], distance + pRowNext[j - 1]);
distance = Distance(i, j, i - 1, j);//q2
Mindis = min(Mindis, distance + pRowNext[j]);
pRowNext = BinaryImage.ptr(i);
distance = Distance(i, j, i, j - 1);//q3
Mindis = min(Mindis, distance + pRowNext[j]);
pRowNext = BinaryImage.ptr(i + 1);//q4
distance = Distance(i, j, i + 1, j - 1);
Mindis = min(Mindis, distance + pRowNext[j - 1]);
pRowOne[j] = (uchar)round(Mindis);
}
}
for (int i = BinaryImage.rows - 2; i > 0; i--)
{
pRowOne = BinaryImage.ptr(i);
for (int j = BinaryImage.cols - 2; j > 0; j--)
{
pRowNext = BinaryImage.ptr(i + 1);
distance = Distance(i, j, i + 1, j);//q1
Mindis = min((float)pRowOne[j], distance + pRowNext[j]);
distance = Distance(i, j, i + 1, j + 1);//q2
Mindis = min(Mindis, distance + pRowNext[j + 1]);
pRowNext = BinaryImage.ptr(i);//q3
distance = Distance(i, j, i, j + 1);
Mindis = min(Mindis, distance + pRowNext[j + 1]);
pRowNext = BinaryImage.ptr(i - 1);//q4
distance = Distance(i, j, i - 1, j + 1);
Mindis = min(Mindis, distance + pRowNext[j + 1]);
pRowOne[j] = (uchar)round(Mindis);
}
}
output = BinaryImage;
}
//:https ://blog.csdn.net/qinzihangxj/article/details/105601108
////////////////////////////////////////////////////////////////////
/*硬件限制,共享内存不够
dim3 threads(2, 607);
distanceTransform << <1, threads >> >(dev_img, imgsizes, dev_closest);
500x1216的图像,实际线程1214个:1个block,每个block里607x2个线程
*/
/*
__global__ void distanceTransform(uchar *bwinput, uisize sizes, uchar *dtimg)
{
__shared__ float tmpmin[500][1216];
int idx = threadIdx.y*blockDim.x + threadIdx.x;
//首尾两行、首尾两列 不用处理 直接填0
int tid = idx;
int r = tid / sizes.cols;
int c = tid % sizes.cols;
while (r < sizes.rows && c upleftvalue)
{
minvalue = upleftvalue;
}
float upvalue = 1 + bwinput[upid];
if (minvalue > upvalue)
{
minvalue = upvalue;
}
float uprightvalue = GEN2 + bwinput[uprightid];
if (minvalue > uprightvalue)
{
minvalue = uprightvalue;
}
tmpmin[r][idx+1] = minvalue;//bwinput[centerid]=minvalue;
__syncthreads();
if (idx == 0)
{
for (int c = 1; c != sizes.cols - 1; c++)
{
int globalid = r*sizes.cols + c;
float leftvalue = 1 + bwinput[globalid - 1];
if (tmpmin[r][c] > leftvalue)
{
tmpmin[r][c] = leftvalue;
}
}
}
__syncthreads();
}
//除了首尾两行、首尾两列的都要处理,反向扫描
for (int r = sizes.rows - 2; r != 0; r--)
{
float minvalue = tmpmin[r][idx + 1];
float upleftvalue = GEN2 + tmpmin[r+1][idx];
if (minvalue > upleftvalue)
{
minvalue = upleftvalue;
}
float upvalue = 1 + tmpmin[r + 1][idx+1];
if (minvalue > upvalue)
{
minvalue = upvalue;
}
float uprightvalue = GEN2 + tmpmin[r + 1][idx + 2];
if (minvalue > uprightvalue)
{
minvalue = uprightvalue;
}
tmpmin[r][idx + 1] = minvalue;//bwinput[centerid]=minvalue;
__syncthreads();
if (idx == 0)
{
for (int c = sizes.cols - 2; c != 0; c--)
{
float leftvalue = 1 + tmpmin[r][c+1];
float tmpminvalue = tmpmin[r][c];
if (tmpminvalue > leftvalue)
{
tmpmin[r][c] = leftvalue;
}
}
}
__syncthreads();
}
//所有线程合作将共享变量的值填充到全局变量
tid = idx;
r = tid / sizes.cols;
c = tid % sizes.cols;
