python爬取微博用户关注和粉丝的公开基本信息
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者:TM0831
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
python学习交流群点击即可加入,相关学习资料已经上传,可自行下载
此次爬虫要实现的是爬取某个微博用户的关注和粉丝的用户公开基本信息,包括用户昵称、id、性别、所在地和其粉丝数量,然后将爬取下来的数据保存在MongoDB数据库中,最后再生成几个图表来简单分析一下我们得到的数据。
具体步骤:
这里我们选取的爬取站点是https://m.weibo.cn,此站点是微博移动端的站点,我们可以直接查看某个用户的微博,比如https://m.weibo.cn/profile/5720474518。

然后查看其关注的用户,打开开发者工具,切换到XHR过滤器,一直下拉列表,就会看到有很多的Ajax请求。这些请求的类型是Get类型,返回结果是Json格式,展开之后就能看到有很多用户的信息。
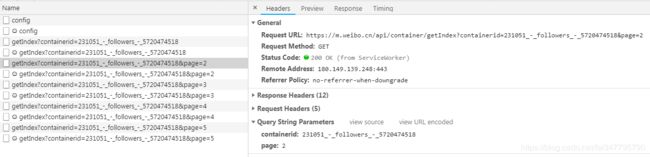
这些请求有两个参数,containerid和page,通过改变page的数值,我们就能得到更多的请求了。获取其粉丝的用户信息的步骤是一样的,除了请求的链接不同之外,参数也不同,修改一下就可以了。
由于这些请求返回的结果里只有用户的名称和id等信息,并没有包含用户的性别等基本资料,所以我们点进某个人的微博,然后查看其基本资料,比如这个,打开开发者工具,可以找到下面这个请求:

由于这个人的id是6857214856,因此我们可以发现当我们得到一个人的id的时候,就可以构造获取基本资料的链接和参数了,相关代码如下(uid就是用户的id):
1 uid_str = "230283" + str(uid)
2 url = "https://m.weibo.cn/api/container/getIndex?containerid={}_-_INFO&title=%E5%9F%BA%E6%9C%AC%E8%B5%84%E6%96%99&luicode=10000011&lfid={}&featurecode=10000326".format(uid_str, uid_str)
3 data = {
4 "containerid": "{}_-_INFO".format(uid_str),
5 "title": "基本资料",
6 "luicode": 10000011,
7 "lfid": int(uid_str),
8 "featurecode": 10000326
9 }
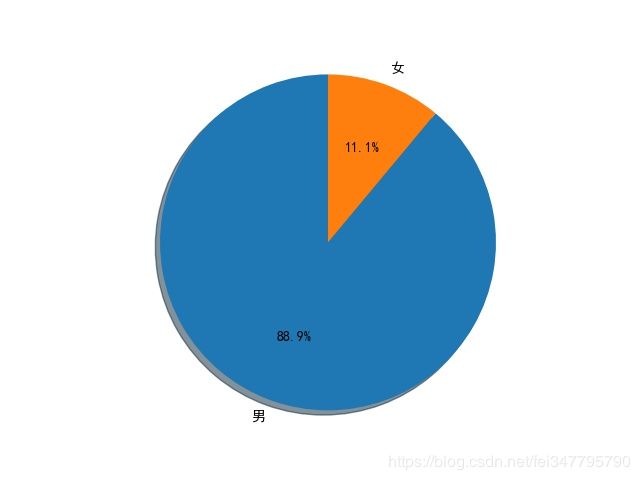
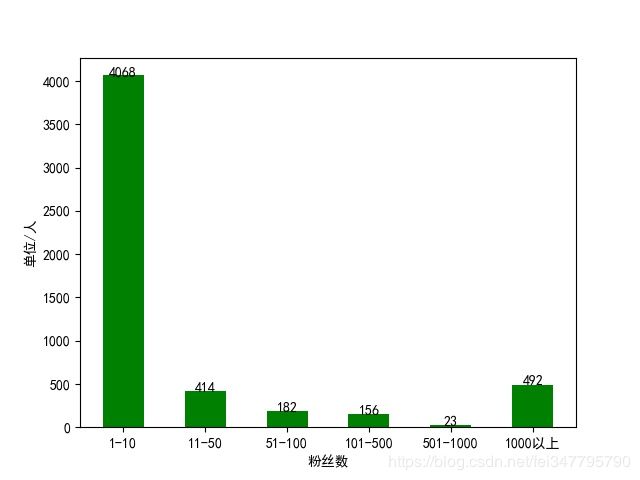
然后这个返回的结果也是Json格式,提取起来就很方便,因为很多人的基本资料都不怎么全,所以我提取了用户昵称、性别、所在地和其粉丝数量。而且因为一些账号并非个人账号,就没有性别信息,对于这些账号,我选择将其性别设置为男性。不过在爬取的时候,我发现一个问题,就是当页数超过250的时候,返回的结果就已经没有内容了,也就是说这个方法最多只能爬250页。对于爬取下来的用户信息,全都保存在MongoDB数据库中,然后在爬取结束之后,读取这些信息并绘制了几个图表,分别绘制了男女比例扇形图、用户所在地分布图和用户的粉丝数量柱状图。
主要代码:
由于第一页返回的结果和其他页返回的结果格式是不同的,所以要分别进行解析,而且因为部分结果的json格式不同,所以可能报错,因此采用了try…except…把出错原因打印出来。
爬取第一页并解析的代码如下:
1 def get_and_parse1(url):
2 res = requests.get(url)
3 cards = res.json()['data']['cards']
4 info_list = []
5 try:
6 for i in cards:
7 if "title" not in i:
8 for j in i['card_group'][1]['users']:
9 user_name = j['screen_name'] # 用户名
10 user_id = j['id'] # 用户id
11 fans_count = j['followers_count'] # 粉丝数量
12 sex, add = get_user_info(user_id)
13 info = {
14 "用户名": user_name,
15 "性别": sex,
16 "所在地": add,
17 "粉丝数": fans_count,
18 }
19 info_list.append(info)
20 else:
21 for j in i['card_group']:
22 user_name = j['user']['screen_name'] # 用户名
23 user_id = j['user']['id'] # 用户id
24 fans_count = j['user']['followers_count'] # 粉丝数量
25 sex, add = get_user_info(user_id)
26 info = {
27 "用户名": user_name,
28 "性别": sex,
29 "所在地": add,
30 "粉丝数": fans_count,
31 }
32 info_list.append(info)
33 if "followers" in url:
34 print("第1页关注信息爬取完毕...")
35 else:
36 print("第1页粉丝信息爬取完毕...")
37 save_info(info_list)
38 except Exception as e:
39 print(e)
爬取其他页并解析的代码如下:
1 def get_and_parse2(url, data):
