我的keras小例子及问题
现在我的问题是:我是分2类 第0张到第622张属于第一类 后面的属于第2类 我先写脚本loaddata8_18.py把图片读成数据文件:
import os
from PIL import Image
import numpy as np
def load_data():
data = np.empty((1040,1,60,60),dtype="float32")
label = np.empty((1040,),dtype="int")
imgs = os.listdir("./sampleyingguang8.18")
num = len(imgs)
for i in range(num):
img = Image.open("./sampleyingguang8.18/"+imgs[i])
arr = np.asarray(img,dtype="float32")
data[i,:,:,:] = arr
if i<623:
label[i] = int(0)
else:
label[i] = int(1)
data /= np.max(data)
data -= np.mean(data)
return data,label
from __future__ import absolute_import
from __future__ import print_function
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation, Flatten
from keras.layers.convolutional import Convolution2D, MaxPooling2D
from keras.optimizers import SGD,Adadelta
import keras.regularizers
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.preprocessing import MinMaxScaler
#from keras.utils import np_utils, generic_utils
from six.moves import range
from luobindata8_18 import load_data
import random
from keras.callbacks import EarlyStopping
import numpy as np
np.random.seed(1024)
data, label = load_data()
def create_model():
model = Sequential()
model.add(Convolution2D(64, 5, 5, border_mode='valid',input_shape=(1,60,60)))
model.add(Activation('relu'))
model.add(Convolution2D(64, 5, 5, border_mode='valid'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(128, 5, 5, border_mode='valid'))
model.add(Activation('relu'))
model.add(Convolution2D(128, 5, 5, border_mode='valid'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(256,3, 3, border_mode='valid'))
model.add(Activation('relu'))
model.add(Convolution2D(256,3, 3, border_mode='valid'))
model.add(Activation('relu'))
model.add(Convolution2D(256,3, 3, border_mode='valid'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten()) # this converts our 3D feature maps to 1D feature vectors
model.add(Dense(256))
model.add(Activation('relu'))
model.add(Dropout(0.5))
#model.add(Dense(512))
#model.add(Activation('relu'))
#model.add(Dropout(0.3))
model.add(Dense(1))
model.add(Activation('sigmoid'))
return model
#############
#开始训练模型
##############
model = create_model()
#sgd = SGD(lr=0.001, decay=1e-8, momentum=0.9, nesterov=True)
#model.compile(loss='binary_crossentropy', optimizer=sgd,metrics=["accuracy"])
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='binary_crossentropy', optimizer=sgd,metrics=["accuracy"])
#adadelta=Adadelta(lr=1.0, rho=0.95, epsilon=1e-09)
#model.compile(loss='mse', optimizer=adadelta,metrics=["accuracy"])
#model.compile(loss="binary_crossentropy", optimizer=adadelta,metrics=["accuracy"])
index = [i for i in range(len(data))]
random.shuffle(index)
data = data[index]
label = label[index]
(X_train,X_val) = (data[0:884],data[884:])
(Y_train,Y_val) = (label[0:884],label[884:])
#使用early stopping返回最佳epoch对应的model
early_stopping = EarlyStopping(monitor='val_loss', patience=1)
model.fit(X_train, Y_train,validation_data=(X_val, Y_val),callbacks=[early_stopping])
cPickle.dump(model,open("./model8.18.pkl","wb"))from __future__ import print_function
import cPickle
import theano
print(theano.config.device)
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.preprocessing import MinMaxScaler
from luobindata8_18 import load_data
import random
import keras.backend as K
def svc(traindata,trainlabel,testdata,testlabel):
print("Start training SVM...")
svcClf = SVC(C=1.0,kernel="rbf",cache_size=900)
svcClf.fit(traindata,trainlabel)
pred_testlabel = svcClf.predict(testdata)
num = len(pred_testlabel)
accuracy = len([1 for i in range(num) if testlabel[i]==pred_testlabel[i]])/float(num)
print("cnn-svm Accuracy:",accuracy)
def rf(traindata,trainlabel,testdata,testlabel):
print("Start training Random Forest...")
rfClf = RandomForestClassifier(n_estimators=2,criterion='gini')
rfClf.fit(traindata,trainlabel)
pred_testlabel = rfClf.predict(testdata)
num = len(pred_testlabel)
accuracy = len([1 for i in range(num) if testlabel[i]==pred_testlabel[i]])/float(num)
print("cnn-rf Accuracy:",accuracy)
if __name__ == "__main__":
#load data
data, label = load_data()
#shuffle the data
index = [i for i in range(len(data))]
random.shuffle(index)
data = data[index]
label = label[index]
(traindata,testdata) = (data[0:900],data[900:])
(trainlabel,testlabel) = (label[0:900],label[900:])
origin_model = cPickle.load(open("model8.18.pkl","rb"))
get_feature = K.function([K.learning_phase(),origin_model.layers[0].input],origin_model.layers[13].output)
feature = get_feature([data])
get_feature = K.function([K.learning_phase(),origin_model.layers[0].input],origin_model.layers[13].output)百度过 改过 然而并没解决????????????????????????????
