为什么不断做迁移,那是在还技术债
本文来自2018年QCon旧金山大会的演讲,Will Larson谈到Stripe公司的代码剧增后,迁移是有效治理技术债的唯一机制,同时他还介绍了不断迁移的方法。
我是Will Larson。在这里,我要谈谈技术债以及实际上怎么处理这些不断出现的技术债。今天早上,我收到别人发来的推特消息,“我很抱歉错过了你的演讲”。我正感到得意时,他们说,“你迄今为止可能解决了大量的技术债”,这让人感觉有点像是反话。我不确定对此的感想,但是技术债是一种体验,尤其是当你在事业上更进一步时,管理技术债成为一种常态,我认为学会管理技术债是很重要的。它是决定一个公司是否能长期成功的一个因素。让我们来深入了解一下。
我现在工作于Stripe,在基础SRE团队工作了几年。我们从事数据、开发人员生产率和基础架构方面的工作。在此之前,我也在Uber工作了几年。我从工程组开始做了很多和基础架构相关的工作。不知道四、五年前你们有多少人乘坐Uber,那时,只要你一上车,司机就会告诉你,“噢,这是我的第一单”。
实际上,这是他们针对用户的一种策略,即如果司机每次都告诉乘客这是第一单,则乘客给司机的评价会更高些。因此,我要说,今天是我的第一次会议演讲。我首先会告诉大家演讲的目的,接把结论提前告诉你们,然后不断地谈及这一点,就像别人告诉我的那样。当公司变大时,技术债是影响公司快速成长的核心限制。
迁移就是完全替换掉一个工具、系统或库。它不能被部分地替换掉,也不是变成一个半或变成三个,而是完全的替换掉某样东西,让其消失。要想迁移成功,正确的做法是把单个迁移都看成一个产品。
什么是迁移?
首先要了解什么是迁移?接下来,就可以了解如下的一些问题,如迁移实际上是否重要?为什么不能忽略这一步?如何才能避免每隔几年就更换工作?你是否真正地做好了迁移?当陷入困境时,如果不跳槽,该如何继续?
正如Jessica’s [泰]之前谈到过的,当看到这张动物图片时,我只会想到和大家分享这个令人激动的画面,而不会注意这是火烈鸟的迁徙。迁移是整个地替换一个工具、系统或库。有哪些例子呢?我想到了一个很好的例子,就是去年在Stripe,我们从工具Chronos(在Mesos上面做二次调度的工具)迁移到Kubernetes 的CronJobs。我们坚决反对再使用Chronos,对其进行了移除,并彻底迁移到Kubernetes。这是一次冒险的经历。
另一个迁移的经典案例则是AW或者说Netflix把他们自己的数据中心迁移到云上。几年前,我曾和一名Netflix员工交流,他们的做法很让人惊奇,数据仓库是他们最后迁移的部分。而且,他们实际上只是把他们的数据仓库返还并卖给了其供应商,该数据仓库后来成了一个平台即服务。这也算彻底完工的一个方法,即重新定义什么是成功。

另一个很有争议的案例则是Uber从Postgres迁移到MySQL。在黑客新闻上,有一些人对此表示不满,这也许可以作为一个成功标准。今年早些时候,Dropbox从Python 2升级到Python 3,看起来这种迁移有点不合理,Python 3后向不兼容,这是一个很大的变化,对他们而言,这也是非常重要的切换。迁移,就是完全地替换一个系统、库或工具。
迁移重要吗?
迁移重要吗?我们已经定义了什么是迁移,但你们为什么要关心这个呢?你们是否应该走出这个相当拥挤的会议室呢?
生产率会随着时间推移降低。当你第一次创建代码库时,只是很小的一个创业公司,每件事都很简单,你可以很快搞定所有事。如果你在家看到类似这样的推特消息,“我可以拿到你们的网站”,或者,“我可以拿到你们的产品,在周末用大约两小时的时间重新创建它”。如果有人这么谈论过你的工作,你就会知道,如果只是一个相当小的公司或团队,一个全新的项目,两个小时几乎可能搞定任何事情。
但是,当代码库变得复杂,功能越来越多,当前代码和原本的设计出入也越来越大,随着时间推移,要做任何修改都将变得越来越困难。团队希望变得有效率,而不是效率低下,如Jessica之前谈到的一样,在Airbnb,部署某些时候变得异常痛苦,我觉得这是很好的一个例子。因此,团队会竭尽全力变得更有效率。
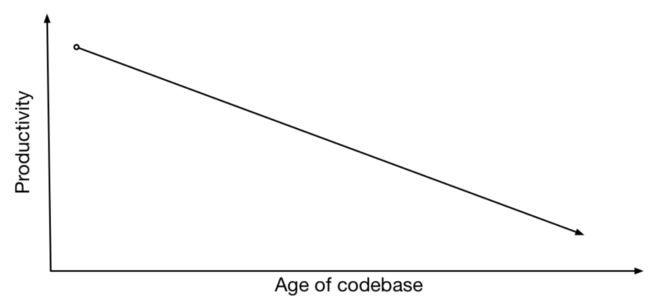
他们会采取一些措施,如代码审查、句法分析(linting),任何他们能做的事,他们会一点点地使他们的工作变得更轻松。每次,你采取其中一项措施,事情就会变得好一点。你一项一项地采取这些措施,最后会陷入低谷,你好像已经用尽了所有可供实现的好点子。现在的问题是,走到这一步该怎么办,停止改进吗?