2 res = requests.get(url, headers=get_random_ua(), data=data)
3 sleep(3)
4 info_list = []
5 try:
6 if 'cards' in res.json()['data']:
7 card_group = res.json()['data']['cards'][0]['card_group']
8 else:
9 card_group = res.json()['data']['cardlistInfo']['cards'][0]['card_group']
10 for card in card_group:
11 user_name = card['user']['screen_name'] # 用户名
12 user_id = card['user']['id'] # 用户id
13 fans_count = card['user']['followers_count'] # 粉丝数量
14 sex, add = get_user_info(user_id)
15 info = {
16 "用户名": user_name,
17 "性别": sex,
18 "所在地": add,
19 "粉丝数": fans_count,
20 }
21 info_list.append(info)
22 if "page" in data:
23 print("第{}页关注信息爬取完毕...".format(data['page']))
24 else:
25 print("第{}页粉丝信息爬取完毕...".format(data['since_id']))
26 save_info(info_list)
27 except Exception as e:
28 print(e)
运行结果:
在运行的时候可能会出现各种各样的错误,有的时候返回结果为空,有的时候解析出错,不过还是能成功爬取大部分数据的,这里就放一下最后生成的三张图片吧。

完整代码
login.py
import requests
import time
import json
import base64
import rsa
import binascii
class WeiBoLogin:
def __init__(self, username, password):
self.username = username
self.password = password
self.session = requests.session()
self.cookie_file = "Cookie.json"
self.nonce, self.pubkey, self.rsakv = "", "", ""
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36'}
def save_cookie(self, cookie):
"""
保存Cookie
:param cookie: Cookie值
:return:
"""
with open(self.cookie_file, 'w') as f:
json.dump(requests.utils.dict_from_cookiejar(cookie), f)
def load_cookie(self):
"""
导出Cookie
:return: Cookie
"""
with open(self.cookie_file, 'r') as f:
cookie = requests.utils.cookiejar_from_dict(json.load(f))
return cookie
def pre_login(self):
"""
预登录,获取nonce, pubkey, rsakv字段的值
:return:
"""
url = 'https://login.sina.com.cn/sso/prelogin.php?entry=weibo&su=&rsakt=mod&client=ssologin.js(v1.4.19)&_={}'.format(int(time.time() * 1000))
res = requests.get(url)
js = json.loads(res.text.replace("sinaSSOController.preloginCallBack(", "").rstrip(")"))
self.nonce, self.pubkey, self.rsakv = js["nonce"], js['pubkey'], js["rsakv"]
def sso_login(self, sp, su):
"""
发送加密后的用户名和密码
:param sp: 加密后的用户名
:param su: 加密后的密码
:return:
"""
data = {
'encoding': 'UTF-8',
'entry': 'weibo',
'from': '',
'gateway': '1',
'nonce': self.nonce,
'pagerefer': 'https://login.sina.com.cn/crossdomain2.php?action=logout&r=https%3A%2F%2Fweibo.com%2Flogout.php%3Fbackurl%3D%252F',
'prelt': '22',
'pwencode': 'rsa2',
'qrcode_flag': 'false',
'returntype': 'META',
'rsakv': self.rsakv,
'savestate': '7',
'servertime': int(time.time()),
'service': 'miniblog',
'sp': sp,
'sr': '1920*1080',
'su': su,