while (r < sizes.rows && c= sizes.rows) && (tid < 2 * sizes.rows))
{
dtimg[(tid - sizes.rows + 2)*sizes.cols - 1] = sidevalue;
}
////////////////////////////////////先前向扫描
for (int r = 1; r != sizes.rows - 1; r++)
{
int therow = r*sizes.cols;
int threadid = idx;
while (threadid < sizes.cols)
{
int centerid = therow + 1 + threadid;//得到中心点的位置,每个thread
int lastrow = therow - sizes.cols;
int upleftid = lastrow + threadid;
int upid = lastrow + threadid + 1;
int uprightid = lastrow + threadid + 2;
float minvalue = bwinput[centerid];
float upleftvalue = GEN2 + bwinput[upleftid];
if (minvalue > upleftvalue)
{
minvalue = upleftvalue;
}
float upvalue = 1 + bwinput[upid];
if (minvalue > upvalue)
{
minvalue = upvalue;
}
float uprightvalue = GEN2 + bwinput[uprightid];
if (minvalue > uprightvalue)
{
minvalue = uprightvalue;
}
tmpmin[threadid] = minvalue;
threadid += (blockDim.x);
}
__syncthreads();
if (idx == 0)
{
for (int c = 1; c != sizes.cols - 1; c++)
{
int globalid = r*sizes.cols + c;
float leftvalue = 1 + dtimg[globalid - 1];
if (tmpmin[c-1] > leftvalue)
{
dtimg[globalid] = leftvalue;
}
else
{
dtimg[globalid] = tmpmin[c - 1];
}
}
}
__syncthreads();
}
///////////////////////////////////////////反向扫描
for (int r = sizes.rows - 2; r != 0; r--)
{
int therow = r*sizes.cols;
int threadid = idx;
while (threadid < sizes.cols)
{
int centerid = therow + 1 + threadid;//得到中心点的位置,每个thread
int lastrow = therow + sizes.cols;
int upleftid = lastrow + threadid;
int upid = lastrow + threadid + 1;
int uprightid = lastrow + threadid + 2;
float minvalue = dtimg[centerid];
float upleftvalue = GEN2 + dtimg[upleftid];
if (minvalue > upleftvalue)
{
minvalue = upleftvalue;
}
float upvalue = 1 + dtimg[upid];
if (minvalue > upvalue)
{
minvalue = upvalue;
}
float uprightvalue = GEN2 + dtimg[uprightid];
if (minvalue > uprightvalue)
{
minvalue = uprightvalue;
}
tmpmin[threadid] = minvalue;
threadid += (blockDim.x);
}
__syncthreads();
if (idx == 0)
{
for (int c = sizes.cols - 2; c != 0; c--)
{
int globalid = r*sizes.cols + c;
float leftvalue = 1 + dtimg[globalid + 1];
float tmpminvalue = tmpmin[c-1];
if (tmpminvalue > leftvalue)
{
dtimg[globalid] = leftvalue;
}
else
{
dtimg[globalid] = tmpminvalue;
}
}
}
__syncthreads();
}
//////////////////////////////////////////////////////
}
int main()
{
char srclowfolder[400] = { 0 };
cv::Mat element_cross55 = cv::getStructuringElement(cv::MORPH_CROSS, cv::Size(5, 5));
for (int index = 3; index <= 3; index++)
{
sprintf(srclowfolder, "E:\\CUDA\\imgs\\jinxinginput\\101\\%d_lowbw.jpg", index);
cv::Mat low_binary_A = cv::imread(srclowfolder, cv::IMREAD_UNCHANGED);
for (int r = 0; r != low_binary_A.rows; r++)
{
for (int c = 0; c != low_binary_A.cols; c++)
{
if (low_binary_A.ptr(r)[c] > 200)
{
low_binary_A.ptr(r)[c] = 255;
}
else
{
low_binary_A.ptr(r)[c] = 0;
}
}
}
/*
cv::Mat realimg(low_binary_A.rows, low_binary_A.cols, CV_8UC1, cv::Scalar(0));
for (int r = 0; r != low_binary_A.rows; r++)
{
for (int c = 0; c != low_binary_A.cols; c++)
