用于视觉问答的四元数乘积的多层内容交互模型《MULTI-LAYER CONTENT INTERACTION THROUGH QUATERNION PRODUCT FOR VQA》
目录
一、文献摘要介绍
二、网络框架介绍
三、实验分析
四、结论
这是视觉问答论文阅读的系列笔记之一,本文有点长,请耐心阅读,定会有收货。如有不足,随时欢迎交流和探讨。
一、文献摘要介绍
Multi-modality fusion technologies have greatly improved the performance of neural network-based Video Description/Caption, Visual Question Answering (VQA) and Audio Visual Scene-aware Dialog (AVSD) over the recent years. Most previous approaches only explore the last layers of multiple layer feature fusion while omitting the importance of intermediate layers. To solve the issue for the intermediate layers, we propose an efficient Quaternion Block Network (QBN) to learn interaction not only for the last layer but also for all intermediate layers simultaneously. In our proposed QBN, we use the holistic text features to guide the update of visual features. In the meantime, Hamilton quaternion products can efficiently perform information flow from higher layers to lower layers for both visual and text modalities. The evaluation results show our QBN improved the performance on VQA 2.0, furthermore surpassed the aproach using large scale BERT or visual BERT pre-trained models. Extensive ablation study has been carried out to examine the influence of each proposed module in this study.
近年来,多模态融合技术极大地提高了基于神经网络的视频描述/字幕,视觉问答(VQA)和视听场景感知对话(AVSD)的性能。先前的大多数方法仅探索多层特征融合的最后一层,而忽略了中间层的重要性。为了解决中间层的问题,我们提出了一种有效的四元数块网络(QBN),不仅可以学习最后一层的交互,还可以同时学习所有中间层的交互。在我们提出的QBN中,使用整体文本特征来指导视觉特征的更新。同时,Hamilton四元数乘积可以有效地执行从高层到较低层的视觉和文本形式的信息流。评估结果表明,QBN提高了VQA 2.0的性能,并且使用大规模BERT或可视BERT预训练模型进一步超越了这一方法。已经进行了广泛的消融研究,以检查本研究中每个提出的模块的影响。
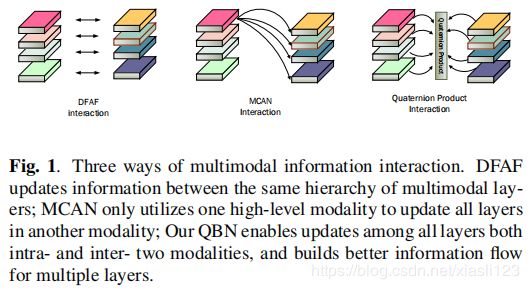
图1展示多模态信息交互的三种方式。DFAF在同一层次的多模态层之间更新信息;MCAN只使用一种高级模态来更新另一种模态中的所有层;我们的QBN允许在两种模态内部和内部的所有层之间更新,并为多个层构建更好的信息流。
二、网络框架介绍
为了获得基本的语言特征,我们首先使用预先训练过的Glove将每个单词嵌入到问题 中。然后使用LSTM,生成隐藏状态的序列
中。然后使用LSTM,生成隐藏状态的序列![]() 。注意,我们使用LSTM
。注意,我们使用LSTM ![]() 的最后一个隐藏状态作为问题特征,表示为
的最后一个隐藏状态作为问题特征,表示为![]() ,并且所有问题都被填充并截断为相同的长度14。
,并且所有问题都被填充并截断为相同的长度14。
![]()
我们提取图像特征,这些特征是从Visual Genome数据集上预先训练的Faster-RCNN模型获得的。 对于每个图像 ,我们提取100个区域推荐及其关联的区域特征。但是,与自下而上和自上而下的注意不同,我们选择
,我们提取100个区域推荐及其关联的区域特征。但是,与自下而上和自上而下的注意不同,我们选择![]() 图像区域特征作为输入。我们通过全连接层
图像区域特征作为输入。我们通过全连接层![]() 和
和![]() 将动态变化的问题向量映射到通道特征的比例因子和偏置项。通过Question的句子向量对图像区域特征进行预处理,以实现对图像空间区域特征的有效缩放。
将动态变化的问题向量映射到通道特征的比例因子和偏置项。通过Question的句子向量对图像区域特征进行预处理,以实现对图像空间区域特征的有效缩放。

式中, 和
和  分别表示比例因子和偏置项。
分别表示比例因子和偏置项。 ![]() 代表问题特征。在
代表问题特征。在![]()
![]() 中,
中, 代表第个区域特征;
代表第个区域特征;  代表2048通道的第通道。在
代表2048通道的第通道。在![]() ,
, 表示具有全部区域特征的图像。 最后,我们平均合并缩放区域特征,模型框架如下图2所示。
表示具有全部区域特征的图像。 最后,我们平均合并缩放区域特征,模型框架如下图2所示。

2.1Multi-layer content learning for text information
在以前使用自我注意(self-attention)模型解决VQA任务时,有两种常用方法。一种方法是利用自我注意对文本信息和视觉信息的每一层进行编码,然后使用共同注意机制实现文本模态与视觉模态之间的信息交互。 另一种方法是使用自我注意机制对文本信息进行多次编码并学习高级文本信息。然后利用高层次文本信息通过共同注意机制与视觉模态信息进行交互。这两种方法都没有充分考虑到浅层和深层所形成的全局文本信息对多模态信息交互的影响。因此我们利用文本的多层全局信息来帮助多模态信息交互。
首先使用自我注意机制对文本特征和视觉区域特征进行三次编码。 考虑到原始文本和视觉信息,因此在文本模态和视觉模态中我们分别具有四层信息。 如以下公式所示,![]() 和
和 ![]() 代表不同层的特征;
代表不同层的特征; ![]() 代表自我注意编码。
代表自我注意编码。

