用于视觉问答的深度注意神经张量网络模型《Deep Attention Neural Tensor Network for Visual Question Answering》
目录
一、文献摘要介绍
二、网络框架介绍
三、实验分析
四、结论
本文有点长,请耐心阅读,定会有收货。如有不足,欢迎交流, 另附:论文下载地址
一、文献摘要介绍
Visual question answering (VQA) has drawn great attention in cross-modal learning problems, which enables a machine to answer a natural language question given a reference image. Signifificant progress has been made by learning rich embedding features from images and questions by bilinear models, while neglects the key role from answers. In this paper, we propose a novel deep attention neural tensor network (DA-NTN) for visual question answering, which can discover the joint correlations over images, questions and answers with tensor-based representations. First, we model one of the pairwise interaction (e.g., image and question) by bilinear features, which is further encoded with the third dimension (e.g., answer) to be a triplet by bilinear tensor product. Second, we decompose the correlation of difffferent triplets by difffferent answer and question types, and further propose a slice-wise attention module on tensor to select the most discriminative reasoning process for inference. Third, we optimize the proposed DA-NTN by learning a label regression with KL-divergence losses. Such a design enables scalable training and fast convergence over a large number of answer set. We integrate the proposed DA-NTN structure into the state-of-the-art VQA models (e.g., MLB and MUTAN). Extensive experiments demonstrate the superior accuracy than the original MLB and MUTAN models, with 1.98%, 1.70% relative increases on VQA-2.0 dataset, respectively.
作者认为视觉问题解答(VQA)在跨模式学习问题中引起了极大的关注,这使机器能够在给定参考图像的情况下回答自然语言问题。通过利用双线性模型从图像和问题中学习丰富的嵌入特征,已经取得了显着重大进展,但是这些工作忽略了答案中的关键作用。在本文中,我们提出了一种新颖的深度关注神经张量网络(DA-NTN)用于视觉问题回答,它可以发现基于张量表示的图像,问题和答案之间的联合相关性。首先,我们通过双线性特征对配对交互(例如,图像和问题)中的一个建模,并进一步用三维(例如,答案)将其编码为双线性张量积的三元组。其次,我们通过不同的答案和问题类型分解不同的三元组的相关性,并进一步在张量上提出一个分段注意模块,以选择最具判别力的推理过程进行推理。第三,我们通过学习带有KL散度损失的标签回归来优化建议的DA-NTN。这样的设计使得可扩展的训练和在大量答案集上的快速收敛成为可能。我们将提出的DA-NTN结构集成到最新的VQA模型(例如MLB和MUTAN)中。大量实验证明,与原始MLB和MUTAN模型相比,其准确性更高,在VQA-2.0数据集上,相对精度分别提高了1.98%和1.70%。
二、网络框架介绍
下图是作者提出的网络框架。图像、问题和所有候选答案都被联合输入到这个框架中。红色框中的结构是生成问题表示![]() 和图像与问题特征向量
和图像与问题特征向量![]() 融合的基础模型。两个蓝框中的结构是我们提出的“深度注意神经张量网络”。蓝框称为神经张量网络,用于度量图像-问题-答案三元组之间的相关性,张量可以表示三元组之间的隐式关系。名为“注意模块”的蓝框用于推理,根据三元组之间隐含的关系类型,对三元组进行自适应推理。
融合的基础模型。两个蓝框中的结构是我们提出的“深度注意神经张量网络”。蓝框称为神经张量网络,用于度量图像-问题-答案三元组之间的相关性,张量可以表示三元组之间的隐式关系。名为“注意模块”的蓝框用于推理,根据三元组之间隐含的关系类型,对三元组进行自适应推理。

作者提出的模型,将开放式VQA视为回归任务,即提出的方法目标是测量图像  ,问题
,问题![]()
 ,答案
,答案 ![]() 之间的相关性得分
之间的相关性得分![]() ,然后预测图像-问题-答案三元组是否正确,下面进行详细分析该框架。
,然后预测图像-问题-答案三元组是否正确,下面进行详细分析该框架。
2.1Neural Tensor Networks for VQA
作者提出DA-NTN模型的目标是用于测量图像-问题-答案三元组相关性得分。对于VQA任务,已经预定义了图像-问题对。因此,图像-问题-答案三元组的相关性可以重写为图像-问题对和答案之间的相关性。
首先获得图像-问题对的表示![]() 。为了对图像-问题表示的
。为了对图像-问题表示的![]() 和候选答案表示的
和候选答案表示的![]() 之间的交互进行建模,需要利用一些度量标准来衡量它们之的相关性。给定这两个特征向量,传统的方法是直接计算其距离或简单地将向量连接起来,然后输入到回归器或分类器中。但是这两种方式不能充分考虑图像-问题对和答案之间的复杂交互作用。
之间的交互进行建模,需要利用一些度量标准来衡量它们之的相关性。给定这两个特征向量,传统的方法是直接计算其距离或简单地将向量连接起来,然后输入到回归器或分类器中。但是这两种方式不能充分考虑图像-问题对和答案之间的复杂交互作用。
因此作者提出以非线性方式对图像-问题对和答案的相关程度进行建模,考虑到张量是描述向量之间关系的几何对象,并且还能够显式建模数据中的多个交互,提出了一种基于神经张量(NTN)的模块来关联图像-问题特征向量和答案特征向量。结果,可以如下方程式进行测量图像-问题对![]() 与答案
与答案![]() 之间的相关度。
之间的相关度。

