手把手教你手动创建线程池
一、为什么要手动创建线程池?
我们之所以要手动创建线程池,是因为 JDK 自带的工具类所创建的线程池存在一定的弊端,那究竟存在怎么样的弊端呢?首先来回顾一下 JDK 中线程池框架的继承关系:
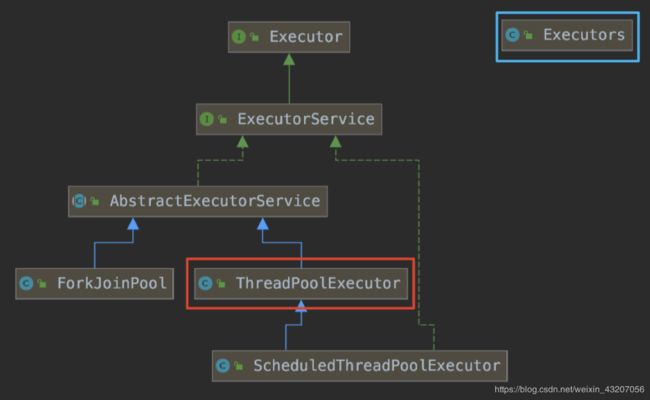
JDK 线程池框架继承关系图
我们最常用的线程池实现类是ThreadPoolExecutor(红框里的那个),首先我们来看一下它最通用的构造方法:
/**
* 各参数含义
* corePoolSize : 线程池中常驻的线程数量。核心线程数,默认情况下核心线程会一直存活,即使处于闲置状态也不会
* 受存活时间 keepAliveTime 的限制,除非将 allowCoreThreadTimeOut 设置为 true。
* maximumPoolSize : 线程池所能容纳的最大线程数。超过这个数的线程将被阻塞。当任务队列为没有设置大小的
* LinkedBlockingQueue时,这个值无效。
* keepAliveTime : 当线程数量多于 corePoolSize 时,空闲线程的存活时长,超过这个时间就会被回收
* unit : keepAliveTime 的时间单位
* workQueue : 存放待处理任务的队列
* threadFactory : 线程工厂
* handler : 拒绝策略,拒绝无法接收添加的任务
*/
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) { ... ... }
使用 JDK 自带的 Executors工具类 (图中蓝色框中的那个,这是独立于线程池继承关系图的工具类,类似于 Collections 和 Arrays) 可以直接创建以下种类的线程池:
-
线程数量固定的线程池,此方法返回 ThreadPoolExecutor
public static ExecutorService newFixedThreadPool(int nThreads) {... ...} -
单线程线程池,此方法返回 ThreadPoolExecutor
public static ExecutorService newSingleThreadExecutor() {... ...} -
可缓存线程的线程池,此方法返回 ThreadPoolExecutor
public static ExecutorService newCachedThreadPool() {... ...} -
执行定时任务的线程池,此方法返回 ScheduledThreadPoolExecutor
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {... ...} -
可以拆分执行子任务的线程池,此方法返回 ForkJoinPool
public static ExecutorService newWorkStealingPool() {... ...}
JDK 自带工具类创建的线程池存在的问题
直接使用这些线程池虽然很方便,但是存在两个比较大的问题:
-
有的线程池可以无限添加任务或线程,容易导致 OOM;
就拿我们最常用
FixedThreadPool和CachedThreadPool来说,前者的详细创建方法如下:public static ExecutorService newFixedThreadPool(int nThreads) { return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); }可见其任务队列用的是
LinkedBlockingQueue,且没有指定容量,相当于无界队列,这种情况下就可以添加大量的任务,甚至达到Integer.MAX_VALUE的数量级,如果任务大量堆积,可能会导致 OOM。而
CachedThreadPool的创建方法如下:public static ExecutorService newCachedThreadPool() { return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>()); }这个虽然使用了有界队列
SynchronousQueue,但是最大线程数设置成了Integer.MAX_VALUE,这就意味着可以创建大量的线程,也有可能导致 OOM。 -
还有一个问题就是这些线程池的线程都是使用 JDK 自带的线程工厂 (ThreadFactory)创建的,线程名称都是类似
pool-1-thread-1的形式,第一个数字是线程池编号,第二个数字是线程编号,这样很不利于系统异常时排查问题。
如果你安装了“阿里编码规约”的插件,在使用Executors创建线程池时会出现以下警告信息:
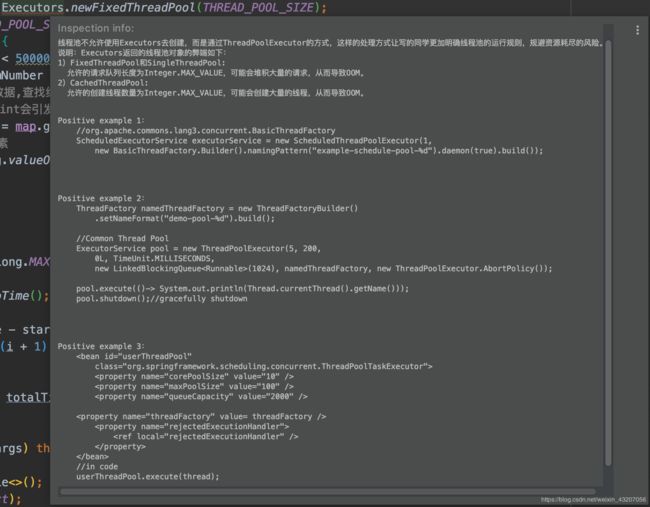
阿里编码规约的警告信息
为避免这些问题,我们最好还是手动创建线程池。
二、 如何手动创建线程池
2.1 定制线程数量
首先要说明一点,定制线程池的线程数并不是多么高深的学问,也不是说一旦线程数设定不合理,你的程序就无法运行,而是要尽量避免以下两种极端条件:
-
线程数量过大
这会导致过多的线程竞争稀缺的 CPU 和内存资源。CPU 核心的数量和计算能力是有限的,在分配不到 CPU 执行时间的情况下,线程只能处于空闲状态。而在JVM 中,线程本身也是对象,也会占用内存,过多的空闲线程自然会浪费宝贵的内存空间。