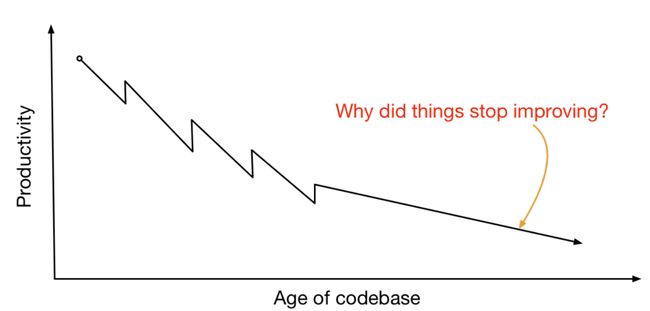
实际上又发生了什么呢?团队自我授权,自下而上,为了使他们的工作变得更好而做任何他们职责范围内的事。他们更改自己的代码库、自己的服务、自己的库、自己的工具。最终,他们会完成自我授权的所有事情。很多时候,人们认为,这里的问题是他们之间无法达成任何一致。

但实际上,我发现,对于大部分改动,每个人都同意去做。它有显而易见的好处,我们只是切换到一个技术负债小的系统,对吗?但同时,这不仅只是对一个方案投赞同票,还意味着许多其他的事情,如时间表的混合、匹配等。因此,我真正希望的可能是,先在后端团队做,再在前端团队做,“是的,我们下季度再做吧”。
大家可以理解,就像在有些不同寻常的情况下,每个人都认为他们想要做某些事而且很紧急,但实际上从来没有完成它。这是因为,在某些时间节点上,有太多的团队需要协调方法、优先级、时序来完成这些事情。一开始就能看到这点,情况会好一些。另外,我的图表看起来非常糟糕,和我在报告中所做的一样。糟糕而专业的图表。一开始看起来还不错,后来就不行了。那我们之后可以做什么呢?答案是可以做迁移。

所以迁移就是,用更有效的库、系统、工具等来彻底替换掉已经不能有效工作的部分。这也是一种简化,对吗?迁移并不会一夜之间带来奇迹,实际上,它可能在某些时候会让情况更糟,但对于更新换代来说,这是值得的。完成一些事并扔掉所有的技术债。然后开始另一个项目,工作一段时间后,情况会变好。再开始另一个项目继续完成它。
但有趣的是背后发生的事情,即你所在的组织不会一成不变。最开始,你有一个研发团队来做这些变更,这会非常快。几年之后,有3个工程团队的时候,变更就会变得有些困难,但也还在可控范围之内。然后团队规模可能会突然扩大到15、50、500、5000,变更就会变得非常非常复杂了。你会发现,实际需要做的可能是3个、4个、5个或6个持续的迁移,而不是一个迁移就可以搞定。
你开始停滞不前。当你的工程团队,如新闻、API、广告等,耗费几乎所有的时间来做迁移,而没有任何多余的时间来做用户相关的工作。企业或公司会经常突发地需要实现基础架构方面的需求,而员工根本没有时间来为用户创造价值,也不再是新奇感和创新性十足的创造型员工了。当产品工程师们把全部精力都倾注于基础架构相关的改动时,就会陷入了这种不正常的状态。
基础架构团队的情况会好一些。他们几乎没有对外依赖,外部的影响也不明显,反馈环路也就相对较弱些。因此,给其他团队带来更多工作的基础架构团队通常意识不到,这对于产品工程团队或栈顶的团队会变成怎样的困难。
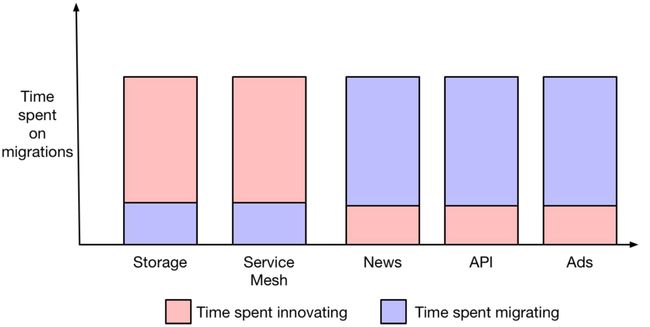
迁移成功和失败的对比
现在,你已经变得忙乱,会发生什么呢?情况会更糟。因为到现在为止都是假设迁移成功。而实际上,很多迁移是不成功的。你打算替换RPC层,替换编排层,替换前端库或替换设计语言,就像打了个赌。突然之间,你花光了所有的时间,让所有的团队一起协作进行迁移,结果失败了。这让人感觉很难堪。你不想它失败,但是你的生产效率持续下降,在很短的一段时间里,甚至接近了零生产率。
