本章内容
1、rawlog处理
2、域名item接口刷新
3、备案结果查询
4、多级域名中取主域
5、发送邮件
6、通过api获取cdn edge ip
7、多线程下载
1、rawlog处理
脚本里面涉及的内容
1、使用多cpu处理
2、UTC与GMT-8时间的转换
3、一个目录下对子目录的文件遍历
 下面有多个panther-*目录
下面有多个panther-*目录
4、gzip文件的读取处理
Parsing Per-Hit (PerHit) Log using Python3 (incl. Multi-Thread version)


#!/usr/bin/env python3 # coding: utf-8 import os import sys import traceback import re import gzip from datetime import datetime from dateutil import tz base_path = "/home/xuanjia/static.trthi.com" file_name_prefix = "F114BC2216604A2C93AF5F6821168CA5_" file_name_sufix = "_pca_cn_cas_001.log" def conv_date(input_date, input_hour): local_date = datetime.strptime(input_date + " " + input_hour, "%Y%m%d %H").replace(tzinfo=tz.gettz('UTC')).astimezone(tz.gettz('Asia/Shanghai')) re_date = [] re_date.append(local_date.strftime("%Y%m%d")) re_date.append(local_date.strftime("%H")) return re_date def main(): global base_path global file_name_prefix global file_name_sufix array_subdirs = [] array_hours = [] array_subdirs = os.listdir(base_path) for i in range(0, 24, 1): array_hours.append('{0:02}'.format(i)) for hour in array_hours: for subdir in array_subdirs: f_name = conv_date(subdir, hour) print(f_name) with open(base_path + "/" + file_name_prefix + f_name[0] + "_" + f_name[1] + file_name_sufix, 'w') as output_f: # output_lines = [] for root, dirs, files in os.walk(base_path + "/" + subdir): for file_name in files: if re.search(".*_upstream_.*", file_name) is None and re.search(".*_" + subdir + "_" + hour + "_.*", file_name) is not None: try: with gzip.open(os.path.join(root + "/" + file_name), 'rt', encoding='utf-8') as input_f: for input_line in input_f: array_line = input_line.split(' ') dict_line = {} dict_line["Event-Type"] = array_line[0] dict_line["Site-ID"] = array_line[1] dict_line["Date"] = array_line[2] dict_line["Time"] = array_line[3] dict_line["C-IP"] = array_line[4] dict_line["CS-UserName"] = array_line[5] dict_line["S-SiteName"] = array_line[6] dict_line["S-ComputerName"] = array_line[7] dict_line["S-IP"] = array_line[8] dict_line["S-Port"] = array_line[9] dict_line["CS-Method"] = array_line[10] dict_line["CS-URI"] = array_line[11] dict_line["CS-URI-Query"] = array_line[12] dict_line["SC-Status"] = array_line[13] dict_line["SC-Win32-Status"] = array_line[14] dict_line["SC-Bytes"] = array_line[15] dict_line["CS-Bytes"] = array_line[16] dict_line["Time-Taken"] = array_line[17] dict_line["CS-Version"] = array_line[18] dict_line["CS-Host"] = array_line[19] dict_line["CS-UserAgent"] = array_line[20] dict_line["CS-Cookie"] = array_line[21] dict_line["CS-Referer"] = array_line[22] dict_line["SC-Sub-Status"] = array_line[23] dict_line["CS-Range"] = array_line[24] dict_line["SC-Initial"] = array_line[25] dict_line["SC-Complete"] = array_line[26] dict_line["SC-ContentType"] = array_line[27] dict_line["Protocol"] = array_line[28] dict_line["SC-Bytes-Body"] = array_line[29] dict_line["Bytes-Origin-Uncompressed"] = array_line[30] dict_line["C-RemotePort"] = array_line[31] # print(dict_line) array_output = [] array_output.append(dict_line["C-IP"]) array_output.append("-") array_output.append("-") array_output.append("[" + datetime.strptime(dict_line["Date"] + " " + dict_line["Time"], "%Y-%m-%d %H:%M:%S").replace(tzinfo=tz.gettz('UTC')).astimezone(tz.gettz('Asia/Shanghai')).strftime("%d/%b/%Y:%H:%M:%S +08:00") + "]") array_output.append("\"" + dict_line["CS-Method"]) array_output.append("http://" + dict_line["CS-Host"] + dict_line["CS-URI"] + "?" + dict_line["CS-URI-Query"]) array_output.append(dict_line["CS-Version"] + "\"") array_output.append(dict_line["SC-Status"]) array_output.append(dict_line["SC-Bytes"]) array_output.append("\"" + dict_line["CS-Referer"] + "\"") array_output.append("\"" + dict_line["CS-UserAgent"] + "\"") array_output.append("\"-\"") array_output.append(dict_line["S-IP"]) # print(" ".join(array_output)) # output_lines.append(" ".join(array_output)) output_f.write(" ".join(array_output) + '\n') except Exception as e: traceback.print_exc(file=sys.stdout) print(root + "/" + file_name) continue exit() if __name__ == '__main__': main()
#!/usr/bin/env python3 # coding: utf-8 import os import sys import traceback import re import gzip import time import multiprocessing from datetime import datetime from dateutil import tz from multiprocessing import Pool base_path = "/home/xuanjia/static.trthi.com" file_name_prefix = "F114BC2216604A2C93AF5F6821168CA5_" file_name_sufix = "_pca_cn_cas_001.log" def conv_date(input_date, input_hour): local_date = datetime.strptime(input_date + " " + input_hour, "%Y%m%d %H").replace( tzinfo=tz.gettz('UTC')).astimezone(tz.gettz('Asia/Shanghai')) re_date = [] re_date.append(local_date.strftime("%Y%m%d")) re_date.append(local_date.strftime("%H")) return re_date def proc_log(proc_list): proc_files = proc_list[0] proc_filename = proc_list[1] with