python爬虫----猫眼电影:最受期待榜
看一下猫眼的最受期待榜,了解大家都在期待什么样的电影,所以抓取数据来汇总。
模块
- requests--->用于请求
- re---->正则表达式的使用
- os---->用于处理目录
- csv---->用于csv文件的读写
- bs4---->获取网页响应的节点信息
- pandas--->读取csv文件
- pyecharts import Line---->画折线图
- fontTools.ttLib import TTFont---->解析字体
- multiprocessing import Pool---->多线程的使用
抓取的数据
下面的图片里面的红色框框就是这次要抓取的数据,但是直接去抓取原网页并不能抓取到我们想要的数据,如本月新增想看和总想看人数,直接抓取到没有什么用,需要进行转换, 通过分析和百度知道这是通过自定义字体的样式来实现的反爬策略之一。
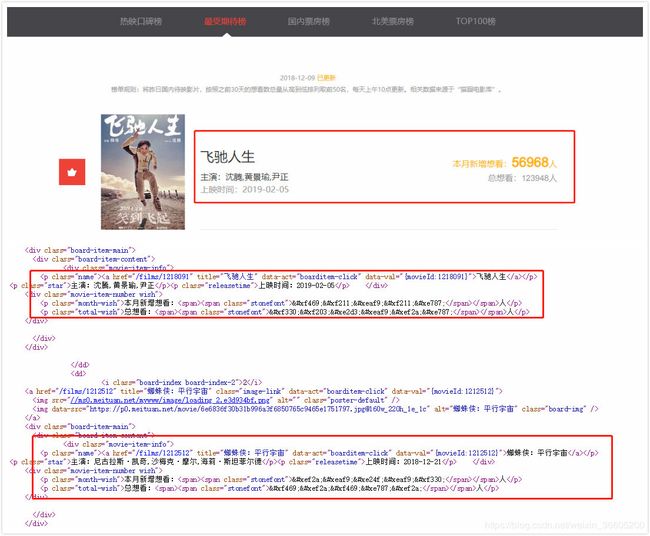
网页分析
如何通过自定义的字体样式来实现反爬的呢?在网页的样式里面,会发现 @font-face,这是css3里面定义的一种规则。并且加密的数据对应span标签的class属性为stonefont,字体的名称也是stonefont,样式里面通过类选择器来定义了字体的样式。
| 描述符 | 值 | 描述 |
|---|---|---|
| font-family | name | 必需。规定字体的名称 |
| src | url | 必需。规定字体文件的url |
| font-stretch | normal、condensed ultra-condensed、extra-condensed、semi-condensed、expanded、 semi-expanded、 extra-expanded、 ultra-expanded |
可选。定义如何拉伸字体。默认是“normal” |
| font-style | ormal、italic、oblique |
可选。定义字体的样式。默认是 "normal"。 |
| font-weight | normal、bold、100、 200、300、400、500 600、700、800、900 |
可选。定义字体的粗细。默认是 "normal"。 |
| unicode-range | unicode-range | 可选。定义字体支持的 UNICODE 字符范围。默认是 "U+0-10FFFF"。 |
下面的图片里面的样式就声明了字体的样式 ,指定了字体的url,在网页加载完之后,再通过样式的渲染就能正常的看到了想要的数据,所以直接抓取网页源代码是没有经过渲染的,就看不到具体的数据,不是真实的数据,而且每次字体文件地址都是随机的,会不一样,导致里面的相同数字的uni编码会不一样,所以需要下载相应的文件来进行解析。
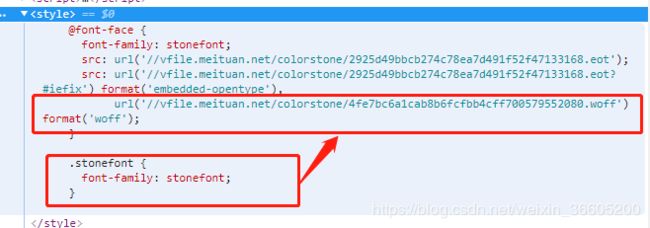
数据解密
通过上一步的解析,发现现有的方法不能够直接拿到数据,那就只能去解了。python里面有一个操作字体文件的库FontTools,通过这个库对字体文件进行解析。首先下载了该字体文件woff,字体文件的url为http:////vfile.meituan.net/colorstone/a116e19480aea9fb1abd5b966c014dcf2080.woff,命名为baseFont.woff,用百度字体编辑器FontEditor,查看下载好的文件,可以看到基本的信息,但是这还不够,找不到什么关联。而且每一次加载字体文件的时候字体的uni编码都不一样,也不是互相对应的。所以用到了FontTools模块来操作,TTFont(“字体文件的地址”).saveXML("保存的文件名")保存为xml文件就可以查看到更加详细的信息了。
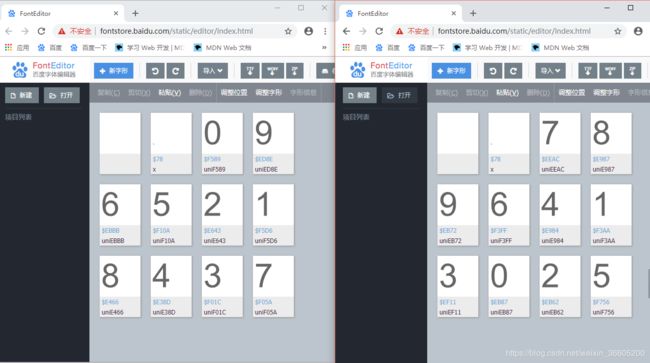 不同的woff字体文件的信息
不同的woff字体文件的信息
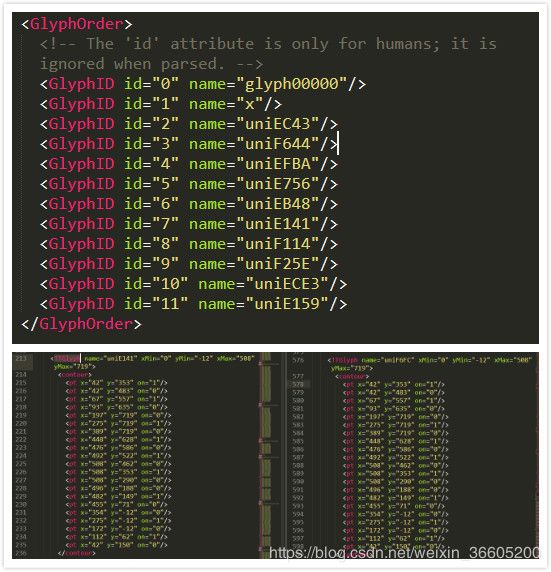 woff保存为xml文件的部分信息
woff保存为xml文件的部分信息
从上面来看,GlyphOrder 标签中就是这个字体xml包含的字符种类了,glyf 这个标签中是这些字体的具体坐标画法,一个TTGlyph对应一个字体,而其中contour标签是字体的坐标数据,通过比较虽然相同数字的uni编码是不一样的,但是它们的contour里面对应的坐标是一样的,所以这里是一个突破口,然后先下载一个字体文件,命名为baseFont作为参照,出现新的字体文件的时候都去和该参照文件作比较,就能找出相应的数字了。
代码
网页抓取
# 获取网页源码
def get_html(url):
