TensorFlow2数据加载与数据集
加载数据集
keras 加载在线数据集
tf.keras.datasets提供了加载在线数据集的API,其中可加载的数据集包括:
boston_housing module: Boston housing price regression dataset.
cifar10 module: CIFAR10 small images classification dataset.
cifar100 module: CIFAR100 small images classification dataset.
fashion_mnist module: Fashion-MNIST dataset.
imdb module: IMDB sentiment classification dataset.
mnist module: MNIST handwritten digits dataset.
reuters module: Reuters topic classification dataset.
以加载mnist 手写数字为例,加载方法为:
import tensorflow as tf
(x_train, y_train), (x_test, y_test)=tf.keras.datasets.mnist.load_data()
其中,load_data()方法:
tf.keras.datasets.mnist.load_data(
path='mnist.npz'
)
path指定将数据缓存与何处(相对于 用户根目/.keras/datasets)
该方法会返回一个Numpy arrays元组: (x_train, y_train), (x_test, y_test).
MNIST数据集介绍
该数据集包含60,000个用于训练的示例和10,000个用于测试的示例。这些数字已经过尺寸标准化并位于图像中心,图像是固定大小(28x28像素),训练数据的值为0到255,训练标签的值为0到9
print(x_train.shape,y_train.shape) #(60000, 28, 28) (60000,)
print(x_test.shape,y_test.shape) #(10000, 28, 28) (10000,)
print(x_train.min(),x_train.max()) #0 255
print(y_train.min(),y_train.max()) #0 9
tf.data流水线读取数据集
tf.data需要将内存或者硬盘中数据,读取为Dataset对象才能进行流水线操作,Dataset是一个可包含任何数据类型的结构,它是可嵌套的,即它的元素可为Dataset类型。它是迭代的,可以通过for循环读取其中的每一个元素,也可以迭代器iter()对其进行迭代。将keras 加载在线数据集转化为Dataset后,可以更加便利的对数据进行处理与训练。
加载 NumPy 数据
如果训练数据已经存于内存中,可以使用tf.data.Dataset.from_tensors() 或tf.data.Dataset.from_tensor_slices(),将内存中的数据转化为Dataset。
tf.data.Dataset.from_tensors()与tf.data.Dataset.from_tensor_slices()的参数与返回值相同,张量的元组并返回Dataset,但是tf.data.Dataset.from_tensor_slices()会对元组进行zip(),即,如果如果张量X内储存有每一批特征向量,张量y内是每一批特征向量对应的标签值,tf.data.Dataset.from_tensor_slices(X,y)返回的Dataset中,储存的是从X 和y对应位置取出的元素组成的"特征-标签"对: ((X[0],y[0]),(X[1],y[1])...)
同样的,如果给tf.data.Dataset.from_tensor_slices()的参数是“特征-标签”对:((X[0],y[0]),(X[1],y[1])...),则其返回的Dataset中储存的为((X[0],X[1],...),(y[0],y[1]...)),即返回(多批特征向量,多批标签)
而tf.data.Dataset.from_tensors()则是给啥就包含啥,tf.data.Dataset.from_tensors(X,y)返回的Dataset中,储存的是((X,y))
例如:
features = tf.constant([[1, 3], [2, 1], [3, 3]])
labels = tf.constant(['A', 'B', 'A'])
dataset1 = tf.data.Dataset.from_tensor_slices((features,labels))
print("sample1")
for sample in dataset1:
print(sample)
print("\nsample2")
dataset2 = tf.data.Dataset.from_tensors((features,labels))
for sample in dataset2:
print(sample)
输出:
sample1
(, )
(, )
(, )
sample2
(, )
在调用模型训练方法model.fit()时,其参数要求为``model.fit(x,y,batch_size,epochs)`,