{
if (low_binary_A.ptr(r)[c] > 0)
{
realimg.ptr(r)[c] = 1;
}
}
}
std::cout << "原图" << std::endl;
for (int r = 152; r != 180; r++)
{
for (int c = 430; c != 458; c++)
{
std::cout << int(realimg.ptr(r)[c]) << " ";
}
std::cout << std::endl;
}
std::cout << std::endl << std::endl;
std::cout << "cv...." << std::endl;
cv::Mat dist_image;
distanceTransform(low_binary_A, dist_image, cv::DIST_L2, 3);
for (int r = 152; r != 180; r++)
{
for (int c = 430; c != 458; c++)
{
std::cout << int(dist_image.ptr(r)[c]) << " ";
}
std::cout << std::endl;
}
std::cout << std::endl << std::endl;
cv::Mat dtcpu(low_binary_A.rows, low_binary_A.cols, CV_8UC1, cv::Scalar(0));
cpu_dt(low_binary_A, dtcpu);
std::cout << "cpu1...." << std::endl;
for (int r = 152; r != 180; r++)
{
for (int c = 430; c != 458; c++)
{
std::cout << int(dtcpu.ptr(r)[c]) << " ";
}
std::cout << std::endl;
}
std::cout << std::endl << std::endl;
dtcpu.release();
cv::Mat dt2cpu(low_binary_A.rows, low_binary_A.cols, CV_32FC1, cv::Scalar(0));
cpu_dt_mine(low_binary_A, dt2cpu);
std::cout << "cpu2...." << std::endl;
for (int r = 152; r != 180; r++)
{
for (int c = 430; c != 458; c++)
{
std::cout << int(dt2cpu.ptr(r)[c]) << " ";
}
std::cout << std::endl;
}
std::cout << std::endl << std::endl;
*/
uisize imgsizes;
imgsizes.rows = low_binary_A.rows;
imgsizes.cols = low_binary_A.cols;
uchar *dev_img = 0;
float *dev_closest = 0;
cudaEvent_t start, stop;
HANDLE_ERROR(cudaEventCreate(&start));
HANDLE_ERROR(cudaEventCreate(&stop));
HANDLE_ERROR(cudaEventRecord(start, 0));
cudaSetDevice(0);
cudaMalloc((void**)&dev_img, imgsizes.rows*imgsizes.cols * sizeof(uchar));
cudaMalloc((void**)&dev_closest, imgsizes.rows*imgsizes.cols * sizeof(float));
cudaMemcpy(dev_img, low_binary_A.data, imgsizes.rows*imgsizes.cols * sizeof(uchar), cudaMemcpyHostToDevice);
distanceTransformgpu << <1, 1024 >> >(dev_img, imgsizes, dev_closest);
cv::Mat deviceDTresult(low_binary_A.rows, low_binary_A.cols, CV_32FC1);
cudaMemcpy(deviceDTresult.data, dev_closest, imgsizes.rows*imgsizes.cols * sizeof(float), cudaMemcpyDeviceToHost);
cudaDeviceSynchronize();
std::cout << "gpu result...." << std::endl;
for (int r = 152; r != 180; r++)
{
for (int c = 430; c != 458; c++)
{
std::cout << int(deviceDTresult.ptr(r)[c]) << " ";
}
std::cout << std::endl;
}
uchar *dev_dilate = 0;
cudaMalloc((void**)&dev_dilate, imgsizes.rows*imgsizes.cols * sizeof(uchar));
dim3 grids(2, 500);
dilatecross5 << > >(dev_img, dev_dilate);
cudaDeviceSynchronize();
HANDLE_ERROR(cudaEventRecord(stop, 0));
HANDLE_ERROR(cudaEventSynchronize(stop));
float elapsedTime;
HANDLE_ERROR(cudaEventElapsedTime(&elapsedTime, start, stop));
//printf("Time on GPU: %3.1f ms\n", elapsedTime);
HANDLE_ERROR(cudaEventDestroy(start));
HANDLE_ERROR(cudaEventDestroy(stop));
cudaFree(dev_img);
cudaFree(dev_closest);
cudaFree(dev_dilate);
}
return 0;
} 结果如下:

基本和cpu版本差不多(和第二个cpu原理出来的结果不完全一样,先懒得追究)。但是如果我把注释的部分放开,打印出的结果就不对,是VS的打印流之间会干扰是吗?有大神遇到过这个奇怪现象吗?

