裁判文书网爬虫(2019.5.15更新)
裁判文书网数据爬取(2019.5.15更新)
一、前言
为避免不必要的侵权纠纷,本篇文章不会贴入核心代码,如有兴趣交流探讨,非工作时间随时欢迎。项目中采用的技术是为了纯粹获取数据,不会涉及暴力侵入,js注入等有害服务器的行为,得到的完全是合理合法的公众数据,请大家监督。文章中采用的技术有js反混淆,解编码等等,所需的支持环境很多,如有需要还请麻烦自行解决,这里不再赘述。分析时采用的是Charles抓包,因为做过一遍知道了路径因此文章就以浏览器自带的调试控制台介绍。
最近因为工作的原因,好久都没有更新博客了,今天为了对最近新掌握的知识做一个总结,就抽空更新一篇关于中国裁判文书网的数据爬取的文章。众所周知,文书网的反爬机制简直令人发指,几乎全部是网站自己定制的规则,再加上封IP,验证码,定量查看等等,但仔细分析依旧有迹可循。文书网两周一小更,四个月一大更,所以可能发现前几天的爬虫突然用不了了,这都是正常现象,尤其是今年四月份的大更,更是一言难尽。曾经也试过使用selenium,但速度的确感人,且相对而言更加不够稳定(重复数据,内存爆炸,异常处理等一系列问题)。裁判文书网是我目前遇到的最难的也是反爬机制最多的网站,如果可以从头至尾分析一遍,对爬虫技术肯定是大有裨益,接下来介绍我的逆向分析过程:
二、分析
A、分析需要获取的数据页
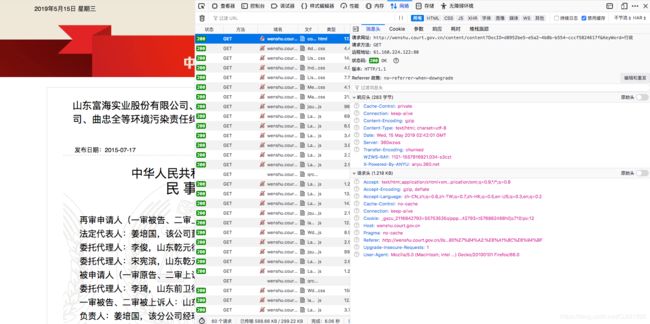 图一、 content_docid请求页面
图一、 content_docid请求页面
1、可以看到这个网址就是我们需要的数据,但是控制台里没有数据,找xhr看是不是在后台返回的结构化数据里,可惜没有。
2、这个docid肯定是唯一索引,全局搜索,发现还有一个aspx,里面刚好是我们需要的数据,而且还是get请求,接下来找docid这个参数。
B、分析真实数据页面请求
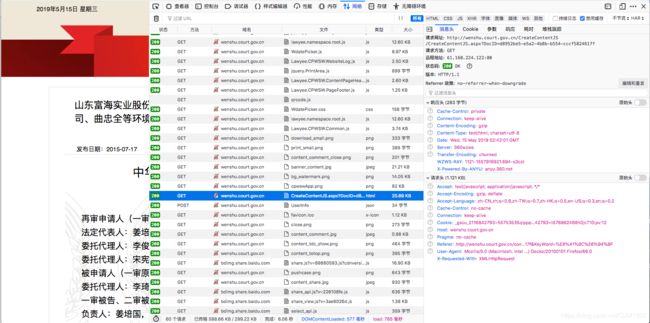 图二、 aspx请求页面
图二、 aspx请求页面
3、分析aspx的cookie,发现参数wzws_cid,vjkl5等一系列参数,带好参数直接请求,获得数据。
4、这里cookie先放一放,找DocID。全局搜索发现没有,加密数据,定位到指定js页面。
5、网站这里用的eval混淆,经过解码js代码,发现是自定规则的基于md5的加密方式,直接翻译成python,一千多行过于臃肿,更换方式,通过execjs库直接执行解码后的js代码,为的是获取加密后docid,但是这段代码需要两个参数,RunEval和ID,这两个参数肯定在列表页。
C、分析列表页
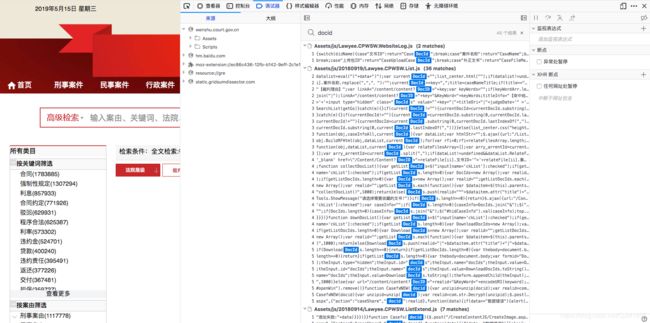 图三、 全局寻找参数
图三、 全局寻找参数
6、找到加密docid的原料RunEval和ID,发现在列表页返回的xhr的ListContent中,但是要请求这个ListContent,需要提交表单,也就是说这是一个post请求。