open(proc_filename, 'w') as output_f: for f in proc_files: try: with gzip.open(f, 'rt', encoding='utf-8') as input_f: for input_line in input_f: array_line = input_line.split(' ') dict_line = {} dict_line["Event-Type"] = array_line[0] dict_line["Site-ID"] = array_line[1] dict_line["Date"] = array_line[2] dict_line["Time"] = array_line[3] dict_line["C-IP"] = array_line[4] dict_line["CS-UserName"] = array_line[5] dict_line["S-SiteName"] = array_line[6] dict_line["S-ComputerName"] = array_line[7] dict_line["S-IP"] = array_line[8] dict_line["S-Port"] = array_line[9] dict_line["CS-Method"] = array_line[10] dict_line["CS-URI"] = array_line[11] dict_line["CS-URI-Query"] = array_line[12] dict_line["SC-Status"] = array_line[13] dict_line["SC-Win32-Status"] = array_line[14] dict_line["SC-Bytes"] = array_line[15] dict_line["CS-Bytes"] = array_line[16] dict_line["Time-Taken"] = array_line[17] dict_line["CS-Version"] = array_line[18] dict_line["CS-Host"] = array_line[19] dict_line["CS-UserAgent"] = array_line[20] dict_line["CS-Cookie"] = array_line[21] dict_line["CS-Referer"] = array_line[22] dict_line["SC-Sub-Status"] = array_line[23] dict_line["CS-Range"] = array_line[24] dict_line["SC-Initial"] = array_line[25] dict_line["SC-Complete"] = array_line[26] dict_line["SC-ContentType"] = array_line[27] dict_line["Protocol"] = array_line[28] dict_line["SC-Bytes-Body"] = array_line[29] dict_line["Bytes-Origin-Uncompressed"] = array_line[30] dict_line["C-RemotePort"] = array_line[31] array_output = [] array_output.append(dict_line["C-IP"]) array_output.append("-") array_output.append("-") array_output.append("[" + datetime.strptime(dict_line["Date"] + " " + dict_line["Time"], "%Y-%m-%d %H:%M:%S").replace( tzinfo=tz.gettz('UTC')).astimezone(tz.gettz('Asia/Shanghai')).strftime( "%d/%b/%Y:%H:%M:%S +08:00") + "]") array_output.append("\"" + dict_line["CS-Method"]) array_output.append( "http://" + dict_line["CS-Host"] + dict_line["CS-URI"] + "?" + dict_line["CS-URI-Query"]) array_output.append(dict_line["CS-Version"] + "\"") array_output.append(dict_line["SC-Status"]) array_output.append(dict_line["SC-Bytes"]) array_output.append("\"" + dict_line["CS-Referer"] + "\"") array_output.append("\"" + dict_line["CS-UserAgent"] + "\"") array_output.append("\"-\"") array_output.append(dict_line["S-IP"]) output_f.write(" ".join(array_output) + '\n') except Exception as e: traceback.print_exc(file=sys.stdout) print(f) continue def main(): global base_path global file_name_prefix global file_name_sufix array_subdirs = [] array_hours = [] array_proc_files = [] array_params = [] time_s = time.time() c_count = multiprocessing.cpu_count() array_subdirs = os.listdir(base_path) #目录下的文件/目录,放到这个列表下面 【'20170912','20170913'】 for i in range(0, 24, 1): array_hours.append('{0:02}'.format(i)) #日期格式 01 02 03 for hour in array_hours: for subdir in array_subdirs: f_name = conv_date(subdir, hour) #utc 转换为加8的时间, 格式【'20170912','09'】 array_proc_files = [] for root, dirs, files in os.walk(base_path + "/" + subdir): for file_name in files: #file_name 会列出子目录下的所有文件 #收集需要统计的日志文件,之中不包括upstream的,和_文件夹下的 if re.search(".*_upstream_.*", file_name) is None and re.search(".*_" + subdir + "_" + hour + "_.*", file_name) is not None: array_proc_files.append(os.path.join(root + "/" + file_name)) if len(array_proc_files) > 0: #输出的目标文件 array_params.append((array_proc_files, base_path + "/" + file_name_prefix + f_name[0] + "_" + f_name[ 1] + file_name_sufix)) '''for param in array_params: print(param)''' with Pool(processes=c_count) as pool: pool.map(proc_log, array_params) time_e = time.time() time_delta = time_e - time_s print("Using " + str(time_delta)) exit() if __name__ == '__main__': main()
2、域名item接口刷新
脚本里面涉及的内容:
1、针对域名对uri做收集
2、收集1000uri后做处理
3、url的截取domain、uri
4、request post 多key相同的情况下请求
#!/usr/bin/env python3 #python version 3 import sys import requests from urllib.parse import urlparse username = 'Mr.python' #input your username password = '*******' #input your password mailto = '[email protected]' #input your email-address if len(sys.argv) != 2: print('\033[1;32m You need input a filename,Format:*.py Filename !! \033[0m') sys.exit() filename = sys.argv[1] domains = {} with open(filename) as f: for line in f: if line == '': continue res = urlparse(line.strip()) parm = '' if res.query: parm = '?' + res.query pad, uri = res.netloc, res.path + parm #print('pad',pad,'uri',uri) if pad not in domains: domains[pad] = [] domains[pad].append(uri) else: domains[pad].append(uri) #print(domains) for domain in domains: print('\033[1;32m Processing Domain: !!\033[0m',domain,'........') openapi = 'https://openapi.us.cdnetworks.com/purge/rest/doPurge' pad = domain flush_item = [] max_item = 1000 loop_count = 0 for uri in domains[domain]: if loop_count == max_item: payload = [('user',username),('pass',password),('pad',pad),('type','item'),('mailTo',mailto),('output','json')] payload = payload + flush_item payload = tuple(payload) #print(loop_count) #print(payload) res = requests.post(openapi,data=payload) print(res.text) loop_count = 1 flush_item = [] flush_item.append(('path',uri)) else: # print('loop_count',loop_count) flush_item.append(('path',uri)) #print(flush_item) loop_count +=1 if len(flush_item) != 0: payload = [('user',username),('pass',password),('pad',pad),('type','item'),('mailTo',mailto),('output','json')] payload = payload + flush_item payload = tuple(payload) #print(payload) res = requests.post(openapi,data=payload) print(res.text)
