一篇文章搞懂缓存穿透、缓存击穿,缓存雪崩 以及解决方案
缓存是我们项目应用肯定会使用,是我们数据库的守护神,能够保证数据库的稳定,能够提高整个系统的性能。一般我们采用市面上的redis、memcahce方案;redis已经非常强大了,每秒支持几万的连接时不成问题。设计一个缓存系统,不得不要考虑的问题就是:缓存穿透、缓存击穿与失效时的雪崩效应。
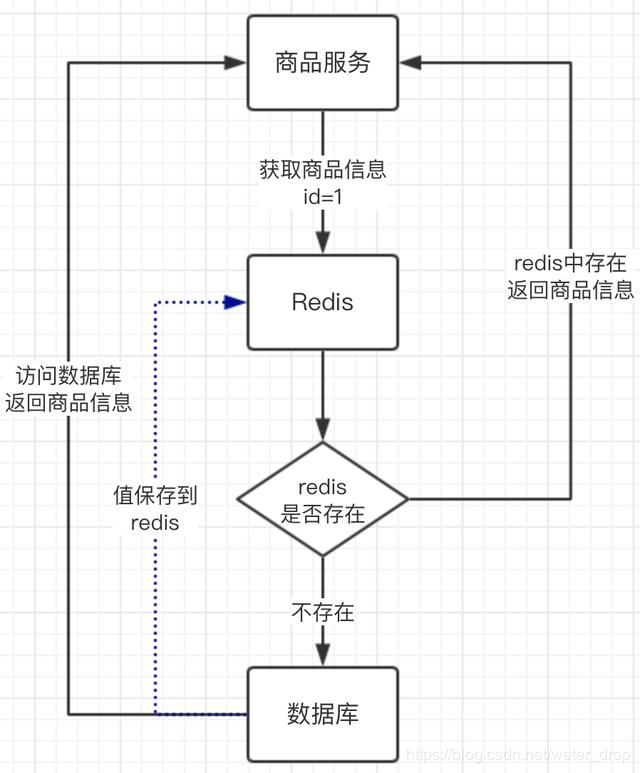
上图商品服务要获取商品信息时,先从redis缓存中获取,缓存中不存在再到数据库中取;数据库的资源时比较宝贵的,这样的设计就能把一些请求转移到redis上面去。这是我们小伙伴常用的缓存设计,绝大部分的缓存也就设计到此了。但只有这样的设计,真的我们就可以安枕无忧了吗?接着带着大家了解一下雪崩,穿透,击穿的含义。
一、缓存穿透
缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。在流量大时,可能DB就挂掉了,要是有人利用不存在的key频繁攻击我们的应用,这就是漏洞。例如:如商品id=10000,系统就不存在id为10000的数据。按照缓存设计的原理,缓存中找不到此商品,就会到数据库中查询,也没有找到。这样的请求都会打到数据库中,缓存在这个场景中就相当于没有。恶意的人利用这个漏洞发起攻击,直接把数据库搞崩溃。
解决方案
有很多种方法可以有效地解决缓存穿透问题:解决方案一:
最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被 这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。
解决方案二:
另外也有一个更为简单粗暴的方法(我们采用的就是这种),如果一个查询返回的数据为空(不管是数 据不存在,还是系统故障),我们仍然把这个空结果进行缓存。但是会存在两个问题:
- 问题一:
空值做了缓存,这样就无形了增加了很多没有意义的缓存,内存吃紧。比较有效的方式就是在这些值上面设置一个过期时间,让起自动删除,一般设置不超过5分钟 - 问题二:
有可能与业务存在不一致的窗口时间,如:虽然商品ID=10000现在不存在,我们现在在redis中保存了一个空值,但业务后来就真的有了商品id为10000的数据,这样数据库和缓存的信息就不一致,导致业务出现问题。此时就可以利用消息中间件等方式系统剔除掉此缓存数据
二、缓存雪崩
雪崩是指我们一般在设置缓存的时候都会设置一个缓存过期时间,如果一些缓存过期时间在同一刻,也就是缓存同时过期了。这个时候有大量请求过来,发现缓存中不存在,就直接到数据库中获取,就像雪崩一样同时打到数据库上面,这样就会导致数据库负载高,很有可能就会崩溃。
解决方案
解决方案一:
发现缓存不存在,在读取数据库时,再保存到redis缓存中,采用队列的方式或加锁的方式,进行排队访问数据库,这样就能够避免同时打到数据库上。
解决方案二:
这个方案就比较简单,雪崩是因为过期时间在同一刻导致的,那我们就可以在设置过期时间分散开。如在原有的过期时间的基础上加上一个 随机数,比如:1~10分钟,这样就不会放生在同一刻缓存失效了。
解决方案三:
设置二级缓存机制,这样就能够保证即时第一层缓存失效了,还有第二级缓存的保障;不过就增加了系统复杂性。
三、缓存击穿
对于一些设置了过期时间的key,如果这些key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候,需要考虑一个问题:缓存被“击穿”的问题,这个和缓存雪崩的区别在于这里针对某一key缓存,前者则是很多key。
缓存在某个时间点过期的时候,恰好在这个时间点对这个Key有大量的并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
解决方案一:检测更新
最容易想到的是这些热点数据设置永不过期,就不存在此问题。这样就会出现一个问题,那缓存怎么去更新呢?