////////////////////////////////////////////////小分界线///////////////////////////////////////////////////////////////////////////////////////////
后来我在保存模型那步不保存为.pkl形式了 改成了这样保存模型:
from __future__ import absolute_import
from __future__ import print_function
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation, Flatten
from keras.layers.convolutional import Convolution2D, MaxPooling2D
from keras.optimizers import SGD,Adadelta
import keras.regularizers
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.preprocessing import MinMaxScaler
import theano
#from keras.utils import np_utils, generic_utils
from six.moves import range
from luobindata8_18 import load_data
import random,cPickle
from keras.callbacks import EarlyStopping
import numpy as np
import sys
sys.setrecursionlimit(1000000)
np.random.seed(1024)
data, label = load_data()
def create_model():
model = Sequential()
model.add(Convolution2D(32, 5, 5, border_mode='valid',input_shape=(1,60,60)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.3))
model.add(Convolution2D(32,3, 3, border_mode='valid'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.3))
model.add(Convolution2D(64,3, 3, border_mode='valid'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.3))
model.add(Flatten()) # this converts our 3D feature maps to 1D feature vectors
model.add(Dense(128))
model.add(Activation('relu'))
model.add(Dropout(0.3))
model.add(Dense(1))
model.add(Activation('sigmoid'))
return model
#############
#开始训练模型
##############
model = create_model()
#sgd = SGD(lr=0.001, decay=1e-8, momentum=0.9, nesterov=True)
#model.compile(loss='binary_crossentropy', optimizer=sgd,metrics=["accuracy"])
sgd = SGD(lr=0.001, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='binary_crossentropy', optimizer=sgd,metrics=["accuracy"])
#adadelta=Adadelta(lr=1.0, rho=0.95, epsilon=1e-09)
#model.compile(loss='mse', optimizer=adadelta,metrics=["accuracy"])
#model.compile(loss="binary_crossentropy", optimizer=adadelta,metrics=["accuracy"])
index = [i for i in range(len(data))]
random.shuffle(index)
data = data[index]
label = label[index]
(X_train,X_val) = (data[0:900],data[900:])
(Y_train,Y_val) = (label[0:900],label[900:])
#使用early stopping返回最佳epoch对应的model
early_stopping = EarlyStopping(monitor='val_loss', patience=1)
#model.fit(X_train, Y_train,callbacks=[early_stopping])
model.fit(X_train, Y_train, batch_size=10,validation_data=(X_val, Y_val),nb_epoch=5,callbacks=[early_stopping])
#cPickle.dump(model,open("./model9.1.pkl","wb"))
json_string = model.to_json()
open('savemodel8.20.json','w').write(json_string)
model.save_weights('savemodel_weights8.20.h5') from __future__ import print_function
import cPickle
import theano
print(theano.config.device)
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.preprocessing import MinMaxScaler
from luobindata8_18 import load_data
from keras.models import model_from_json
import random
import keras.backend as K
def svc(traindata,trainlabel,testdata,testlabel):
print("Start training SVM...")
svcClf = SVC(C=1.0,kernel="rbf",cache_size=900)
svcClf.fit(traindata,trainlabel)
pred_testlabel = svcClf.predict(testdata)
num = len(pred_testlabel)
accuracy = len([1 for i in range(num) if testlabel[i]==pred_testlabel[i]])/float(num)
print("cnn-svm Accuracy:",accuracy)
def rf(traindata,trainlabel,testdata,testlabel):
print("Start training Random Forest...")