3、备案结果查询
脚本里面涉及的内容
1、client模块的使用
2、域名本案结果批量查询
#!/usr/bin/env python3 # coding: utf-8 import json from suds.client import Client import time def process(domains,begin,end): wsdl = "http://x.x.x.x:43392/?wsdl" param = json.dumps({"IcpRequest": {"domains": domains[begin:end]}}) client = Client(wsdl) client.set_options(timeout=3000) result_main = client.service.findDomainState_main(param) res = json.loads(result_main) res1 = res['IcpRespone']['domains'] for i in res1: print('Domain:%-30s NO:%-20s'%(i['domain'],i['phylicnum'])) with open('result.txt','a') as f: f.write(i['domain'] + ':' + i['phylicnum'] + '\n') def domains(filename): with open(filename) as f: domains = [] for line in f: domains.append(line.strip()) return domains def rangerequest(filename): domain = domains(filename) begin = 0 end = 10 n = 1 for i in range(0,len(domain),10): print(' \033[1;35m <======== begin:%s,end:%s , 第%s批 ========> \033[0m ' % (begin, end, n)) print(domain[begin:end]) print('\033[1;31m Time:%s \033[0m'%time.strftime(" %X")) print('') try: process(domain,begin,end) except Exception as e: print(e) print('') print(' \033[1;32m done!!! \033[0m') begin += 10 end += 10 n += 1 if __name__ == '__main__': try: rangerequest('beian_domains.txt') #you need input you domain`s filename except Exception as e: print(e)
4、多级域名中取主域
脚本的设计内容
1、python中的正则
2、标准中定义的后缀
def get_sld(input_domain): output_domain = "" if re.search(r"^([0-9a-zA-Z-])+\.([0-9a-zA-Z-])+$", input_domain): output_domain = input_domain elif re.search(r"\.(co|or|aaa|aarp|abb|abbott|abbvie|abogado|abudhabi|academy|accenture|accountant|accountants|\ aco|active|actor|adac|ads|adult|aeg|aero|afl|agakhan|agency|aig|airforce|airtel|akdn|allfinanz|\ ally|alsace|amica|amsterdam|analytics|android|anquan|apartments|app|aquarelle|aramco|archi|army|\ arpa|arte|asia|associates|attorney|auction|audi|audio|author|auto|autos|avianca|aws|axa|azure|\ baby|band|bank|bar|barcelona|barclaycard|barclays|barefoot|bargains|bauhaus|bayern|bbva|bcg|bcn|\ beats|beer|bentley|berlin|best|bet|bharti|bible|bid|bike|bing|bingo|bio|biz|black|blackfriday|bloomberg|\ blue|bms|bmw|bnl|bnpparibas|boats|boehringer|bom|bond|boo|book|boots|bosch|bostik|bot|boutique|bradesco|\ bridgestone|broadway|broker|brother|brussels|budapest|bugatti|build|builders|business|buy|buzz|bzh|\ cab|cafe|cal|call|camera|camp|cancerresearch|canon|capetown|capital|car|caravan|cards|care|career|careers|\ cars|cartier|casa|cash|casino|cat|catering|cba|cbn|ceb|center|ceo|cern|cfa|cfd|chanel|channel|chase|chat|\ cheap|chloe|christmas|chrome|church|cipriani|circle|cisco|citic|city|cityeats|claims|cleaning|click|clinic|\ clinique|clothing|cloud|club|clubmed|coach|codes|coffee|college|cologne|com|commbank|community|company|compare|\ computer|comsec|condos|construction|consulting|contact|contractors|cooking|cool|coop|corsica|country|coupon|coupons|\ courses|credit|creditcard|creditunion|cricket|crown|crs|cruises|csc|cuisinella|cymru|cyou|\ dabur|dad|dance|date|dating|datsun|day|dclk|dds|dealer|deals|degree|delivery|dell|deloitte|delta|democrat|\ dental|dentist|desi|design|dev|diamonds|diet|digital|direct|directory|discount|dnp|docs|dog|doha|domains|doosan|\ download|drive|dubai|durban|dvag|\ earth|eat|edeka|edu|education|email|emerck|energy|engineer|engineering|enterprises|equipment|erni|\ esq|estate|eurovision|eus|events|everbank|exchange|expert|exposed|express|extraspace|\ fage|fail|fairwinds|faith|family|fan|fans|farm|fashion|fast|feedback|ferrero|film|final|finance|\ financial|firestone|firmdale|fish|fishing|fit|fitness|flights|florist|flowers|flsmidth|fly|foo|football|\ ford|forex|forsale|forum|foundation|fox|fresenius|frl|frogans|frontier|ftr|fund|furniture|futbol|fyi|\ gal|gallery|gallo|gallup|game|garden|gbiz|gdn|gea|gent|genting|ggee|gift|gifts|gives|giving|glass|gle|global|\ globo|gmail|gmbh|gmo|gmx|gold|goldpoint|golf|goo|goog|gop|got|gov|grainger|graphics|gratis|green|gripe|group|\ gucci|guge|guide|guitars|guru|\ hamburg|hangout|haus|hdfcbank|health|healthcare|help|helsinki|here|hermes|hiphop|hitachi|hiv|hkt|hockey|\ holdings|holiday|homedepot|homes|honda|horse|host|hosting|hoteles|hotmail|house|how|hsbc|htc|hyundai|\ ibm|icbc|ice|icu|ifm|iinet|imamat|immo|immobilien|industries|infiniti|info|ing|ink|institute|insurance|\ insure|int|international|investments|ipiranga|irish|iselect|ismaili|ist|istanbul|itau|iwc|\ jaguar|java|jcb|jcp|jetzt|jewelry|jlc|jll|jmp|jnj|jobs|joburg|jot|jpmorgan|jprs|juegos|\ kaufen|kddi|kerryhotels|kerrylogistics|kerryproperties|kfh|kia|kim|kinder|kitchen|kiwi|koeln|komatsu|kpmg|\ kpn|krd|kred|kuokgroup|kyoto|\ lacaixa|lamborghini|lamer|lancaster|land|landrover|lanxess|lasalle|lat|latrobe|law|lawyer|lds|lease|\ leclerc|legal|lexus|lgbt|liaison|lidl|life|lifeinsurance|lifestyle|lighting|like|limited|limo|lincoln|linde|\ link|lipsy|live|living|lixil|loan|loans|locus|lol|london|lotte|lotto|love|ltd|ltda|lupin|luxe|luxury|\ madrid|maif|maison|makeup|man|management|mango|market|marketing|markets|marriott|mba|med|media|meet|melbourne|\ meme|memorial|men|menu|meo|miami|microsoft|mil|mini|mls|mma|mobi|mobily|moda|moe|moi|mom|monash|money|montblanc|\ mormon|mortgage|moscow|motorcycles|mov|movie|movistar|mtn|mtpc|mtr|museum|mutual|mutuelle|\ nadex|nagoya|name|natura|navy|nec|net|netbank|network|neustar|new|news|next|nextdirect|nexus|ngo|nhk|nico|nikon|\ ninja|nissan|nissay|nokia|northwesternmutual|norton|nowruz|nowtv|nra|nrw|ntt|nyc|\ obi|office|okinawa|olayan|olayangroup|omega|one|ong|onl|online|ooo|oracle|orange|org|organic|origins|osaka|\ otsuka|ovh|\ page|pamperedchef|panerai|paris|pars|partners|parts|party|passagens|pet|pharmacy|philips|photo|photography|\ photos|physio|piaget|pics|pictet|pictures|pid|pin|ping|pink|pizza|place|play|playstation|plumbing|plus|pohl|\ poker|porn|post|praxi|press|pro|prod|productions|prof|progressive|promo|properties|property|protection|pub|pwc|\ qpon|quebec|quest|\ racing|read|realtor|realty|recipes|red|redstone|redumbrella|rehab|reise|reisen|reit|ren|rent|rentals|repair|\ report|republican|rest|restaurant|review|reviews|rexroth|rich|ricoh|rio|rip|rocher|rocks|rodeo|room|rsvp|ruhr|\ run|rwe|ryukyu|\ saarland|safe|safety|sakura|sale|salon|sandvik|sandvikcoromant|sanofi|sap|sapo|sarl|sas|saxo|sbi|sbs|sca|scb|\ schaeffler|schmidt|scholarships|school|schule|schwarz|science|scor|scot|seat|security|seek|select|sener|services|\ seven|sew|sex|sexy|sfr|sharp|shaw|shell|shia|shiksha|shoes|shouji|show|shriram|singles|site|ski|skin|sky|skype|\ smile|sncf|soccer|social|softbank|software|sohu|solar|solutions|song|sony|soy|space|spiegel|spot|spreadbetting|srl|\ stada|star|starhub|statebank|statefarm|statoil|stc|stcgroup|stockholm|storage|store|stream|studio|study|style|sucks|\ supplies|supply|support|surf|surgery|suzuki|swatch|swiss|sydney|symantec|systems|\ tab|taipei|talk|taobao|tatamotors|tatar|tattoo|tax|taxi|tci|team|tech|technology|tel|telecity|telefonica|\ temasek|tennis|teva|thd|theater|theatre|tickets|tienda|tiffany|tips|tires|tirol|tmall|today|tokyo|tools|top|\ toray|toshiba|total|tours|town|toyota|toys|trade|trading|training|travel|travelers|travelersinsurance|trust|trv|\ tube|tui|tunes|tushu|tvs|\ ubs|unicom|university|uno|uol|\ vacations|vana|vegas|ventures|verisign|versicherung|vet|viajes|video|vig|viking|villas|vin|vip|virgin|vision|\ vista|vistaprint|viva|vlaanderen|vodka|volkswagen|vote|voting|voto|voyage|vuelos|\ wales|walter|wang|wanggou|warman|watch|watches|weather|weatherchannel|webcam|weber|website|wed|wedding|weir|whoswho\ |wien|wiki|williamhill|win|windows|wine|wme|wolterskluwer|work|works|world|wtc|wtf|\ xbox|xerox|xihuan|xin|орг|xperia|xxx|xyz|\ yachts|yahoo|yamaxun|yandex|yodobashi|yoga|yokohama|you|youtube|yun|\ zara|zero|zip|zone|zuerich){1}\.(ac|ad|ae|af|ag|ai|al|am|an|ao|aq|ar|as|at|au|aw|ax|az|\ ba|bb|bd|be|bf|bg|bh|bi|bj|bm|bn|bo|bq|br|bs|bt|bv|bw|by|bz|\ ca|cc|cd|cf|cg|ch|ci|ck|cl|cm|cn|co|cr|cu|cv|cw|cx|cy|cz|\ de|dj|dk|dm|do|dz|\ ec|ee|eg|eh|er|es|et|eu|\ fi|fj|fk|fm|fo|fr|\ ga|gb|gd|ge|gf|gg|gh|gi|gl|gm|gn|gp|gq|gr|gs|gt|gu|gw|gy|\ hk|hm|hn|hr|ht|hu|\ id|ie|il|im|in|io|iq|ir|is|it|\ je|jm|jo|jp|\ ke|kg|kh|ki|km|kn|kp|kr|kw|ky|kz|\ la|lb|lc|li|lk|lr|ls|lt|lu|lv|ly|\ ma|mc|md|me|mg|mh|mk|ml|mm|mn|mo|mp|mq|mr|ms|mt|mu|mv|mw|mx|my|mz|\ na|nc|ne|nf|ng|ni|nl|no|np|nr|nu|nz|\ om|\ pa|pe|pf|pg|ph|pk|pl|pm|pn|pr|ps|pt|pw|py|\ qa|\ re|ro|rs|ru|rw|\ sa|sb|sc|sd|se|sg|sh|si|sj|sk|sl|sm|sn|so|sr|ss|st|su|sv|sx|sy|sz|\ tc|td|tf|tg|th|tj|tk|tl|tm|tn|to|tp|tr|tt|tv|tw|tz|\ ua|ug|uk|us|uy|uz|\ va|vc|ve|vg|vi|vn|vu|\ wf|ws|\ ye|yt|\ za|zm|zw){1}$", input_domain): match = re.search(r"\.{0,1}([0-9a-zA-Z-])+\.