Heperbahn Uber的Hyperbahn是一个非常好的例子。Uber过去一直使用HAProxy做路由请求。这是一种简单的路由方法,每个服务器在Clusto上都有一个配置。Clusto有点像命令行窗口,但它来自Digg,没有被其他公司所采用。Clusto使用Python语言,也存在一些问题,但它仍是个很酷的工具。我们构建这些HAProxy配置,然后是HAProxy的sidecar模式,我们在该模式下进行本地路由,没有共享分布状态。

很多情况下,这样处理是很好的,但是当你要增加越来越多的服务器时,缺少集中化的配置或集中化的状态来协调路由会让人很累。Hyperbahn项目应运而生。Hyperbahn最重要的一点是它明显比它要替换掉的方式更先进。断路器,非常复杂。速率限制,它有不同的抢占式重试,它有各种类似这样的很棒的功能。但是,接口变了,这意味着从一种服务实现切换到另一种会变得非常困难。
最后的结果是,很长时间以后,我们会有太多的服务需要维护。但是我们很难做到面面俱到,系统很可能以失败告终。这是迁移过程中可能遇到的最坏的一种情况。我们不仅不能更快,反而会浪费时间做迁移并迁移回去。其后果就是,几年后,它成为一个废弃的项目。这里主要不是为了说Hyperbahn不好,Hyperbahn本身确实是一种比它要替代的技术更好的技术,而是说迁移本身失败了。
团队在迁移上的赌注
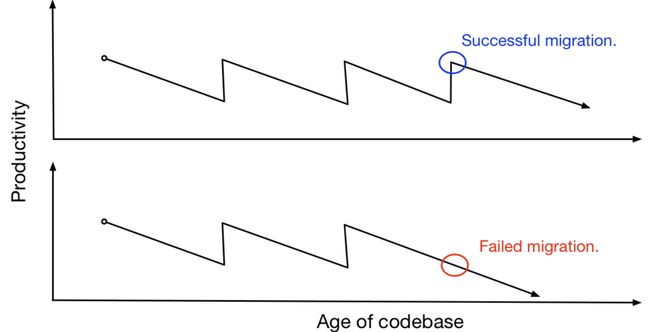
接下来我们会谈到怎样做得更好。我认为,迁移失败也像是迁移的动力。如果迁移的不好,团队可能会得到一些反馈,如“好吧,上次我和你一起工作了很长时间,接下来我必须做回自己的事了”,或者是“毫无疑问,这次不能和你一起工作了。不过,如果你已经快做完了,也许下次我们可以一起工作,我会最后一个做迁移”。实际上,如果你一次迁移失败,人们下次就不愿意和你一起工作了,因此,你就有动力把迁移做好。
Digg v4
相反,也有好的案例。如果你做得相当好,人们觉得这会节省他们的时间,下次会愿意继续和你合作。他们知道你会减少他们的技术债。不过,迁移成功或失败的势头也是很重要的影响因素,如图上红圈所示,如果连续好几个迁移都失败了,到最后生产率几乎会降到零。如果你从来没有在一个经历过该阶段的公司工作过,你会认为这不可能发生,好像我们能控制,能做任何事情一样。在一个代码库上怎么会无法往前推进呢?但是,我曾在多个团队和公司待过,他们都碰到了这种情况,最典型的是Digg v4。我之前和Randy讨论过,他没有意识到我在Digg工作,他说那是差劲的迁移实例。很讽刺的是,那是我感到很自豪的工作之一,但它同时也是一个完完全全的灾难。之前的代码库叫LOLcat,即使我们是专业人员,也很难基于它开展工作。它是一个PHP单体应用,我们最终替换掉了它,但我们决定不只是让它看起来被替换掉了。
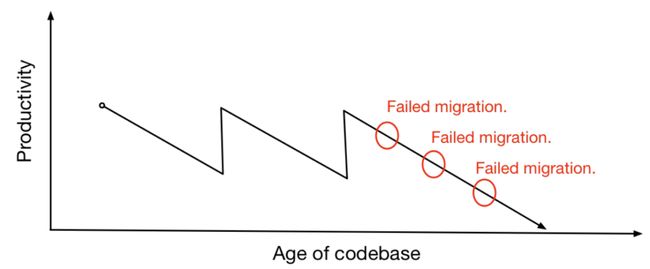
五六年后,如果我们尽力做到最好,会出现什么情况呢?我们知道,MySQL比较旧,有时候会出现问题,Facebook推出了一种新型数据库Cassandra。不知道是否有人听说过下面的玩笑话,Cassandra就像Facebook发布的一个特洛伊木马病,用来毒害新一代创业公司。2018年,Cassandra实际上已经是一款非凡的软件,对吗?但在2011年,时间还有点早。我们切换到Cassandra,后端切换到Python语言,我们切换到Thrift协议。我们做了所有这些切换。只是SQL,对吗?我们把每个算法删除,然后重新开始,没有任何理由。新的总是好的,但没有效果,人们讨厌它,不再访问我们的网站。我们花光了钱,关闭了公司,每个人都回家了。如果陷入迁移混乱中,就会出现的情况,耗尽生产率,重写整个系统。这是非常非常危险的,接下来就只能回家并丢掉工作了。迁移重要吗?答案是肯定的,因为我们不想回家并丢掉工作。