为了反映每一层的整体信息,我们首先对每一层的文本信息进行平均。 平均值表示求平均值的函数。
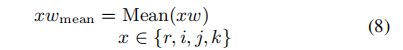
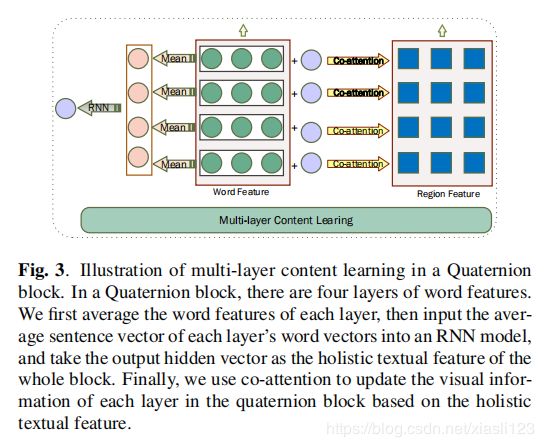
![]() 代表文本特征每一层的整体信息,为了反映各层信息之间的相关性,我们使用RNN处理每一层的均值信息。
代表文本特征每一层的整体信息,为了反映各层信息之间的相关性,我们使用RNN处理每一层的均值信息。![]() 表示四元数块中多层文本特征的整体信息。
表示四元数块中多层文本特征的整体信息。

我们使用共同注意机制来实现视觉信息和文本信息的融合,但是与以往的方法不同,我们首先在每一层的文本特征中加入a,使得每一层的视觉信息都是在融合相应层的文本信息时考虑到多层文本的整体特征。

下图3展示了四元数块中多层内容学习的图解。
2.2.Multi-layer feature relationship learning
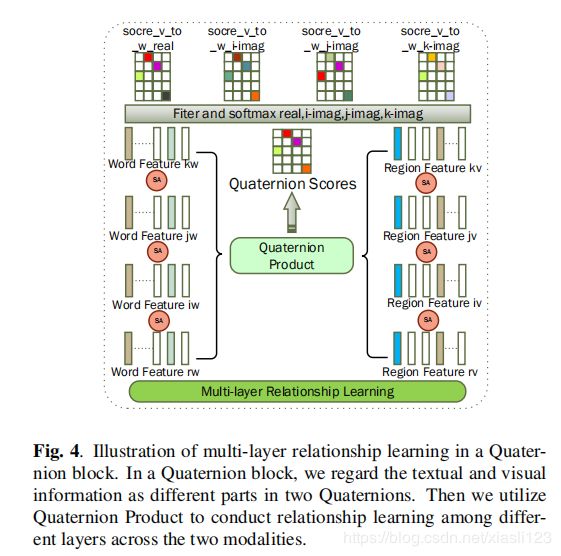
对于自我注意或共同注意,只能建立相同级别的关注图。 为了建立文本模态与视觉模态多层特征之间的关系,我们使用四元数乘积法来学习这种关系,并将这种关系应用于长期关注中。
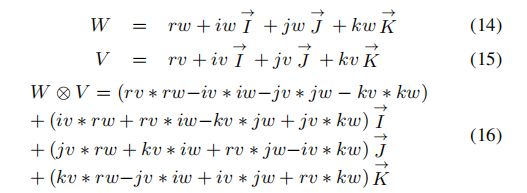
我们分离了Hamilton积结果的实部和虚部,实层用![]() 表示, 表示第一虚层关系,
表示, 表示第一虚层关系, 表示第二虚层关系,
表示第二虚层关系, 表示第三虚层关系。我们将这些关系应用于图像-文本模式之间的信息更新[28]。
表示第三虚层关系。我们将这些关系应用于图像-文本模式之间的信息更新[28]。

下图4展示了四元体块中多层关系学习的图解。
三、实验分析
作者使用VQA 2.0数据集测试了所提出的模型。 表1显示了与常规方法相比的评估结果。表2显示了对VQA 2.0验证数据集进行的消融研究,以通过组合每个模块来检查性能。 最后,我们通过结合VG数据集,VQA v2.0的训练和测试数据集在测试数据集上测试了QBN。 所有实验都使用ADAM优化器,其学习速率为0.0001,持续13个循环。 批次大小为64。所有隐藏的单位的维度为512。


图5 可视化的更新过程

四、结论
Our proposed Multi-Layer Content Interaction can be a fundamental approach to capture high-level interaction between different modalities. In this paper, the performance on Visual Question Answering can even surpass models with BERT pre-training. In the future, we will test our model on more diverse applications like visual grounding and vision language pre-training.
作者提出的多层内容交互可以是捕获不同模式之间高层交互的基本方法。 在本文中,Visual Question Answering的性能甚至可以超过具有BERT预训练的模型。
这是最近才出的文章,方法比较新颖,指出了2019年那几个之前方法的缺陷,并得到了解决,是个不错的思路,值得推荐阅读。