若参数x被指定为Dataset对象,则参数y和batch_size不应该被填写,此时要求Dataset中储存的元素为批数据(),其中每一批的元素要求为(特征,标签)元组。
故我们更期望Dataset中储存(特征,标签)结构的数据。此时就可以灵活的使用tf.data.Dataset.from_tensors()与tf.data.Dataset.from_tensor_slices()方法了,如果内存中的是”特征-标签“对,则使用tf.data.Dataset.from_tensors()加载,内存中储存的是(多批特征向量,多批标签)则使用tf.data.Dataset.from_tensor_slices()加载
从线上加载MNIST并训练
import tensorflow as tf
(x_train, y_train), (x_test, y_test)=tf.keras.datasets.mnist.load_data()
train_dataset = tf.data.Dataset.from_tensor_slices((x_train,y_train)).batch(64)
test_dataset = tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(64)
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer=tf.keras.optimizers.RMSprop(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()])
model.fit(train_dataset, epochs=10)
model.evaluate(test_dataset)
加载 CSV 数据
可使用pandas将数据CSV加载入内存
import pandas as pd
df = pd.read_csv(csv_file)
再使用tf.data.Dataset.from_tensor_slices 将数据从内存中转化为Dataset对象实例
转化前,应先将标签分离,在按(特征,标签)这种形式,将参数传入:
target = df.pop('target')
dataset = tf.data.Dataset.from_tensor_slices((df.values, target.values))
也可以将pandas的数据之间转化为张量
tf.constant(df['thal'])
加载分布在文件中的图片
以flower_photos数据为例,下面的代码将下载该数据:
import tensorflow as tf
import pathlib
data_root_orig = tf.keras.utils.get_file(origin='https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz',
fname='flower_photos', untar=True)
data_root = pathlib.Path(data_root_orig)
print(data_root)
通过输出的data_root浏览该数据
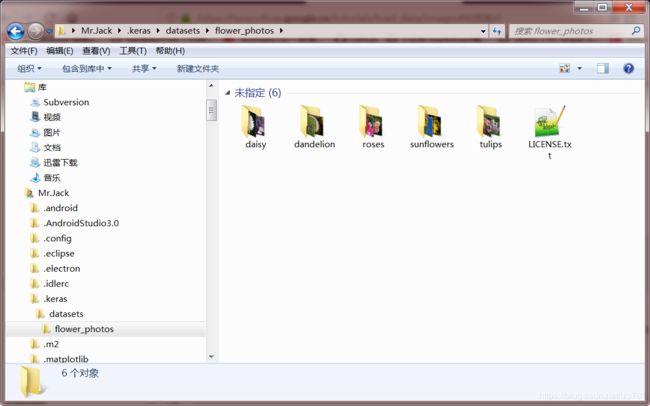
可见图片存储于每个文件夹中,文件夹的名称为数据的标签
建立图片路径列表和标签列表:
all_image_paths = list(data_root.glob('*/*'))
all_image_paths = [str(path) for path in all_image_paths]
print(all_image_paths[:10])
label_names = sorted(item.name for item in data_root.glob('*/') if item.is_dir())
print(label_names[:4])
将标签转化为离散的数字,并与图片路径相关联:
- 建立(标签:索引)字典
- 遍历
all_image_paths根据其父文件夹名,建立元素为标签索引的列表,命名为all_image_labels
label_to_index = dict((name, index) for index, name in enumerate(label_names))
all_image_labels = [label_to_index[pathlib.Path(path).parent.name]
for path in all_image_paths]
将文件夹内一个的图片加载进内存,并转化为张量:
img_raw = tf.io.read_file(all_image_paths[0])
img_tensor = tf.image.decode_image(img_raw)
print(img_tensor.shape)
print(img_tensor.dtype)
同时,加载入内存的图片,需要根据模型调整大小并标准化:
img_final = tf.image.resize(img_tensor, [192, 192])
img_final = img_final/255.0
上述过程可封装在函数内,以便日后再次使用:
def preprocess_image(image):
image = tf.image.decode_jpeg(image, channels=3)
image = tf.image.resize(image, [192, 192])
image /= 255.0 # normalize to [0,1] range