接口
如果你不喜欢迁移,不喜欢做任何类似迁移的工作,最好的方法就是拥有强大的接口。强大的接口意味着它们之间重叠的部分要尽可能得少。这样,团队才能够不断地自我授权,提高生产率。同时,依靠那些聪明缜密而且可以在自己的工作范围内自我授权的人员来抑制任何生产率的大幅下降。
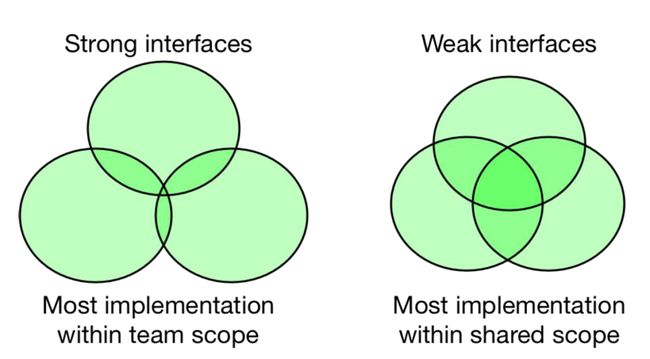
有效的迁移
相反,如果接口弱,彼此间重叠很多,作为一个整体,边界定义的不清楚,我们能做的事情不多,则只能尽快做迁移。好了,我们知道什么是迁移,也知道它意味着什么。现在,怎么实际地开展迁移呢?每个迁移都是一个产品,我会反复强调这一点。这个过程分为三个风险阶段或三个过程,即去风险、使能、完成。因为每个迁移都非常重要,同一时段,只能做部分迁移。能够并行进行迁移的数量是有限制的。
我们必须考虑迁移带来的好处。这意味着几件事,第一个就是“这么做值得吗?”。坦白地讲,我认为,大多数迁移没有解决已有的问题。很多迁移是由错误原因引起的。下面给出一些策略,它们将从迁移的角度来看是否值得。
寻找支持者。经常会出现这种情况,我觉得很有意思,就是当你决定做某些事情,如针对新的数据库、新的后端,新的Digg v4进行重写,却找不到一个团队真正地愿意支持你。这不是指高管层的支持者,对于高管层,只要付出足够的努力就能说服他们。我们需要寻找的是工程团队,虽然忙但愿意把你的工作的优先级排在他们当前正在做的工作之前的团队。
如果找不着这样的团队,也许这是一些不值得做的事。找到一个信任你工作的另一个团队是非常重要的。一旦你找到一个,可能还有第二、第三个。
第二,机会成本。选择一个迁移不代表它有价值。因为有诸多限制,我们必须识别出能做的最有价值的事情是什么。这点很重要。同一时间段,只能做其中的一部分,因为很占用时间。这是策略性的赌注。
比如,公司会采用的一些最重要的策略性赌注,它们决定了你的实际能力,是重写新功能,还是以零交付告终。我们经常会像这样,“哦,如果我们迁移到这个新事物上就太酷了。”但是,真正的机会成本,这是你本次可以做的最有价值的东西呢?作为资深人士,做这样的选择是你的职责,它决定了你公司的未来,你会因此而受人尊敬。
第二条不是我发明的。最近,在我和别人聊天时,他们谈到了正在构建自己的高一致性或强一致性分布数据存储的初创公司的数量。事实证明,这是一个很难的问题。毕竟他们和数据库公司不一样,这更像是一些创业公司,试图创建另一个Spanner或另一个Cosmos DB。如果没有秘密武器,这几乎是不可能解决问题的。所以说,这不只是一件很好的事,也是一件很酷的事。很多时候,人们容易被一个问题的有趣性所吸引,从而忽略了这个事情本事是不是值得去做。不要这样做。
再一个是为工具找问题。第一次练习本次演讲时,我列举了一堆我认为是糟糕选择的例子,事实证明,如果想要不冒犯至少一半的听众,那就没有办法做出选择。因此,我希望大家做的就是,想象一下,你看到别人采用了而进展非常不顺利,然后你可能会想,“哦,他们周末刚做的,现在要拿到这里来讨论,这正是我在谈论的东西。他们为什么这么做呢?”