rfClf = RandomForestClassifier(n_estimators=2,criterion='gini')
rfClf.fit(traindata,trainlabel)
pred_testlabel = rfClf.predict(testdata)
num = len(pred_testlabel)
accuracy = len([1 for i in range(num) if testlabel[i]==pred_testlabel[i]])/float(num)
print("cnn-rf Accuracy:",accuracy)
if __name__ == "__main__":
#load data
data, label = load_data()
#shuffle the data
index = [i for i in range(len(data))]
random.shuffle(index)
data = data[index]
label = label[index]
(traindata,testdata) = (data[0:900],data[900:])
(trainlabel,testlabel) = (label[0:900],label[900:])
origin_model = model_from_json(open('savemodel8.20.json').read())
origin_model.load_weights('savemodel_weights8.20.h5')
get_feature = K.function([K.learning_phase(),origin_model.layers[0].input],origin_model.layers[13].output)
feature = get_feature([data])feature = get_feature([data])为什么报这个错呢?我是要提取1040张1通道60X60图片的特征啊 这和我生成model时一样的格式啊 怎么报错呢??????
我换成:
feature = get_feature([K.learning_phase(),data])百度过 依旧没解决??????????????????
///////////////////////////////////////////////分界线////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
推荐这个博客http://www.360doc.com/content/16/0815/17/1317564_583418923.shtml 写的关于keras防止过拟合的
http://deeplearning.net/software/theano/tutorial/index.html关于theano的
http://keras-cn.readthedocs.io/en/latest/preprocessing/image/ http://blog.csdn.net/mrgiovanni/article/details/52169959关于keras入门的 https://keras.io/
http://mp.weixin.qq.com/s?__biz=MjM5MjAwODM4MA%3D%3D&idx=2&mid=2650687049&sn=4fadb5ae18a0da6208f56236a9bcad98
http://blog.christianperone.com/2016/01/convolutional-hypercolumns-in-python/
http://issuehub.io/?label%5B%5D=caffe
观察每层的输出 http://www.tuicool.com/articles/m6ZjYnm
对951张图train 对89张test 4个类
from keras.preprocessing.image import ImageDataGenerator,img_to_array, load_img
#旋转60度 随机平移、仿射变换 缩放 0.2的比例
datagen = ImageDataGenerator(rotation_range=60,width_shift_range=0.2,height_shift_range=0.2,shear_range=0.2,zoom_range=0.2,horizontal_flip=True,fill_mode='nearest')
#导入Keras模型和层模块
###########################################
from keras.models import Sequential
from keras.layers import Convolution2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
#第一个模型,一个很简单的3层卷积加上ReLU激活函数,再接池化层防止过拟合
model = Sequential()
model.add(Convolution2D(32,5, 5, input_shape=(3,128,128)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(32, 3, 3))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(64, 3, 3))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
# 压平层 拉成一维的特征向量
model.add(Flatten())
#then两个全连接网络,
model.add(Dense(128))
model.add(Activation('relu'))
#随机丢弃0.5比例的特征 防止过拟合
model.add(Dropout(0.5))
model.add(Dense(4))
model.add(Activation('softmax'))
##################################################################
#开始准备数据,使用.flow_from_directory()来从图片中直接产生数据和标签
train_datagen = ImageDataGenerator(rescale=1./255,shear_range=0.2,zoom_range=0.2,horizontal_flip=True)
# 测试的类
# only rescaling
test_datagen = ImageDataGenerator(rescale=1./255)
# 在指定文件夹下读取图片产生array数据和标签
# 目标大小是(128,128)
train_generator = train_datagen.flow_from_directory(
'train8.5',
target_size=(128,128),
batch_size=32,
class_mode='categorical',shuffle=True) #打乱数据标签
#测试的文件夹 打乱数据和标签
validation_generator = test_datagen.flow_from_directory(
'valiation8.5',
target_size=(128,128),
batch_size=32,
class_mode='categorical',shuffle=True)
##################################################################
#用这个生成器来训练网络 损失函数是categorical_crossentropy 优化器是rmsprop 进行编译
model.compile(loss="categorical_crossentropy", optimizer="rmsprop",metrics=["accuracy"])
#正式开始训练 并显示进度条
#model.fit_generator(train_generator,samples_per_epoch=951,nb_epoch=15,validation_data=validation_generator,nb_val_samples=89)
model.fit_generator(train_generator,samples_per_epoch=951,nb_epoch=15)
#model.save_weights('first_try.h5','rb') # 保存模型层的权重信息
score=model.predict_generator(validation_generator,val_samples=89)
print score
print validation_generator.classes
我是如上面写的 结果
 这是训练准确率
这是训练准确率
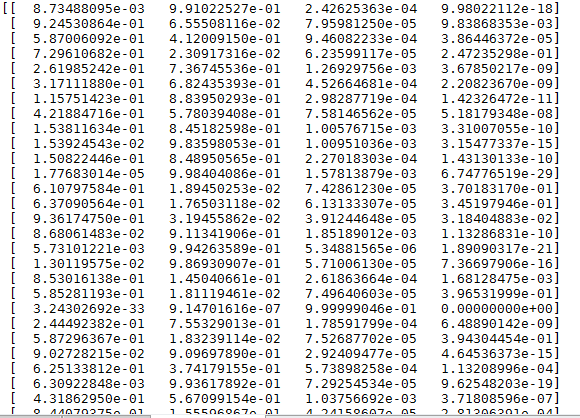 这是测试样本的预测标签 但我要的是测试样本的真实标签!
这是测试样本的预测标签 但我要的是测试样本的真实标签!
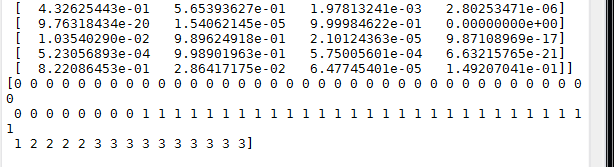 可是下面这个 不是啊 因为我
可是下面这个 不是啊 因为我
validation_generator = test_datagen.flow_from_directory( 'valiation8.5',target_size=(128,128),batch_size=32,class_mode='categorical',shuffle=True)
明明shuffle=True也就是说打乱了的 可是输出的却是没打乱的???而且怎么把预测标签 也就是概率矩阵 转化为标签矩阵啊 应该有直接转的函数的?
哎 我都烦死我自己了 不是深度学习的却要用深度学习 连函数都找不到 烦死了 都要吐了 哎烦躁
#####################################################################################################################################################################################################################################
帮同事 他做另一个项目的 他是一万多个样本 分2类
from keras.preprocessing.image import ImageDataGenerator,img_to_array, load_img
#旋转60度 随机平移、仿射变换 缩放 0.2的比例
datagen = ImageDataGenerator(rotation_range=60,width_shift_range=0.2,height_shift_range=0.2,shear_range=0.2,zoom_range=0.2,horizontal_flip=True,fill_mode='nearest')
#导入Keras模型和层模块
###########################################
from keras.models import Sequential
from keras.layers import Convolution2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
#第一个模型,一个很简单的3层卷积加上ReLU激活函数,再接池化层防止过拟合
model = Sequential()
model.add(Convolution2D(32,5, 5, input_shape=(3,128,128)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(32, 3, 3))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(64, 3, 3))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
# 压平层 拉成一维的特征向量
model.add(Flatten())
#then两个全连接网络,
model.add(Dense(128))
model.add(Activation('relu'))
#随机丢弃0.5比例的特征 防止过拟合
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))
##################################################################
#开始准备数据,使用.flow_from_directory()来从图片中直接产生数据和标签
# 训练的类
train_datagen = ImageDataGenerator(rescale=1./255,shear_range=0.2,zoom_range=0.2,horizontal_flip=True)
# 测试的类
# only rescaling
test_datagen = ImageDataGenerator(rescale=1./255)
# 在指定文件夹下读取图片产生array数据和标签
# 目标大小是(128,128)
train_generator = train_datagen.flow_from_directory(
'train8.16',
target_size=(128,128),
batch_size=80,
class_mode='binary',shuffle=True) #打乱数据标签
#测试的文件夹 打乱数据和标签
validation_generator = test_datagen.flow_from_directory(
'valiation8.16',
target_size=(128,128),
batch_size=80,
class_mode='binary',shuffle=True)
##################################################################
#用这个生成器来训练网络 损失函数是categorical_crossentropy 优化器是rmsprop 进行编译
model.compile(loss="binary_crossentropy", optimizer="rmsprop",metrics=["accuracy"])
#正式开始训练 并显示进度条
model.fit_generator(train_generator,samples_per_epoch=8020,nb_epoch=10,validation_data=validation_generator,nb_val_samples=2869)
#model.save_weights('first_try.h5') # 保存模型层的权重信息
