论文阅读笔记(visual relation相关)—Exploring Visual Relationship for Image Captioning
《探索图像描述的视觉关系》
这是京东AI研究院被2018ECCV收录的一篇关于图像描述的文章。
这篇文章提出了一种新的模型,是GCN+LSTM的结构,整合了语义信息和空间位置信息到图像编码器。
image caption问题的典型解决方案是受机器翻译启发的,相当于将图像翻译为文本。
图像中的物体可能有各种尺度,可能在图像中的任意位置, 以及他们是不同的类别,这样就比较难以确定关系的类别。
本文是利用对象间的固有关系来全面的解释图像,并新颖的使用视觉连接来增强用于图像描述的image编码器。基本设计是在语义和空间层面上建模关系,并将连接connecttions整合到编码器中,以产生关系感知(relation-aware)区域级的表示。如此当进入句子解码器时,能够赋予图像表示更多的信息。
具体提出的结构是下面c的结构:

首先是用Faster R-CNN来提取出一组图像中显著的一些区域。
然后构建语义图,边将检测到的区域直接连接起来,顶点表示检测到的区域,边表示关系(predicate),关系是通过在visual genome数据集学习到的语义关系检测器预测得到的。
类似的,还构建了空间图,顶点还是表示检测到的区域,边表示的是区域之间的相对几何关系。
然后利用图卷积网络GCN,在建立的语义图和空间图上表示的视觉关系来丰富区域表示。
然后,学习到的每种关系的关系感知区域表示送入一个单独的attention LSTM解码器,来生成句子。
在推理阶段,为了融合两个解码器的输出,在每个time step,对两个解码器预测的单词的预测得分分布进行线性平均,并且弹出具有最大概率的词作为两个解码器在下一个time step的输入单词。
模型整体的结构如下:
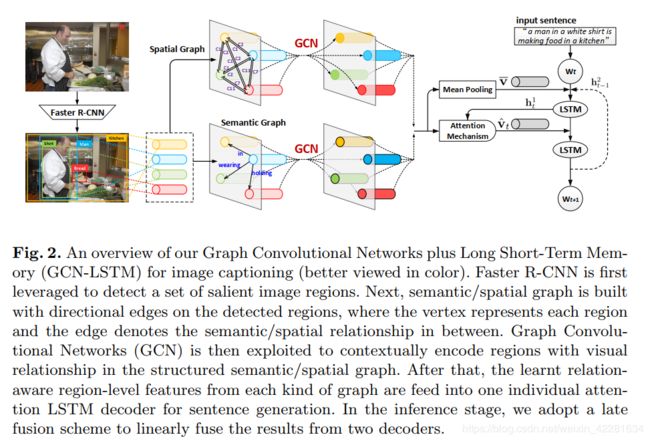
首先是用Faster R-CNN来提取一系列图像中突出的图像区域。然后利用提取出来的图像区域进行构建空间图和语义图。顶点表示区域,边表示区域之间的语义关系或是空间关系。然后用GCN 在结构化的语义和空间图上的视觉关系进行上下文编码。然后得到这些学习后区域级别的关系感知的特征,然后分别送入一个独立的attention LSTM解码器用于句子生成。在推理阶段,是采用后期融合方案来线性融合两个解码器的结果。
问题制定:
假设有一张图I,有一个描述这张图的句子S,这个句子S有Ns个单词,
![]()
![]()
表示的是每一个单词都是Ds维的文字特征,wt表示句子S中第t个单词的文字特征。
Faster R-CNN提取特征,得到
![]()
K个检测到的区域,区域中包含检测到的物体。每一个区域的特征都是Dv维。
以检测到的区域为顶点构建语义图
![]() ,
,
和空间图
![]()
后面的表示语义关系和空间关系的边的集合。
对于句子生成问题,定义这样一个损失函数:

这是一个负对数概率。用
![]()
来简化表示形式。
负对数概率通常用交叉熵损失来衡量,这不可避免的会导致训练和推理之间的评估差异。
为了修正这种差异,优化LSTM,用预期的句子级别的奖励损失。
图像中的objects之间的视觉关系
semantic object relationship
语义关系是有方向的。因此有两种检测的区域,vi表示subject,vj表示object。定义了一个简单的深度分类模型来预测vi和vj之间的语义关系,是基于两个区域的bbox的并集区域。
语义关系检测的模型如下:

红色是subject,蓝色是object,黄色是并集。
将两个区域的特征和两个区域的并集特征分别经过一个嵌入层,然后连接到一个N+1个类别的语义关系分类层,给出softmax概率。
Dv是2048维。
在训练这个分类器之后,使用它来构建语义图。
检测到K个region,组成K(K-1)个对象对。然后计算这些对在N+1个语义类别上的分类概率。如果在“没有关系”这个类别的概率不超过0.5,则这个对象对之间的边就建立了,然后relation分类概率最大的类别,就是这条边的标签。
Spatial Object relationship
语义图只是展现了对象对之间的固有联系,缺少空间关系。
因此构建空间图。
在这,空间关系用《objecti–objectj》来表示,来表示j相对于i的相对几何位置。
边和类别标签是依据IOU进行建立和给出的,与两者之间的相对距离和角度相关。
具体有哪些种类按照下面的类别进行分类:
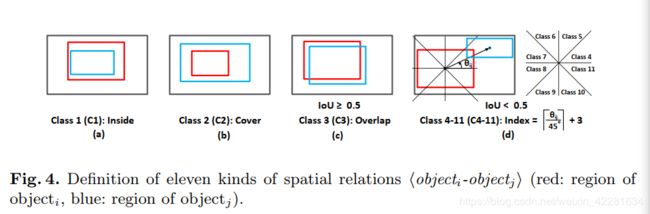
红色表示i,蓝色表示j,关系对表示的是j相对于i的关系。
对于两个区域i和j,用坐标(xi,yi)和(xj,yi)表示区域的质心。然后根据距离公式:
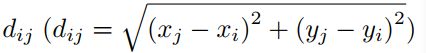
来表示相对距离;
相对角度:
![]()
首先是两种特殊关系,一种是inside,另一种是cover。
除了两种特殊情况以外,如果IOU大于0.5,直接给定两者之间的edge,并分类为overlap。
若果IOU的值小于0.5,主要是依据相对角度进行分类:
![]()
以上,完成了空间关系的分类,并构建空间图。
用视觉关系来进行图像描述
GCN-based image encoder
图卷积网络通畅用于无向图,对于每个顶点用于其有真实连接的邻接顶点来进行更新:
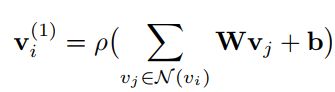
W是转换矩阵,b是偏置向量, ρ \rho ρ表示激活函数,relu;N(vi)表示所有vi的邻接顶点,包括自身。
这种更新的方式没有用到方向信息,并且边的label也没有考虑,因此使用一种新的GCN来进行语义图和空间图的更新:
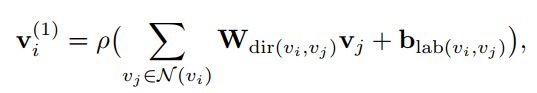
dir(vi,vj)表示的是选择传输矩阵来选择方向,例如W1表示从vi到vj的传输矩阵,W2表示vj到vi,W3表示vi到vi自身。
lab(vi,vj)表示边的label。
并不是从所有相连的顶点中同样的获取信息,是加入一个逐边的门控单元来自动的聚焦于那些重要的边。
因此每个顶点vi最终的更新形式:
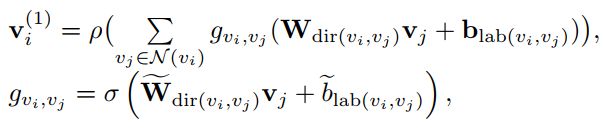
g v i , v j g_{v_i,v_j} gvi,vj表示计算得到的比例因子, σ \sigma σ表示logistic sigmoid函数

![]()
表示传输矩阵,
![]()
表示偏置。
经过改进的GCN网络后,每一个region特征其中赋予了视觉关系信息。
Attention LSTM sentence decoder
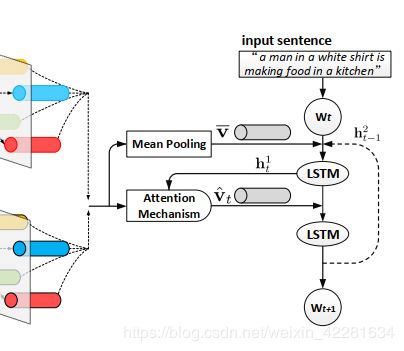
文中定义attention LSTM解码器将所有的relation-aware 的region特征(即上面经过GCN更新的特征)输入到一个两层的带有attention机制的LSTM网络。
解码的结构如上图所示。
解码器首先通过连接输入单词wt和第二层LSTM单元的上一个输出 h t − 1 2 h_{t-1}^2 ht−12以及平均池化的图像特征

这三者来收集最大上下文信息,然后将其作为第一层LSTM单元的输入。计算方式为:

Ws是输入单词的传输矩阵, h t 1 h_t^1 ht1表示第一层LSTM单元的输出,f1是第一层lstm单元的更新函数。
然后在输出 h t 1 h_t^1 ht1的基础上,进行attention分布的计算:
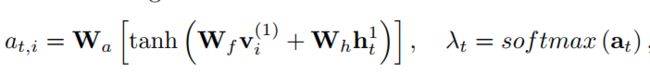
a t , i a_{t,i} at,i是at向量的第i个元素,Wa,Wf,Wh是传输矩阵。 λ t \lambda_t λt表示attention分布,其中第i个元素 λ t , i \lambda_{t,i} λt,i表示第i个结点
![]()
(也可以说是区域)的attention 概率。
在此基础上,对图像特征区域进行加权:
![]()
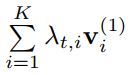
然后将加权后的特征和第一层LSTM单元的输出连接,经过第二层LSTM的单元,得到输出:

f2是第二层LSTM单元的更新函数。输出 h t 2 h_t^2 ht2通过softmax层来预测下一个单词。
然后循环往复,得到预测的句子。
训练和推理
训练阶段,预先建立两种视觉图。每种图分别用于训练一个单独的GCN编码器和一个attentionLSTM的解码器。LSTM解码器可以通过常用的交叉熵损失函数来优化,或者是[22,31]中提到的句子级别的奖励损失函数来优化。
融合两种特征的方案:

推理阶段,采用后期融合方案来连接两个视觉图。
具体的是,在每一个time step,融合两个解码器的输出给出的预测单词分布,然后弹出拥有最大概率单词作为下一个time step的输入。
每一单词wi的融合概率按如下式子进行计算:
![]()
α \alpha α是一个折中参数,这两个概率表示解码器给出的每个单词的预测概率,两个解码器是分别用语义图和空间图来进行训练的。
实验结果:

