hadoop2.7.7完全分布式及HA步骤安装(二)之真的很扎心的hbase-1.4.9的安装(史上最全)
环境变量
export HBASE_HOME=/usr/local/hbase-1.4.9
export PATH=$HBASE_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin:$HADOOP_HOME/bin:$SCALA_HOME/bin:$JAVA_HOME/bin:$PATH
- hbase-env.sh
添加
#Java环境
export JAVA_HOME=/usr/local/jdk1.8
#通过hadoop的配置文件找到hadoop集群
export HBASE_CLASSPATH=/home/hadoop/hadoop-2.7.3/etc/hadoop
#使用HBASE自带的zookeeper管理集群
export HBASE_MANAGES_ZK=false
注释这两行
![]()
- hbase-site.xml
<configuration>
<property>
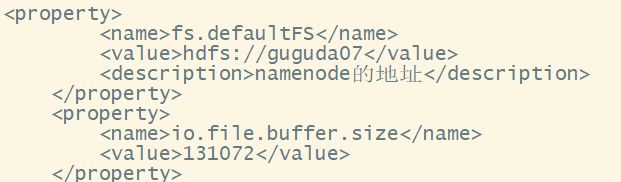
<!--这里要和hadoop下的配置文件core-site.xml的<name>fs.defaultFS</name>值hdfs://guguda07:9000一致-->
<name>hbase.rootdir</name>
<value>hdfs://guguda07:9000/hbase</value>
</property>
<!--启用分布式集群-->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!--默认HMaster HTTP访问端口-->
<property>
<name>hbase.master.info.port</name>
<value>16010</value>
</property>
<!--默认HRegionServer HTTP访问端口-->
<property>
<name>hbase.regionserver.info.port</name>
<value>16030</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>guguda07:2181,guguda08:2181,guguda08:2181</value>
</property>
<!--是否加入协处理器-->
<property>
<name>hbase.coprocessor.abortonerror</name>
<value>false</value>
</property>
</configuration>
参数
- hbase.rootdir
这个目录是 RegionServer 的共享目录,用来持久化 HBase。URL 需要是 “完全正确” 的,还要包含文件系统的 scheme。 例如 “/hbase” 表示 HBase 在 HDFS 中占用的实际存储位置,HDFS 的 NameNode 运行在主机名为 master5 的 8020 端口,则 hbase.rootdir 的设置应为 “hdfs://master5:8020/hbase”。在默认情况下 HBase 是写在 /tmp 中的。不修改这个配置的话,数据会在重启的时候丢失。特别注意的是 hbase.rootdir 里面的 HDFS 地址是要跟 Hadoop 的 core-site.xml 里面的 fs.defaultFS 的 HDFS 的 IP 地址或者域名、端口必须一致。
默认为 file:///tmp/hbase-${user.name}/hbase
- regionservers
给conf下的regionservers中添加regionservers
guguda07
guguda08
guguda09
启动hbase,bin下的start-hbase.sh
在哪个节点启动start-hbase.sh命令,哪个节点就是Hmaster
启动一会后master和regionserver服务会消失,原因是没启动zookeeper
启动zookeeper依然Hmaster启动不起来,regionserver节点上的服务都可以启动
打开hbaseweb界面:http://192.168.1.7:16010
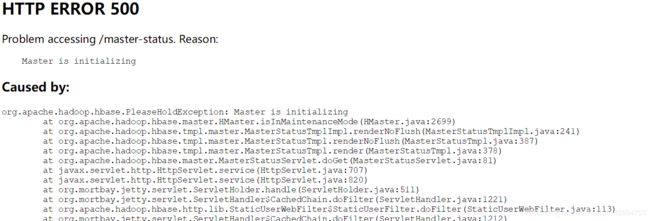
去查看日志
Caused by: java.io.IOException: Port 9000 specified in URI hdfs://guguda07:9000/hbase but host ‘guguda07’ is a logical (HA) namenode and does not use port information.
解决方法:
查了很久,解决不了,后来看到这个博主的这篇文章

之前配置了hadoop集群没有在集群上实验命令,我试了试我的hadoop集群,果然hadoop集群报错!hbase和hadoop的报错是一样的!
![]()
将

修改为
重启hadoop集群

hadoop集群修复
原来hadoop的分布式配置和HA配置有这个9000端口的区别,分布式加上端口9000,hadoop命令不会报错的。
重新启动hbase
报错
master.AssignmentManager: Unable to determine a plan to assign a hbase:meta region {ENCODED => 1588230740, NAME => ‘hbase:meta,1’, STARTKEY => ‘’, ENDKEY => ‘’} after maximumAttempts (10). Reset attempts count and continue retrying.
2019-04-28 23:26:19,582 WARN [guguda07:16000.activeMasterManager] master.AssignmentManager: Can’t move 1588230740, there is no destination server available.
2019-04-28 23:26:19,582 WARN [guguda07:16000.activeMasterManager] master.AssignmentManager: Unable to determine a plan to assign {ENCODED => 1588230740, NAME => ‘hbase:meta,1’, STARTKEY => ‘’, ENDKEY => ‘’}
查看这篇文章https://blog.csdn.net/gou290966707/article/details/77196819
cp /usr/local/hadoop-2.7.7/share/hadoop/common/lib/htrace-core-3.1.0-incubating.jar /usr/local/hbase-1.4.9/lib
cp:是否覆盖"/usr/local/hbase-1.4.9/lib/htrace-core-3.1.0-incubating.jar"? yes
还是没用
启动hbase shell
status
ERROR: org.apache.hadoop.hbase.PleaseHoldException: Master is initializing
at org.apache.hadoop.hbase.master.HMaster.checkInitialized(HMaster.java:2654)
at org.apache.hadoop.hbase.master.MasterRpcServices.getClusterStatus(MasterRpcServices.java:819)
at org.apache.hadoop.hbase.protobuf.generated.MasterProtos$MasterService 2. c a l l B l o c k i n g M e t h o d ( M a s t e r P r o t o s . j a v a : 63370 ) a t o r g . a p a c h e . h a d o o p . h b a s e . i p c . R p c S e r v e r . c a l l ( R p c S e r v e r . j a v a : 2380 ) a t o r g . a p a c h e . h a d o o p . h b a s e . i p c . C a l l R u n n e r . r u n ( C a l l R u n n e r . j a v a : 124 ) a t o r g . a p a c h e . h a d o o p . h b a s e . i p c . R p c E x e c u t o r 2.callBlockingMethod(MasterProtos.java:63370) at org.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:2380) at org.apache.hadoop.hbase.ipc.CallRunner.run(CallRunner.java:124) at org.apache.hadoop.hbase.ipc.RpcExecutor 2.callBlockingMethod(MasterProtos.java:63370)atorg.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:2380)atorg.apache.hadoop.hbase.ipc.CallRunner.run(CallRunner.java:124)atorg.apache.hadoop.hbase.ipc.RpcExecutorHandler.run(RpcExecutor.java:297)
在http://192.168.1.7:16010

看到这篇帖子
https://blog.csdn.net/liuxiao723846/article/details/53146304
对作者@赶路人儿,表示感谢!!!
先启动regionserver,在启动HMaster。
在regionServer上: hbase-daemon.sh start regionserver
在master上执行:hbase-daemon.sh start master

问题解决,但是真的不知道为什么。。。
一般来说 hbase 出问题,解决方案:
1./etc/hosts 主机名映射
2.zookeeper 挂掉
3.集群时间不同步
4.需要用hadoop lib 中的jar包覆盖hbase/lib中的包
5.hbase/conf中的hbase-sit.xml文件root/dir要和hadoophdfs-xml文件中的fs.DEFAULT位置一样(见本文)
HA的实现
其实只需要在regionserver节点上再启动一个master
[root@guguda07 conf]# hbase-daemon.sh start master
running master, logging to /usr/local/hbase-1.4.9/logs/hbase-root-master-guguda07.out
现在guguda07节点跟guguda08节点上都有一个HMaster进程了。
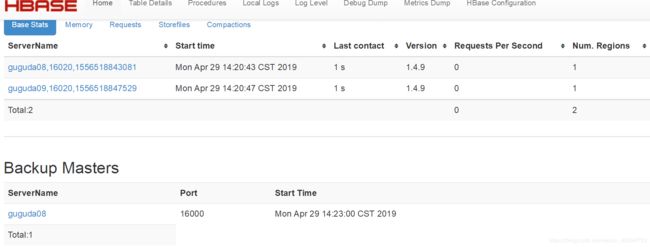
终于找到解决方案!!!!
原因是网上很多配置步骤没有这一步:
要把hadoop的hdfs-site.xml和core-site.xml 放到hbase/conf下
之后就可以直接start-hbase.sh