结果: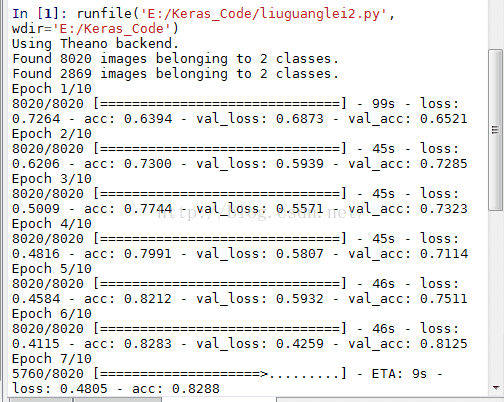
 感觉这个比我自己的好 因为他的训练精度是慢慢上升的 虽然测试精度不是一直跟着升 但好歹没降特别厉害 没过拟合 。。。。
感觉这个比我自己的好 因为他的训练精度是慢慢上升的 虽然测试精度不是一直跟着升 但好歹没降特别厉害 没过拟合 。。。。
######################################################################################################
又试了下我自己的分两类:
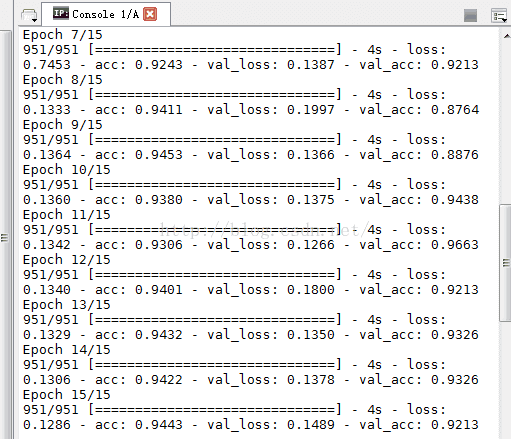 我自己的训练精度不是一直上升的 。。。 虽然总体是上升的。。。
我自己的训练精度不是一直上升的 。。。 虽然总体是上升的。。。
###########################################################################################################################
另外 ImageDataGenerator.flow_from_directory()是不是不管图片原本是三通道还是单通道 它产生都是3通道??是吗????
########################################################################################################################
不用上面的图片生成器生成数据和标签的类,用
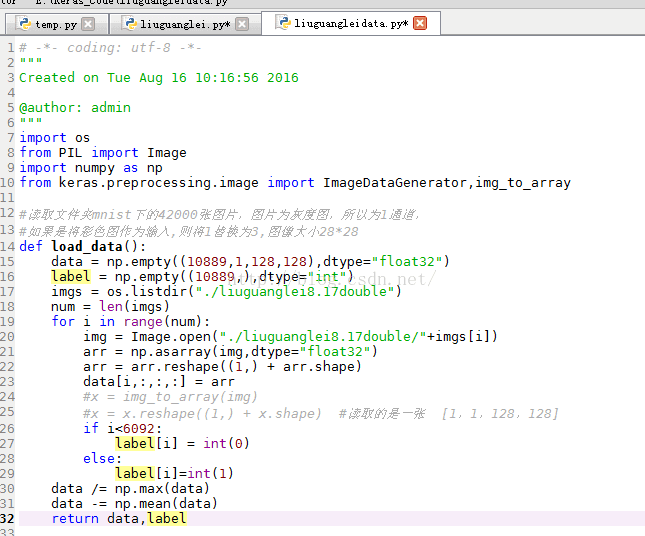 就是放到一个文件夹下 前0---6091属于第一类 后面的属于第2类
就是放到一个文件夹下 前0---6091属于第一类 后面的属于第2类
from __future__ import absolute_import
from __future__ import print_function
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation, Flatten
from keras.layers.convolutional import Convolution2D, MaxPooling2D
from keras.optimizers import SGD
from keras.utils import np_utils, generic_utils
from six.moves import range
from liuguangleidata import load_data
import random,cPickle
from keras.callbacks import EarlyStopping
import numpy as np
np.random.seed(1024) # for reproducibility
#加载数据
data, label = load_data()
#label为0~9共10个类别,keras要求形式为binary class matrices,转化一下,直接调用keras提供的这个函数
nb_class = 2
def create_model():
model = Sequential()
model.add(Convolution2D(32, 5, 5, border_mode='valid',input_shape=(1,128,128)))
model.add(Activation('relu'))
model.add(Convolution2D(32,3, 3, border_mode='valid'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(64,3, 3, border_mode='valid'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten()) # this converts our 3D feature maps to 1D feature vectors
model.add(Dense(128))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))
return model
#############
#开始训练模型
##############
model = create_model()
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='binary_crossentropy', optimizer=sgd,metrics=["accuracy"])
index = [i for i in range(len(data))]
random.shuffle(index)
data = data[index]
label = label[index]
(X_train,X_val) = (data[0:9000],data[9000:])
(Y_train,Y_val) = (label[0:9000],label[9000:])
#使用early stopping返回最佳epoch对应的model
early_stopping = EarlyStopping(monitor='val_loss', patience=1)
model.fit(X_train, Y_train, batch_size=30,validation_data=(X_val, Y_val),nb_epoch=5,callbacks=[early_stopping])
结果,话说模型层和上面的一样 只是一个是用的图片生成器 一个没有图片预处理用的sgd 结果差别这么大???: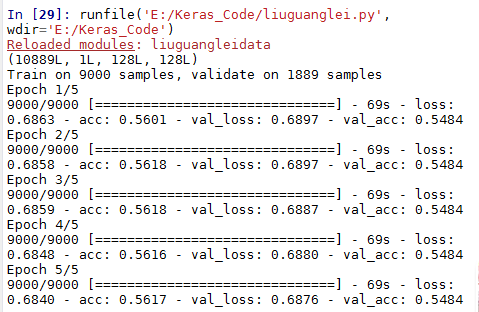 是因为它实际就是这样 还是我模型设置得不好????
