(论文阅读)STEP:Spatio-Temporal Progressive Learning for Video Action Detection
STEP:Spatio-Temporal Progressive Learning for Video Action Detection
用于视频动作检测的时空渐进学习
原文链接
摘要:
本文提出了一种用于视频时空动作检测的渐进学习框架——时空渐进动作检测器。从几个粗略的建议长方体开始,我们的方法通过几个步骤逐步细化建议,使之成为行动。这样,高质量的提案(即遵守动作)可以通过利用前面步骤的回归输出,在后面的步骤中逐步获得。在每一个步骤中,我们都及时自适应地扩展提案,以包含更多相关的时间上下文。与以往一次运行中执行动作检测的工作相比,我们的渐进学习框架能够自然地处理动作管内的空间位移,因此为时空建模提供了更有效的方法。我们广泛评估了我们在UCF101和AVA上的方法,并证明了优越的检测结果。值得注意的是,我们通过3个渐进步骤,分别使用11个和34个初始建议,在两个数据集上实现了75.0%和18.6%的mAP。
1.介绍
时空动作检测的目的是识别视频中出现的感兴趣的动作,并对其进行时空定位。灵感来自于目标检测在图像领域的进步(8,21),最近的工作方法基于标准二级框架:这个任务在第一阶段行动建议由区域提议算法或密集采样的锚点产生,并在第二阶段建议用于分类和本地化改进行动。
与图像中的目标检测相比,视频中的时空动作检测是一个更具挑战性的问题。考虑到视频的时间特性,上述两个阶段都带来了新的挑战。首先,一个行动管(即一个动作的包围框序列)通常涉及随着时间的推移而发生的空间位移,这为提案的生成和细化带来了额外的复杂性。其次,有效的时间建模对于准确的操作分类是必不可少的,因为只有当时间上下文信息可用时,才能识别许多操作。
先前的工作通常通过在剪辑(即,短视频片段)级别执行动作检测来利用时间信息。例如,[12,17]将一系列帧作为输入,输出每个剪辑的动作类别和回归的小管。为了生成行动建议,他们将2D区域建议随着时间的推移复制到3D,假设空间范围固定在一个剪辑中。然而,对于空间位移较大的动作管,特别是当剪辑较长或涉及到演员或相机的快速运动时,这种假设就会被打破。因此,直接使用长长方体作为行动建议并不是最优的,因为它们为行动分类引入了额外的噪音,使行动定位更具挑战性,如果不是没有希望的话。最近,有一些尝试使用自适应建议来进行动作检测[16,20]。然而,这些方法需要一个离线链接过程来生成建议.

图1:动作检测的时空渐进学习示意图。从一个粗尺度的提案长方体开始,它逐步细化提案,使其更适合于行动,并自适应地扩展提案,在每个步骤中包含更多相关的时间上下文。
本文提出了一种用于视频动作检测的新型学习框架——时空递进(STEP)动作检测器。如图1所示,与直接在一次运行中执行操作检测的现有方法不同,我们的框架涉及一个多步骤优化过程,该过程逐步细化初始建议,最终解决方案。具体来说,
步骤包括两个部分:空间细化和时间扩展。空间细化从少量的粗尺度建议开始,并迭代地更新它们,以便更好地对操作区域进行分类和本地化。我们按顺序执行多个步骤,其中一个步骤的输出用作下一步的建议。这是由于回归输出能够比输入建议更好地跟踪参与者并适应行动管道。时间扩展的重点是通过合并较长范围的时间信息来提高分类精度。
然而,简单地将较长的剪辑作为输入是无效的,而且也是无效的,因为较长的序列往往具有较大的空间位移,如图1所示。相反,我们在每个步骤中逐步处理更长的序列,并自适应地扩展建议,以跟踪动作。这样,STEP可以很自然地处理空间位移问题,从而提供更有效的时空建模。此外,STEP仅使用少量的提案(如11个)就可以获得优异的性能,避免了由于巨大的空间和时间搜索空间而产生和处理大量提案(如>1K)的需要.