(co|or|\ aaa|aarp|abb|abbott|abbvie|abogado|abudhabi|academy|accenture|accountant|\ accountants|aco|active|actor|adac|ads|adult|aeg|aero|afl|agakhan|agency|\ aig|airforce|airtel|akdn|allfinanz|ally|alsace|amica|amsterdam|analytics|\ android|anquan|apartments|app|aquarelle|aramco|archi|army|arpa|arte|asia|associates|\ attorney|auction|audi|audio|author|auto|autos|avianca|aws|axa|azure|\ baby|band|bank|bar|barcelona|barclaycard|barclays|barefoot|bargains|bauhaus|bayern|\ bbva|bcg|bcn|beats|beer|bentley|berlin|best|bet|bharti|bible|bid|bike|bing|bingo|bio|biz|\ black|blackfriday|bloomberg|blue|bms|bmw|bnl|bnpparibas|boats|boehringer|bom|bond|boo|\ book|boots|bosch|bostik|bot|boutique|bradesco|bridgestone|broadway|broker|brother|brussels|\ budapest|bugatti|build|builders|business|buy|buzz|bzh|\ cab|cafe|cal|call|camera|camp|cancerresearch|canon|capetown|capital|car|caravan|cards|care|\ career|careers|cars|cartier|casa|cash|casino|cat|catering|cba|cbn|ceb|center|ceo|cern|cfa|cfd|\ chanel|channel|chase|chat|cheap|chloe|christmas|chrome|church|cipriani|circle|cisco|citic|city|\ cityeats|claims|cleaning|click|clinic|clinique|clothing|cloud|club|clubmed|coach|codes|coffee|\ college|cologne|com|commbank|community|company|compare|computer|comsec|condos|construction|\ consulting|contact|contractors|cooking|cool|coop|corsica|country|coupon|coupons|courses|credit|\ creditcard|creditunion|cricket|crown|crs|cruises|csc|cuisinella|cymru|cyou|\ dabur|dad|dance|date|dating|datsun|day|dclk|dds|dealer|deals|degree|delivery|dell|deloitte|\ delta|democrat|dental|dentist|desi|design|dev|diamonds|diet|digital|direct|directory|discount|\ dnp|docs|dog|doha|domains|doosan|download|drive|dubai|durban|dvag|\ earth|eat|edeka|edu|education|email|emerck|energy|engineer|engineering|enterprises|equipment|\ erni|esq|estate|eurovision|eus|events|everbank|exchange|expert|exposed|express|extraspace|\ fage|fail|fairwinds|faith|family|fan|fans|farm|fashion|fast|feedback|ferrero|film|final|finance|\ financial|firestone|firmdale|fish|fishing|fit|fitness|flights|florist|flowers|flsmidth|fly|foo|\ football|ford|forex|forsale|forum|foundation|fox|fresenius|frl|frogans|frontier|ftr|fund|furniture|\ futbol|fyi|\ gal|gallery|gallo|gallup|game|garden|gbiz|gdn|gea|gent|genting|ggee|gift|gifts|gives|giving|\ glass|gle|global|globo|gmail|gmbh|gmo|gmx|gold|goldpoint|golf|goo|goog|gop|got|gov|grainger|\ graphics|gratis|green|gripe|group|gucci|guge|guide|guitars|guru|\ hamburg|hangout|haus|hdfcbank|health|healthcare|help|helsinki|here|hermes|hiphop|hitachi|hiv|\ hkt|hockey|holdings|holiday|homedepot|homes|honda|horse|host|hosting|hoteles|hotmail|house|how|\ hsbc|htc|hyundai|\ ibm|icbc|ice|icu|ifm|iinet|imamat|immo|immobilien|industries|infiniti|info|ing|ink|institute|\ insurance|insure|int|international|investments|ipiranga|irish|iselect|ismaili|ist|istanbul|\ itau|iwc|\ jaguar|java|jcb|jcp|jetzt|jewelry|jlc|jll|jmp|jnj|jobs|joburg|jot|jpmorgan|jprs|juegos|\ kaufen|kddi|kerryhotels|kerrylogistics|kerryproperties|kfh|kia|kim|kinder|kitchen|kiwi|koeln|\ komatsu|kpmg|kpn|krd|kred|kuokgroup|kyoto|\ lacaixa|lamborghini|lamer|lancaster|land|landrover|lanxess|lasalle|lat|latrobe|law|lawyer|lds|\ lease|leclerc|legal|lexus|lgbt|liaison|lidl|life|lifeinsurance|lifestyle|lighting|like|limited|limo|\ lincoln|linde|link|lipsy|live|living|lixil|loan|loans|locus|lol|london|lotte|lotto|love|ltd|ltda|lupin|\ luxe|luxury|\ madrid|maif|maison|makeup|man|management|mango|market|marketing|markets|marriott|mba|med|media|\ meet|melbourne|meme|memorial|men|menu|meo|miami|microsoft|mil|mini|mls|mma|mobi|mobily|moda|moe|\ moi|mom|monash|money|montblanc|mormon|mortgage|moscow|motorcycles|mov|movie|movistar|mtn|mtpc|mtr|\ museum|mutual|mutuelle|\ nadex|nagoya|name|natura|navy|nec|net|netbank|network|neustar|new|news|next|nextdirect|nexus|ngo|\ nhk|nico|nikon|ninja|nissan|nissay|nokia|northwesternmutual|norton|nowruz|nowtv|nra|nrw|ntt|nyc|\ obi|office|okinawa|olayan|olayangroup|omega|one|ong|onl|online|ooo|oracle|orange|org|organic|\ origins|osaka|otsuka|ovh|\ page|pamperedchef|panerai|paris|pars|partners|parts|party|passagens|pet|pharmacy|philips|\ photo|photography|photos|physio|piaget|pics|pictet|pictures|pid|pin|ping|pink|pizza|place|play|\ playstation|plumbing|plus|pohl|poker|porn|post|praxi|press|pro|prod|productions|prof|progressive|promo|\ properties|property|protection|pub|pwc|\ qpon|quebec|quest|\ racing|read|realtor|realty|recipes|red|redstone|redumbrella|rehab|reise|reisen|reit|ren|rent|rentals|\ repair|report|republican|rest|restaurant|review|reviews|rexroth|rich|ricoh|rio|rip|rocher|rocks|rodeo|\ room|rsvp|ruhr|run|rwe|ryukyu|\ saarland|safe|safety|sakura|sale|salon|sandvik|sandvikcoromant|sanofi|sap|sapo|sarl|sas|saxo|sbi|sbs|\ sca|scb|schaeffler|schmidt|scholarships|school|schule|schwarz|science|scor|scot|seat|security|seek|\ select|sener|services|seven|sew|sex|sexy|sfr|sharp|shaw|shell|shia|shiksha|shoes|shouji|show|shriram|\ singles|site|ski|skin|sky|skype|smile|sncf|soccer|social|softbank|software|sohu|solar|solutions|song|\ sony|soy|space|spiegel|spot|spreadbetting|srl|stada|star|starhub|statebank|statefarm|statoil|stc|stcgroup|\ stockholm|storage|store|stream|studio|study|style|sucks|supplies|supply|support|surf|surgery|suzuki|swatch|\ swiss|sydney|symantec|systems|\ tab|taipei|talk|taobao|tatamotors|tatar|tattoo|tax|taxi|tci|team|tech|technology|tel|telecity|telefonica|\ temasek|tennis|teva|thd|theater|theatre|tickets|tienda|tiffany|tips|tires|tirol|tmall|today|tokyo|tools|top|\ toray|toshiba|total|tours|town|toyota|toys|trade|trading|training|travel|travelers|travelersinsurance|trust|\ trv|tube|tui|tunes|tushu|tvs|\ ubs|unicom|university|uno|uol|\ vacations|vana|vegas|ventures|verisign|versicherung|vet|viajes|video|vig|viking|villas|vin|vip|virgin|\ vision|vista|vistaprint|viva|vlaanderen|vodka|volkswagen|vote|voting|voto|voyage|vuelos|\ wales|walter|wang|wanggou|warman|watch|watches|weather|weatherchannel|webcam|weber|website|wed|wedding|\ weir|whoswho|wien|wiki|williamhill|win|windows|wine|wme|wolterskluwer|work|works|world|wtc|wtf|\ xbox|xerox|xihuan|xin|орг|xperia|xxx|xyz|\ yachts|yahoo|yamaxun|yandex|yodobashi|yoga|yokohama|you|youtube|yun|\ zara|zero|zip|zone|zuerich){1}\.(ac|ad|ae|af|ag|ai|al|am|an|ao|aq|ar|as|at|au|aw|ax|az|\ ba|bb|bd|be|bf|bg|bh|bi|bj|bm|bn|bo|bq|br|bs|bt|bv|bw|by|bz|\ ca|cc|cd|cf|cg|ch|ci|ck|cl|cm|cn|co|cr|cu|cv|cw|cx|cy|cz|\ de|dj|dk|dm|do|dz|\ ec|ee|eg|eh|er|es|et|eu|\ fi|fj|fk|fm|fo|fr|\ ga|gb|gd|ge|gf|gg|gh|gi|gl|gm|gn|gp|gq|gr|gs|gt|gu|gw|gy|\ hk|hm|hn|hr|ht|hu|\ id|ie|il|im|in|io|iq|ir|is|it|\ je|jm|jo|jp|\ ke|kg|kh|ki|km|kn|kp|kr|kw|ky|kz|\ la|lb|lc|li|lk|lr|ls|lt|lu|lv|ly|\ ma|mc|md|me|mg|mh|mk|ml|mm|mn|mo|mp|mq|mr|ms|mt|mu|mv|mw|mx|my|mz|\ na|nc|ne|nf|ng|ni|nl|no|np|nr|nu|nz|\ om|\ pa|pe|pf|pg|ph|pk|pl|pm|pn|pr|ps|pt|pw|py|\ qa|\ re|ro|rs|ru|rw|\ sa|sb|sc|sd|se|sg|sh|si|sj|sk|sl|sm|sn|so|sr|ss|st|su|sv|sx|sy|sz|\ tc|td|tf|tg|th|tj|tk|tl|tm|tn|to|tp|tr|tt|tv|tw|tz|\ ua|ug|uk|us|uy|uz|\ va|vc|ve|vg|vi|vn|vu|\ wf|ws|\ ye|yt|\ za|zm|zw){1}$", input_domain) if (str(match.group(0))[0:1] == "."): output_domain = str(match.group(0))[1:] else: output_domain = str(match.group(0)) elif re.search(r"\.(ac|ad|ae|af|ag|ai|al|am|an|ao|aq|ar|as|at|au|aw|ax|az|\ ba|bb|bd|be|bf|bg|bh|bi|bj|bm|bn|bo|bq|br|bs|bt|bv|bw|by|bz|\ ca|cc|cd|cf|cg|ch|ci|ck|cl|cm|cn|co|cr|cu|cv|cw|cx|cy|cz|\ de|dj|dk|dm|do|dz|\ ec|ee|eg|eh|er|es|et|eu|\ fi|fj|fk|fm|fo|fr|\ ga|gb|gd|ge|gf|gg|gh|gi|gl|gm|gn|gp|gq|gr|gs|gt|gu|gw|gy|\ hk|hm|hn|hr|ht|hu|\ id|ie|il|im|in|io|iq|ir|is|it|\ je|jm|jo|jp|\ ke|kg|kh|ki|km|kn|kp|kr|kw|ky|kz|\ la|lb|lc|li|lk|lr|ls|lt|lu|lv|ly|\ ma|mc|md|me|mg|mh|mk|ml|mm|mn|mo|mp|mq|mr|ms|mt|mu|mv|mw|mx|my|mz|\ na|nc|ne|nf|ng|ni|nl|no|np|nr|nu|nz|\ om|\ pa|pe|pf|pg|ph|pk|pl|pm|pn|pr|ps|pt|pw|py|\ qa|\ re|ro|rs|ru|rw|\ sa|sb|sc|sd|se|sg|sh|si|sj|sk|sl|sm|sn|so|sr|ss|st|su|sv|sx|sy|sz|\ tc|td|tf|tg|th|tj|tk|tl|tm|tn|to|tp|tr|tt|tv|tw|tz|\ ua|ug|uk|us|uy|uz|\ va|vc|ve|vg|vi|vn|vu|\ wf|ws|\ ye|yt|\ za|zm|zw){1}$", input_domain): match = re.search(r"\.{0,1}([0-9a-zA-Z-])+\.(ac|ad|ae|af|ag|ai|al|am|an|ao|aq|ar|as|at|au|aw|ax|az|\ ba|bb|bd|be|bf|bg|bh|bi|bj|bm|bn|bo|bq|br|bs|bt|bv|bw|by|bz|\ ca|cc|cd|cf|cg|ch|ci|ck|cl|cm|cn|co|cr|cu|cv|cw|cx|cy|cz|\ de|dj|dk|dm|do|dz|\ ec|ee|eg|eh|er|es|et|eu|\ fi|fj|fk|fm|fo|fr|\ ga|gb|gd|ge|gf|gg|gh|gi|gl|gm|gn|gp|gq|gr|gs|gt|gu|gw|gy|\ hk|hm|hn|hr|ht|hu|\ id|ie|il|im|in|io|iq|ir|is|it|\ je|jm|jo|jp|\ ke|kg|kh|ki|km|kn|kp|kr|kw|ky|kz|\ la|lb|lc|li|lk|lr|ls|lt|lu|lv|ly|\ ma|mc|md|me|mg|mh|mk|ml|mm|mn|mo|mp|mq|mr|ms|mt|mu|mv|mw|mx|my|mz|\ na|nc|ne|nf|ng|ni|nl|no|np|nr|nu|nz|\ om|\ pa|pe|pf|pg|ph|pk|pl|pm|pn|pr|ps|pt|pw|py|\ qa|\ re|ro|rs|ru|rw|\ sa|sb|sc|sd|se|sg|sh|si|sj|sk|sl|sm|sn|so|sr|ss|st|su|sv|sx|sy|sz|\ tc|td|tf|tg|th|tj|tk|tl|tm|tn|to|tp|tr|tt|tv|tw|tz|\ ua|ug|uk|us|uy|uz|\ va|vc|ve|vg|vi|vn|vu|\ wf|ws|\ ye|yt|\ za|zm|zw){1}$", input_domain) if (str(match.group(0))[0:1] == "."): output_domain = str(match.group(0))[1:] else: output_domain = str(match.group(0)) elif re.search(r"\.([0-9a-zA-Z-])+\.([0-9a-zA-Z-])+$", input_domain): match = re.search(r"\.([0-9a-zA-Z-])+\.([0-9a-zA-Z-])+$", input_domain) output_domain = str(match.group(0))[1:] else: output_domain = input_domain return output_domain
5、发送邮件
脚本涉及的内容
1、126邮箱smtp服务端的设置
2、python发送邮件模块的使用
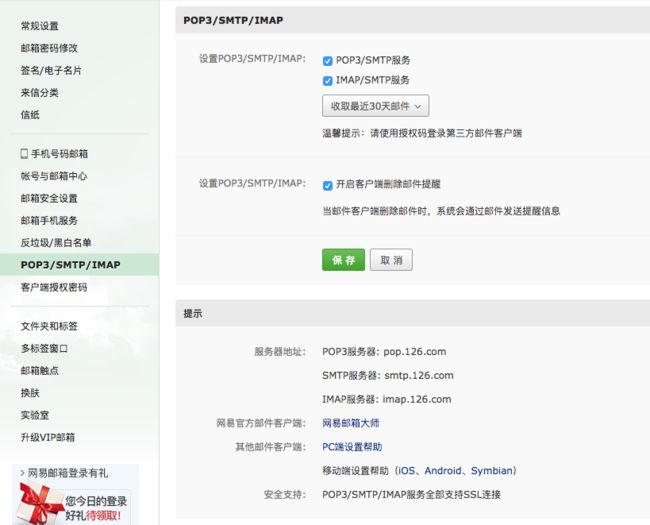
126服务端需要开启SMTP服务,这是你已经设置了客户端授权密码,这时候就需要用客户端授权密码去登录
