kubeedge1.3.1部署(基于keadm)
本文根据kubeedge官方github中keadm工具配置kubeedge环境的说明,进行了实践与总结。
实验环境
本实验基于虚拟机环境,对最新kubeedge1.3.1版本进行了环境搭建,其中master节点为ubuntu操作系统,edge节点为centos操作系统,两个节点都需要预先安装docker-ce环境。
kubernetes环境配置
kubeedge相当于k8s在边缘侧的扩展,其master节点需要搭建k8s环境,本实验安装的k8s版本为1.15.0,具体步骤如下。
配置k8s阿里源
利用vim编辑器,在 /etc/apt/source.list.d/目录下新建文件kubernetes.list,加入内容
deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main
然后apt-get update更新源。
执行如下命令安装kubeadm、kubectl以及kubelet的1.15.0版本(三个版本要一致)
apt-get install kubeadm=1.15.0-00 kubectl=1.15.0-00 kubelet=1.15.0-00
利用kubeadm对k8s初始化
kubeadm init --kubernetes-version=1.15.0 --apiserver-advertise-address= --image-repository registry.aliyuncs.com/google_containers --service-cidr=10.1.0.0/16 --pod-network-cidr=10.244.0.0/16
其中,替换为master节点的IP地址,kubernetes-version与之前安装的kubeadm等软件版本一致。
初始化成功之后会出现执行kubeadm join加入节点的提示,这里我们不需要通过这种方式加入节点。
采用keadm工具部署kubeedge
官方git仓库的keadm文档
cloud端配置
在master节点上,下载keadm工具,解压后,在keadm二进制文件目录下执行命令
./keadm init
该命令会自动检查k8s部署情况,并自动安装kubeedge的cloud侧组件。
运行cloudcore
执行命令cloudcore,启动kubeedge的云端程序,也可用nohup将其作为后台程序运行。
nohup cloudcore > cloudcore.log 2>&1
成功运行的cloudcore日志界面如图
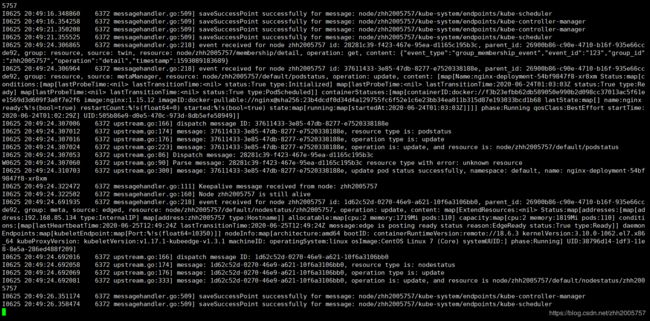
edge端配置
首先需要在master节点上生成edge节点接入所需要的token,在master节点上执行以下命令
./keadm gettoken
![]()
如果这里执行该命令报错,通常是由于cloudcore没有启动成功所致,而cloudcore的启动失败往往和kubelet组件没有启动成功有关,这一点在之后会介绍。
在edge端根据生成的token加入cloud端
./keadm join --cloudcore-ipport=:10000 --token=
这里的ip为cloud端ip,token为生成的token。kubeedge在1.3版本之后云端与边缘端不需要再手动拷贝证书,而是可以通过token的方式进行自动验证。
执行命令edgecore,启动kubeedge的edge程序,如图。

之后即可在master节点执行
kubectl get nodes
来查看节点运行情况,也可以通过部署简单的nginx应用来进行云边测试。
采坑记录
1.通常很多问题都是由于kubelet或cloudcore未能启动成功导致
查看kubelet日志
journalctl -xfu kubelet
查看cloudcore日志
vim /var/log/kubeedge/cloudcore.log
2.cloudcore日志提示CloudCore 1.3.0 failed to run: failed to parse EC private key: asn1: structure error: length too large
kubectl删除kubeedge的namespace,然后重新运行cloudcore
3.运行kubectl命令提示The connection to the server 192.168.180.110:6443 was refused - did you specify the right host or port?
通常是由docker daemon的驱动是cgroupfs和kubelet的systemd不一致导致的。修改Docker及kubelet的Cgroup Driver
这里给出本实验中kubelet与docker的驱动配置
- 修改kubelet驱动
vim /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
#Note: This dropin only works with kubeadm and kubelet v1.11+
[Service]
Environment=“KUBELET_KUBECONFIG_ARGS=–bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf”
Environment=“KUBELET_CONFIG_ARGS=–config=/var/lib/kubelet/config.yaml”
#This is a file that “kubeadm init” and “kubeadm join” generates at runtime, populating the KUBELET_KUBEADM_ARGS variable dynamically
EnvironmentFile=-/var/lib/kubelet/kubeadm-flags.env
#This is a file that the user can use for overrides of the kubelet args as a last resort. Preferably, the user should use
#the .NodeRegistration.KubeletExtraArgs object in the configuration files instead. KUBELET_EXTRA_ARGS should be sourced from this file.
EnvironmentFile=-/etc/default/kubelet
ExecStart=
ExecStart=/usr/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_CONFIG_ARGS $KUBELET_KUBEADM_ARGS $KUBELET_EXTRA_ARGS
- 修改docker驱动
vim /etc/docker/daemon.json
{
“exec-opts”: [“native.cgroupdriver=systemd”]
}
在这种配置下,kubelet日志会提示failed to run Kubelet: failed to create kubelet: misconfiguration: kubelet cgroup driver: “cgroupfs” is different from docker cgroup driver: “systemd”,也就是docker与kubelet驱动不一致,kubectl get nodes可以看到master节点没有ready,但不影响实际运行,改成systemd或者cgroupfs时,便会报错,无法运行,这一点也是我比较疑惑的地方,欢迎各位同仁提出宝贵意见!
上述问题后记
用journalctl -f -u kubelet查看kubelet相关日志后,发现是NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized Unable to update cni config错误,这不就是没有安装网络组件嘛,突然想起来!!!master节点Notready的原因其实就是自己忘记安装网络组件啦!!
然后根据k8s 集群部署问题整理这篇文章的步骤,成功安装flannel组件之后,master节点也恢复为ready了。

之前还以为是docker cgroup的驱动问题,其实并不是,这里留个记录。