看这个打印结果怎么变成这样,和注释掉时的结果不一样。明明注释掉的地方应该不影响CUDA的结果啊??
然后我测试了一下时间,opencv版本的距离变换只要3~4ms,按两种原理自己手写的cpu版本的距离变换时间是100ms左右,但是gpu版本的竟然要1500ms!!!太不科学了,我以为应该要比100ms少的?!!!!!!!真的想知道opencv版的距离变换的源码内部怎么处理的这么快!!!!!!
我刚刚查到,原来opencv中的距离变换用的原理是< 这才是cv::distanceTransform的来源。这是2012年的论文,我现在还找到另一个作者说已经实现并行的论文2019年出来的,但有的地方还看不怎么懂,据说实现了全并行,应该比cv版本快很多,但我还没完全懂。
这才是cv::distanceTransform的来源。这是2012年的论文,我现在还找到另一个作者说已经实现并行的论文2019年出来的,但有的地方还看不怎么懂,据说实现了全并行,应该比cv版本快很多,但我还没完全懂。
我准备先把cv原理改成CUDA版本,测试性能,如果不够再继续研究2019这篇并行度很高的原理。
今天终于写完了cv原理的CUDA版本,与对应的CPU版本一致,但耗时很多:
/*对输入的二值图做准备工作,
然后对所有列完成一次扫描
500x1216的图像,那么实际使用500x1216个线程就够了,每个block内608x1
每个grid里有 2x500个blocks
*/
__global__ void preparefordt(uchar *bwimg, float *gpudtimg)
{
int rows = 500;
int cols = 1216;
int idx = blockIdx.x*blockDim.x + threadIdx.x;
int idy = blockIdx.y*blockDim.y + threadIdx.y;
int imgid = idy*cols + idx;
if (bwimg[imgid] == 0)
{
gpudtimg[imgid] = 0;
}
else
{
gpudtimg[imgid] = INF;
}
}
/*
f----输入的一维数据
d----一维数据f对应的距离变换结果
*/
__device__ void dt1dimgpu(float *f, float *d)
{
const int n = 500;
//float d[n];
int v[n];
float z[n + 1];
int k = 0;
v[0] = 0;
z[0] = -INF;
z[1] = +INF;
for (int q = 1; q <= n - 1; q++)
{
float s = ((f[q] + q*q) - (f[v[k]] + (v[k])*(v[k]))) / (2 * q - 2 * v[k]);
while (s <= z[k])
{
k--;
s = ((f[q] + q*q) - (f[v[k]] + (v[k])*(v[k]))) / (2 * q - 2 * v[k]);
}
k++;
v[k] = q;
z[k] = s;
z[k + 1] = +INF;
}
k = 0;
for (int q = 0; q <= n - 1; q++)
{
while (z[k + 1] < q)
{
k++;
}
d[q] = (q - v[k])*(q - v[k]) + f[v[k]];
}
}
/*
f----输入的一维数据
d----一维数据f对应的距离变换结果
*/
__device__ void dt1dimrowgpu(float *f, float *d)
{
const int n = 1216;
int v[n];
float z[n + 1];
int k = 0;
v[0] = 0;
z[0] = -INF;
z[1] = +INF;
for (int q = 1; q <= n - 1; q++)
{
float s = ((f[q] + q*q) - (f[v[k]] + (v[k])*(v[k]))) / (2 * q - 2 * v[k]);
while (s <= z[k])
{
k--;
s = ((f[q] + q*q) - (f[v[k]] + (v[k])*(v[k]))) / (2 * q - 2 * v[k]);
}
k++;
v[k] = q;
z[k] = s;
z[k + 1] = +INF;
}
k = 0;
for (int q = 0; q <= n - 1; q++)
{
while (z[k + 1] < q)
{
k++;
}
d[q] = (q - v[k])*(q - v[k]) + f[v[k]];
}
}
/*
然后对gpudtimg所有列完成一次扫描
500x1216的图像,那么实际使用1216个线程就够了,每个block内1x500个线程
每个grid里有 2x608个blocks
*/
__global__ void dtcolpass(float *gpudtimg, float *colpassimg)
{
const int rows = 500;
const int cols = 1216;
int id = blockIdx.y*gridDim.x + blockIdx.x;
int rowid = threadIdx.x;
int globalid = id + cols*rowid;
//block内所有线程合作,完成一列从全局搬运到共享内存
__shared__ float coldata[rows];
coldata[rowid] = gpudtimg[globalid];//globalid 有问题 越界了??
