解释与注意:用于视觉问答的一场获得注意的两人游戏模型《Explanation vs Attention: A Two-Player Game to Obtain Attention for VQA》
目录
一、文献摘要介绍
二、网络框架介绍
三、实验分析
四、结论
这是视觉问答论文阅读的系列笔记之一,本文有点长,请耐心阅读,定会有收货。如有不足,随时欢迎交流和探讨。
一、文献摘要介绍
In this paper, we aim to obtain improved attention for a visual question answering (VQA) task. It is challenging to provide supervision for attention. An observation we make is that visual explanations as obtained through class activation mappings (specifically Grad-CAM) that are meant to explain the performance of various networks could form a means of supervision. However, as the distributions of attention maps and that of Grad-CAMs differ, it would not be suitable to directly use these as a form of supervision. Rather, we propose the use of a discriminator that aims to distinguish samples of visual explanation and attention maps. The use of adversarial training of the attention regions as a two-player game between attention and explanation serves to bring the distributions of attention maps and visual explanations closer. Significantly, we observe that providing such a means of supervision also results in attention maps that are more closely related to human attention resulting in a substantial improvement over baseline stacked attention network (SAN) models. It also results in a good improvement in rank correlation metric on the VQA task. This method can also be combined with recent MCB based methods and results in consistent improvement. We also provide comparisons with other means for learning distributions such as based on Correlation Alignment (Coral), Maximum Mean Discrepancy (MMD) and Mean Square Error (MSE) losses and observe that the adversarial loss outperforms the other forms of learning the attention maps. Visualization of the results also confirms our hypothesis that attention maps improve using this form of supervision.
在本文中,作者旨在提高对视觉问题解答(VQA)任务的关注。提供监督以引起注意是一项挑战。作者所做的观察是,通过类激活映射(特别是Grad-CAM)获得的视觉解释(旨在解释各种网络的性能)可以形成一种监管手段。但是,由于注意力图的分布和Grad-CAM的分布不同,因此不适合将其直接用作监督形式。相反,作者建议使用区分器,以区分视觉解释和注意图的样本。使用注意力区域的对抗训练作为注意力和解释之间的两人游戏,可以使注意力图和视觉解释的分布更加接近。重要的是,我们观察到,提供这种监管手段还可以使注意力图与人的注意力更加紧密相关,从而大大改善了基线堆叠注意力网络(SAN)模型。这也导致VQA任务的等级相关度量得到了很好的改善。该方法也可以与最近基于MCB的方法结合使用,从而获得一致的改进。作者还提供了与其他学习分布方式的比较,例如基于相关比对(Coral),最大平均差异(MMD)和均方误差(MSE)损失,并观察到对抗损失优于学习注意图的其他形式。结果的可视化也证实了我们的假设,即使用这种形式的监督可以改善注意力图。
二、网络框架介绍
作者解决视觉问题解答(VQA)的方法的主要重点是利用从视觉解释方法(例如Grad-CAM)获得的监督来提高注意力。 与现有的VQA体系结构相比,该体系结构中的关键区别是在对抗性设置中使用视觉解释和注意块,(如图1所示)与仅使用注意力相比,使用Grad-CAM作为注意力显示了更高的性能。
使用卷积神经网络(CNN)获得了图像 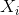 的嵌入
的嵌入  。类似地,我们使用LSTM网络获得了查询问题
。类似地,我们使用LSTM网络获得了查询问题 ![]() 的问题特征嵌入
的问题特征嵌入![]() ,这些输入到注意力网络,该注意力网络使用加权的softmax函数将图像和问题嵌入相结合,并生成加权的输出注意力向量
,这些输入到注意力网络,该注意力网络使用加权的softmax函数将图像和问题嵌入相结合,并生成加权的输出注意力向量 ![]() 。有多种建模注意力网络的方法,作者分别用SAN和MCB进行了评估,而Grad-CAM是使用(Selvaraju等人,2017)提出的模型,Grad-CAM使用最后一个卷积层的梯度信息来可视化每个像素在预测结果中的贡献。
。有多种建模注意力网络的方法,作者分别用SAN和MCB进行了评估,而Grad-CAM是使用(Selvaraju等人,2017)提出的模型,Grad-CAM使用最后一个卷积层的梯度信息来可视化每个像素在预测结果中的贡献。

使用两个玩家(P1,P2)之间的零和对抗游戏,其中一组玩家是生成器网络,另一组是鉴别器网络。他们从各自的决策集![]() 和
和![]() 中选择一个决策。在我们的案例中,注意力网络是生成器网络,而“真实”分布是Grad-CAM网络的输出。我们称之为“对抗性注意网络”(AAN)。游戏目标
中选择一个决策。在我们的案例中,注意力网络是生成器网络,而“真实”分布是Grad-CAM网络的输出。我们称之为“对抗性注意网络”(AAN)。游戏目标![]() 设定玩家的效用。具体来说,通过选择合适的策略
设定玩家的效用。具体来说,通过选择合适的策略![]() ,P1的效用为
,P1的效用为![]() ,而P2的效用为
,而P2的效用为![]() 。P1 / P2的目标是最大化其最坏情况的效用; 从而,
。P1 / P2的目标是最大化其最坏情况的效用; 从而,

