练就火眼金睛:Python助你一眼看穿社交媒体中的假新闻!

全文共2767字,预计学习时长12分钟

图源:unsplash
2016年总统大选,和特朗普一起走上风口浪尖的是Facebook,假新闻一度成为了学界业界热议的话题。这个社交媒体巨头受到了来自各方的批评,人们认为,Facebook拒绝审查核实其平台上列出的新闻真实性这一做法危害性很大。
它纵容了虚假新闻和具有误导性信息的传播,这为阴谋论提供了温床。譬如,有传言说俄罗斯影响了那次大选结果。几年后,马克·扎克伯格现身国会回答了一系列问题。美国议员指责Facebook CEO在2020年大选前允许政治虚假信息传播。
在紧张气氛中,扎克伯格被问及政治广告活动缺乏事实核查的问题。亚历山大·奥卡西奥·科尔特斯问道:“我能在初选时针对共和党人投放广告,说他们支持绿色新政吗?”扎克伯格大吃一惊,无法回答这个问题。
越来越多的民众意识到要采取行动打击虚假内容。在社交媒体上阅读新闻是一把双刃剑。它成本低廉,容易获取,人们与全球事务保持同步,与他人分享新闻,也分享他们的想法。
然而,这种优势常常被病毒式营销所利用。比如尽管有些低质量新闻包含虚假事件,这些新闻还是会被传播开来。社交媒体上的假新闻形式多样,人们创建一些恶意账户来传播假新闻,如喷子、电子人用户、水军等等。
虚假新闻的迅速传播会对社会产生负面影响,它会助长错误认知2016年总统大选期间最受欢迎的政治新闻本身就是虚假事实。因此,在媒体上寻找基于事实的新闻是非常有必要的。

你该了解的

图源:unsplash
先打住,我们有必要先理解一些概念:
TF-IDF
机器学习的一大困境是算法计算数字,而自然语言主要由文本组成,因此需要将文本转换为数字,这个过程被称为文本向量化。它是机器学习的重要组成部分,有助于进行文本分析。向量化算法会产生不同的结果,所以你需要仔细选择。
TF-IDF是一种统计度量,用于确定文档中放置在一组文档中的单词的相关性。使用TF-IDF Vectorizer可以将文本转换为特征向量。它是通过以下两个指标相乘计算的:
· 术语频率是指一个单词在文档中出现的次数。
· 逆文档频率是一个单词在一组文档中出现的次数。
被动攻击算法(Passive Aggressive Classifier)
被动攻击算法是在线学习算法,用于从大量的数据中进行学习。例如,系统每天24小时从Twitter上收集推文,你希望根据这些数据进行预测。
然而,由于内存限制这是不可行的,你不能在内存中存储这么多数据。被动攻击算法从这些例子中学习,并在使用后立即丢弃它们,而不是将它们存储在内存中。这些算法被称为被动的是因为它们是温顺的,直到分类结果保持正确。一旦他们发现了错误的计算就会变得咄咄逼人,更新、调整模型。
混淆矩阵(Confusion matrix)
在机器学习分类中,如果输出应该生成两个或两个以上的类,则用于性能度量。有四种可能的结果:
· 真阳性——做出了积极的预测,结果证明是正确的。
· 真阴性——预测是负数,结果证明是真的。
· 假阳性——预测是肯定的,但结果却是错误的。
· 假阴性——预测结果是错误的。
难题
假设你已经用Python构建了一个web抓取应用程序,它收集了来自社交媒体网络的所有新闻链接。你该如何知道这些网站上的信息是来自真实事件呢?

图源:unsplash
解决方案
用Python构建一个系统,可以识别新闻链接是否真实,先用sklearn为数据集创建TF-IDF Vectorizer。TF-IDF的目的是将文本转换为特征向量,这能让你使用它们作为估计器的输入。
先决条件
打开命令行,下载并安装Numpy。Numpy是numericalpython的缩写,它为大量的多维数组和、阵及几个有用的数学函数提供支持。运行以下命令:
Pip install numpy
接下来,安装Pandas。Pandas将帮助你对数据执行大量操作,例如导入、准备、合并、重塑、连接、处理、分析和调整数据。它是围绕DataFrame对象组织的。运行以下命令:
Pip install pandas
最后,安装项目中最重要的sklearn库。它主要用于机器学习,含有内置的算法,这些算法包括模型选择、模式、聚类、回归和聚类的函数。运行以下命令:
Pip install sklearn
还需要安装JupyterLab。JupyterLab是一个基于web的工具,用于收集Jupyter数据、代码、笔记本。它具有灵活性,可以自定义它来处理机器学习、科学计算和数据科学中的多个工作流。运行以下命令:
Pip install jupyter lab
安装好了之后,可以在命令提示符中输入以下命令:
C:>jupyterlab
浏览器会打开一个新窗口,转到New à Console。勾选文本框,在这里输入你的代码,按Shift + Enter运行你的命令。