'url': 'https://weibo.com/ajaxlogin.php?framelogin=1&callback=parent.sinaSSOController.feedBackUrlCallBack',
'useticket': '1',
'vsnf': '1'}
url = 'https://login.sina.com.cn/sso/login.php?client=ssologin.js(v1.4.19)&_={}'.format(int(time.time() * 1000))
self.session.post(url, headers=self.headers, data=data)
def login(self):
"""
模拟登录主函数
:return:
"""
# Base64加密用户名
def encode_username(usr):
return base64.b64encode(usr.encode('utf-8'))[:-1]
# RSA加密密码
def encode_password(code_str):
pub_key = rsa.PublicKey(int(self.pubkey, 16), 65537)
crypto = rsa.encrypt(code_str.encode('utf8'), pub_key)
return binascii.b2a_hex(crypto) # 转换成16进制
# 获取nonce, pubkey, rsakv
self.pre_login()
# 加密用户名
su = encode_username(self.username)
# 加密密码
text = str(int(time.time())) + '\t' + str(self.nonce) + '\n' + str(self.password)
sp = encode_password(text)
# 发送参数,保存cookie
self.sso_login(sp, su)
self.save_cookie(self.session.cookies)
self.session.close()
def cookie_test(self):
"""
测试Cookie是否有效,这里url要替换成个人主页的url
:return:
"""
session = requests.session()
session.cookies = self.load_cookie()
url = ''
res = session.get(url, headers=self.headers)
print(res.text)
if __name__ == '__main__':
user_name = ''
pass_word = ''
wb = WeiBoLogin(user_name, pass_word)
wb.login()
wb.cookie_test()
test.py
import random
import pymongo
import requests
from time import sleep
import matplotlib.pyplot as plt
from multiprocessing import Pool
# 返回随机的User-Agent
def get_random_ua():
user_agent_list = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/"
"536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 "
"Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
return {
"User-Agent": random.choice(user_agent_list)
}
# 返回关注数和粉丝数
def get():
res = requests.get("https://m.weibo.cn/profile/info?uid=5720474518")
return res.json()['data']['user']['follow_count'], res.json()['data']['user']['followers_count']
# 获取内容并解析
def get_and_parse1(url):
res = requests.get(url)
cards = res.json()['data']['cards']
info_list = []
try:
for i in cards:
if "title" not in i:
for j in i['card_group'][1]['users']:
user_name = j['screen_name'] # 用户名
user_id = j['id'] # 用户id
fans_count = j['followers_count'] # 粉丝数量
sex, add = get_user_info(user_id)
info = {
"用户名": user_name,
"性别": sex,
"所在地": add,
"粉丝数": fans_count,
}
info_list.append(info)
else:
for j in i['card_group']:
user_name = j['user']['screen_name'] # 用户名
user_id = j['user']['id'] # 用户id
fans_count = j['user']['followers_count'] # 粉丝数量
sex, add = get_user_info(user_id)
info = {
"用户名": user_name,
"性别": sex,
"所在地": add,
"粉丝数": fans_count,
}
info_list.append(info)
if "followers" in url:
print("第1页关注信息爬取完毕...")