设计文档
如果你认为某件事有价值,值得去做,接下来的问题是解决方案是否有效?设计文档是第一步。这里有三个步骤。第一是你要先让自己相信,这个方案有效,写下具体细节,最终让你自己相信这种方案切实可行。
第二,你需要让用户相信该方案对他们而言是可行的。第三,人们通常容易忽略这一点,而我认为更重要的是,让持有不同意见的人相信该方案的可行性。搞定那些可能赞同你想法的人是一方面,但是,如果你没有试图找到那些讨厌你的想法,认为该方案很糟糕或对你持怀疑态度的人,从他们那里得到反馈,你就没有做好前期的准备。
一个好的设计文档不会包含你应该做某事的原因。如果有,它同时还会有更长的篇幅来写为什么不应该做其他事。如果你不能说清楚为什么不做其他事,你就不能说清楚你的解决方案是否有效。
原型很多时候,原型对人们来说就是第一个版本V0。但原型并不是指构建第一个版本或是快速版本。它不是用来验证正确的实现方法。实际上,存在多种解决方案时,原型可以降低风险。这就像在两个小时内找到可以做的事情。如果你试图将服务器配置从Puppet迁移到Dockerfiles,可以选择Puppet中的一个角色,重写成Dockerfile。这可能很糟糕,但你的任务就是花几小时看看这是否可行。你并不是要试图创建一个可以工作的版本,也不是创建一个一直运行的实现,你只是要确认你的方案是否很可行,“我们花了两个小时来验证,然后停下。”
让前期使用者参与
让前期用户参与进来是更深入原型的一个方法。确保能够满足他们所有的需求。为了实现好的产品设计,要尽快同客户建立良好关系。他们能看到那些你看不到的边缘情况。我认为,当你经常操作一个系统时,对于使用它会有一种抽象的感受,这也是为什么需要实际地参与,加入会成为早期使用者的团队,设法让原型为他们工作。
Kubernetes就是一个很好的例子。因此,我们有了以它为基础的Chronos,一个Mesos调度程序。结果在运营上,有点被抛弃了,我们内部并没有很好的拥有它。但总的来说,这个项目在最初创建它的公司里就没有得到太多的使用,所以有一点衰败。我们内部有个团队使用了大量的约有90%的Chronos cron任务。我们加入进去和他们一起工作,把每一个都移走了。
这也是让我们很吃惊的地方,在将Chronos替换为Kubernetes的迁移中,验证了我之前关于迁移的、也是唯一的定义。突然之间,Chronos被完全的废弃掉,Kubernetes上的CronJob,那时不被人看好,它早期有一些问题,现在已经好了。我们成功做了迁移,那时仍然考虑二次迁移,即把无状态服务迁移到Kubernetes。
一难一易
当你想看某件事是否能正常工作,先让容易的部分可以工作。这很重要。做简单的事情会简单些,否则,团队成员不愿意接受。但人们也包括我犯过好多次的一个错误是,去做了第二、第三简单的事情。从度量数据来看,似乎进展不错。然后,当遇到很难的部分而做不下去时,能做的就是撤回已做的迁移工作。
当前阶段,我们的目标不是尽快的完成任务,而是确保任务完成的可行性。所以应该先易后难。如果难的部分不工作,反而更好,此时只需撤回简单部分的实现和集成。这可以节省我们和用户的很多时间。做好这一步,就不容易失败,导致用户失去信心。在大公司里,你可以有很多这样的经历。
在Stripe,一个很好的例子就是MongoDB的升级。在很长的一段时间里,Stripe在旧版本的MongoDB上是世界顶级专家。我觉得自己比实现MongoDB的工程师们了解的还要多。在这个特殊的版本上,我们有很多技巧,在决定升级时,是有些压力的。这是我们所有的数据,非常重要的数据,有足够多的数据都在这个数据库里。每个人都会问,“你们有备份吗?”。当然,我们有备份,但是当数据量非常大时,恢复这些数据,仅仅是数据的传输就会花费大量的时间。所以问题不仅是“你备份了吗?”而可能是你有两个数据备份吗?你愿意花双份的钱吗?这里需要取舍权衡。
当我们决定做迁移时,我们首先做了能想到的最简单的事情。比如,只有几行代码的营销网站停止工作了,我们可以恢复,毕竟只有很小的数据集合,可以在一两小时内恢复,对用户的影响不会太大。现在,轮到最难、最棘手、最让人畏惧的部分,如访问模式非常古怪的数据集合。我们迁移过去了,虽然有点困难,有时会来回切换,但最后我们还是彻底让它工作了。那时,我们就知道,其他的每件事都可以迎刃而解了。
在我们完成这些比较简单的部分时,可能会碰到失败的点。当在新版本中遇到不同的可扩展性问题时,我们不得不做一些回滚。这样会更安全、便捷和简单。消除风险。现在我们知道了,正在做的首先应该是值得做的。第二,方法可行的,能正常工作。真让人很激动。所以,下一步是识别出你能做什么,让迁移变得简单。