__syncthreads();
//一个线程 对共享内存的数据进行一维距离变换
__shared__ float coldataresult[rows];
if (rowid == 0)
{
dt1dimgpu(coldata, coldataresult);
}
__syncthreads();
//block内所有线程合作,将共享内存的距离变换结果搬到全局某列
colpassimg[globalid]= coldataresult[rowid];
}
/*
然后对colpassimg所有行完成一次扫描
500x1216的图像,那么实际使用500个线程就够了,每个block内1024个线程
每个grid里有 500个blocks
*/
__global__ void dtrowpass(float *colpassimg, float *rowpassimg)
{
const int rows = 500;
const int cols = 1216;
//block内所有线程合作,完成一行从全局搬运到共享内存
__shared__ float rowdata[cols];
int tid = threadIdx.x;
while (tid < cols)
{
int thid = tid + cols*blockIdx.y;
rowdata[tid] = colpassimg[thid];
tid += blockDim.x;
}
__syncthreads();
tid = threadIdx.x;
//一个线程 对共享内存的数据进行一维距离变换
__shared__ float rowdataresult[cols];
if (tid == 0)
{
dt1dimrowgpu(rowdata, rowdataresult);
}
__syncthreads();
//block内所有线程合作,将共享内存的距离变换结果搬到全局某行
while (tid < cols)
{
int thid = tid + cols*blockIdx.y;
rowpassimg[thid]= rowdataresult[tid];
tid += blockDim.x;
}
}
/*
最后对图像结果每个数据开根号,得到最终结果
500x1216的图像,那么实际使用500x1216个线程就够了,每个block内608x1
每个grid里有 2x500个blocks
*/
__global__ void dtsqrt(float *rowpassimg, float *dtresult)
{
int rows = 500;
int cols = 1216;
int idx = blockIdx.x*blockDim.x + threadIdx.x;
int idy = blockIdx.y*blockDim.y + threadIdx.y;
int imgid = idy*cols + idx;
float tmpsquare = rowpassimg[imgid];
dtresult[imgid] = sqrt(tmpsquare);
}cudaMalloc((void**)&dev_preparedt, imgsizes.rows*imgsizes.cols * sizeof(float));
dim3 preparegrids(2, 500);
preparefordt << > >(dev_img, dev_preparedt);
cudaDeviceSynchronize();
float *dev_colpassimg = 0;
cudaMalloc((void**)&dev_colpassimg, imgsizes.rows*imgsizes.cols * sizeof(float));
dim3 colgrids(2, 608);
dtcolpass << > > (dev_preparedt, dev_colpassimg);
cudaDeviceSynchronize();
cudaFree(dev_preparedt);
float *dev_rowpassimg = 0;
cudaMalloc((void**)&dev_rowpassimg, imgsizes.rows*imgsizes.cols * sizeof(float));
dim3 rowgrids(1, 500);
dtrowpass << > > (dev_colpassimg, dev_rowpassimg);
cudaDeviceSynchronize();
cudaFree(dev_colpassimg);
float *dev_dtresult = 0;
cudaMalloc((void**)&dev_dtresult, imgsizes.rows*imgsizes.cols * sizeof(float));
dtsqrt << > > (dev_rowpassimg, dev_dtresult);
cudaDeviceSynchronize();
cudaFree(dev_rowpassimg);  这个耗时太长,然后我又改写了一个版本:
这个耗时太长,然后我又改写了一个版本:
//up to down, down to up
__device__ void likedt1dimvec(uchar *dim1data, uchar *dim1result)
{
int length = 500;
for (int i = 1; i != length; i++)