else:
print("第1页粉丝信息爬取完毕...")
save_info(info_list)
except Exception as e:
print(e)
# 爬取第一页的关注和粉丝信息
def get_first_page():
url1 = "https://m.weibo.cn/api/container/getIndex?containerid=231051_-_followers_-_5720474518" # 关注
url2 = "https://m.weibo.cn/api/container/getIndex?containerid=231051_-_fans_-_5720474518" # 粉丝
get_and_parse1(url1)
get_and_parse1(url2)
# 获取内容并解析
def get_and_parse2(url, data):
res = requests.get(url, headers=get_random_ua(), data=data)
sleep(3)
info_list = []
try:
if 'cards' in res.json()['data']:
card_group = res.json()['data']['cards'][0]['card_group']
else:
card_group = res.json()['data']['cardlistInfo']['cards'][0]['card_group']
for card in card_group:
user_name = card['user']['screen_name'] # 用户名
user_id = card['user']['id'] # 用户id
fans_count = card['user']['followers_count'] # 粉丝数量
sex, add = get_user_info(user_id)
info = {
"用户名": user_name,
"性别": sex,
"所在地": add,
"粉丝数": fans_count,
}
info_list.append(info)
if "page" in data:
print("第{}页关注信息爬取完毕...".format(data['page']))
else:
print("第{}页粉丝信息爬取完毕...".format(data['since_id']))
save_info(info_list)
except Exception as e:
print(e)
# 爬取关注的用户信息
def get_follow(num):
url1 = "https://m.weibo.cn/api/container/getIndex?containerid=231051_-_followers_-_5720474518&page={}".format(num)
data1 = {
"containerid": "231051_ - _followers_ - _5720474518",
"page": num
}
get_and_parse2(url1, data1)
# 爬取粉丝的用户信息
def get_followers(num):
url2 = "https://m.weibo.cn/api/container/getIndex?containerid=231051_-_fans_-_5720474518&since_id={}".format(num)
data2 = {
"containerid": "231051_-_fans_-_5720474518",
"since_id": num
}
get_and_parse2(url2, data2)
# 爬取用户的基本资料(性别和所在地)
def get_user_info(uid):
uid_str = "230283" + str(uid)
url2 = "https://m.weibo.cn/api/container/getIndex?containerid={}_-_INFO&title=%E5%9F%BA%E6%9C%AC%E8%B5%84%E6%96%99&luicode=10000011&lfid={}&featurecode=10000326".format(
uid_str, uid_str)
data2 = {
"containerid": "{}_-_INFO".format(uid_str),
"title": "基本资料",
"luicode": 10000011,
"lfid": int(uid_str),
"featurecode": 10000326
}
res2 = requests.get(url2, headers=get_random_ua(), data=data2)
data = res2.json()['data']['cards'][1]
if data['card_group'][0]['desc'] == '个人信息':
sex = data['card_group'][1]['item_content']
add = data['card_group'][2]['item_content']
else: # 对于企业信息,返回性别为男
sex = "男"
add = data['card_group'][1]['item_content']
# 对于所在地有省市的情况,把省份取出来
if ' ' in add:
add = add.split(' ')[0]
return sex, add
# 把数据保存到MongoDB数据库中
def save_info(data):
conn = pymongo.MongoClient(host="127.0.0.1", port=27017)
db = conn["Spider"]
db.WeiBoUsers.insert(data)
# 绘制男女比例扇形图
def plot_sex():
conn = pymongo.MongoClient(host="127.0.0.1", port=27017)
col = conn['Spider'].WeiBoUsers
sex_data = []
for i in col.find({}, {"性别": 1}):
sex_data.append(i['性别'])
labels = '男', '女'
sizes = [sex_data.count('男'), sex_data.count('女')]
# 设置分离的距离,0表示不分离
explode = (0, 0)
plt.pie(sizes, explode=explode, labels=labels, autopct='%1.1f%%', shadow=True, startangle=90)
# 保证画出的是圆形
plt.axis('equal')
# 保证能够显示中文
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.savefig("sex.jpg")
print("已保存为sex.jpg!")