图源:unsplash
使用什么数据集呢?
我们将使用一个包含7796行和4列的大型数据集。这些列表示:
· 一个标识符
· 新闻标题
· 新闻文本
· 标签(例如,这则新闻是真是假)
从此链接下载数据集:https://drive.google.com/file/d/1er9NJTLUA3qnRuyhfzuN0XUsoIC4a-_q/view
对社交媒体上的新闻进行事实核查
导入刚刚在JupyterLab控制台中安装的所有库。运行以下代码:
import numpyas nyimportpandas as psimportitertoolsfromsklearn.model_selection import train_test_splitfromsklearn.feature_extraction.text import TfidfVectorizerfromsklearn.linear_model import PassiveAggressiveClassifierfromsklearn.metrics import accuracy_score, confusion_matrix
将Excel数据转换为二维数据结构(矩阵),我们需要使用来自pandas的DataFrame,它是一个可以包含异构列的二维数据结构。通过使用shape和head属性可以确定数据集的格式和检查行。运行以下代码:
#Read from the datasetdf=ps.read_csv(‘C:\SocialFactCheckPython\news.csv’)df.shapedf.head(6)
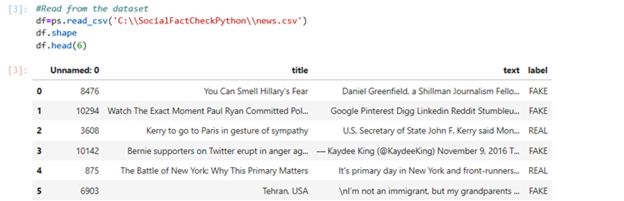
接着用DataFrame获得真实和虚假的事实。运行以下代码:
#Check the labelsfactcheck=df.labelfactcheck.head(7)

常见任务是将数据集分为两组:培训和测试。
#Split the dataseta_train,a_test,b_train,b_test=train_test_split(df[‘text’],factcheck, test_size=0.15, random_state=8)
将TF-IDF Vectorizer初始化。设置英文停止词,并指定最大文档频率为0.65。这表示包含较高文档频率的术语将被删除。
过滤出停止词来进行自然语言处理。TF-IDF Vectorizer用于将一组原始文档转换为具有TF-IDF特性的矩阵。随机状态用于指定随机生成的种子,它确保了分割测试集训练集总是确定的。
使用矢量化工具来适应并转换你的训练集和测试集。用.fit_transform学习词汇表和逆文档频率。作为响应,它会创建term-document矩阵。使用.transform可返回一个term-document矩阵。运行以下代码:
tfidf_vectorizer=TfidfVectorizer(stop_words=’english’,max_df=0.65)tfidf_train=tfidf_vectorizer.fit_transform(a_train)tfidf_test=tfidf_vectorizer.transform(a_test)
现在将被动攻击算法初始化,将它安装在tfidf_train和b_train上。TF-IDF Vectorizer将有助于对测试集进行预测,并用sklearn.metrics中的 accuracy score()函数进行事实核查。
在多标签分类中,accuracy score()函数可以用来处理子集的准确率。一个样本中预测的标签必须与另一子集中相应的标签完全匹配。运行以下代码:
pclass=PassiveAggressiveClassifier(max_iter=60)pclass.fit(tfidf_train,b_train)b_pred=pclass.predict(tfidf_test)factcheckscore=accuracy_score(b_test,b_pred)print(f’Fact-checkAccuracy Is {round(factcheckscore*100,2)}%’)
这表明,该模型在区分真实新闻和假新闻时,准确率为94.43%。让我们来看看它有多少次是正确的,运行以下代码:

结果是,有456个真阳性,442个真阴性,27个假阳性和49个假阴性。
Python可以用来检测出社交媒体上的假新闻。从包含政治新闻的数据集中提取数据,用TF-IDF Vectorizer将其转换为向量,运行被动攻击算法,拟合模型,最终能得到94.43%的准确率。

图源:unsplash
如今,假新闻已然泛滥成灾,是时候好好“收拾”它们了。

推荐阅读专题





留言点赞发个朋友圈
我们一起分享AI学习与发展的干货
编译组:吴子珺、孔祺琪
相关链接:
https://medium.com/datadriveninvestor/using-python-to-detect-fake-news-7895101aebb8
如转载,请后台留言,遵守转载规范
推荐文章阅读
ACL2018论文集50篇解读
EMNLP2017论文集28篇论文解读
2018年AI三大顶会中国学术成果全链接
ACL2017论文集:34篇解读干货全在这里
10篇AAAI2017经典论文回顾
长按识别二维码可添加关注
读芯君爱你