一个基于Memory Pool的图像算法内存池实现
动机
在实现图像处理工程应用中,往往需要一些临时的中间图。若应用较为简单可以固定一些image buffer,反复利用这些内存来达到避免内存碎片和节省内存申请的时间。但业务流程较为复杂时,还是需要内存池来帮助管理这部分内存。大致搜索了一下现有的内存池,其中boost的四种内存池显然不符合我在这里提到的需求。我希望的是可以存一些图像的中间结果,可能是小图也可能是大图,是不定长的且内存的需求量较多。
后来看到了一份古老的实现,觉得逻辑简单清晰,方便改写和查验。只需要略加修改就可以满足我的需求。
代码主页如下:http://www.codeproject.com/cpp/MemoryPool.asp
再附上一份别人的中文翻译:https://blog.csdn.net/imxiangzi/article/details/50953295
适配
到这里,假设你已经看完了上面链接的内容并理解了其实现的逻辑。现在就可以根据需求进行修改了。看完整个内存池的实现,我发现主要有三个地方不满足我的需求。
- 多次free同一块内存,会触发异常。
- 申请的内存不连续
- 因为有chunk size的限制,不够灵活。
其中1和3都是小问题,1加个判断,3本文最后说明一下。2的问题比较严重,会导致不小心越界。下面具体的说明为什么原始实现会导致问题2。
假如我的chunk大小为100Byte,初始化5个chunk。则内存结构用下面图示表示。注意chunk之间是指针相连,mem是实际从os申请的连续内存,chunk中的数字表示从该节点可以分配的最大内存数目,很明显是依次递减,第一chunk可以把前五个chunk全部分配出去,第二个则最多可以分配四个… 依次递减,知道最后空指针链表尾部无法再切分。
case 1:
chunk |500|-|400|-|300|-|200|-|100|
mem: |100||100||100||100||100|
此时,我需要一个400Byte的内存空间,在调用malloc后则变为
case 2:
chunk |500x|-|400x|-|300x|-|200x|-|100|
mem: |100x||100x||100x||100x||100|
chunk中加上x表示已经被占用,再申请其他内存时会跳过这些节点,除非被占用的内存被释放。然后我再申请300Byte的内存,很明显内存池的空间不够了(实现过程中建议要精打细算,避免这种情况频繁发生)。按照原始代码的逻辑需要申请300Byte额外内存,并拼接到当前chunk链表的尾部去,同时通过RecalcChunkMemorySize()函数对chunk链表进行信息更新,函数实现如下:
bool CMemoryPool::RecalcChunkMemorySize(SMemoryChunk *ptrChunk, unsigned int uiChunkCount)
{
unsigned int uiMemOffSet = 0 ;
for(unsigned int i = 0; i < uiChunkCount; i++)
{
if(ptrChunk)
{
uiMemOffSet = (i * ((unsigned int) m_sMemoryChunkSize)) ;
ptrChunk->DataSize = (((unsigned int) m_sTotalMemoryPoolSize) - uiMemOffSet) ;
ptrChunk = ptrChunk->Next ;
}
else
{
assert(false && "Error : ptrChunk == NULL") ;
return false ;
}
}
return true ;
}于是变成了这个样子,注意mem中前500Byte和后300Byte之间用波浪号连接,表示它们之间的内存不连续,因为源码中是调用了两次原始malloc,无法保证两次申请的内存是连续的:
case 3:
chunk |800x|-|700x|-|600x|-|500x|-|400|-|300|-|200|-|100|
mem: |100x||100x||100x||100x||100|~|100||100||100|
看到这里问题的原因就很明显了,此时申请300Byte,会变成这个样子:
case 4:
chunk |800x|-|700x|-|600x|-|500x|-|400y|-|300y|-|200y|-|100|
mem: |100x||100x||100x||100x||100y|~|100y||100y||100|
y表示第二次申请占用的实际内存和chunk。我们的第二次申请跨越了连续内存,但是我们拿到的是mem中第一个y位置的头指针。所以当ptr[105]时,我们很可能已经越界了,我们期望访问的是第6个chunk的第6个字节,实际上却越界了。
问题找到了,代码很好修改:
首先要把RecalcChunkMemorySize用一个新函数RecalcChunkMemorySizeNoBreak代替:
bool CMemoryPool::RecalcChunkMemorySizeNoBreak(SMemoryChunk *ptrChunk, unsigned int uiChunkCount)
{
unsigned int uiMemOffSet = 0;
unsigned int newChunksTotalSize = uiChunkCount*m_sMemoryChunkSize; // 添加此变量
for (unsigned int i = 0; i < uiChunkCount; i++)
{
if (ptrChunk)
{
uiMemOffSet = (i * ((unsigned int)m_sMemoryChunkSize));
ptrChunk->DataSize = (((unsigned int)newChunksTotalSize) - uiMemOffSet);// 修改新chunk的初始化
ptrChunk = ptrChunk->Next;
}
else
{
assert(false && "Error : ptrChunk == NULL");
return false;
}
}
return true;
}这样改变后,在更新chuak链表后就不会从头开始更新了,只是更新新malloc进来的内存:
case 6:
chunk |500x|-|400x|-|300x|-|200x|-|100|-|300|-|200|-|100|
mem: |100x||100x||100x||100x||100|~|100||100||100|
配套的需要修改一下寻找空闲chunk的代码,让空闲chunk从头开始搜索。
SMemoryChunk *CMemoryPool::FindChunkSuitableToHoldMemory(const std::size_t &sMemorySize)
{
// Find a Chunk to hold *at least* "sMemorySize" Bytes.
unsigned int uiChunksToSkip = 0 ;
bool bContinueSearch = true ;
//SMemoryChunk *ptrChunk = m_ptrCursorChunk; // Start search at Cursor-Pos.