{
if (dim1data[i] > 0)
{
dim1result[i] = dim1data[i] + dim1result[i - 1];
}
}
}
//left to right , right to left
__device__ void likedt1dimhor(uchar *dim1data, uchar *dim1result)
{
int length = 1216;
for (int i = 1; i != length; i++)
{
if (dim1data[i] > 0)
{
dim1result[i] = dim1data[i] + dim1result[i - 1];
}
}
}
/*
然后对colpassimg所有行完成一次从左到右扫描
500x1216的图像,那么实际使用500个线程就够了,每个block内1024个线程
每个grid里有 500个blocks
*/
__global__ void likedtleftrightpass0(uchar *colpassimg, uchar *leftright)
{
const int rows = 500;
const int cols = 1216;
//block内所有线程合作,完成一行从全局搬运到共享内存
__shared__ uchar rowdata[cols];
int tid = threadIdx.x;
while (tid < cols)
{
int thid = tid + cols*blockIdx.y;
rowdata[tid] = colpassimg[thid];
tid += blockDim.x;
}
__syncthreads();
tid = threadIdx.x;
//一个线程 对共享内存的数据进行一维距离变换
__shared__ uchar rowdataresult[cols];
if (tid == 0)
{
likedt1dimhor(rowdata, rowdataresult);
}
__syncthreads();
//block内所有线程合作,将共享内存的距离变换结果搬到全局某行
while (tid < cols)
{
int thid = tid + cols*blockIdx.y;
leftright[thid] = rowdataresult[tid];
tid += blockDim.x;
}
}
/*
然后对colpassimg所有行完成一次从右到左扫描
500x1216的图像,那么实际使用500个线程就够了,每个block内1024个线程
每个grid里有 500个blocks
*/
__global__ void likedtrightleftpass0(uchar *colpassimg, uchar *rightleft)
{
const int rows = 500;
const int cols = 1216;
//block内所有线程合作,完成一行从全局搬运到共享内存
__shared__ uchar rowdata[cols];
int tid = threadIdx.x;
while (tid < cols)
{
int thid = tid + cols*blockIdx.y;
rowdata[cols-1-tid] = colpassimg[thid];
tid += blockDim.x;
}
__syncthreads();
tid = threadIdx.x;
//一个线程 对共享内存的数据进行一维距离变换
__shared__ uchar rowdataresult[cols];
if (tid == 0)
{
likedt1dimhor(rowdata, rowdataresult);
}
__syncthreads();
//block内所有线程合作,将共享内存的距离变换结果搬到全局某行
while (tid < cols)
{
int thid = tid + cols*blockIdx.y;
rightleft[thid] = rowdataresult[cols-1-tid];
tid += blockDim.x;
}
}
/*
然后对gpudtimg所有列完成一次从上到下扫描
500x1216的图像,那么实际使用1216个线程就够了,每个block内1x500个线程
每个grid里有 2x608个blocks
*/
__global__ void likedtupdownscan0(uchar *gpudtimg, uchar *updownpassimg)
{
const int rows = 500;
const int cols = 1216;
int id = blockIdx.y*gridDim.x + blockIdx.x;
int rowid = threadIdx.x;
int globalid = id + cols*rowid;
//block内所有线程合作,完成一列从全局搬运到共享内存
__shared__ uchar coldata[rows];
coldata[rowid] = gpudtimg[globalid];
__syncthreads();
//一个线程 对共享内存的数据进行一维距离变换
__shared__ uchar coldataresult[rows];
if (rowid == 0)
{
likedt1dimvec(coldata, coldataresult);
}