是因为它实际就是这样 还是我模型设置得不好????
##################################################################################################################
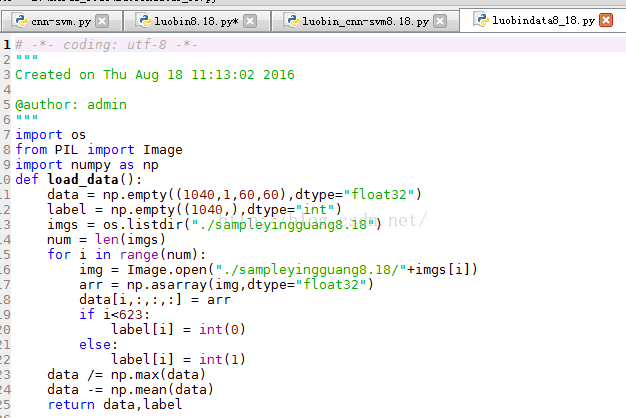
换了我自己的数据 同样不进行图片预处理 直接在一个文件夹中读取图片 但我的样本只有1040个 总的
from __future__ import absolute_import
from __future__ import print_function
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation, Flatten
from keras.layers.convolutional import Convolution2D, MaxPooling2D
from keras.optimizers import SGD
from keras.utils import np_utils, generic_utils
from six.moves import range
from luobin_data2 import load_data
import random,cPickle
from keras.callbacks import EarlyStopping
import numpy as np
np.random.seed(1024) # for reproducibility
#加载数据
data, label = load_data()
#label为0~9共10个类别,keras要求形式为binary class matrices,转化一下,直接调用keras提供的这个函数
nb_class = 2
def create_model():
model = Sequential()
model.add(Convolution2D(32, 5, 5, border_mode='valid',input_shape=(1,128,128)))
model.add(Activation('relu'))
model.add(Convolution2D(32,3, 3, border_mode='valid'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(64,3, 3, border_mode='valid'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten()) # this converts our 3D feature maps to 1D feature vectors
model.add(Dense(128))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))
return model
#############
#开始训练模型
##############
model = create_model()
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='binary_crossentropy', optimizer=sgd,metrics=["accuracy"])
index = [i for i in range(len(data))]
random.shuffle(index)
data = data[index]
label = label[index]
(X_train,X_val) = (data[0:900],data[900:])
(Y_train,Y_val) = (label[0:900],label[900:])
#使用early stopping返回最佳epoch对应的model
early_stopping = EarlyStopping(monitor='val_loss', patience=1)
model.fit(X_train, Y_train, batch_size=30,validation_data=(X_val, Y_val),nb_epoch=5,callbacks=[early_stopping])
结果:
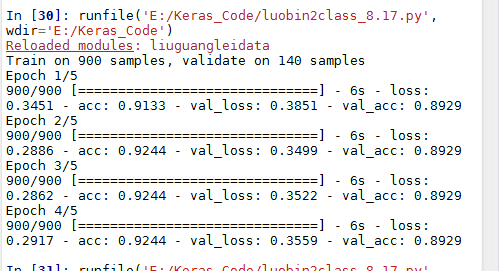
我换了损失函数 从binary_crossentropy换为mse 结果:
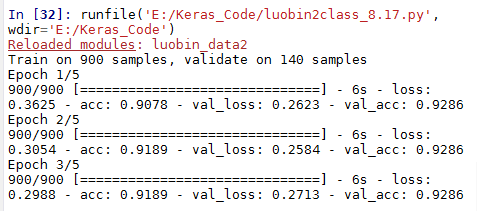
我奇怪的是 第三次就收敛了?测试精度没有动?