SMemoryChunk *ptrChunk = m_ptrFirstChunk; // Start search at Cursor-Pos.用这句替换上面注释的那句
for(unsigned int i = 0; i < m_uiMemoryChunkCount; i++)
{
if(ptrChunk)
{
if(ptrChunk == m_ptrLastChunk) // End of List reached : Start over from the beginning
{
ptrChunk = m_ptrFirstChunk ;
}
if(ptrChunk->DataSize >= sMemorySize)
{
if(ptrChunk->UsedSize == 0)
{
m_ptrCursorChunk = ptrChunk ;
return ptrChunk ;
}
}
uiChunksToSkip = CalculateNeededChunks(ptrChunk->UsedSize) ;
if(uiChunksToSkip == 0) uiChunksToSkip = 1 ;
ptrChunk = SkipChunks(ptrChunk, uiChunksToSkip) ;
}
else
{
bContinueSearch = false ;
}
}
return NULL ;
}下面来看下现在的结果吧,在申请300Byte后变为:
case 7:
chunk |500x|-|400x|-|300x|-|200x|-|100|-|300y|-|200y|-|100y|
mem: |100x||100x||100x||100x||100|~|100y||100y||100y|
从case7可以看出,内存已经连续了。然后再申请100Byte,按照预计的那样,把500Byte空闲的那部分利用起来了。
case 8:
chunk |500x|-|400x|-|300x|-|200x|-|100z|-|300y|-|200y|-|100y|
mem: |100x||100x||100x||100x||100z|~|100y||100y||100y|
重点比较case3和case6,以及case4和case7来理解是怎么避免内存不连续的。实际上chunk链表维护了一段段连续的内存空间,这里可以称做sub-pool,我们做的修改就是为了避免由chunk申请出去的内存跨越不同的sub-pool。
上面的简图不是特别清晰,下面附上代码测试辅助理解。
测试代码:
int main(){
MemPool::CMemoryPool *g_mem;
g_mem = new MemPool::CMemoryPool();
printf("index addr diff chunkSize\n");
void * p1=g_mem->GetMemory(400); //申请400内存
void * p2 = g_mem->GetMemory(300); //申请400内存
g_mem->PrintAllChunkAddr();//打印chunk链表的关键信息
printf("p1:%p \np2:%p\n",p1,p2);
g_mem->FreeMemory(p1,-1);
g_mem->FreeMemory(p2,-1);
delete[] g_mem;
getchar();
getchar();
return 0;
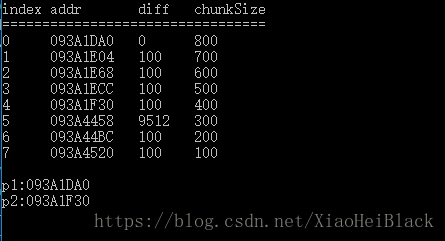
}未修改内存池的结果:
修改后内存池的结果:
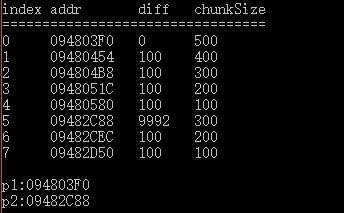
在图中,index是chunk的索引,addr是chunk中data指针的地址。diff为本chunk和上一个chunk指向地址的差,chunkSize是每个chunk的最大可分配内存。注意到index为5的chunk已经和上一个chunk管理的内存不连续了。但是原始代码还是把index为4的chunk维护的内存交给指p2了,带来了越界的风险。修改后的结果,p2的结果为index为5的chunk对应的内存,不会导致内存越界。
补充
经过实际测试有以下结论:
- 合理使用缓存池是可以提高申请内存效率的,初始化参数至关重要。,如应用中的图大小都为4000*3000,那么初始化时把chunk size设置较大,如256Byte。并设置2*4000*3000大小的初始内存池,就比chunk size设置成100Byte,初始大小500的快很多。前者效率假如1ms,后者达到100ms+。
- 会导致部分内存浪费,因为最小分配单位为chunk size,所以最多浪费一个chunk size以及一些池内内存碎片。不过在图像处理的应用场景下,除了DSP之类的,安卓、PC和服务器都不在乎这点内存了,而且显然池内的碎片是我们是可控的。
- 避免了内存碎片。但是内存池有越来越大的风险(使用不当的情况下),建议再对内存池做一个max size的限制和约束。
- 文中开头也说了chunk size的浪费内存的问题。本文是希望做一个图像算法的内存池管理,管理的是临时文件。在一个特定的应用场景下,图像的尺寸是不会变化太多了,所以这个简单的内存池实现就有了应用的价值。另外还可以做分级策略,实例化多个
CMemoryPool类,设置不同的初始化参数,大图用大的chunk值的内存池管理,小图用小的chunk值的内存池管理。
用c++做算法实现,比较痛并快乐的一点就是对内存的掌控度很高。补充下这个实现不支持多线程,但是一般做图像算法应用也犯不着在子线程里申请子图,把整图分块分给多个线程并行处理即可。