return image
def load_and_preprocess_image(path):
image = tf.io.read_file(path)
return preprocess_image(image)
为验证加载是否成功,可以通过matplotlib.pyplot查看第一张图片的图像和标签:
import matplotlib.pyplot as plt
image_path = all_image_paths[0]
label = all_image_labels[0]
plt.imshow(load_and_preprocess_image(image_path))
plt.grid(False)
plt.title(label_names[label].title())
plt.show()
为了把图片数据加载为dataset,可行的方案之一是:
- 通过
Dataset.from_tensor_slices构建(图片路径,标签)对数据集 - 通过
map()方法,将从路径列表中的路径加载每一张图片,构建(图片,标签)对数据集
ds = tf.data.Dataset.from_tensor_slices((all_image_paths, all_image_labels))
def load_and_preprocess_from_path_label(path, label):
return load_and_preprocess_image(path), label
image_label_ds = ds.map(load_and_preprocess_from_path_label)
image_label_ds可直接用于模型的训练。
更多
https://tensorflow.google.cn/tutorials/load_data/images
对数据集的操作
数据分批
最简单的数据分批方案,就是将n个连续的元素堆叠成一组元素,即成一批。Dataset.batch()方法正是实现这种方案的一个工具,这种操作要求Dataset内元素shape相同:
batch(
batch_size, drop_remainder=False
)
参数:
batch_size: 一个整型标量,代表多少个连续元素将会组成一批drop_remainder: 一个可选参数,代表是否会把最后构不成一批的数据丢弃掉,默认是不丢弃
返回值:
- 返回一个新的
Dataset实例,实例的内的数据是分好批的。
例:
dataset = tf.data.Dataset.range(8)
dataset = dataset.batch(3)
print(dataset) #([0,1,2],[3,4,5],[6,7])
若Dataset内元素shape各异,此时如若分批,则需要将其填充(pad)到一个统一的shape,此时可以调用Dataset.padded_batch 方法,完成该操作:
padded_batch(
batch_size, padded_shapes, padding_values=None, drop_remainder=False
)
参数:
batch_size: 整型标量,同batch方法,表示将多少连续的元素分为一批。padded_shapes:shape类型,如果指定了一个明确的shape,则所有批会被填充至该shape,如果为none或者-1,则默认每一批都数据都填充至该批数据内的最大shapepadding_values: 可选参数,指定填充值,默认为0drop_remainder: 可选参数,布尔型,同batch方法,是否丢弃最后凑不够一批的数据,默认不丢弃。
返回值:
- 返回一个新的
Dataset实例,实例的内的数据是分好批的。
注意:分批操作并非是给Dataset内的元素增加了一个维度,而是将Dataset内多个元素堆叠成一个元素,分批后Dataset.map(f)方法将是对数据集内每一批数据执行函数f.
随机打乱
Dataset.shuffle() 方法通过维持一个固定的缓存区,并随机地从这个缓冲区选择元素的办法来打乱数据集中元素的顺序,具有而言就是,如果dataset内包含10,000个元素,调用``dataset=dataset.suffle(1000),在选择新返回的新dataset中的第一个元素时,会只从原dataset的前1000个元素随机原则。一旦一个元素被选择,这个元素空出来的空缺会被下一个元素(比如原dataset`的第1001个元素)填不上,以此来保障缓冲区内元素始终为1000个。
所以如果dataset内元素值按顺序为1,2,…,n,对dataset执行:
dataset = dataset.shuffle(buffer_size=100).batch(20)
则新的dataset内第一批元素不会超过120
shuffle(
buffer_size, seed=None, reshuffle_each_iteration=None
)
参数:
buffer_size: 一个整型标量,代表缓冲区的大小。seed: 可选参数,随机种子,一个整型标量。reshuffle_each_iteration:可选参数,布尔型,如果为true则表示该数据集将会在每次迭代结束时进行伪随机。
tf.data.Dataset.repeat()
重复其所在的数据集实例,使该实例能被查看count次
repeat(
count=None
)
参数:
count:可选,整型,代表重复次数(即返回的数据集是**count**个新数据集的拼接),默认是重复无限次。