据我们所知,这项工作为视频动作检测提供了第一个端到端渐进优化框架。提出了作用管的空间位移问题,并证明了该方法能够很好地解决这一问题。广泛的评估发现,我们的方法可以产生更好的检测结果,而只使用少量的建议.
2.相关工作
动作识别。频动作识别领域的一大系列研究是关于动作分类,它提供了动作检测的基本工具,例如多模态下的双流网络[28,35],用于同时进行空间和时间特征学习的3D-CNN [4] ,13]和RNN捕获时间上下文和处理可变长度的视频序列[25,36]。另一个活跃的研究方向是时间动作检测,它侧重于定位每个动作的时间范围。从快速时间行动提案[15],区域卷积三维网络[34],到预算感知的经常性政策网络,提出了许多方法。
时空行为检测。受近年来图像目标检测技术进步的启发,人们将图像目标检测器(如RCNN、Fast R-CNN和SSD)扩展为帧级动作检测器[10,26,27,30,33,37,38]。扩展部分主要包括:首先,利用光流捕获运动线索;其次,开发了连接算法,将帧级检测结果连接为动作管。虽然这些方法取得了很好的效果,但是由于对每一帧的检测是独立进行的,视频的时间特性并没有得到显式的或充分的利用。为了更好地利用时间线索,最近有几项工作被提议在剪辑级别执行动作检测。例如,ACT[17]将一个短序列的帧(如6帧)作为输入,输出回归后的tubelet,然后通过tubelet链接算法将其链接起来,构建动作管。Gu等人通过使用更长的剪辑(如40帧),并利用在大规模视频数据集[4]上预先训练的I3D,进一步证明了时间信息的重要性。除了链接帧级或剪辑级检测结果外,还有一些方法是在分类前将提案链接起来,生成action tube提案[16,20]。
逐步优化。从姿态估计[3]、图像生成[11]到目标检测,该技术已经在一系列视觉任务中得到了探索[2,6,7,24]。其中,多区域检测器[6]引入了R-CNN迭代边界盒回归,使回归结果更好。[7]中的AttractioNet使用一个多阶段的过程来生成精确的对象建议,然后输入快速R-CNN。G-CNN[24]训练一个回归器,迭代地将一个边界框网格移动到对象上。级联R-CNN[2]提出了一种用于高质量目标检测的级联框架,该框架通过增加IoU阈值训练一系列RCNN检测器,迭代抑制闭合误报。
3.方法
在本节中,我们介绍了提出的用于视频动作检测的渐进学习框架步骤。我们首先制定问题并概述我们的方法。然后,我们详细描述了STEP的两个主要组件,包括空间细化和时间扩展。最后给出了训练算法和实现细节。
3.1框架概述
结合最近的工作[12,17],我们的方法在clip级别执行动作检测,即,检测结果首先从每个剪辑中获得,然后链接到整个视频中构建动作管。我们假设一个剪辑的每个动作tubelet都有一个固定的动作标签,考虑到剪辑的时间很短,例如一秒钟。
我们的目标是通过几个渐进的步骤来解决动作检测问题,而不是直接在一次运行中检测动作。为了检测具有K帧的剪辑It中的动作,根据最大渐进步骤Smax,我们首先使用诸如VGG16 [29]或I3D [4]的骨干网络提取一组剪辑![]()
的卷积特征。渐进式学习从M个预先定义的提议立方体
![]()
开始,这些立方体从粗略的方框网格中稀疏地采样并在时间上复制以形成初始提议。我们的实验中使用的11个初始建议的一个例子如图2所示。然后逐步更新这些初始提议,以更好地对行动进行分类和本地化。在每个步骤s,我们通过按顺序执行以下过程来更新提议:
扩展:
建议被临时扩展到相邻的剪辑,以包括更长的范围的时间上下文,并且时间扩展适应于动作的移动,如3.3节所述。
细化:
将扩展后的建议转发给空间细化,空间细化输出分类和回归结果,如3.2节所示。
更新:
所有的提案都使用一个简单的贪心算法进行更新,即,每个提案都被分类得分最高的回归输出所替代


图2:11个初始建议的示例:2D框跨时间复制以获得长方体。
3.2 空间细化
在每个步骤中,空间细化解决了一个涉及动作分类和定位回归的多任务学习问题。因此,我们设计了一个twobranch体系结构,它为这两个任务学习不同的特性,如图3所示。我们的动机是这两项任务有着截然不同的目标,需要不同类型的信息。为了准确的动作分类,它需要空间和时间上的上下文特征,而为了鲁棒的定位回归,它需要在帧级更精确的空间线索。因此,我们的两个分支网络包括一个全局分支,它对整个输入序列执行时空建模以进行动作分类,以及一个局部分支,它在每个帧上执行边界框回归。
考虑到当前步骤的帧级卷积特性和tubelet建议,我们首先通过ROI池[8]提取区域特性。然后将区域特征提取到全局分支进行时空建模,生成全局特征。每个全局特征对整个tubelet的上下文信息进行编码,并进一步用于预测分类输出psi。此外,将全局特征与每个帧对应的区域特征连接起来形成局部特征,用于生成类特定的回归输出lis。我们的局部特征不仅捕获了一个tubelet的时空背景,而且提取了每个帧的局部细节。通过联合训练这两个分支,网络学习到两个独立的特征,这两个特征具有信息性,并且适合于各自的任务
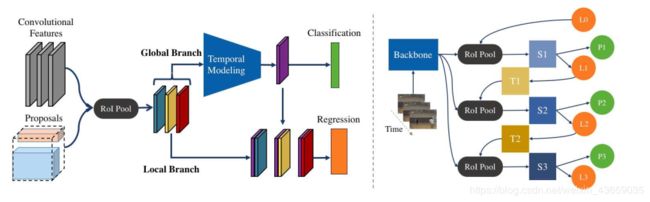
图3:左:我们的双分支网络的架构。右:我们渐进学习框架的图解,其中S表示空间细化,T表示时间扩展,P表示分类,L表示定位,数字对应步骤,L0表示初始建议。
3.3 时间扩展
视频时间信息,尤其是长期的时间依赖关系,对于准确的动作分类至关重要[4,36]。**为了利用更大范围的时间上下文,我们将建议扩展到包含更多的帧作为输入。**然而,这种扩展并不是微不足道的,因为对于较长的序列,空间位移问题变得更加严重,如图1所示。近年来,空间位移问题对动作检测的一些负面影响也被[12,17]观察到,它们只是在时间上复制2D提案,以增加更长的时间长度。
为了减轻空间位移问题,我们是渐进地、自适应地进行时间扩展的。从第二步开始,我们将tubelet建议扩展到两个相邻的剪辑。换句话说,在每一步1=
长度为Ks+2K,其中○表示连接。此外,时间扩展通过利用前一步的回归小管来适应动作运动。我们引入了两种方法来使时间扩展具有自适应性,如下所述。
外推法。
假设一个动作的空间运动近似在一个较短的时间范围内满足一个线性函数,例如一个6帧的clip,我们可以使用一个简单的线性外推函数来扩展tubelet提案:

类似的函数也可以应用于Bs - 1来适应运动趋势,但是对于长序列,这种假设会被违背,从而导致漂移估计。
预期 。
我们还可以通过位置预测来实现自适应时间扩展,即,训练一个额外的回归分支,根据当前剪辑推测相邻剪辑中tubelet的位置。直观地,预测要求网络通过当前剪辑中的动作建模来推断相邻剪辑中的运动趋势。在[37]中探索了类似的想法,在区域建议阶段使用位置预测。