- 方法一:
可以做一个后台服务,专门用来做数据缓存的更新。每隔30分钟更新一下这些热点缓存数据。不过这样就增加了系统复杂度。
- 方法二:
方法一过于复杂,我们可以改造一下redis的缓存结构,在缓存业务数据的时候,再保存跟业务数据关联的过期时间key。每次请求过来时,判断一下此业务数据的是否要到过期时间了,如:此值还有1分钟就过期了,这样就服务本身主动去数据库查询一次,做一个缓存的更新。
解决方案二:分级缓存
分级缓存,可采用二级缓存的方式缓存此热点数据。
采用 L1 (一级缓存)和 L2(二级缓存) 缓存方式,L1 缓存失效时间短,L2 缓存失效时间长。 请求优先从 L1 缓存获取数据,如果 L1缓存未命中则加锁,只有 1 个线程获取到锁,这个线程再从数据库中读取数据并将数据再更新到到 L1 缓存和 L2 缓存中,而其他线程依旧从 L2 缓存获取数据并返回。
这种方式,主要是通过避免缓存同时失效并结合锁机制实现。所以,当数据更新时,只能淘汰 L1 缓存,不能同时将 L1 和 L2 中的缓存同时淘汰。L2 缓存中可能会存在脏数据,需要业务能够容忍这种短时间的不一致。而且,这种方案可能会造成额外的缓存空间浪费。
解决方案三:加锁
也就是在获取数据时,redis缓存不存在,在访问数据库时,通过加锁的方式获取数据库的值,这样就保证了访问数据库只有一个请求过来,从而保证数据库的负载。具体如何加锁,下篇文章中会介绍。
具体的解决方案
我们的目标是:尽量少的线程构建缓存(甚至是一个) + 数据一致性 + 较少的潜在危险,下面会介绍四种方法来解决这个问题:
1. 使用互斥锁(mutex key): 这种解决方案思路比较简单,就是只让一个线程构建缓存,其他线程等待构建缓存的线程执行完,重新从缓存获取数据就可以了(如下图)
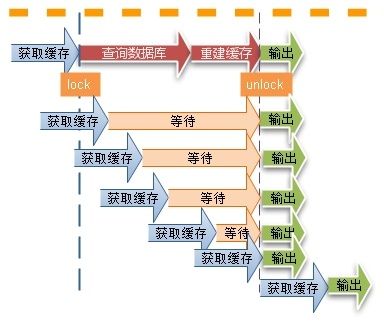
如果是单机,可以用synchronized或者lock来处理,如果是分布式环境可以用分布式锁就可以了(分布式锁,可以用memcache的add, redis的setnx, zookeeper的添加节点操作)。
下面是Tim yang博客的代码,是memcache的伪代码实现
if (memcache.get(key) == null) {
// 3 min timeout to avoid mutex holder crash
if (memcache.add(key_mutex, 3 * 60 * 1000) == true) {
value = db.get(key);
memcache.set(key, value);
memcache.delete(key_mutex);
} else {
sleep(50);
retry();
}
}
如果换成redis,就是:
String get(String key) {
String value = redis.get(key);
if (value == null) {
if (redis.setnx(key_mutex, "1")) {
// 3 min timeout to avoid mutex holder crash
redis.expire(key_mutex, 3 * 60)
value = db.get(key);
redis.set(key, value);
redis.delete(key_mutex);
} else {
//其他线程休息50毫秒后重试
Thread.sleep(50);
get(key);
}
}
}
2. "提前"使用互斥锁(mutex key):
在value内部设置1个超时值(timeout1), timeout1比实际的memcache timeout(timeout2)小。当从cache读取到timeout1发现它已经过期时候,马上延长timeout1并重新设置到cache。然后再从数据库加载数据并设置到cache中。伪代码如下:
v = memcache.get(key);
if (v == null) {
if (memcache.add(key_mutex, 3 * 60 * 1000) == true) {
value = db.get(key);
memcache.set(key, value);
memcache.delete(key_mutex);
} else {
sleep(50);
retry();
}
} else {
if (v.timeout <= now()) {