返回:
Dataset: 一个新的数据集
tf.data.Dataset.take()
创建一个数据集,新数据集最多包含被修饰的数据集count个元素(其实就是返回前count个元素)
take(
count
)
参数:
count: 整型,代表返回的数据集所包含的最大元素数,如果被指定-1则是包含整个数据集
返回:
Dataset:一个新的数据集
tf.data.Dataset.skip()
创建一个数据集,新数据是被修饰的数据集跳过了前count个元素得到的
skip(
count
)
参数:
count: 整型,如果是-1,则跳过整个数据集。
返回:
Dataset: 一个新数据集
tf.data.Dataset.zip()
可以对一组数据集(大于等于两个)进行操作,将它们像zip()函数一样构建在一起,返回一个新的数据,新数据包含多个元组,每个元组都各从参数中的数据集取一个元素构成。
@staticmethod
zip(
datasets
)
参数
datasets: 数据集元组
返回
Dataset: 一个数据集
tf.data.Dataset.flat_map()
flat_map(
map_func
)
参数:
- map_func : 与
map()相同,对数据集内每一个元素的处理函数,要求返回数据集类型
返回:
- 一个数据集对象
Dataset.flat_map(f) 方法与Dataset.map(f)方法相同,会对数据集内的每一个元素应用函数f,flat_map的f要求返回Dataset对象,且flat_map()方法会把函数f返回的数据集拼接成一个新的数据集:
dataset = Dataset.from_tensor_slices([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
dataset = dataset.flat_map(lambda x: Dataset.from_tensor_slices(x))
for i in dataset:
print(i)
输出:
tf.Tensor(1, shape=(), dtype=int32)
tf.Tensor(2, shape=(), dtype=int32)
tf.Tensor(3, shape=(), dtype=int32)
tf.Tensor(4, shape=(), dtype=int32)
tf.Tensor(5, shape=(), dtype=int32)
tf.Tensor(6, shape=(), dtype=int32)
tf.Tensor(7, shape=(), dtype=int32)
tf.Tensor(8, shape=(), dtype=int32)
tf.Tensor(9, shape=(), dtype=int32)
数据预处理
Dataset.map(f)
大多数数据预处理的操作,需要应用到数据集中的每一个元素内,如标准化操作。不同的数据处理方法对应的代码自然不同,TensorFlow提供了Dataset.map(f) 方法,会将函数f作用于dataset中的每一个元素 , 并返回一个新的数据集 . 函数f的输入参数为tf.Tensor类型 , 代表dataset中的每一个元素 , 函数f返回一个tf.Tensor类型数据 , 代表新数据集中的一个元素 , 这样开发人员就可以通过在函数f内设计张量操作实现对数据集中的每一个元素进行处理了 .
map(
map_func, num_parallel_calls=None
)
参数 :
map_func: 对每个元素调用的函数 , 要求有参数和返回值 .num_parallel_calls:可选参数 , 整型 , 代表同一时间处理数据的个数 , 默认是连续处理数据 , 即一个接一个的 .如果此处传入参数为tf.data.experimental.AUTOTUNE则表示平行处理的数据数目将依据CPU动态设置。
在加载图片数据时,map()函数就起到了一个重要的作用:依据路径加载图片并预处理
ds = tf.data.Dataset.from_tensor_slices((all_image_paths, all_image_labels))
def load_and_preprocess_from_path_label(path, label):
return load_and_preprocess_image(path), label
image_label_ds = ds.map(load_and_preprocess_from_path_label)
此时对于load_and_preprocess_from_path_label()函数来说,它被输入的是(图片路径,标签)元组,load_and_preprocess_from_path_label()函数接受它并返回(图片,标签)元组,
map()方法将load_and_preprocess_from_path_label()的返回值构建成新的dataset。
时间序列窗口
时间序列数据需要保障时间轴的完整,下面将用Dataset.range 进行演示:
range_ds = tf.data.Dataset.range(100000)
使用简单分批
通常基于这类数据的模型将会期望一个时间连续的切片,最简单的方法就是直接对其进行分批:
batches = range_ds.batch(10, drop_remainder=True)
for batch in batches.take(5):