7、点击控制台参数,发现需要的参数如下表所示,这里前五项是数据请求的形式,后三项vl5x,number,guid也是需要自己构造的,可惜的是这里的三个变量依旧是加密的。
8、post请求也需要cookie,这里需要vjkl5,wzws_cid等一系列参数,cookie问题与上面相同,先放到最后处理。这里提前说明一下,post表单与cookie时效都是一分钟左右,也就是每一次测试都要新构造,但是一个ip每天的请求频率如果达到大约5秒一个的话,就会被ban,第二天解封,这里需要有足够的代理测试,同时要保证构造的速度够快,否则报的错误很容易误导到其他方向上去。(操作逐渐狰狞......)
| Param | 全文检索:行政 |
| Index | 1 |
| Page | 10 |
| Order | 法院层级 |
| Direction | asc |
| vl5x | 068bef0cd4a1ed5c886cd2ed |
| number | B5L4 |
| guid | 2955fa06-6042-02eba40d-d91e566c3163 |
 图四、 ListContent请求页面
图四、 ListContent请求页面
9、通过火狐浏览器带参数请求,(这里不使用谷歌浏览器原因是,谷歌浏览器在执行重定向时返回的是重定向之前的请求,是后台通过抓包才发现的,浏览器机制问题)。
10、全局搜索vjkl5,定位到vjkl5的加密js,同样需要反混淆,翻译调用,使用execjs包执行vjkl5码发现可以得到所需要的vl5x码。
11、下面解决number与guid,这里的number也是加密数据,但是不是js混淆加密,而是post请求加密,加密原料就是guid,全局搜索guid,定位到guid函数,发现这是一个随机生成的base数据,翻译成python,获取了三个参数。
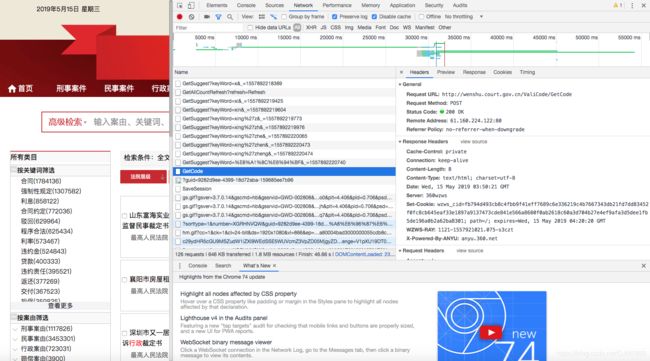 图五、 number的post请求页面
图五、 number的post请求页面
12、找到vjkl5的起始源头,发现在请求列表数据时返回的Set-Cookie中刚好包含这个值,拿到之后请求发现如下图所示,数据没请求到,这与四月份的大更新有关,新增了一个参数wzws_cid参数,这个参数被作为请求标志防止机器爬取。
13、通过302重定向这个页面会返回一个新的cid,反混淆js,得到三个关键数据dynamicurl,wzwsfactor,wzwsquestion和一段js代码。
14、这里的js采用的是反混淆sojson.v5加密,这个加密方式的介绍是:“请保存好源代码,加密过后无法恢复”,是的,无法解密。怎么办,方法有三,第一种selenium(舍弃,就是为了脱离selenium的),第二种nodejs直接运行(内存爆炸,有一些注意事项),第三种暴力傻瓜式破解(手动更换变量调试,最后翻译成python)。