if (memcache.add(key_mutex, 3 * 60 * 1000) == true) {
// extend the timeout for other threads
v.timeout += 3 * 60 * 1000;
memcache.set(key, v, KEY_TIMEOUT * 2);
// load the latest value from db
v = db.get(key);
v.timeout = KEY_TIMEOUT;
memcache.set(key, value, KEY_TIMEOUT * 2);
memcache.delete(key_mutex);
} else {
sleep(50);
retry();
}
}
}
3. "永远不过期":
这里的“永远不过期”包含两层意思:
(1) 从redis上看,确实没有设置过期时间,这就保证了,不会出现热点key过期问题,也就是“物理”不过期。
(2) 从功能上看,如果不过期,那不就成静态的了吗?所以我们把过期时间存在key对应的value里,如果发现要过期了,通过一个后台的异步线程进行缓存的构建,也就是“逻辑”过期
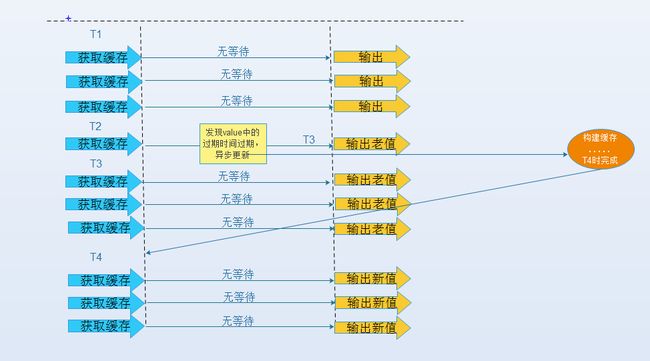
从实战看,这种方法对于性能非常友好,唯一不足的就是构建缓存时候,其余线程(非构建缓存的线程)可能访问的是老数据,但是对于一般的互联网功能来说这个还是可以忍受。
String get(final String key) {
V v = redis.get(key);
String value = v.getValue();
long timeout = v.getTimeout();
if (v.timeout <= System.currentTimeMillis()) {
// 异步更新后台异常执行
threadPool.execute(new Runnable() {
public void run() {
String keyMutex = "mutex:" + key;
if (redis.setnx(keyMutex, "1")) {
// 3 min timeout to avoid mutex holder crash
redis.expire(keyMutex, 3 * 60);
String dbValue = db.get(key);
redis.set(key, dbValue);
redis.delete(keyMutex);
}
}
});
}
return value;
}
4. 资源保护:
之前在缓存雪崩那篇文章提到了netflix的hystrix,可以做资源的隔离保护主线程池,如果把这个应用到缓存的构建也未尝不可。
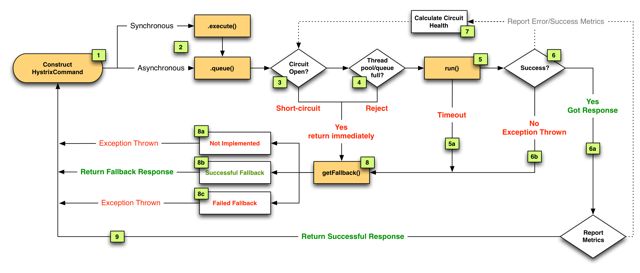
三、四种方案对比:
作为一个并发量较大的互联网应用,我们的目标有3个:
1. 加快用户访问速度,提高用户体验。
2. 降低后端负载,保证系统平稳。
3. 保证数据“尽可能”及时更新(要不要完全一致,取决于业务,而不是技术。)
所以第二节中提到的四种方法,可以做如下比较,还是那就话:没有最好,只有最合适。
| 解决方案 | 优点 | 缺点 |
| 简单分布式锁(Tim yang) | 1. 思路简单 2. 保证一致性 |
1. 代码复杂度增大 2. 存在死锁的风险 3. 存在线程池阻塞的风险 |
| 加另外一个过期时间(Tim yang) | 1. 保证一致性 | 同上 |
| 不过期(本文) | 1. 异步构建缓存,不会阻塞线程池 |
1. 不保证一致性。 2. 代码复杂度增大(每个value都要维护一个timekey)。 3. 占用一定的内存空间(每个value都要维护一个timekey)。 |
| 资源隔离组件hystrix(本文) | 1. hystrix技术成熟,有效保证后端。 2. hystrix监控强大。
|
1. 部分访问存在降级策略。 |
四、总结
1. 热点key + 过期时间 + 复杂的构建缓存过程 => mutex key问题
2. 构建缓存一个线程做就可以了。
3. 四种解决方案:没有最佳只有最合适。
总结
针对业务系统,永远都是具体情况具体分析,没有最好,只有最合适。
最后,对于缓存系统常见的缓存满了和数据丢失问题,需要根据具体业务分析,通常我们采用LRU策略处理溢出,Redis的RDB和AOF持久化策略来保证一定情况下的数据安全。