print(batch.numpy())
输出:
[0 1 2 3 4 5 6 7 8 9]
[10 11 12 13 14 15 16 17 18 19]
[20 21 22 23 24 25 26 27 28 29]
[30 31 32 33 34 35 36 37 38 39]
[40 41 42 43 44 45 46 47 48 49]
如果想通过稠密预测( dense predictions )预测之后的一个时间步,可能需要通过平移来关联特征与标签,如[0 1 2 3 4 5 6 7 8] => [1 2 3 4 5 6 7 8 9],可以通过Datase.map()方法实现这个需求:
def dense_1_step(batch):
#将每一批的前n-1个元素作为特征,后n-1个元素作为标签
return batch[:-1], batch[1:]
predict_dense_1_step = batches.map(dense_1_step)
如果要预测整个窗口而非固定偏移,可以将每一批分成不重叠的两部分,前一部分作为特征,后一部分作为标签如:[0 1 2 3 4 5 6 7 8 9] => [10 11 12 13 14]
此时map_func应该这样设计:
def label_next_5_steps(batch):
return (batch[:-5], # Take the first 5 steps
batch[-5:]) # take the remainder
# 假设batches = range_ds.batch(15, drop_remainder=True)
predict_5_steps = batches.map(label_next_5_steps)
如果需要一批的标签与另一批的特征有些重叠,如:
[0 1 2 3 4 5 6 7 8 9] => [10 11 12 13 14]
[10 11 12 13 14 15 16 17 18 19] => [20 21 22 23 24]
可以借助Dataset.zip 方法:
features = range_ds.batch(10, drop_remainder=True)
labels = range_ds.batch(10).skip(1) #忽略第一批
labels = labels.map(lambda labels: labels[:-5])
predict_5_steps = tf.data.Dataset.zip((features, labels))
使用Dataset.window()
Dataset.window()方法给开发人员提供了对时序窗口的平移、取样步长的控制,但是有一点需要注意,该方法会把每个窗口的数据当做一个数据集,并把这些数据集再包裹在一个数据内,若依该方法返回的是数据集的数据集(Dataset of Datasets)
Dataset.window :
window(
size, shift=None, stride=1, drop_remainder=False
)
参数:
size: 整型标量,代表窗口大小,具体来说是一个窗口内包含几个元素shift:可选参数,默认和窗口大小相同,表示一个窗口由前几一个窗口向前平移几个元素得到stride: 可选,默认是1,表示一个窗口中的数据采样步长是多少drop_remainder: 可选,默认为False 当最后一部分元素不满足窗口大小时,是否丢弃
返回值:
- 一个数据集,数据集内的元素是也是数据集类型,每个元素都是包裹着一个窗口数据的数据集
例如:
dataset = tf.data.Dataset.range(7).window(3, 1, 2, True)
for window in dataset:
print(list(window.as_numpy_iterator()))
""""
输出:
[0, 2, 4]
[1, 3, 5]
[2, 4, 6]
""""
注意window()方法的返回值,是数据集的数据集:
windows = range_ds.window(5, shift=1)
for sub_ds in windows.take(5):
print(sub_ds)
输出:
<_VariantDataset shapes: (), types: tf.int64>
<_VariantDataset shapes: (), types: tf.int64>
<_VariantDataset shapes: (), types: tf.int64>
<_VariantDataset shapes: (), types: tf.int64>
<_VariantDataset shapes: (), types: tf.int64>
Dataset.flat_map(f) 方法与Dataset.map(f)方法相同,会对数据集内的每一个元素应用函数f,flat_map的f要求返回Dataset对象,且flat_map()方法会把函数f返回的数据集拼接成一个新的数据集。
所以Dataset.flat_map(f) 方法可以用于处理Dataset.window()方法的返回值,将其摊平为一个数据集。
windows.flat_map(lambda x: x)
此后所有窗口的元素都被摊平为数据集的元素,但是这也并非最终目的,我们希望每一个窗口作为一批,所以摊平后接分批操作,批大小即为窗口大小。
总结上述所有操作,完整代码如下:
import tensorflow as tf
range_ds = tf.data.Dataset.range(100000)