######################
我把上面的 改为sgd = SGD(lr=0.005, decay=1e-6, momentum=0.9, nesterov=True) 调小学习速率 结果:
 一动不动?过拟合了??
一动不动?过拟合了??
那么改成下面这样:

结果:
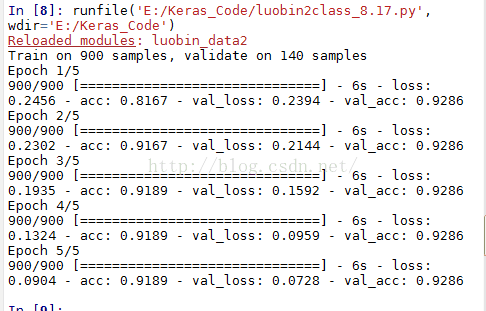 一样不动 ?可是val_loss在下降 算过拟合吗?
一样不动 ?可是val_loss在下降 算过拟合吗?
###############################################################################################################
新数据 重新来:
from __future__ import absolute_import
from __future__ import print_function
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation, Flatten
from keras.layers.convolutional import Convolution2D, MaxPooling2D
from keras.optimizers import SGD,Adadelta
import keras.regularizers
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.preprocessing import MinMaxScaler
import theano
#from keras.utils import np_utils, generic_utils
from six.moves import range
from luobindata8_18 import load_data
import random,cPickle
from keras.callbacks import EarlyStopping
import numpy as np
np.random.seed(1024)
data, label = load_data()
def create_model():
model = Sequential()
model.add(Convolution2D(32, 5, 5, border_mode='valid',input_shape=(1,60,60)))
model.add(Activation('relu'))
model.add(Dropout(0.3))
model.add(Convolution2D(32,3, 3, border_mode='valid'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.3))
model.add(Convolution2D(64,3, 3, border_mode='valid'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.3))
model.add(Flatten()) # this converts our 3D feature maps to 1D feature vectors
model.add(Dense(128))
model.add(Activation('relu'))
model.add(Dropout(0.3))
model.add(Dense(1))
model.add(Activation('sigmoid'))
return model
#############
#开始训练模型
##############
model = create_model()
#sgd = SGD(lr=0.001, decay=1e-8, momentum=0.9, nesterov=True)
#model.compile(loss='binary_crossentropy', optimizer=sgd,metrics=["accuracy"])
sgd = SGD(lr=0.005, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='binary_crossentropy', optimizer=sgd,metrics=["accuracy"])
#adadelta=Adadelta(lr=1.0, rho=0.95, epsilon=1e-09)
#model.compile(loss='mse', optimizer=adadelta,metrics=["accuracy"])
#model.compile(loss="binary_crossentropy", optimizer=adadelta,metrics=["accuracy"])
index = [i for i in range(len(data))]
random.shuffle(index)
data = data[index]
label = label[index]
(X_train,X_val) = (data[0:900],data[900:])
(Y_train,Y_val) = (label[0:900],label[900:])
#使用early stopping返回最佳epoch对应的model
early_stopping = EarlyStopping(monitor='val_loss', patience=1)
#model.fit(X_train, Y_train,callbacks=[early_stopping])
model.fit(X_train, Y_train, batch_size=30,validation_data=(X_val, Y_val),nb_epoch=15,callbacks=[early_stopping])
pre_label=model.predict_classes(X_val)
print('true test label:')
print(Y_val)
print('cnn test label:')
print(pre_label)
cPickle.dump(model,open("./model8.18.pkl","wb"))
结果:
 把模型也存在了目录下 然后我想接着用SVM分类
把模型也存在了目录下 然后我想接着用SVM分类
from __future__ import print_function
import cPickle
import theano
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.preprocessing import MinMaxScaler
from luobindata8_18 import load_data
import random
def svc(traindata,trainlabel,testdata,testlabel):
print("Start training SVM...")
svcClf = SVC(C=1.0,kernel="rbf",cache_size=900)
svcClf.fit(traindata,trainlabel)
pred_testlabel = svcClf.predict(testdata)
num = len(pred_testlabel)
accuracy = len([1 for i in range(num) if testlabel[i]==pred_testlabel[i]])/float(num)
print("cnn-svm Accuracy:",accuracy)
def rf(traindata,trainlabel,testdata,testlabel):
print("Start training Random Forest...")
