使用selenium自动爬取想要爬取的内容
1、安装selenium
在CMD输入pip install selenium即可(可以指定下载源,了解详情请点击这个链接)
https://blog.csdn.net/weixin_44548394/article/details/88225465
2、下载并使用谷歌浏览器驱动chromedriver(还可以使用其他浏览器比如火狐等)
下载网址:http://chromedriver.storage.googleapis.com/index.html
注意:下载前请先查看你所用谷歌浏览器的版本
![]()
点击已选中的按钮,然后点击帮助-关于Google Chrome
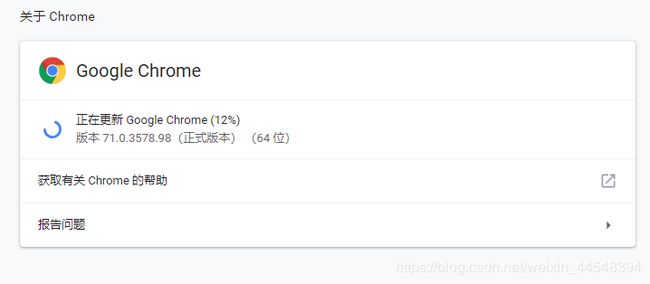
下载谷歌浏览器驱动要选择与你浏览器版本最近的一个版本
比如我的版本是 71.0.3578.98 那么我就要选择和我浏览器版本最近的一个版本
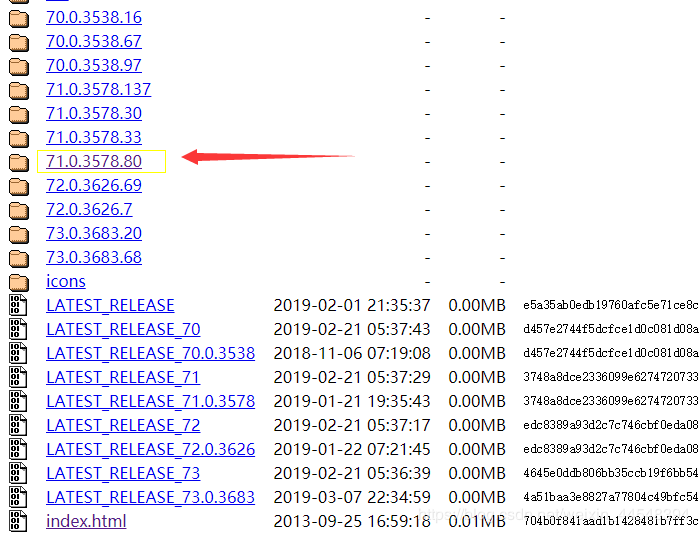
将下载完的文件解压到你浏览器所在文件夹中(选中浏览器,右键,选择打开文件夹所在位置,将其放入即可)
然后我们还需要配置环境变量
选中 此电脑,右键属性
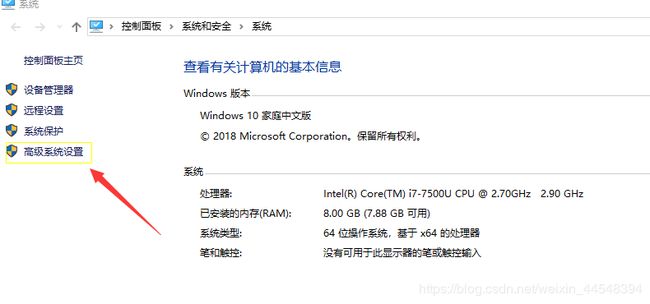
点击高级系统设置
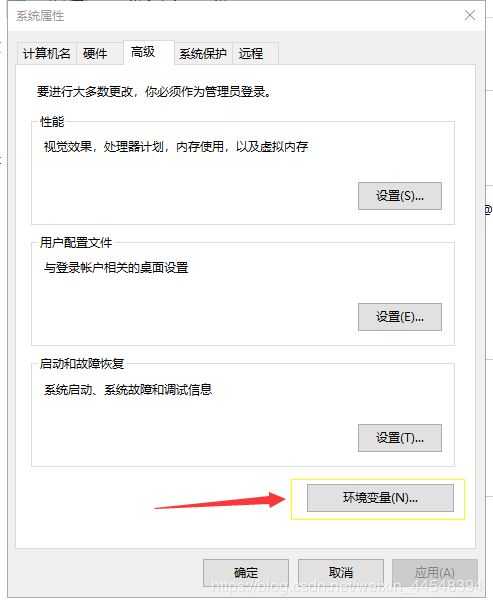
点击环境变量

选择Path 点击编辑按钮

选择新建,将浏览器所在位置复制填入其中就好
完成以上操作重启电脑,就可以执行下面的代码
3、代码如下:
#coding:utf-8
from selenium import webdriver
#指定selenium进行自动化操作时选用谷歌浏览器
self = webdriver.Chrome()
#要打开的网页
self.get('https://yuedu.baidu.com/book/list/3001?show=0')
total_book = self.find_element_by_id('bd')
#找到已经定位到的div盒子里的每一个包含图书介绍的子div
books = total_book.find_elements_by_class_name('book ')
#通过for循环依次把每一本图书的内容取出来
for book in books:
#将爬取到的内容打印
print (book.text + '\n')
#爬取数据完成后关闭浏览器
self.quit()
我认为 selenium 可以给我带来很多帮助
比如你要爬取某网站,可以写好脚本,在下班以后将脚本运行。
第二天去公司以后,你想要爬取的东西就爬好了。