window_size=5
windows = range_ds.window(window_size, shift=1).flat_map(lambda x: x)
ds=windows.batch(window_size, drop_remainder=True)
for batch in ds.take(5):
print(batch.numpy())
输出:
[0 1 2 3 4]
[1 2 3 4 5]
[2 3 4 5 6]
[3 4 5 6 7]
[4 5 6 7 8]
这样处理得到的数据与用batch()方法得到的数据结构相同,所以可以用同样的方法提取标签:
- 紧接上述代码引入
dense_1_step()函数 - 同
map()方法对每批数据进行特征与标签的分离
def dense_1_step(batch):
#将每一批的前n-1个元素作为特征,后n-1个元素作为标签
return batch[:-1], batch[1:]
dense_labels_ds = ds.map(dense_1_step)
for inputs,labels in dense_labels_ds.take(3):
print(inputs.numpy(), "=>", labels.numpy())
输出:
[0 1 2 3] => [1 2 3 4]
[1 2 3 4] => [2 3 4 5]
[2 3 4 5] => [3 4 5 6]
tf.data的并行化策略
tf.data.Dataset.prefetch()
数据集应该在训练前执行dataset = dataset.prefetch(buffer_size),这将允许该数据集在在训练的同时,并行地获取数据。
prefetch(
buffer_size
)
buffer_size: 一个整型标量,表示数据在预选载入时的最大缓存数,可设置为tf.data.experimental.AUTOTUNE,交由框架自动给定。
使用num_parallel_calls参数
tf.data.Dataset.interleave 和tf.data.Dataset.map 都设置有num_parallel_calls参数,该参数表示并行处理数据的个数,可设置为tf.data.experimental.AUTOTUNE,交由框架自动给定。
tf.data缓存
tf.data.Dataset.cache 可以在内存或者本地储存中缓存一个数据集,这对每一个epoch来说,将节约很多操作(如文件打开,数据读取)
当开发人员缓存一个数据时,在缓存操作之前的一个操作(he transformations before the cache one )将只会在第一个epoch执行,在之后的epoch将会使用缓存的数据
如果传递给map转换的用户定义函数开销很大,只要得到的数据集仍然适合内存或本地存储,就可以在map转换之后应用cache转换。如果用户定义的函数增加了存储数据集所需的空间,超出了缓存容量,那么可以在cache转换之后应用map,或者考虑在训练之前对数据进行预处理,以减少资源使用。
建议在map转换之后缓存数据集,除非该转换使数据太大而无法装入内存。如果您的map_func 函数可以分成两个部分:时间消耗的部分和内存消耗的部分,那么就可以进行权衡。在这种情况下,您可以像下面这样操作:
dataset.map(time_consuming_mapping).cache().map(memory_consuming_mapping)
这样,时间消耗的部分只在第一个epoch中执行,并且避免使用太多的缓存空间。
本文摘录、翻译自
Keras中文文档
https://keras.io/zh/
TensorFlow官方
https://tensorflow.google.cn/
最全Tensorflow2.0 入门教程持续更新
https://zhuanlan.zhihu.com/p/59507137
简单粗暴TensorFlow2
这对每一个epoch来说,将节约很多操作(如文件打开,数据读取)
当开发人员缓存一个数据时,在缓存操作之前的一个操作(he transformations before the cache one )将只会在第一个epoch执行,在之后的epoch将会使用缓存的数据
如果传递给map转换的用户定义函数开销很大,只要得到的数据集仍然适合内存或本地存储,就可以在map转换之后应用cache转换。如果用户定义的函数增加了存储数据集所需的空间,超出了缓存容量,那么可以在cache转换之后应用map,或者考虑在训练之前对数据进行预处理,以减少资源使用。
建议在map转换之后缓存数据集,除非该转换使数据太大而无法装入内存。如果您的map_func 函数可以分成两个部分:时间消耗的部分和内存消耗的部分,那么就可以进行权衡。在这种情况下,您可以像下面这样操作:
dataset.map(time_consuming_mapping).cache().map(memory_consuming_mapping)
这样,时间消耗的部分只在第一个epoch中执行,并且避免使用太多的缓存空间。
本文摘录、翻译自
Keras中文文档
https://keras.io/zh/
TensorFlow官方
https://tensorflow.google.cn/
最全Tensorflow2.0 入门教程持续更新
https://zhuanlan.zhihu.com/p/59507137
简单粗暴TensorFlow2
https://tf.wiki/zh/preface.html