用户测试
用户测试可以说是最重要的事情。这就像你看到了一个小公司,就像这个样子,“我们做出了令人惊叹的产品,但没人愿意使用它”。你必须尽快找到用户。必须实际地测试迁移。至此,一个重要的区别是这样做并没有测试产品,而只是测试了产品的使用。迁移对于要切换到该产品的人来说要尽可能得简单。测试接口,让人们真正使用你的接口来解决问题。观察他们对接口的不满。我们就是这样学习的,不是吗?观察人们如何使用你的接口。这能让你进入快速迭代周期。就这样做。
文档
文档工作经常容易被忘掉。我认为在Stripe早期的成功和持续发展中,文档工作非常重要,优质的文档让员工可以很容易使用。在每次迁移中,如果给人们可用的文档,他们就可以根据自己的时间安排几小时实施迁移,而不需要等你有空闲时间去协助他们解决。但是,只有你坐下来,观察别人怎样使用你的文档来进行迁移工作,你才能知道文档是否实际有用。
对于Email来说,也是如此。很多时候,Email像是世界上最糟糕的东西。我不记得在读写电子邮件上到底花费了多少时间,但是很多很多。但如果你不对电子邮件先做测试就发出去,那是在浪费人们的时间。因此,对你的电子邮件也进行A/B测试吧。让小部分人先阅读,看看他们是否明白需要做什么。邮件吸引人吗?让人兴奋吗?这些并不是必需的,但是可以让邮件起到它的作用。 “真正的技术难点在哪里?”,又或者是“什么是成功的必要因素?每件事的质量体现在哪里,电子邮件的质量,文档的质量,而不仅仅只是代码的质量”,这些问题看起来有些奇怪,但可以让你在职业发展中上一层楼。
操作
我认为操作是一个常规步骤,很容易切换。实际上,一旦切换,人们不会再使用不好的系统。确保人们真正使用系统。我觉得混沌工程是个很好的方法,早期人为注入故障,迫使用户习惯系统操作,让用户在实际使用前或至少在我们自己宣称系统可以工作前,对系统有信心。
调试
调试也一样。注入故障进行测试,最终让人们习惯这个系统。经常会有工具帮助人们完成切换,但这会让人们失去调试系统的能力。
这是很糟糕的,因其突发性,人们不清楚切换是否存在问题,可能在哪里,是在迁移中少了一个标识或其它的东西,还是底层系统工作异常。出现这种情况后,人们很快就会不信任新系统。他们会相互谈论这个问题,说来也奇怪,他们会从其他使用过新系统的人那里了解到新系统无法正常工作,这会妨碍其他团队的采用。而实际上,新系统是工作的,这只是一个误解。但是,对于已经认为你的产品不可靠或有问题的人来说,你完全无法说服他们。你只能确保他们在早期就获得了这样的信息,有了这样的理解。
欲速则不达
现在谈下欲速则不达。重新回到之前的例子,早期做很多简单的事情,让你获得迁移势头。努力识别出完成全部迁移所需要构建的工具。不需要在早期就全速前进,这点并不重要,重要的是识别出怎么开展工作,怎么构建工具,编写文档?怎样进行宣贯才能处于可以尽快完成迁移的有利位置?
自助服务
有关这一点,自助服务是一个很好的例子。很多时候,如果文档不够好,或者即使文档非常棒,执行迁移的团队也可能会变成整个生产环节中的瓶颈。这很糟糕,因为有个组织可能就正好准备好了迁移和完全切换。但是,团队正处于一系列的麻烦中,为个人提供帮助,回答各种问题,整天在Slack中回复这些问题,可能就是告诉他们,“答案就在文档中。”这就是前期的准备工作没做好,没法让人们自行解决问题。自助服务,从这个工作流程中脱颖而出,让人们可以自行解决问题。
自动化迁移
最好的迁移是不需要任何人做任何工作。通常,这还不够。我认为Sorbet是一个很好的例子。Stripe有着上百万行Ruby代码。Ruby是非类型化语言。它有时候有点神奇。我们一直在做的就是努力把渐进式类型策略引入Ruby,使用了正在开源过程中工具Sorbert。修改1亿行代码是不现实的,但老实说,让我们大约300个工程师来做所有的类型化工作也不可能,因为他们都忙着做相当重要而且非常价值的事。
因此,我们在迁移中所做的几乎所有工作就是一系列的脚本,通过编程重写抽象语法树,然后提交代码。在Googel ClangMR里有一篇很棒的论文,提到怎样在大得多的规模上进行这项工作。但是怎样能不手工做这件事呢?你可能会想,“啊,我们有600个工程师精通这个,可以都来参与。”但如果只有一个员工通过编写脚本来重写代码,你实际上可以跳过整个迁移,还跳过了调试,比如7000多个因为胖手指引起的打字错误。