上述公式提出了一个问题,即是否存在两个参与者可以共同收敛的解![]() 。该问题的解决方案是获得纳什均衡,使判别器无法区分发生器网络的代与“实际”分布,即:
。该问题的解决方案是获得纳什均衡,使判别器无法区分发生器网络的代与“实际”分布,即:![]() 。
。
由于并非总是存在纯平衡,因此存在一个混合纳什均衡的近似解,
![]()
其中 是
是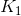 的分布,
的分布, 是
是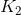 的分布,在零和对抗游戏中,生成器损失和鉴别器损失之和始终为零,即发生器损失是
的分布,在零和对抗游戏中,生成器损失和鉴别器损失之和始终为零,即发生器损失是![]() 零和游戏的解决方案称为极小极大值解,其中目标是最小化最大损失。
零和游戏的解决方案称为极小极大值解,其中目标是最小化最大损失。
我们可以通过说明损失函数为![]() (即判别式收益)来总结整个游戏,因此,最小极大目标为
(即判别式收益)来总结整个游戏,因此,最小极大目标为

为简单起见,我们删除下标  。
。 ![]() 是样本的Grad-cam网络
是样本的Grad-cam网络 ![]() 的输出,
的输出, 和
和 ![]() 是注意力网络的输出。鉴别器想要最大化目标(即它的回报),使得
是注意力网络的输出。鉴别器想要最大化目标(即它的回报),使得![]() 接近1,
接近1,![]() 接近于零。生成器想要最小化目标(即其损失),以使
接近于零。生成器想要最小化目标(即其损失),以使![]() 接近1。具体来说,鉴别器是一组CNN层,后面是使用二进制交叉熵损失函数的线性层。
接近1。具体来说,鉴别器是一组CNN层,后面是使用二进制交叉熵损失函数的线性层。
网络的最终代价函数将注意力网络的对抗性损失和求解VQA时的交叉熵损失结合起来。用于获得注意力网络的参数![]() ,分类网络的
,分类网络的![]() 和鉴别器的
和鉴别器的![]() 的最终成本函数如下:
的最终成本函数如下:

其中n是示例数,η= 10是超参数,使用验证集进行了微调,而  是标准交叉熵损失。我们使用此成本函数训练模型,直到模型收敛为止,以便参数
是标准交叉熵损失。我们使用此成本函数训练模型,直到模型收敛为止,以便参数![]() 提供鞍点函数。
提供鞍点函数。

对抗性注意网络的一个变体是获得局部像素(pixel-wise)判别器以获得改进的注意网络,这个思想已经用于生成对抗网络中,被称为patch-GAN,我们在这里表明,以像素为单位(每个像素具有多个通道)的注意力网络可以改善注意力网络。我们称此网络为逐像素对抗注意网络(PAAN),得到的最小-最大损失函数如下:

最后,给出了训练像素级鉴别器、注意网络和Grad-CAM的实际成本函数:
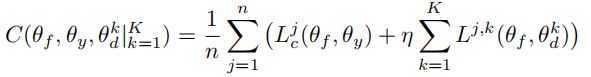
下图是PANN算法

作者也实验了所提出方法的变体,分别是Maximum Mean Discrepancy (MMD) Net和CORAL Net,下面介绍一下。
Maximum Mean Discrepancy (MMD) Net:在此变体中,我们使用基于MMD的标准分布距离度量来最小化此距离。
CORAL Net:在此变体中,我们使用基于CORAL损耗的标准分布距离度量,将注意力的二阶统计量(协方差)与Grad-CAM mask 之间的距离最小化。
我们直接训练了变体MMD和CORAL,而没有对抗损失,以使基于Grad-CAM的伪分布更接近注意力分布。 最后,我们用对抗性损失代替了MMD和CORAL。
三、实验分析
我们提供了我们提出的模型PAAN和其他变体的比较,以及使用表1和表2中的各种度量的基本模型。


表3:SOTA:开放式VQA1.0测试精度

表4:SOTA:开放式VQA2.0测试精度

图2,epoch-10, epoch-50, epoch-100, epoch-200迭代后的热力图可视化。

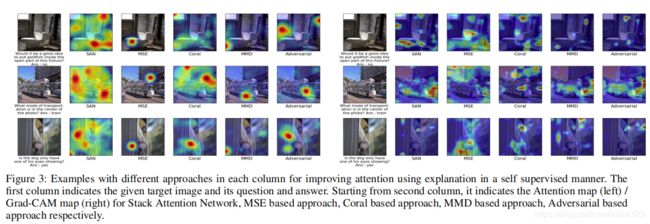
图3,不同例子的可视化。
四、结论
In this paper we have proposed a method to obtain surrogate supervision for obtaining improved attention using visual explanation. Specifically, we consider the use of Grad-CAM. However, other such modules could also be considered. We show that the use of adversarial method to use the surrogate supervision performs best with the pixel-wise adversarial method (PAAN) performing better against other methods of using this supervision. The proposed method shows that the improved attention indeed results in improved results for the semantic task such as VQA or Visual dialog. Our method provides an initial means for obtaining surrogate supervision for attention and in future we would like to further investigate other means for obtaining improved attention.
在本文中,作者提出了一种通过视觉解释获得替代监督的方法,以获得更好的关注。 具体来说,作者考虑使用Grad-CAM。 但是,也可以考虑其他此类模块。 结果显示,使用对抗方法来使用代理监督效果最好,而使用像素监督对抗方法(PAAN)则优于使用该监督的其他方法。 所提出的方法表明,注意力的提高确实导致语义任务(例如VQA或可视对话框)的结果得到改善。 作者的方法提供了一种获得代理监督关注的初始方法,将来作者将进一步研究其他方法来获得关注的改进。
此篇论文的创新点是加入了一个鉴别器网络,用于提高识别区域的准确性,值得参考。