# !/usr/bin/env python3 # -*- coding: UTF-8 -*- import smtplib from email.mime.text import MIMEText from email.header import Header sender = '[email protected]' password = '******' subject = "CDN_Analysis - BEIAN Status Summary" fromaddr = "[email protected]" toaddrs = [ '[email protected]', '[email protected]'] #msg = ("From: %s\r\nSubject: %s\r\nTo: %s\r\n\r\n" % (fromaddr, subject, ",".join(toaddrs))) #print(msg) subject = "python邮件测试" content = "这是我使用python smtplib及email模块发送的邮件" msg = MIMEText(content, 'plain', 'utf-8') msg['Subject'] = Header(subject, 'utf-8') msg['From'] = fromaddr msg['To'] = toaddrs #不能是个邮箱的列表得是单个邮箱,下面注释的是测试正确的,邮件中只会显示这个人的邮箱,列表中其他的邮箱被隐藏发送了 #subject = '放假通知' #msg =MIMEText(content,'plain','utf-8')#中文需参数‘utf-8',单字节字符不需要 #msg['Subject'] = Header(subject, 'utf-8') #msg['From'] = '[email protected]' #msg['To'] = "[email protected]" try: smtpObj = smtplib.SMTP('smtp.126.com') smtpObj.set_debuglevel(1) smtpObj.login(sender, password) smtpObj.sendmail(sender, toaddrs, msg.as_string()) print("邮件发送成功") except smtplib.SMTPException as e: print("Error: 无法发送邮件",e) ============ 简洁版 ========== # -*- coding: UTF-8 -*- from email.mime.text import MIMEText from email.header import Header subject = '放假通知' msg = MIMEText('大家关好窗户','plain','utf-8')#中文需参数‘utf-8',单字节字符不需要 msg['Subject'] = Header(subject, 'utf-8') msg['From'] = '[email protected]' msg['To'] = "[email protected]" from_addr = '[email protected]' password = '*******' smtp_server = 'smtp.126.com' to_addr = '[email protected]' import smtplib server = smtplib.SMTP(smtp_server, 25) # SMTP协议默认端口是25 server.set_debuglevel(1) server.login(from_addr, password) server.sendmail(from_addr, [to_addr], msg.as_string()) server.quit()
收到的邮件内容如下:
6、通过api获取cdn edge ip
脚本涉及的内容:
1、获取token
2、再通过token获取ip list
3、requests
#!/usr/bin/env python3 import requests import json username = '[email protected]' password = '123!@#qwe' def get_token(): api_url = 'https://openapi.cdnetworks.com/api/rest/login' p_data = {'user':username,'pass':password,'output':'json'} r = requests.post(api_url,data=p_data) res = json.loads(r.text) if res['loginResponse']['resultCode'] == 0: return res else: return 'error' def pro_list(): result = get_token() for sess in result['loginResponse']['session']: print(sess) while True: svcGroupName = input('please input the svcGroupName:') for sess in result['loginResponse']['session']: if sess['svcGroupName'] == svcGroupName: #print('sessionToekn:',sess['sessionToken']) return sess['sessionToken'] else: continue print('your svcGroupName not correct!!!') def getCdnEdgeList(): sessionToken = pro_list() print(sessionToken) api_url = 'https://openapi.cdnetworks.com/api/rest/cdn/getCdnEdgeList' p_data = {'sessionToken': sessionToken, 'output': 'json'} r = requests.post(api_url,data=p_data) res = json.loads(r.text) if res['ipListResponse']['returnCode'] == 0: return res else: return 'error' def ip_list(): iplists = getCdnEdgeList()['ipListResponse']['item'] for ip in iplists: print(ip) if __name__ == '__main__': ip_list()
获取token后再获取apikey,两者结合再去查询
#!/usr/bin/env python3 import requests import json username = '[email protected]' password = '123!@#qwe' def get_token(): api_url = 'https://openapi.cdnetworks.com/api/rest/login' p_data = {'user':username,'pass':password,'output':'json'} r = requests.post(api_url,data=p_data) res = json.loads(r.text) if res['loginResponse']['resultCode'] == 0: return res else: return 'error' def pro_list(): result = get_token() for sess in result['loginResponse']['session']: print(sess) while True: svcGroupName = input('please input the svcGroupName:') for sess in result['loginResponse']['session']: if sess['svcGroupName'] == svcGroupName: #print('sessionToekn:',sess['sessionToken']) return sess['sessionToken'] else: continue print('your svcGroupName not correct!!!') def get_api_key_list(): post_data = {} sessionToken = pro_list() post_data['sessionToken'] = sessionToken print(sessionToken) api_key_list = 'https://openapi.cdnetworks.com/api/rest/getApiKeyList' post_data = {'sessionToken':sessionToken,'output':'json'} r = requests.post(api_key_list, data=post_data) res = json.loads(r.text) if res['apiKeyInfo']['returnCode'] == 0: for pad in res['apiKeyInfo']['apiKeyInfoItem']: print(pad) while True: padName = input('please input the PAD you want:') for sess in res['apiKeyInfo']['apiKeyInfoItem']: if sess['serviceName'] == padName.strip(): #print('sessionToekn:',sess['sessionToken']) choice_apikey = sess['apiKey'] post_data['apiKey'] = choice_apikey return post_data else: continue else: print('get data fail,Maybe there is something wrong with the sessionToken') def traffic_info(): post_data = get_api_key_list() traffic_info_api = 'https://openapi.cdnetworks.com/api/rest/traffic/edge' post_data['output'] = 'json' post_data['fromDate'] = 20171212 post_data['toDate'] = 20171213 post_data['timeInterval'] = 0 print(post_data) r = requests.post(traffic_info_api, data=post_data) res = json.loads(r.text) res = json.dumps(res, indent=4) print(res) def getCdnEdgeList(): sessionToken = pro_list() print(sessionToken) api_url = 'https://openapi.cdnetworks.com/api/rest/cdn/getCdnEdgeList' p_data = {'sessionToken': sessionToken, 'output': 'json'} r = requests.post(api_url,data=p_data) res = json.loads(r.text) if res['ipListResponse']['returnCode'] == 0: return res else: return 'error' def ip_list(): iplists = getCdnEdgeList()['ipListResponse']['item'] for ip in iplists: print(ip) if __name__ == '__main__': traffic_info()
8、多线程下载
脚本涉及的内容
一个大的文件,分range去分段请求,下载完毕后然后再组合到一起