# 绘制用户所在地条形图
def plot_province():
conn = pymongo.MongoClient(host="127.0.0.1", port=27017)
col = conn['Spider'].WeiBoUsers
province_list = ['北京', '天津', '河北', '山西', '内蒙古', '辽宁', '吉林', '黑龙江', '上海', '江苏', '浙江', '安徽',
'福建', '江西', '山东', '河南', '湖北', '湖南', '广东', '广西', '海南', '重庆', '四川', '贵州',
'云南', '陕西', '甘肃', '青海', '宁夏', '新疆', '西藏', '台湾', '香港', '澳门', '其他', '海外']
people_data = [0 for _ in range(36)]
for i in col.find({}, {"所在地": 1}):
people_data[province_list.index(i['所在地'])] += 1
# 清洗掉人数为0的数据
index_list = [i for i in range(len(people_data)) if people_data[i] == 0]
j = 0
for i in range(len(index_list)):
province_list.remove(province_list[index_list[i] - j])
people_data.remove(people_data[index_list[i] - j])
j += 1
# 排序
for i in range(len(people_data)):
for j in range(len(people_data) - i - 1):
if people_data[j] > people_data[j + 1]:
people_data[j], people_data[j + 1] = people_data[j + 1], people_data[j]
province_list[j], province_list[j + 1] = province_list[j + 1], province_list[j]
province_list = province_list[:-1]
people_data = people_data[:-1]
# 图像绘制
fig, ax = plt.subplots()
b = ax.barh(range(len(province_list)), people_data, color='blue', height=0.8)
# 添加数据标签
for rect in b:
w = rect.get_width()
ax.text(w, rect.get_y() + rect.get_height() / 2, '%d' % int(w), ha='left', va='center')
# 设置Y轴刻度线标签
ax.set_yticks(range(len(province_list)))
ax.set_yticklabels(province_list)
plt.xlabel("单位/人")
plt.ylabel("所在地")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.savefig("province.jpg")
print("已保存为province.jpg!")
# 绘制用户粉丝数量柱状图
def plot_fans():
conn = pymongo.MongoClient(host="127.0.0.1", port=27017)
col = conn['Spider'].WeiBoUsers
fans_list = ["1-10", "11-50", "51-100", "101-500", "501-1000", "1000以上"]
fans_data = [0 for _ in range(6)]
for i in col.find({}, {"粉丝数": 1}):
fans_data[0] += 1 if 1 <= i["粉丝数"] <= 10 else 0
fans_data[1] += 1 if 11 <= i["粉丝数"] <= 50 else 0
fans_data[2] += 1 if 51 <= i["粉丝数"] <= 100 else 0
fans_data[3] += 1 if 101 <= i["粉丝数"] <= 500 else 0
fans_data[4] += 1 if 501 <= i["粉丝数"] <= 1000 else 0
fans_data[5] += 1 if 1001 <= i["粉丝数"] else 0
# print(fans_data)
# 绘制柱状图
plt.bar(x=fans_list, height=fans_data, color="green", width=0.5)
# 显示柱状图形的值
for x, y in zip(fans_list, fans_data):
plt.text(x, y + sum(fans_data) // 50, "%d" % y, ha="center", va="top")
plt.xlabel("粉丝数")
plt.ylabel("单位/人")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.savefig("fans.jpg")
print("已保存为fans.jpg!")
if __name__ == '__main__':
follow_count, followers_count = get()
get_first_page()
# 由于当page或者since_id大于250时就已经无法得到内容了,所以要设置最大页数为250
max_page1 = follow_count // 20 + 1 if follow_count < 5000 else 250
max_page2 = followers_count // 20 + 1 if followers_count < 5000 else 250
# 使用进程池加快爬虫的效率
pool = Pool(processes=4)
# 爬取关注的用户信息
start1, end1 = 2, 12
for i in range(25):
pool.map(get_follow, range(start1, end1))
# 超过max_page则跳出循环
if end1 < max_page1:
start1 = end1
end1 = start1 + 10
sleep(5)
else:
break
# 爬取粉丝的用户信息
start2, end2 = 2, 50
for i in range(5):
pool.map(get_followers, range(start2, end2))
# 超过max_page则跳出循环
if end2 < max_page2:
start2 = end2
end2 = start2 + 50
sleep(10)
else:
break
# 可视化成图表
plot_sex()
plot_province()
plot_fans()