如果公司没有诸如Codemod之类的工具,迁移之初,手动工作量都会被严重低估。如果工具使用得当,能够节省工程师们几百个小时甚至几百年的时间。
增量和回滚工具
迁移中的另一个典型问题是迁移有最后期限。通常是在周五,因为我们不能很好地按时间来安排相应工作。在周五4点、5点、6点或其他时间切换到新的系统上,就会有一个系统中断。
如果我们不给客户提供回滚工具让他们可以使用,遇到突发事件,就需要周五晚或周末加班进行调试。如果让他们可以撤销迁移,遇到失误后就可以返回到上一版本。这样,人们就会信任迁移,建立迁移过程中的心理安全感,他们会相信自己得到了很好的支持,而不只是强迫他们这么做。
增量迁移也很重要,它让人们可以一次只迁移一小部分。它让人们可以做得心应手或有足够的时间。迁移过程中一个不断重复的现象就是大家总有很多的工作要做,非常的忙。几乎没有终端用户会说类似这样的话,“我实际需要你们做的是迁移Cassandra集群环境”。你的外部用户对此并不关心。这种情况经常发生在边缘情况下或者暗处,在20%的时间里或120%的时间里.。确保每次只做一点点迁移是很有价值的。
灰度上线
一个可回退发布的例子就是灰度上线。通过灰度上线,可以频繁发布面向用户的产品,基础架构、库和迁移。可以在新旧版本之间通过开关功能标志位或配置设置来进行切换,这对于风险消除是很安全的一种做法。而且,也增强了信心,因为这不仅增强了当前做迁移的人员的信心,也增加了下一年会和你共事的人员的信心。
最后是接口。接口有点独特,因为从表面看并不明显。好的接口遵循一定的规则,差的接口亦然。好的接口正确限定了问题范围,让迁移简单易行,而差的接口让迁移变得非常非常困难。Mongo有些独特的属性,在Stripe,我们被它困扰就是一个很好的例子。用户必须根据他们不同的写一致性需求来构建持久性保护。
虽然不明显,但有一种情况可能会丢失数据。如果主备份先于从备份不可用,Mongo中的主备份是否会从丢失数据将取决于一致性级别。这是相当令人讨厌的,人们不得不保护这些数据,到处增加写前日志。
这只是一个例子,说明如果接口有一点错误,哪怕是一点点的疏忽,都会让人们花费很大的精力来获得正确的输出。少点爱,多点爱,少点用户测试,多点用户测试。所以要努力让接口达到100%正确,从而不会因为一些迁移中古怪的边界情况或问题停滞不前。
完成迁移
我们知道所做的事是值得的,方案也是可行的,可以稍微提前想想加快速度的工具。现在,我们需要完成迁移。完成是指100%完成,不是99%,也不是99.9995%,也不是指17个9或7000和9。它也不是指其他团队在维护旧系统,所以对旧系统没有任何影响。怎么才能实际弃用旧系统呢?怎样完全替换需要摒弃的系统、库或工具,从而得到完全的胜利并减少技术债呢?
uContainer
通过很多很多的迁移,我发现最重要的事就是停止压榨。我能想到的最好的例子就是在Uber做过的uContainer迁移。5年前,大约在2013年,Uber的道路服务已经提供,和无状态服务类似,有大量的Puppet变更, Clusto作为Digg的优质技术被移植到Uber。一系列的Clusto变更,也被添加来运行命令。增加单个服务,会花6到20个小时时间,因为系统总是存在一些错误,通信异常,从而导致输出不是预期的结果。
6-20个小时的工作对于SRE组员来说,是很折磨人的。实际上,人们还想要更多的更新,比如我们中的三个人,想一周有三到四次的迁移。现在突然的,我们需要花费大部分的时间来提供服务,并为此付出艰辛的劳动,如损坏的Puppet配置,但对公司来说没有任何价值。采用它们并并不好。但那时,在Uber,最恐怖的是公司人员以每年四倍的速度在增长。我们都觉得“这实在不好。”我们预期情况很快会变得更糟。我们所做的就是将所有配置从Puppet迁移到Docker。
我们采用了完全自助的服务方式,每个新的服务与SRE组的交互为零。这让人赞叹不已,其一,我们不需要在迁移上花费全部的精力。其二,我们可以把之前花费在迁移上的时间用来处理其它还未完成的事务,这真的是太棒了。其三,我们的度量数据表明,在没有人员介入的情况下,每天可以提供20个新服务。
看起来我们做了件了不起的事,让每个人都能提升效率。但实际上,我们什么也没有做。人们可以专注于已有的服务。要注意的是,使用绝对值而不用百分比。百分比数据会有欺骗性,当演讲变得乏味时,可以试着想象,这里插入7到8个猫咪表情包,如果正好和和你头脑中想象的猫咪图像一致,会让你觉得激动,有了活力,就不再觉得枯燥了。