其中,![]() 是答案
是答案![]() 的特征向量,R表示图像-问题对和答案之间的隐式关系。
的特征向量,R表示图像-问题对和答案之间的隐式关系。![]() 是一个张量,双线性张量积
是一个张量,双线性张量积![]() 得出
得出 ![]() 维向量
维向量 ![]() ,每个具有特殊关系类型
,每个具有特殊关系类型![]() 的
的![]() 可以通过张量相应切片
可以通过张量相应切片![]() 来计算
来计算![]() 。隐式关系 R 的其他参数是神经网络的标准形式:
。隐式关系 R 的其他参数是神经网络的标准形式:![]() 和
和![]() 。结果我们可以得到一个
。结果我们可以得到一个![]() 维向量
维向量![]() 来衡量图像-问题对和答案之间的相关程度,向量中的每一个元素代表图像-问题-答案三元组响应一个特定的隐式关系。
来衡量图像-问题对和答案之间的相关程度,向量中的每一个元素代表图像-问题-答案三元组响应一个特定的隐式关系。
按照先前的工作设置,视觉表示![]() 和问题表示
和问题表示![]() 均从预先训练的模型中初始化,然后在VQA任务的训练过程中进行微调。但是对于答案
均从预先训练的模型中初始化,然后在VQA任务的训练过程中进行微调。但是对于答案![]() ,其表示形式
,其表示形式![]() 应该提供视觉信息以进行推理。仅从自然语言语料库中学到的传统词嵌入不适合于建模丰富的视觉信息。例如,从自然语言语料库中学习的单词表示空间中最接近"dog"的描述动物(如"pet","cat")的其他单词。从自然语言语料库学到的词嵌入可以区分答案之间的语义和语法的差异,但是很难用于要求能够描述视觉信息的视觉问答任务中。因此,作者尝试从头开始学习VQA任务中的答案表示形式,而不是直接使用从自然语言语料库中学习的单词表示形式。
应该提供视觉信息以进行推理。仅从自然语言语料库中学到的传统词嵌入不适合于建模丰富的视觉信息。例如,从自然语言语料库中学习的单词表示空间中最接近"dog"的描述动物(如"pet","cat")的其他单词。从自然语言语料库学到的词嵌入可以区分答案之间的语义和语法的差异,但是很难用于要求能够描述视觉信息的视觉问答任务中。因此,作者尝试从头开始学习VQA任务中的答案表示形式,而不是直接使用从自然语言语料库中学习的单词表示形式。
2.2Attention Module for Reasoning
由于向量![]() 中的每个元素被设计成对应于
中的每个元素被设计成对应于![]() 中的一个特定关系和推理过程,作者提出了一种注意机制,通过动态调整向量中每个元素的权重来组合它们。对于VQA任务,
中的一个特定关系和推理过程,作者提出了一种注意机制,通过动态调整向量中每个元素的权重来组合它们。对于VQA任务,![]() 三元组之间的关系通常由问题q的类型决定,例如,三元组之间的关系可以分为对象识别、对象定位、对象计数、对象属性等,所有这些关系类都可以根据问题的含义来识别。此外,所有候选答案的回答还可以提供有关问题类型的更多详细信息。例如,如果一个问题正在回答有关颜色的问题,则有关颜色的候选答案的响应应该比其他候选答案具有更大的响应。具体来说,我们使用注意力机制来获取相关向量
三元组之间的关系通常由问题q的类型决定,例如,三元组之间的关系可以分为对象识别、对象定位、对象计数、对象属性等,所有这些关系类都可以根据问题的含义来识别。此外,所有候选答案的回答还可以提供有关问题类型的更多详细信息。例如,如果一个问题正在回答有关颜色的问题,则有关颜色的候选答案的响应应该比其他候选答案具有更大的响应。具体来说,我们使用注意力机制来获取相关向量![]() 中每个元素的加权平均值,作为关于
中每个元素的加权平均值,作为关于![]() 是否正确的最终得分的输出,即表示为
是否正确的最终得分的输出,即表示为
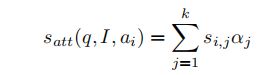
其中![]() 是相关性向量
是相关性向量![]() 中的第
中的第 个元素,
个元素,![]() 是第个元素的注意力权重。 注意力分数
是第个元素的注意力权重。 注意力分数![]() 由下式计算:
由下式计算:

其中![]() 被定义为:
被定义为:
![]()
其中,![]() 是一个向量,用于表示给定图像、问题 和一种特殊隐式关系类型的所有候选答案的响应。
是一个向量,用于表示给定图像、问题 和一种特殊隐式关系类型的所有候选答案的响应。![]() 是注意力模块的权重矩阵。组合权重由所有候选答案和问题表示的响应来确定。以这种方式,考虑了多个图像-问题-答案的隐式关系,并根据候选答案和所讨论的上下文信息的响应,整合了不同的推理结果。
是注意力模块的权重矩阵。组合权重由所有候选答案和问题表示的响应来确定。以这种方式,考虑了多个图像-问题-答案的隐式关系,并根据候选答案和所讨论的上下文信息的响应,整合了不同的推理结果。
2.3Label Distribution Learning with Regression
实际上,图像-问题对与一个或多个类似的答案相关联。在VQA和VQA-2.0这样的数据集中,每个图像-问题对都由不同的人用多个答案进行注释。每个样本的答案可以表示为所有可能答案![]() 的分布向量,其中
的分布向量,其中![]() 表示该图像-问题对在人类标记答案中第i个答案的出现概率。
表示该图像-问题对在人类标记答案中第i个答案的出现概率。
作者提出的模型输出是答案得分的回归,因此典型的训练策略是使用基于边距的损失函数(margin-based loss function)来最大化正确答案和任何错误答案之间的距离。由于负样本(也就是不正确答案)过多会造成模型复杂,为了克服这个问题,作者把这个带有负样本的基于边距的学习问题转换为具有答案分布  的标签分布学习(LDL)问题。
的标签分布学习(LDL)问题。
对于每个图像-问题对,我们计算总体答案候选集 ![]() 中每个答案
中每个答案![]() 的回归得分
的回归得分![]() 。然后使用softmax回归来估算答案分布:
。然后使用softmax回归来估算答案分布:

应用KL散度损失函数( ![]() )对预测
)对预测![]() 进行惩罚,通过最小化训练模型
进行惩罚,通过最小化训练模型

其中,N是用于训练的图像问题对的数量。
在推理过程中,只将所有候选答案的嵌入内容输入到DA-NTN中,然后选择具有三元组相关分数![]() 最大的答案
最大的答案![]() 作为最终答案。
作为最终答案。
三、实验分析
我们使用Faster R-CNN自下而上注意力的图像特征,生成大小为K×2048的特征图的视觉特征,因为这些特征可以解释为以图像中top-K对象为中心的ResNet特征 ,其中K <100。使用预先训练的Skip-thoughts模型的参数初始化GRU,用于学习问题表示。将答案的维度设为360,候选答案集 ![]() 固定为前2000个最常见的答案。为了避免过拟合,对所有候选答案的嵌入使用L2正则化。默认情况下,考虑训练复杂与验证集上的性能之间的权衡来设置 k = 6。
固定为前2000个最常见的答案。为了避免过拟合,对所有候选答案的嵌入使用L2正则化。默认情况下,考虑训练复杂与验证集上的性能之间的权衡来设置 k = 6。
表1是基于VQA-2.0验证数据集的开放式VQA模型的比较。

表2针对VQA-2.0数据集的TestDev和Test-stand组的开放式VQA的不同单个模型的性能。

表3不同的开放式VQA模型在VQA-1.0数据集的测试开发和测试集上的比较。

下图是平均注意力分数在不同类型的问题中的分布。

对于答案,下表是DA-NTN和Glove的比较

四、结论
In this paper, a reasoning attention based neural tensor network is designed for visual question answering. We applied our proposed method to different VQA models and got substantial gains for all types of questions. Our analysis demonstrates that our proposed method can not only model the diverse implicit relationship among image-question-answer triples to benefifit the reasoning of visual question answering, but also learn reasonable answer representations.
One direction for future work is to apply our DA-NTN to more VQA models, the other direction is to model the relationships of triplet by measuring the relevance between question-answer pair and image, image-answer pair and question, or some more complex combinations of image, question, and answer. We are also interested in learning better answer representations for some specialized tasks such as reading.
本文设计了一种基于推理注意力的神经张量网络,用于视觉问题的回答。创新点是把图像和问题进行融合,把答案和融合后的问题对组成三元组,通过张量学习他们之间的隐式关系,利用注意力机制得到与答案的注意力得分,选择得分最高的作为最终答案。其中利用张量计算图像和问题融合特征与答案的相关性值得借鉴。