rfClf = RandomForestClassifier(n_estimators=2,criterion='gini')
rfClf.fit(traindata,trainlabel)
pred_testlabel = rfClf.predict(testdata)
num = len(pred_testlabel)
accuracy = len([1 for i in range(num) if testlabel[i]==pred_testlabel[i]])/float(num)
print("cnn-rf Accuracy:",accuracy)
if __name__ == "__main__":
#load data
data, label = load_data()
#shuffle the data
index = [i for i in range(len(data))]
random.shuffle(index)
data = data[index]
label = label[index]
(traindata,testdata) = (data[0:900],data[900:])
(trainlabel,testlabel) = (label[0:900],label[900:])
#use origin_model to predict testdata
origin_model = cPickle.load(open("model8.18.pkl","rb"))
#print(origin_model.layers)
pred_testlabel = origin_model.predict_classes(testdata)
#print(pred_testlabel)
num = len(testlabel)
accuracy = len([1 for i in range(num) if testlabel[i]==pred_testlabel[i]])/float(num)
print(" Origin_model Accuracy:",accuracy)
#define theano funtion to get output of FC layer
get_feature = theano.function([origin_model.layers[0].input],origin_model.layers[9].output,allow_input_downcast=False)
feature = get_feature(data)
#train svm using FC-layer feature
scaler = MinMaxScaler()
feature = scaler.fit_transform(feature)
svc(feature[0:900],label[0:900],feature[900:],label[900:])
rf(feature[0:900],label[0:900],feature[900:],label[900:])
结果报错了 在提取特征这里 get_feature = theano.function([origin_model.layers[0].input],origin_model.layers[9].output,allow_input_downcast=False)我知道这个的意思就是自变量是第0层的输入 因变量是第9层的输出 找到它们的关系的函数为get_feature,然后以data为新自变量 这样就可以得到data对应的新输出即data所对应的特征
 为什么 是按照cnn-svm.py改的 那个就很好啊 这里总是说这个错???哦我知道了 官方例子的model.add(Flatten())在第9层 所以它写的9 而 我的model.add(Flatten())在第12层 所以9应该改为12 可是改了还是不对啊??
为什么 是按照cnn-svm.py改的 那个就很好啊 这里总是说这个错???哦我知道了 官方例子的model.add(Flatten())在第9层 所以它写的9 而 我的model.add(Flatten())在第12层 所以9应该改为12 可是改了还是不对啊??
最后我只能到github上去问了 :

https://github.com/fchollet/keras/issues/431 最终瞎找到了原因 不能以rb即二进制load一个model 这样的话theano.function()和K.function()就报错说:
MissingInputError: ("An input of the graph, used to compute DimShuffle{x,x,x,x}(keras_learning_phase), was not provided and not given a value.Use the Theano flag exception_verbosity='high',for more information on this error.", keras_learning_phase)
我改用了
json_string = model.to_json()
open('savemodel8.20.json','w').write(json_string)
model.save_weights('savemodel_weights8.20.h5')
这样保存模型 再这样load 模型:
origin_model = model_from_json(open('savemodel8.20.json').read())
origin_model.load_weights('savemodel_weights8.20.h5')
import keras.backend as K
f = K.function([K.learning_phase(), origin_model.layers[0].input], [origin_model.layers[13].output])
这样在theano.function()或K.function()就不报那个错误了。我的是这样解决的。
然而,最开始那层和Flatten层的关系f得到了,但我接下来把data输进去想看变成行向量的特征时,出错了!
File "E:/Keras_Code/luobin_cnn-svm8.18.py", line 79, in
feature=f(data)
File "C:\Anaconda2\lib\site-packages\keras\backend\theano_backend.py", line 561, in __call__
assert type(inputs) in {list, tuple}
AssertionError
我的data明明和第0层input_shape=(1,60,60)一致的 怎么还报这个错呢?原来是要我输入列表list 所以我改成了feature=f([data]) 错误变成: TypeError: ('Bad input argument to theano function with name "C:\\Anaconda2\\lib\\site-packages\\keras\\backend\\theano_backend.py:558" at index 0(0-based)', 'Wrong number of dimensions: expected 0, got 4 with shape (1040L, 1L, 60L, 60L).')
这又是闹哪样?我定义model的时候第1层是model.add(Convolution2D(32, 5, 5, border_mode='valid',input_shape=(1,60,60))) 那么它应该显示number of dimensions: expected 3,才对啊 它怎么expected 0呢?