# 构造请求头
headers={
'Content-Type': 'application/x-www-form-urlencoded',
'Origin': 'https://maoyan.com',
'Referer': 'https://maoyan.com/board/6',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'
}
try:
resp=requests.get(url,headers=headers)
# 响应状态码,200表示请求成功
if resp.status_code==200:
return resp.content
else:return None
except Exception as e:
return None字体文件下载并转换为xml文档
# 下载字体文件,字体文件的url为:http://vfile.meituan.net/colorstone/fbbbe0bb5db49c744f4b966d65c5e7612084.woff
def down_load_woff(html_content):
# 加上r表示是原生字符串
# 正则表达式匹配出字符串:url('//vfile.meituan.net/colorstone/fbbbe0bb5db49c744f4b966d65c5e7612084.woff') format('woff');
pattern=re.compile(r"url\('(.*?)'\) format\('woff'\)")
font_url="http:"+re.findall(pattern, html_content)[0]
print(font_url)
# 找出fonts文件夹下的所有文件,返回path指定的文件夹包含的文件或文件夹的名字的列表
font_files=os.listdir('./fonts')
# 要下载的字体名称
font_name=font_url.split('/')[-1]
# 判断该字体文件是否存在本地的项目的fonts下
if font_name not in font_files:
print('下载字体:'+font_name)
resp=get_html(font_url)
with open('./fonts/'+font_name,'wb')as f:
f.write(resp)
font=TTFont('./fonts/'+font_name)
# 分割字体文件的名称
xml_name=font_name.split('.')[0]
# 保存为xml
font.saveXML('./xmls/'+xml_name)
return font
数据解码
# 对网页上面的加密的数字进行解码
def decode_font(font,html_content):
# 打开原本下载好的字体文件
base_font=TTFont('./fonts/baseFont.woff')
# 获取xml文档GlyphOrder标签的name属性值
new_unicode_list=font['cmap'].tables[0].ttFont.getGlyphOrder()
# 手动解析映射关系,数字和编码的关系
base_num_list=[0,9,6,5,2,1,8,4,3,7]
base_unicode_list=['uniF589','uniED8E','uniEBBB','uniF10A','uniE643','uniF5D6','uniE466','uniE38D','uniF01C','uniF05A']
# 存储数字
new_num_list=[]
for n in range(1,12):
# 获取xml文档glfy标签对应的TTGlyph对象
new_glyf=font['glyf'][new_unicode_list[n]]
for b in range(10):
base_glyf=base_font['glyf'][base_unicode_list[b]]
if base_glyf==new_glyf:
new_num_list.append(base_num_list[b])
break
# 修改uniEBBB--->
result=[str.replace('uni','&#x').lower()+";"for str in new_unicode_list[2:]]
# zip函数将列表打包为元组列表,dict函数将元组列表转换为字典
dictory = dict(zip(result, new_num_list))
# 遍历字典,判断键是否在网页当中
for key in dictory:
if key in html_content:
# 网页的加密数据的编码替换
html_content = html_content.replace(key, str(dictory[key]))
return html_content网页数据获取
# 解析网页
def parse_page(html_content):
# beautifulsoup解析
soup=bs(html_content,'lxml')
board_item_contents=soup.findAll(attrs={'class':'board-item-content'})
for item in board_item_contents:
star=""
try:
star=item.find(attrs={'class':'star'}).get_text()
except Exception as e:
star+="无"
finally:
yield{
# 获取相应节点的信息
'title':item.find(attrs={'class':'name'}).a['title'],
'star':star,
'releasetime':item.find(attrs={'class':'releasetime'}).get_text(),
'monthwish':item.find(attrs={'class':'month-wish'}).find(attrs={'class':'stonefont'}).get_text(),
'totalwish':item.find(attrs={'class':'total-wish'}).find(attrs={'class':'stonefont'}).get_text()
}
csv文件存储数据
def write_to_csv(content,offset):
with open('猫眼最受期待榜'+str(offset)+'.csv','a',newline='',encoding='utf-8-sig') as f:
w=csv.writer(f)
w.writerow(['电影名称','主演','上映时间','本月新增想看人数','总想看人数'])
for item in parse_page(content):
# print(item)
w.writerow([item['title'],item['star'][3:],item['releasetime'][5:],item['monthwish'],item['totalwish']])读csv文件
利用pandas来读取csv文件,读取后面10行的数据,每个csv文件放10部电影的信息,需要对文件特定列读取信息,转换为list,因为画图要用到。
# 读csv文件
def read_csv_file(csv_name,index):
with open(csv_name,encoding='utf-8') as f:
csv_data=pd.read_csv(f,header=None)
# 取后10条数据
field_data=csv_data.tail(10)
make_line_chart(index,list(field_data[0]),list(field_data[3]),list(field_data[4]))折线图
使用pyecharts来画图,安装方式:pip install pyecharts,但是在导入pyecharts显示出错,No module named 'pyecharts_snapshot',需要去安装pip install pyecharts-snapshot即可。
# 画折线图
def make_line_chart(index,list_x,list_y1,list_y2):
# 电影名称
x=list_x
# 本月新增想看人数
y1=list_y1
# 总想看人数
y2=list_y2
line=Line("猫眼最受期待榜"+str(index))
label1='本月新增想看人数'
label2='总想看人数'
line.add(label1, x, y1, mark_point=["average"])
line.add(label2, x, y2, is_smooth=True,mark_line=["max", "average"])
line.render('猫眼最受期待榜'+str(index)+'.html')效果图
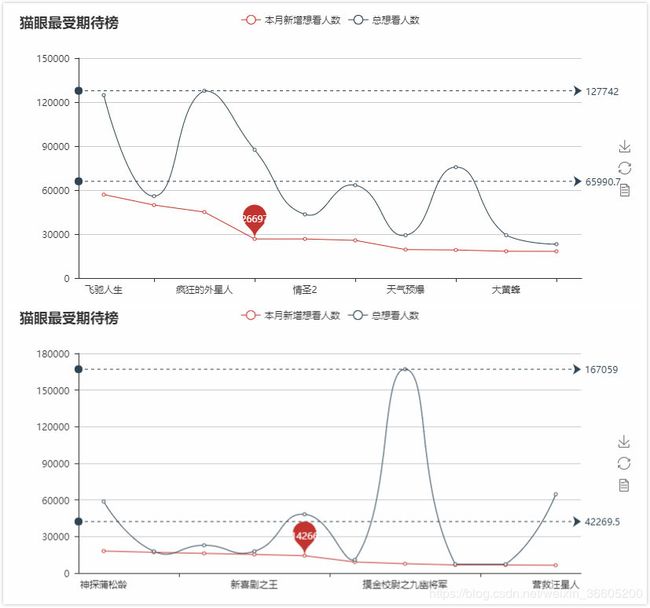 效果图
效果图
总结:csv的写入中文乱码是一个坑,网页数据解析也是一个坑,有些电影是没有主演的。
项目链接:链接:https://pan.baidu.com/s/162LumULIQeQEn5frdM_4xQ 提取码:tyqm