读后感背景
工作中要对高分辨率图像(至少1024 \(\times\) 1024)进行分类,而且ground-truth分类的标准一般都是取决于像素级别的精细local feature(e.g. texture),图像中大致的global feature (e.g. spatial arrangement)不是很重要。大多数生物医学图像分类都属于这类,这就导致了很多传统的CNN不适用于医学图片的分类,比如AlexNet, VGG等。
论文[Patch-based Convolutional Neural Network for WholeSlide Tissue Image Classification]为此类问题提出了 一个解决方案。基本原理就是把一个高分辨率图像分成很多小patch,然后对每个patch做patch-level classification,最后集合patch-level classification得到一个image-level classification。
这种解决方案基于多示例学习(Multiple Instance Learning),这里的image—>patch对应着多示例学习中的bag—>instance。label对应着image,但是patch是没有groud-truth label的。因此多示例学习也属于弱监督学习。
论文中提出了patch-level classifier和decesion fusion model。patch-level classifier就是给每一个patch打上标签,通过CNN进行训练。decesion fusion model是把一个image里上一步得到的所有patch标签结合起来,得到一个image标签。下面的图基本上就是论文用的方法,上面为patch-level classifier,下面是decesion fusion model。
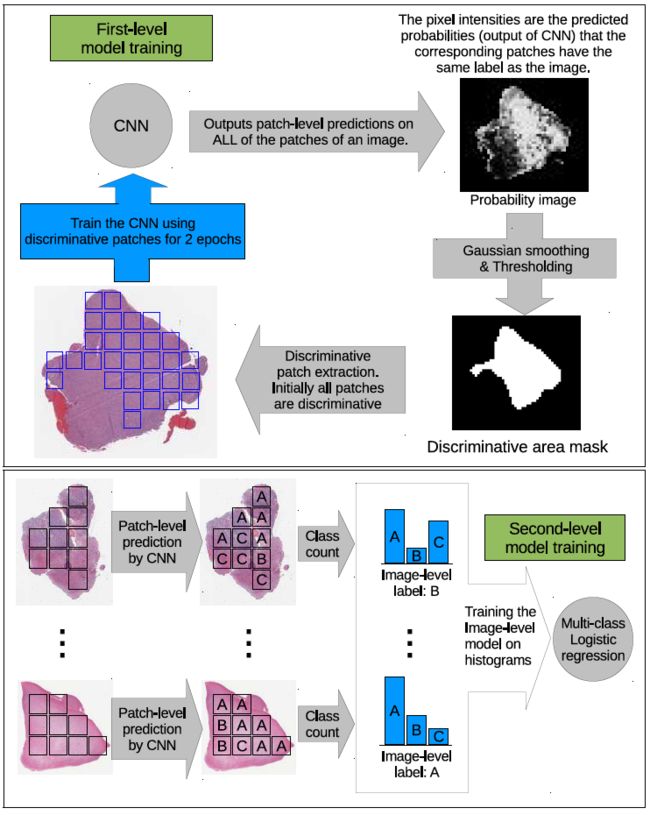
decesion fusion model的实现很简单,从简易的max pooling, average pooling 和 voting,到机器学习中的SVM,logistic regression,再到深度学习里的神经网络都可以实现。变种很多,就不一一介绍了。
读后感主体
本编读后感重点思考一下patch-level classifier,因为文中提到:Furthermore, we formulate a novel Expectation-Maximization (EM) based method that automatically locates discriminative patches robustly by utilizing the spatial relationships of patches. 意思就是在做decesion fusion的时候,不是所有的patch的标签都被fuse在一起的,因为有一些patch只是背景或者对分类结果没啥影响。(虽然我个人觉得这步用处不大,都把image分成很多patch了,还多此一举,这样也不能节省很多时间吧,具体文中对结果的影响好像也不大)。
对于怎么用EM的方式选出 discriminative patches,文中一开始用了很多数学推导,先介绍数学标志。

对于一个patch怎么才能叫discriminative,文中说到: Patches \(x_{i,j}\) that have \(P(H_{i,j} | X)\) larger than a threshold \(T_{i,j}\) are considered discriminative and are selected to continue training the CNN.
对于什么是\(P(H_{i,j} | X)\) ,文中又说 :\(P(H_{i,j} | X)\) is obtained by applying Gaussian smoothing on $P(y_{i, j}| x_{i,j} ; \theta) $
结合这两句话就总结成:一个patch到底discriminative与否取决与它自身预测结果中,对应image label的confidence score。这个image label指的是这个patch对应的image的ground-truth label,所以这个patch在训练的时候可以被分成其他类(i.e. 其对应image的label的confidence score不是最大),而只是在patch的预测结果中,只要对应image类别的confidence score比阈值大,这个patch就可以是discriminative。
明确了discriminative patch的定义之后,我们就可以看看论文中如何用EM和deep learning的形式来确定一个patch的discriminativeness了。

首先,初始化时候,把所有的patch都看成discriminative,意思就是第一次迭代的时候把所有patch都用上,这个\(H_{i,j}=1\)和神经网络参数初始化并没有关系。


在M步里,通过一系列假设,最后的目标就是公式(4),其中\(P(y_i|x_{i,j})P(x_{i,j})\)的最大化可以用cross-entropy loss作为loss function的神经网络达成。具体推倒看上面的手写图。这里\(P(y_i|x_{i,j})\)就是\(y_i\) given \(x_{i,j}\)的后验概率:posterior is the conditional probability of obersving the actual output \(y_{i}\) given the input \(x_{i,j}\) with regard to weights \(\theta\).
至于公式(4)里面的\(P(x_{i,j})\),可能直接省略了吧。这里其实还没有太搞懂,如果有看到这篇读后感的大神请不吝赐教!!!

最后,在E步里,用神经网络经过softmax层的输出\(P(y_i|x_{i,j})\)加上一些Gaussian smoothing来得到\(P(H_{i,j}|X)\)的值,然后通过把\(P(H_{i,j}|X)\)和设定好的阈值比较,来确定patch是否是discriminative。阈值设定和比较上具体还有些细节,就不赘述了。之后把E步里判定是discriminative的patch再用做M步的网络学习。
所以整个学习的过程就是通过EM迭代来确定网络参数。网络的学习(SGD)是在M步里完成的,每次M步网络参数经过几个epoch的更新。然后在E步里,更新完参数的网络再对所有patch进行discriminative判定,判定成功的patch再去到M去帮助网络参数学习。这样EMEMEM轮回,最后达到收敛条件后(收敛条件貌似是discriminative patch的判断不再改变了)结束patch-level classifier的训练。然后放到decesion fustion model里去预测。
读后感总结
这就是我对这篇文章[Patch-based Convolutional Neural Network for Whole Slide Tissue Image Classification]的理解,其中可能有很多偏差或者不对的地方。因为作者并没有提供源代码,网上找到的第三方代码貌似也不能复现。希望有关注这篇文章的同学读过之后,可以和我留言讨论,看看我上述理解对不对,谢谢!