-
线程数量过小
线程池存在的意义,或者说并发编程的意义就是为了“压榨”计算机的运算能力,说白了就是别让 CPU 闲着。如果线程数量比 CPU 核心数量还小的话,那么必定有 CPU 核心将处于空闲状态,这是极大的浪费。
所以在实际开发中我们需要根据实际的业务场景合理设定线程池的线程数量,那又如何分析业务场景呢?我们的业务场景大致可以分为以下两大类:
-
CPU (计算)密集型
这种场景需要大量的 CPU 计算,比如加密、计算 hash 等,最佳线程数为 (CPU 核心数 + 1)。比如8核 CPU,可以把线程数设置为 9,这样就足够了,因为在 CPU 密集型的场景中,每个线程都会在比较大的负荷下工作,很少出现空闲的情况,正好每个线程对应一个 CPU 核心,然后不停地工作,这样就实现了最优利用率。多出的一个线程起到了备胎的作用,在其他线程意外中断时顶替上去,确保 CPU 不中断工作。其实也大可不必这么死板,线程数量设置为 CPU 核心数的 1 到 2 倍都是可以接受的。
-
I/O 密集型
比如读写数据库,读写文件或者网络读写等场景。各种 I/O 设备 (比如磁盘)的速度是远低于 CPU 执行速度的,所以在 I/O 密集型的场景下,线程大部分时间都在等待资源而非 CPU 时间片,这样的话一个 CPU 核心就可以应付很多线程了,也就可以把线程数量设置大一点。线程具体数量的计算方法可以参考 Brain Goetz 的建议:
假设有以下变量:
- Nthreads = 线程数量
- Ncpu = CPU 核心数
- Ucpu = 期望的CPU 的使用率 ,因为 CPU 可能还要执行其他任务
- W = 线程的平均等待资源时间
- C = 线程平均使用 CPU 的计算时间
- W / C = 线程等待时间与计算时间的比率
这样为了让 CPU 达到期望的使用率,最优的线程数量计算公式如下:
Nthreads = Ncpu * Ucpu ( 1 + W / C )*
CPU 核心数可以通过以下方法获取:
int N_CPUS = Runtime.getRuntime().availableProcessors();
当然,除了 CPU,线程数量还会受到很多其他因素的影响,比如内存和数据库连接等,需要具体问题具体分析。
2.2 使用可自定义线程名称的线程工厂
这个就简单多了,可以借助大名鼎鼎的谷歌开源工具库 Guava,首先引入如下依赖:
<dependency>
<groupId>com.google.guavagroupId>
<artifactId>guavaartifactId>
<version>28.2-jreversion>
dependency>
然后我就可以使用其提供的ThreadFactoryBuilder类来创建线程工厂了,Demo 如下:
public class ThreadPoolDemo {
// 线程数
public static final int THREAD_POOL_SIZE = 16;
public static void main(String[] args) throws InterruptedException {
// 使用 ThreadFactoryBuilder 创建自定义线程名称的 ThreadFactory
ThreadFactory namedThreadFactory = new ThreadFactoryBuilder()
.setNameFormat("hyn-demo-pool-%d").build();
// 创建线程池,其中任务队列需要结合实际情况设置合理的容量
ThreadPoolExecutor executor = new ThreadPoolExecutor(THREAD_POOL_SIZE,
THREAD_POOL_SIZE,
0L,
TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<>(1024),
namedThreadFactory,
new ThreadPoolExecutor.AbortPolicy());
// 新建 1000 个任务,每个任务是打印当前线程名称
for (int i = 0; i < 1000; i++) {
executor.execute(() -> System.out.println(Thread.currentThread().getName()));
}
// 优雅关闭线程池
executor.shutdown();
executor.awaitTermination(1000L, TimeUnit.SECONDS);
// 任务执行完毕后打印"Done"
System.out.println("Done");
}
}
控制台打印结果如下:
... ...
hyn-demo-pool-2
hyn-demo-pool-6
hyn-demo-pool-13
hyn-demo-pool-12
hyn-demo-pool-15
Done
可见这样的线程名称相比pool-1-thread-1更有辨识度,可以为不同用途的线程池设定不同的名称,便于系统出故障时排查问题。
三、总结
本文为大家介绍了手动创建线程池的详细方法,不过这些都是理论性的内容,而多线程编程是非常注重实践的一门学问,在实际生产环境中要综合考虑各种因素并不断尝试,才能实现最佳实践。