Spark集群安装配置
1 Spark概述
1、Spark是一个计算框架
MR是批量计算框架,Spark-Core是批量计算框架
Spark相比MR速度快,MR作为一个job,在中间环节中结果是落地的(会经过磁盘交换),Spark计算过程中数据流转都是在内存的(减少了对HDFS的依赖)
MR:多进程模型(缺点:每个任务启动时间长,所以不适合于低延迟的任务
优点:资源隔离,稳定性高,开发过程中不涉及内存锁(互斥锁、读写锁)的开发)
Spark:多线程模型(缺点:稳定性差
优点:速度快,适合低延迟的任务,适合于内存密集型任务)
一个机器节点,所有的任务都会运载jvm进程(executor进程),
每一个进程包含一个executor对象,在对象内部会维持一个线程池,提高效率,每一个线程执行一个task
2、Spark的运行模式:
(1)单机模式:方便人工调试
(2)Standalone模式:自己独立一套集群(master/client/slave),缺点:资源不利于充分利用
(3)Yarn模式:
1)Yarn-Client模式:Driver运行在本地
适合交互调试
2)Yarn-Cluster模式:Driver运行在集群(AM)
正式提交任务的模式(remote)
2 Spark安装地址
1.官网地址:http://spark.apache.org/
2.文档查看地址:https://spark.apache.org/docs/2.1.1/
3.下载地址:https://spark.apache.org/downloads.html
3 Spark安装配置
3.1 Standalone模式安装
(1)上传并解压spark安装包
[caimh@master-node software]$ tar -zxvf spark-2.1.1-bin-hadoop2.7.tgz -C /opt/module/
[caimh@master-node module]$ mv spark-2.1.1-bin-hadoop2.7/ spark-2.1.1(2)进入spark安装目录下的conf文件夹,修改配置文件名称
[caimh@master-node module]$ cd /opt/module/spark-2.1.1/conf/
[caimh@master-node conf]$ mv slaves.template slaves
[caimh@master-node conf]$ mv spark-env.sh.template spark-env.sh(3)修改slave文件,添加work节点
[caimh@master-node conf]$ vim slaves
slave-node1
slave-node2(4)修改spark-env.sh文件,指定SPARK_MASTER_HOST和SPARK_MASTER_PORT: 46 47 行
Worker与master之间进行通信(worker连接,通信,注册)
worker怎么知道Master在哪里?读取spark-env.sh文件得知的。如下面配置文件。
[caimh@master-node conf]$ vim spark-env.sh
SPARK_MASTER_HOST=master-node
SPARK_MASTER_PORT=7077(5)分发spark
[caimh@master-node module]$ xsync spark-2.1.1/(6) 启动
[caimh@master-node spark-2.1.1]$ sbin/start-all.sh
[caimh@master-node spark-2.1.1]$ jps
11794 Jps
11720 Master
[caimh@slave-node1 conf]$ jps
6747 Jps
6701 Worker
[caimh@slave-node2 spark-2.1.1]$ jps
7600 Worker
7676 Jps注意:如果遇到 “JAVA_HOME not set” 异常,可以在sbin目录下的spark-config.sh 文件中加入如下配置:
export JAVA_HOME=XXXX

(8) 查看网页spark管理页面(master所在机器的地址+8080端口)

3.2 YARN模式安装
Yarn集群与Standalone集群没有关系,不需要配置master,slave结构,只需要配置jar包的client提交端,让提交端能够发现hadoop的一些配置
(1)修改hadoop配置文件yarn-site.xml,添加如下内容:
(2)进入conf目录,修改spark-env.sh,添加如下配置:--client提交端
[caimh@master-node conf]$ vim spark-env.sh
YARN_CONF_DIR=/opt/module/hadoop-2.7.4/etc/hadoop
HADOOP_CONF_DIR=/opt/module/hadoop-2.7.4/etc/hadoop配置文件不需要分发
4 Spark验证
4.1 本地模式
[caimh@master-node spark-2.1.1]$ ./bin/run-example SparkPi 10 --master local[2]
4.2 Standalone集群模式
[caimh@master-node spark-2.1.1]$ ./bin/spark-submit \
> --class org.apache.spark.examples.SparkPi \
> --master spark://master-node:7077 \
> ./examples/jars/spark-examples_2.11-2.1.1.jar 100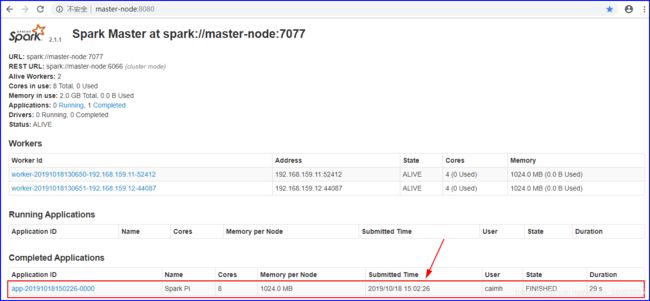

4.3 Yarn模式
在3.2安装基础上,执行案例程序
[caimh@master-node spark-2.1.1]$ ./bin/spark-submit \
> --class org.apache.spark.examples.SparkPi \
> --master yarn-cluster \ --yarn-cluster模式
> ./examples/jars/spark-examples_2.11-2.1.1.jar 10注意:在提交任务之前需启动HDFS以及YARN集群。
Yarm模式启动,无法在Spark的UI界面master-node:8080查看执行情况。只能在yarn的UI界面查看应用执行情况。下·

5 JobHistoryServer配置
(1)修改spark-default.conf.template名称,并开启Log
[caimh@master-node conf]$ cp spark-defaults.conf.template spark-defaults.conf
[caimh@master-node conf]$ vim spark-defaults.conf
spark.eventLog.enabled true
spark.eventLog.dir hdfs://master-node:9000/directory注意:HDFS上的目录hdfs://master-node:9000/directory需要提前存在。
(2)修改spark-env.sh文件,添加如下配置:
[caimh@master-node conf]$ vim spark-env.sh
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=4000
-Dspark.history.retainedApplications=3
-Dspark.history.fs.logDirectory=hdfs://hadoop102:9000/directory"
参数描述:
spark.eventLog.dir:Application在运行过程中所有的信息均记录在该属性指定的路径下;
spark.history.ui.port=4000 调整WEBUI访问的端口号为4000
spark.history.fs.logDirectory=hdfs://hadoop102:9000/directory 配置了该属性后,在start-history-server.sh时就无需再显式的指定路径,Spark History Server页面只展示该指定路径下的信息
spark.history.retainedApplications=3 指定保存Application历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数。
(3)分发配置文件
[caimh@master-node spark-2.1.1]$ xsync conf/(4)启动历史服务器
[caimh@master-node spark-2.1.1]$ sbin/start-history-server.sh
[caimh@master-node spark-2.1.1]$ jps
15072 Jps
12659 Master
12918 ResourceManager
15032 HistoryServer --Spark历史服务器
13034 NodeManager
13532 NameNode
14222 JobHistoryServer
13646 DataNode(6)再次执行任务
[caimh@master-node spark-2.1.1]$ ./bin/spark-submit \
> --class org.apache.spark.examples.SparkPi \
> --master spark://master-node:7077 \
> ./examples/jars/spark-examples_2.11-2.1.1.jar 100(7)查看历史服务http://master-node:4000/

查看日志的2种方式:
1)对于正在运行的应用,直接访问http://master-node:4040
2) 对于已经结束的应用,直接访问http://master-node:4000
日志生成是存储在HDFS中,日志存储不需要开启历史服务器,通过UI查看历史日志信息,需要开启历史服务器。