#!/usr/bin/env python #coding:utf-8 from multiprocessing import Pool import sys import requests class downloader(object): # 构造函数 def __init__(self,url,num=4): # 要下载的数据连接 self.url = url # 要开的线程数 self.num = num # 存储文件的名字,从url最后面取 self.name = self.url.split('/')[-1] # head方法去请求url r = requests.head(self.url) # headers中取出数据的长度 self.total = int(r.headers['Content-Length']) print 'total is %s' % (self.total) def get_range(self): ranges=[] # 比如total是50,线程数是4个。offset就是12 offset = int(self.total/self.num) for i in range(self.num): if i==self.num-1: # 最后一个线程,不指定结束位置,取到最后 ranges.append((i*offset,'')) else: # 每个线程取得区间 ranges.append((i*offset,(i+1)*offset)) return ranges # range大概是[(0,12),(12,24),(25,36),(36,'')] def download(self,start,end): # 拼出Range参数 获取分片数据 headers={'Range':'Bytes=%s-%s' % (start,end),'Accept-Encoding':'*'} res = requests.get(self.url,headers=headers) print '%s:%s download success'%(start,end) #seek(m,n):从文件n位置开始,指针偏移m个字节,n:0(文件头),1(当前位置),2(文件未),seek(x),从x处开始 self.fd.seek(start) self.fd.write(res.content) def run(self): self.fd = open(self.name,'w') p = Pool(self.num) n = 1 for ran in self.get_range(): start,end = ran p.apply_async(self.download,args=(start,end,)) print 'Proces %s start:%s,end:%s'% (n,start,end) n += 1 p.close() p.join() print 'download %s load success'% (self.name) self.fd.close() if __name__=='__main__': #down = downloader('http://51reboot.com/src/blogimg/pc.jpg',5) if len(sys.argv) != 3: print "usage: python download2.py url num" sys.exit(1) down = downloader(sys.argv[1],int(sys.argv[2])) down.run()
9、服务器硬盘清理
脚本涉及的内容
Popen的使用,使用python在linux服务器上面执行一些shell命令
#!/usr/bin/python # Managed by Puppet - /var/cdn/ops/clearcache2.py # $Id: clearcache2.py 5526 2013-07-24 02:18:11Z taejoon.moon $ ##### See OPSUSSD-653 for the history # clearcache2.py -- New, more efficient clearcache script # # Improves performance over clearcache.sh by destroying and re-creating the # filesystem on each /cacheX partition instead of running a slow "rm -rf" # # Usage: sudo ./clearcache2.py ##### from subprocess import PIPE, Popen, STDOUT from os import getuid from time import sleep def stopServices(): print "===== Stopping HTTP and NMON =====" Popen(['/home/cdn/nmon/nmon', 'stop']).wait() Popen(['/home/cdn/http/http', 'stop']).wait() print "...done" def startServices(): print "===== Re-starting HTTP and NMON =====" Popen(['/home/cdn/http/http', 'restart']).wait() Popen(['/home/cdn/nmon/nmon', 'restart' ]).wait() print "...done" def prepareCache(): print "===== Preparing cache for first-use =====" print "Removing old index and flush informations" Popen(["/bin/rm -rf /var/cdn/http/cacheindex.* /var/cdn/http/flush* /var/cdn/http/last-flush-id /var/cdn/http/http-sites-verified.xml.*"], shell=True).wait() print "Cleaning JVM crash dumps" Popen(["/bin/rm -rf /tmp/hs_err_pid*"], shell=True).wait() print "Creating cacheindex.createit" Popen(['touch', '/var/cdn/http/cacheindex.createit']).wait() print "...done" def getPartitions(): """ Executes "df -T" and parses output, looking for /cache* partitions. Returns a dict where {mountpoint: device} A partition is considered a "Cache partition" if the following are met: 1.) The string "/cache" is found in the mountpoint name 2.) The filesystem type is ext3 """ partitions = {} p = Popen(['df', '-T'], stdout=PIPE, stderr=STDOUT) for line in p.stdout.readlines(): line = line.split() if "cache" in line[6] and line[1] == "ext3": partitions[line[6]] = line[0] return partitions def formatPartition(mountpoint, device): """ Unmounts, re-FS'es, and re-mounts a given partition with a given mountpoint. Filesystem label will be extracted from the mountpoint. This function assumes we're dealing with a /cacheX partition. """ print "===== Handling %s (%s) =====" % (mountpoint, device) print "Unmounting %s" % (mountpoint) Popen(['umount', '-f', mountpoint]).wait() print "...done" label = mountpoint.split("/")[1] print "Making ext3 fs on %s with label %s" % (device, label) Popen(['/sbin/mkfs', '-t', 'ext3', '-T', 'largefile4', '-L', label, device]).wait() print "...done" print "Re-mounting %s as %s" % (device, mountpoint) Popen(['mount', mountpoint]).wait() print "...done" print "Setting permissions on %s" % (mountpoint) Popen(['chown', 'http:cdn', mountpoint]).wait() print "...done" print "" if __name__ == "__main__": if getuid() is not 0: print "You must run this script as root" print "Usage: sudo clearcache2.py" else: print """ ***** WARNING ***** You are about to destroy ALL CACHED CONTENT on this node. If you do not want to flush this entire node, Ctrl-C now! ...Starting in 10 seconds... ******************* """ sleep(10) stopServices() for mountpoint, device in sorted(getPartitions().items()): #print "DEBUG %s as %s" % (mountpoint, device) formatPartition(mountpoint, device) prepareCache() startServices() print "" print "All tasks complete!"