跟踪
跟踪,这又是一类没有趣味但又不得不做的事情,因为我们需要从中受益,减少实际的技术债,并完成迁移。一个大体的方法是建立已做未做事宜的元数据。这些可以填到JIRA表单中,但不是手动来做,可以通过专门的工具来实现。不要手填,因为生命短暂。项目经理的生命也很短暂,每个人的生命都很短暂。构建一个工具吧。
这些令人惊奇的元数据可以用到其他的任何事上,比如,报告。执行迁移时,如µContainer迁移,刚开始有50个服务,等我们完全完成后,有2000多个服务。跟踪每年所有的50到2000个服务是件很混乱的事。但也是很有趣的一年。但我们需要报告来指出做的好的地方。我们有基于每个服务的元数据,可以明确指出哪些迁移失败了,给出最典型的例子。为了产品的研发,我们也可以建立经典案例,哪个组有困扰,哪类服务困难较大,从而做理论分析,了解可以在接口上做怎么的改进,哪些的地方接口和用户的实际需求不匹配,哪些地方是用户太忙了没有实际花时间和我们一起工作的。报告,并不令人激动,但老实说,如果你想让基础架构不断改进,想让公司尽可能成为最有产能的公司,而不是零生产率的公司,想要从零重写所有的东西,想要不带工作回家,跟踪报告是非常重要的。
增加推力
现在,谈下增加推力。很多时候,当人们做迁移时,是自顶向下的,比如“你有六周的时间,如果不能按时完成的话,你就成了坏人,我们的CTO也会对你怒吼。”事实上,很多时候这可以奏效,但是,你总不能一直疏远你的同伴们。可以改进这一点的思想就是增加推力。怎么能给人们尽可能多的信息,让他们能自发地做你希望他们做的事情,而不是告诉他们必须去做呢?例如,在Stripe时,我们做过AWS账单的成本核算,使用了一种不同的方法。我们会说“嘿,你现在花了大笔的钱,很酷哦,不过你的花销是最多的。你的平级团队只用了大约一半的钱”。这只是一点点的背景信息,但人们会突然意识到“可能我做的不合规范”。不用告诉他们那些事情做的不正确。你不是把关的人,只需要给他们提供一点信息即可。
迁移也是同样的。“嘿,你知道,你现在是最后一名。不过很酷哦,我们明白。你做的是很重要的部分,不过它的确太晚了,其他所有人都在16周前就结束了”。只是一小点的推力,一小点的信息。最重要的一点是,如果团队没有和你一起做迁移,这很多时候并不是因为他们讨厌你,而是因为他们根据领导的任务优先级安排他们在做的其他事情。所以,提供事情进展的足够信息作为一种推力,让他们可以自己去和领导进行讨论,并重新进行任务排序。
自己完成迁移
迁移的最后一步就是自己完成它。通常,人们不愿意做这一步,他们会想,“噢,这不是我的代码。开发团队应该负责迁移,完成他们自己的工作”。但是,我们知道,应该自己深入进去并完成它。在我的整个职业生涯中,最好的例子就是在Strip时做的供应商迁移。我们替换了可观测性供应商。我们不得不做完整的RIP,替换所有的度量数据和数据表。
我们还有一个合同要到期的供应商,如果同时更新它们成本会很高。而且,如果不能搞定,我们就会闹笑话。规则一就是不要闹笑话。也许是规则四,我记不太清楚了。但实际上,我们让大部分的团队自己进行了迁移,但当我们到最后期限时,可观测性团队加入进来,自己完成了所有的迁移。事实证明这是一段相当好的经历。我们在数据表中看到了很多常见错误。我们看到很多团队不清楚新的可用功能。他们需要暂停,进行升级,采用平台上更多的功能。最后我们做到了。这是最重要的,我们做到了100%。
完成后的庆祝
完成的最后一步是在结束时进行庆祝。有两种庆祝迁移的方式。第一个是针对你的用户的,开工时,你可能会说,“嘿,我们要实际开始做迁移了”。你会尝试劝说你的用户们准备好,你不会把它搞得和以前一样糟。所以这是给他们准备的,不是给你的。你只需要在结束时进行庆祝,这点很重要,也是你需要在公司里推行的一个文化准则。
如果不这样,人们会开始迁移,可能会得到这样的信息,“哈,我完成大升级了”,团队被解散了。突然之间,他们到另一个团队了开始新的迁移,这让你产生一种错觉,公司里最好的工程师们在不断地产生技术债。我们必须设定公司文化,否则会陷入困境。很多公司没有很好地认识到这一点。但是如果去做,它会带来令人难以置信的价值。
演讲即将结束。重点是什么呢?技术债是发展道路上最重要的制约。不断进行迁移是管理技术债的唯一方法。唯一的,最简单的,最直白的解决方案就是,把每个独立的迁移都当作一个产品来做。谢谢!
查看演讲原文:Paying Technical Debt at Scale - Migrations