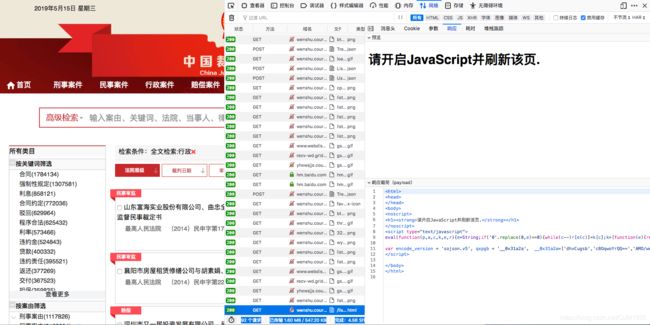 图六、 假cookie请求结果
图六、 假cookie请求结果
15、拿到禁止重定向请求到的wzws_cid,这里分析时使用浏览器的无痕模式,cookie是服务器端给的,要想获取cookie就要避免本地的cookie影响,配合第一次请求到的假cookie再次发起请求,获得Set-Cookie字段的vjkl5值。
16、不同的ip返回的wzws_cid码是不同的,因为封ip机制所以必须使用高匿代理,云端ssl隧道转发与本地ip都会被后台识别,这样每一个新的页面链接都需要重新获取wzws_cid,至此逆向分析完毕,下面是最终获取的json数据。
三、正向请求步骤
1、请求列表网址,这个网址需要带生成guid和post请求后的number,获得假cookie与wzws_cid
2、获取网址内容拿到三条数据dynamicurl,wzwsfactor,wzwsquestion,以三条数据为原料执行获得当前请求网址
3、带着刚才的假wzws_cid,向上一步构造的网址请求数据,这里要禁止重定向,获取vjkl5值
4、解密vjkl5值为vl5x值,重新获取guid与number,带好form表单,这里表单数据要与第一步构造的列表网址同义,请求ListContent,获取RunEval与ID,一次能够得到十条数据
5、通过RunEval与ID,解密DocID,构造aspx请求链接
6、带vjkl5请求上一步链接,获得假cookie与wzws_cid
7、重复执行第二步
8、重复执行第三步,获取最终的文本数据
9、一次十条数据,因为cookie与vjkl5的时效性,并且vjkl5是与请求列表页链接和post表单完全契合的,再次请求时需要从第一步循环开始
四、注意
1、当请求显示“请开启JavaScript并刷新页面”,说明wzws_cid失效
2、当请求显示“remind key”,说明vjkl5失效
3、aspx可以使用docker+splash直接渲染得到最终数据,亲测可用,但是稍慢,本次就不再介绍,后期有机会再更新。
4、这里scrapy,lxml,代理设置等等python中所用到的工具、框架、支持为节省篇幅都没有介绍,如果这方面还有问题,请先熟读崔庆才的《网络爬虫开发实践》
5、It is easier said than done
五、插曲
1、两周一小更,刚好赶上,跑的好好的代码第二天突然失效了,心态大崩,所幸又找到了问题。建议留出一个selenium版本,以防止网站大更后爬虫失效而无法获取数据的问题。
2、裁判文书网站开发者喜欢把自己工作注释到代码中,摆好擂台发起挑战,这里放一张去年八月份的大更新。
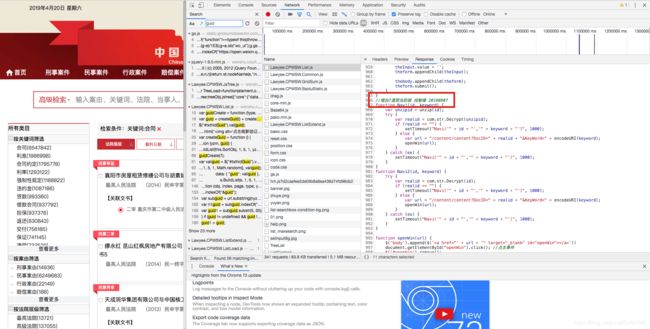 图八、 接受挑战
图八、 接受挑战