__syncthreads();
//block内所有线程合作,将共享内存的距离变换结果搬到全局某列
updownpassimg[globalid] = coldataresult[rowid];
}
/*
然后对gpudtimg所有列完成一次从下到上扫描
500x1216的图像,那么实际使用1216个线程就够了,每个block内1x500个线程
每个grid里有 2x608个blocks
*/
__global__ void likedtdownupscan0(uchar *gpudtimg, uchar *downuppassimg)
{
const int rows = 500;
const int cols = 1216;
int id = blockIdx.y*gridDim.x + blockIdx.x;
int rowid = threadIdx.x;
int globalid = id + cols*rowid;
//block内所有线程合作,完成一列从全局搬运到共享内存
__shared__ uchar coldata[rows];
coldata[rows-1-rowid] = gpudtimg[globalid];
__syncthreads();
//一个线程 对共享内存的数据进行一维距离变换
__shared__ uchar coldataresult[rows];
if (rowid == 0)
{
likedt1dimvec(coldata, coldataresult);
}
__syncthreads();
//block内所有线程合作,将共享内存的距离变换结果搬到全局某列
downuppassimg[globalid] = coldataresult[rows-1-rowid];
}
/*
最后对图像结果每个数据开根号,得到最终结果
500x1216的图像,那么实际使用500x1216个线程就够了,每个block内608x1
每个grid里有 2x500个blocks
*/
__global__ void likedtresult(uchar *updown, uchar *downup, uchar *leftright, uchar *rightleft, uchar *dtresult)
{
int rows = 500;
int cols = 1216;
int idx = blockIdx.x*blockDim.x + threadIdx.x;
int idy = blockIdx.y*blockDim.y + threadIdx.y;
int imgid = idy*cols + idx;
uchar udvalue = updown[imgid];
uchar minvalue = udvalue;
uchar duvalue = downup[imgid];
if (minvalue > duvalue)
{
minvalue = duvalue;
}
uchar lrvalue = leftright[imgid];
if (minvalue > lrvalue)
{
minvalue = lrvalue;
}
uchar rlvalue = rightleft[imgid];
if (minvalue > rlvalue)
{
minvalue = rlvalue;
}
dtresult[imgid] = minvalue;
}但是这个版本的时间还是无法接受要34ms左右。最后我又在此基础上将本来一个线程处理共享内存中的数据,变成多个线程去处理,现在时间已比CPU版本(10~11)快。
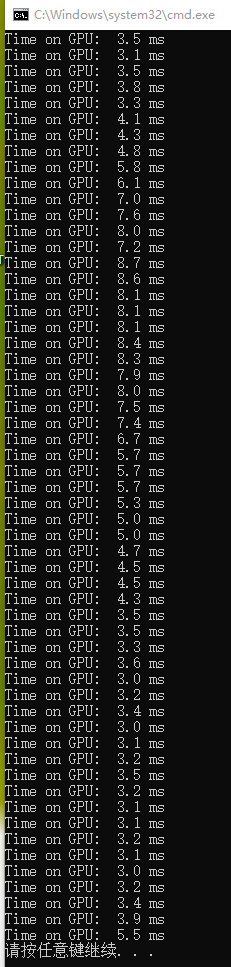 这是现在这个版本的时间。
这是现在这个版本的时间。
另一个核函数即图像膨胀,我测试了一下CUDA版本和我想的一样提速很多很多,而且测试结果与opencv版本图像膨胀结果一致。
三、分水岭
我要使用基于距离变换标记的分水岭,看了下opencv的这个版本的源码,终于看懂了。依赖性很强而且使用了链表动态取出--存放--取出,不是那么好并行啊。
我刚刚找到Nvidia NPP提供的watershedSegment的API,它是基于CA分水岭实现的https://docs.nvidia.com/cuda/npp/group__image__filter__watershed__segmentation.html,https://github.com/NVIDIA/CUDALibrarySamples/tree/master/NPP/watershedSegmentation Nvidia官方上个月才更新。每次查这些资料的时候,总会对我们自己失望,在技术方面与国际接轨还是太慢了,知识的更新落后了很多。问一堆CUDA或图像相关的群里,或查国内一些网站,都有这个感觉。
NPP中关于分水岭与连通域标记都是需要CUDA11.0支持的,而我的电脑不是,所以我真的很想看明白那篇论文自己实现,再看看吧。
四、《CUDA C编程权威指南》
买的书终于到了,看前三章,我终于知道为什么之前代码一样,设置不同的grid block性能差别很大了,因为我没有遵循其设置规则,比如block内线程不能太少....
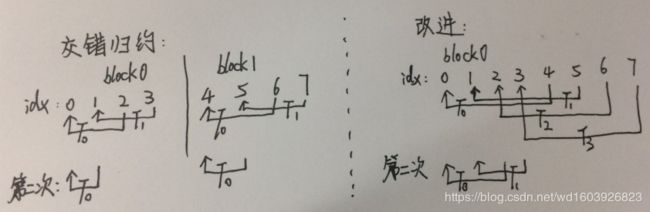
另外看到交错规约的设计改进,再一次发现设计思路真的很重要。右边的设计只需一个block,而且第一次时block内的所有线程都活跃,第二次时活跃线程也比左边这种多一倍。